标签:数据分析 数据库 数据仓库 查询 OLTP OLAP 表单 数据
在接触大数据之前我们基本都是使用mysql数据库,这种定位为关系型的数据库主要是为了实时业务需要而建表,而在大数据中大多是以分析为主的,读多写少,且如果用传统的关系型数据库则经常会涉及到多表联合查询,因此这种关系型数据库并不适用于分析场景,本文主要是介绍OLAP和OLTP区别以及数据仓库和数据库区别入门大数据。
一、OLTP和OLAP是什么?
OLTP,也叫联机事务处理(Online Transaction Processing),表示事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction往往超过几百个,或者是几千个,Select 语句的执行量每秒几千甚至几万个。典型的OLTP系统有电子商务系统、银行、证券等,如美国eBay的业务数据库,就是很典型的OLTP数据库。业务场景如银行转账等实时场景。
OLAP,叫联机分析处理(On-Line Analytical Processing),是数据仓库系统(HBase、ClickHouse…)的主要应用,支持对海量数据进行复杂的统计分析操作,持久化数据一般不进行修改,数据一致性要求不高,侧重决策支持,并且提供直观易懂的查询结果,例如商城推荐系统,用户人物画像。有的时候也叫DSS决策支持系统,就是我们说的数据仓库。在这样的系统中,语句的执行量不是考核标准,因为一条语句的执行时间可能会非常长,读取的数据也非常多。所以,在这样的系统中,考核的标准往往是磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。业务场景如商品推荐,比如电商场景下常见的,根据用户行为做商品推荐。用户的行为数据存进数仓后,进行实时计算,然后将算法模型计算出的推荐结果发给业务端做展示。
二、数据仓库和数据库区别?
本质上来说讲数据仓库和数据库区别就是OLAP和OLTP区别,而二者存储上,数据库采用的行式存储,数据仓库基本采用基于HDFS的列式存储。数据库的的作用我们基本知道,用于比较实时的事务型业务场景,而数据仓库的作用也比较多,如下图所示(图片来源:https://www.zhihu.com/question/20623931):

由上面的数据仓库系统架构图我们可以看出,数据仓库系统面向的使用者一般为产品运营人员和决策人员,帮助运营人员分析系统的不足,及时进行优化,而数据仓库中的数据是经过对各业务系统中的业务数据进行ETL之后得到的。如下图所示:

ETL(Extract-Transform-Load):是一种数据仓库技术,ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据, ETL是BI(商业智能)项目重要的一个环节。
下面内容来自:https://www.zhihu.com/question/20623931/answer/750367153
在数据存储方面,以图书表格系统为例。如果是数据库储存的话,表单的设计如下:

这里有六张表,分别记录了作者,图书,图书种类,发行商以及他们之间的关系。
如果我们把以上数据用数据仓库来存储,表单设计需要对原始表单进行Denormalization。

很明显,因为在denormalization的过程中,如果数据库主表和次表不是一对一的关系,那么最终数据仓库主表或者次表一定会出现重复的数据。所以从存储空间角度讲,相比于数据库紧密的存储结构,数据仓库则存在大量冗余重复的数据。
基本读(Read)操作对比
下图所示的两种查询,一个是找一本书(PrimaryKey)的信息,另一个是找一位作者(Non-Key)所有的作品信息。由于数据库需要利用表之间的关联才能找到所有需要的数据,在效率上会相对低下。相比之下数据仓库把这些关联关系转化成重复数据记录到同一张表上了,查询效率相对就会较高。数据仓库相当于牺牲了空间换取了查询效率。

在数据库里面写这段query的时候,我们需要了解表单的结构与他们之间的关系——这对于做数据报告或者数据分析非常不友好,尤其是在表单结构很复杂的时候(比如表单使用了逻辑树的储存结构)。这时候数据仓库简单明了的Denormalized表单结构就对于生成数据报告就非常有优势了。除此之外,由于数据报告和数据分析常常涉及到大规模的查询,这些查询很可能会占用很高的CPU资源,从而可能影响到数据库的常规读写操作——因为数据库常常是单实例的;这一点上数据仓库的Multi-instances的结构就不会有太多这个问题。
大数据读(Read)操作对比
当数据量非常大的时候,特定条件下的数据仓库的读优化所带来的优势就开始碾压数据库了。大部分的数据库都是Single-instance的,而数据仓库则是Multi-instances的distributed system。数据仓库在分配储存的节点的时候是根据PrimaryKey/PartitionKey来分配的,查询的时候不仅根据查询键的值来搜索对应节点位置,同时进行大量的并行查询。这使得在对大数据进行查询的时候有极大的优势。
在对小量数据进行读取操作的时候,由于数据仓库要进行找Node的location之类的预运算,整体效率上反倒不如数据库。如果读取操作的目标不是主键(PrimaryKey)或者分配键(PartitionKey),那么数据仓库的查询也需要进行全局扫描,效率上就不好说是否胜过数据库了。
写操作对比
大多数情况下,数据仓库不太会进行精确的写操作。因为冗余行数太多,有时候只是改一个很小的字段,也会修改大量的行数。而对于数据库来说,由于其紧凑的表格结构,写操作就可以非常精细有效了。比如,我需要修改《Java Complete》这本书的版权,从1999改到2002,数据库里面只需要该一行,而数据仓库里面需要改5行。

