标签:遍历 对象 Lua step GC 内存 table gc 机制
说明
分析lua使用的gc算法,如何做到分步gc,以及测试结论
gc算法分析
lua gc采用的是标记-清除算法,即一次gc分两步:
- 从根节点开始遍历gc对象,如果可达,则标记
- 遍历所有的gc对象,清除没有被标记的对象
二色标记法
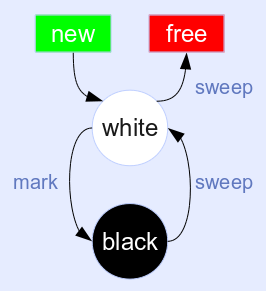
lua 5.1之前采用的算法,二色回收法是最简单的标记-清除算法,缺点是gc的时候不能被打断,所以会严重卡住主线程
三色标记法
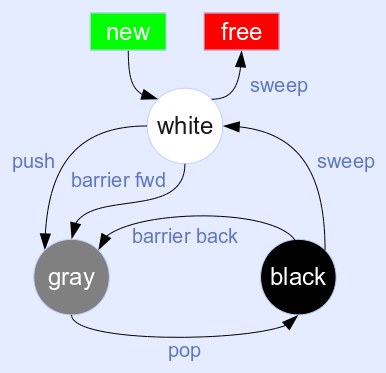
- lua5.1开始采用了一种三色回收的算法
- 白色:在gc开始阶段,所有对象颜色都为白色,如果遍历了一遍之后,对象还是白色的将被清除
- 灰色:灰色用在分步遍历阶段,如果一直有对象为灰色,则遍历将不会停止
- 黑色:确实被引用的对象,将不会被清除,gc完成之后会重置为白色
- luajit使用状态机来执行gc算法,共有6中状态:
- GCSpause:gc开始阶段,初始化一些属性,将一些跟节点(主线程对象,主线程环境对象,全局对象等)push到灰色链表中
- GCSpropagate:分步进行扫描,每次从灰色链表pop一个对象,遍历该对象的子对象,例如如果该对象为table,并且value没有设置为week,则会遍历table所有table可达的value,如果value为gc对象且为白色,则会被push到灰色链表中,这一步将一直持续到灰色链表为空的时候。
- GCSatomic:原子操作,因为GCSpropagate是分步的,所以分步过程中可能会有新的对象创建,这时候将再进行一次补充遍历,这遍历是不能被打断的,但因为绝大部分工作被GCSpropagate做了,所以过程会很快。新创建的没有被引用的userdata,如果该userdata自定义了gc元方法,则会加入到全局的userdata链表中,该链表会在最后一步GCSfinalize处理。
- GCSsweepstring:遍历全局字符串hash表,每次遍历一个hash节点,如果hash冲突严重,会在这里影响gc。如果字符串为白色并且没有被设置为固定不释放,则进行释放
- GCSsweep:遍历所有全局gc对象,每次遍历40个,如果gc对象为白色,将被释放
- GCSfinalize:遍历GCSatomic生成的userdata链表,如果该userdata还存在gc元方法,调用该元方法,每次处理一个
什么时候会导致gc?