数据仓库的写操作都是整段(表)刷新或者整段数据插入, 这也和它的用途——做数据分析有关系。由于数据仓库的整表刷新和分布式储存的特质,我们可以通过把PartitionKey设置成数据创建/更新的时间,然后记录一段时间内的历史数据。这对于数据分析以及利用数据进行决策都有重要意义。虽然这里进行了数据库和数据仓库的对比,但是并不是想得出两者孰优孰劣的结论。实际情况是,很多的架构的存储方案都是数据库和数据仓库一起使用的。
通常的软件架构简化一下就是,用户通过API和数据库交互。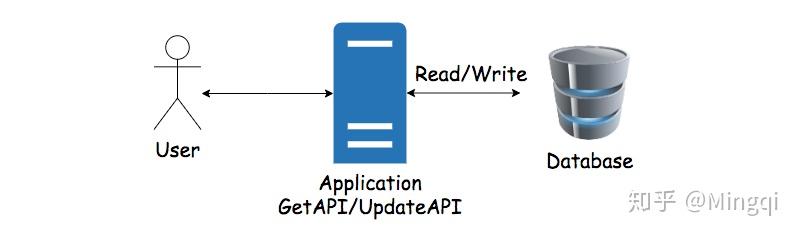 这里如果要直接在数据库上做数据分析,数据监控等等任务的话,会有以下几个问题:数据分析通常涉及大量数据查询,可能会占用太多CPU从而影响软件的基本功能。数据库的表单结构通常比较复杂,需要数据分析人员对DB结构有深入的了解。数据库在进行大量数据查询的时候效率较低。开放数据库访问权限(即便只是读权限),尤其是给外组人员,会有安全隐患。为了解决以上四个问题,我们可以通过利用脚本,每隔一段时间把数据库里面的所有数据Denormalize到数据仓库里面,在数据仓库里面进行数据分析。根据之前提到的数据仓库的所有的特性(独立不影响业务,表结构简单,读数据速度快,相对安全),这四个问题都可以得到很好的解决。
这里如果要直接在数据库上做数据分析,数据监控等等任务的话,会有以下几个问题:数据分析通常涉及大量数据查询,可能会占用太多CPU从而影响软件的基本功能。数据库的表单结构通常比较复杂,需要数据分析人员对DB结构有深入的了解。数据库在进行大量数据查询的时候效率较低。开放数据库访问权限(即便只是读权限),尤其是给外组人员,会有安全隐患。为了解决以上四个问题,我们可以通过利用脚本,每隔一段时间把数据库里面的所有数据Denormalize到数据仓库里面,在数据仓库里面进行数据分析。根据之前提到的数据仓库的所有的特性(独立不影响业务,表结构简单,读数据速度快,相对安全),这四个问题都可以得到很好的解决。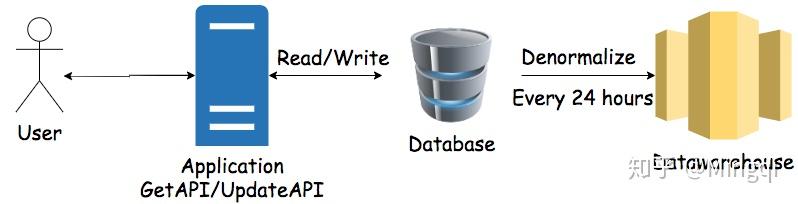 但是这里还是有一个小问题。如果有很多不同的组需要共享这个Datawarehouse,那么同样他们的脚本可能会相互影响。通过数据目录(Data Catalog)储存元数据,然后发布出去让不同组的数据仓库都可以同步这个数据。这样,每个不同组的数据仓库都拿到了同样的Denormalized数据,但是却相互独立开了。
但是这里还是有一个小问题。如果有很多不同的组需要共享这个Datawarehouse,那么同样他们的脚本可能会相互影响。通过数据目录(Data Catalog)储存元数据,然后发布出去让不同组的数据仓库都可以同步这个数据。这样,每个不同组的数据仓库都拿到了同样的Denormalized数据,但是却相互独立开了。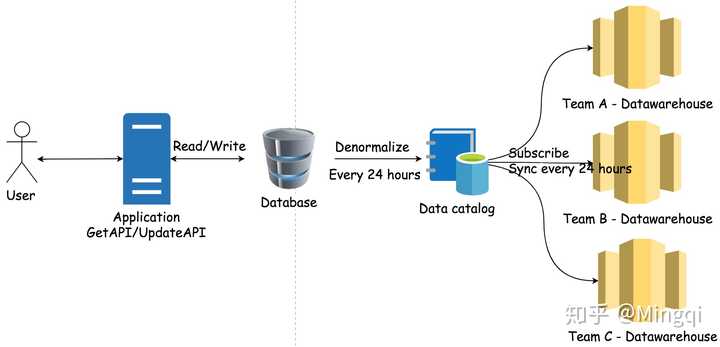 这样一个架构基本上是把做事务处理的数据库和做数据分析的数据仓库解耦了。同时增加了整个系统的可扩展性。
这样一个架构基本上是把做事务处理的数据库和做数据分析的数据仓库解耦了。同时增加了整个系统的可扩展性。
标签:数据分析,数据库,数据仓库,查询,OLTP,OLAP,表单,数据 来源: https://blog.csdn.net/dl962454/article/details/120611994
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。