-
luajit中有两个判断是否需要gc的宏,如果需要gc,则会直接进行一次gc的step操作
1
2
3
4
5
6
7/* GC check: drive collector forward if the GC threshold has been reached. */
#define lj_gc_check(L) \
{ if (LJ_UNLIKELY(G(L)->gc.total >= G(L)->gc.threshold)) \
lj_gc_step(L); }
#define lj_gc_check_fixtop(L) \
{ if (LJ_UNLIKELY(G(L)->gc.total >= G(L)->gc.threshold)) \
lj_gc_step_fixtop(L); }- gc.total: 代表当前已经申请的内存
- gc.threshold:代表当前设置gc的阈值
-
这两个宏会在各个申请内存的地方进行调用,所以当前申请的内存如果已经达到设置的阈值,则会申请的所有对象都会有gc消耗。
lua gc api
lua可以通过
1 |
collectgarbage([opt [, arg]]) |
来进行一些gc操作,其中opt参数可以为:
- “collect”:执行一个完整的垃圾回收周期,这是一个默认的选项
- “stop”:停止垃圾收集器(如果它在运行),实现方式其实就是将gc.threshold设置为一个巨大的值,不再触发gc step操作
- “restart”:将重新启动垃圾收集器(如果它已经停止)。
- “count”:返回当前使用的的程序内存量(单位是Kbytes),返回gc->total/1024
- “step”:执行垃圾回收的步骤,这个步骤的大小由参数arg(较大的数值意味着较多的步骤),如果这一步完成了一个回收周期则函数返回true。
-
“setpause”:设置回收器的暂停参数,并返回原来的暂停数值。该值是一个百分比,影响gc.threshold的大小,即影响触发下一次gc的时间,设置代码如下:
1
g->gc.threshold = (g->gc.estimate/100) * g->gc.pause;
g->gc.estimate为当前实际使用的内存的大小,如果gc.pause为200,则该段代码表示,设置gc的阈值为当前实际使用内存的2倍
- “setstepmul”:设置回收器的步进乘数,并返回原值。该值代表每次自动step的步长倍率,影响每次gc step的速率,具体这么影响可以查看后面小节
luajit gc速率控制
1 |
int LJ_FASTCALL lj_gc_step(lua_State *L) |
- 可以看到最重要的变量为lim,该变量控制着一个lj_gc_step里的循环次数。每次调用gc_onestep都会返回此次的step消耗,例如如果处于GCSpropagate阶段,则返回值为该step遍历的内存大小,所以如果遍历了一个较大的table就会消耗更多的lim值
- lim大小主要由gc.stepmul控制,所以设置该值的大小会影响每次step的调用时间
测试大table对gc的影响
从luajit gc原理上看,以为每次gc的遍历都会遍历所有的gc对象,所以大的table是会影响gc性能
测试环境
操作系统:Debian GNU/Linux 8
CPU:Intel(R) Xeon(R) CPU E5-2640 v2 @ 2.00GHz
内存:64G
lua环境:LuaJIT-2.1.0-beta3 (测试的时候关闭jit)
测试代码
1 |
-- 关闭jit |
测试结果(第一个列为当前内存,第二列为当前内存阈值,第三列为当前gc状态,第四列为循环10次的时间)
1 |
-- gc没有介入阶段,平均时间大概在0.059s,这时候代表着内存的分配速度 |
- 火焰图分析(gc处于sweep状态):
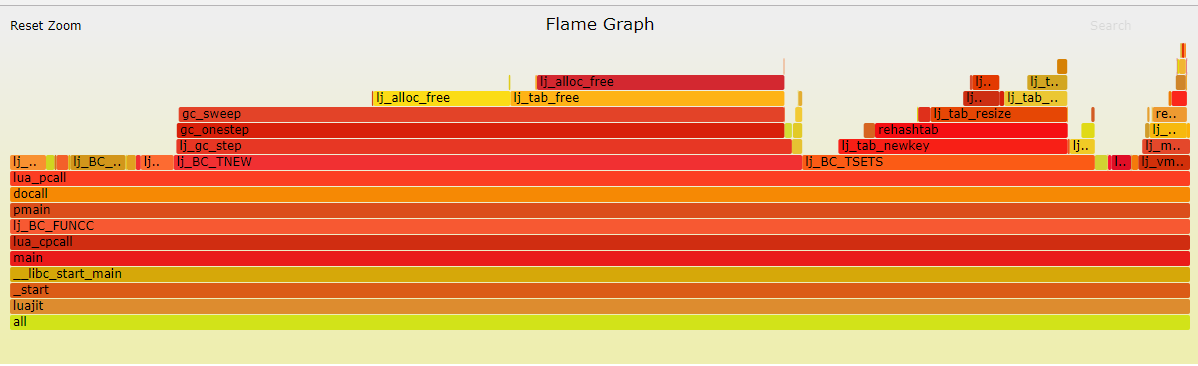
主要时间消耗在gc_sweep(51.34%):该步骤会遍历所有的gc对象,如果可回收,就进行free操作,所以gc_sweep里面最耗时的就是free函数(34%左右)
gc优化
从火焰图上看到,gc_sweep函数耗时严重,其主要工作是遍历所有gc对象,如果为白色,则free它,所以优化方案有两点:
- 内存分配算法优化
- 减少gc遍历的对象,即减少那些明确常驻内存的gc对象遍历
内存分配算法优化
luajit默认使用的是自己的内存分配算法,现在尝试分别使用glibc自带的内存分配和第三方高性能jemalloc(选择的版本是jemalloc-stable-4),tcmalloc(选择的是gperftools-2.7)的分配算法进行分析测试结果

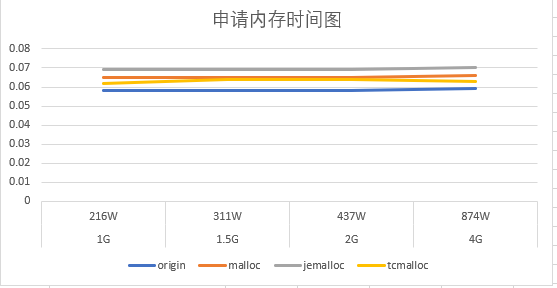
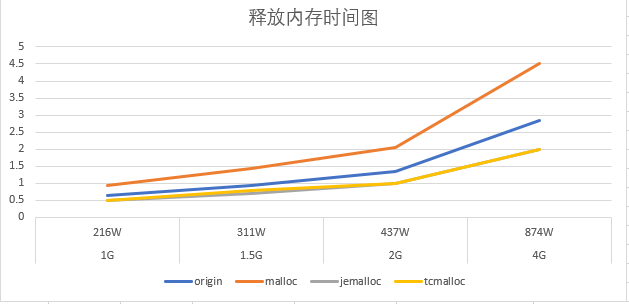
结果分析
- 申请内存的速率跟常驻内存的table大小关系不大,luajit自带的分配算法最快,但是总体相差不大
- 随着常驻内存的table大小变大,会影响gc释放速度,这将会卡主主线程
- 释放内存速率jemalloc最好,并且随着常驻内存的table大小变大,效率体现的越明显
table缓存优化
思路
自己写一个table缓冲池,缓冲一定数量、一定大小的table在c++内存,避免每次反复申请内存及rehash,reszie table操作
TODO: 需要具体修改luajit源码进行测试
减少gc遍历的对象
思路
对于那些常驻内存的table,可以主动加一个标记,在gc时候遍历到这个table,将对其以及所有子gc对象从全局gc链表删除,并加入到一个全局const gc对象链表中。
源代码可以查看github
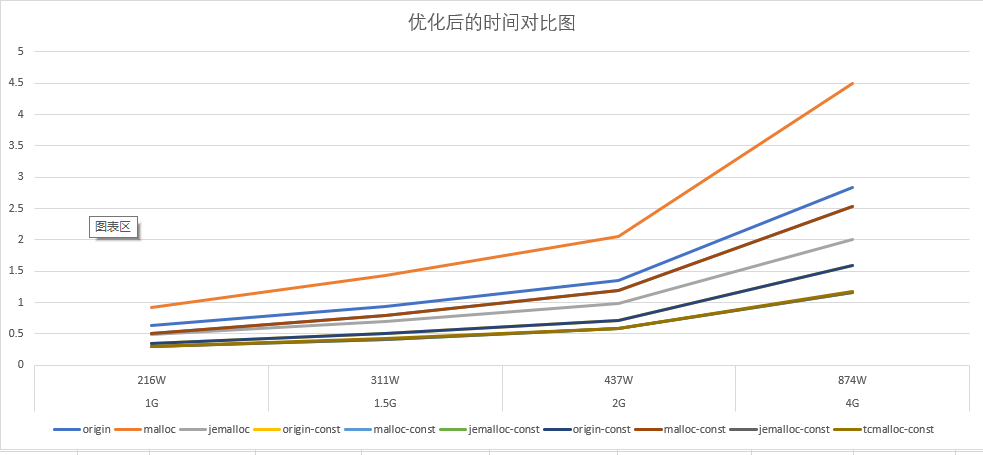
测试结果

对比结果
火焰图(jemalloc-4G内存)
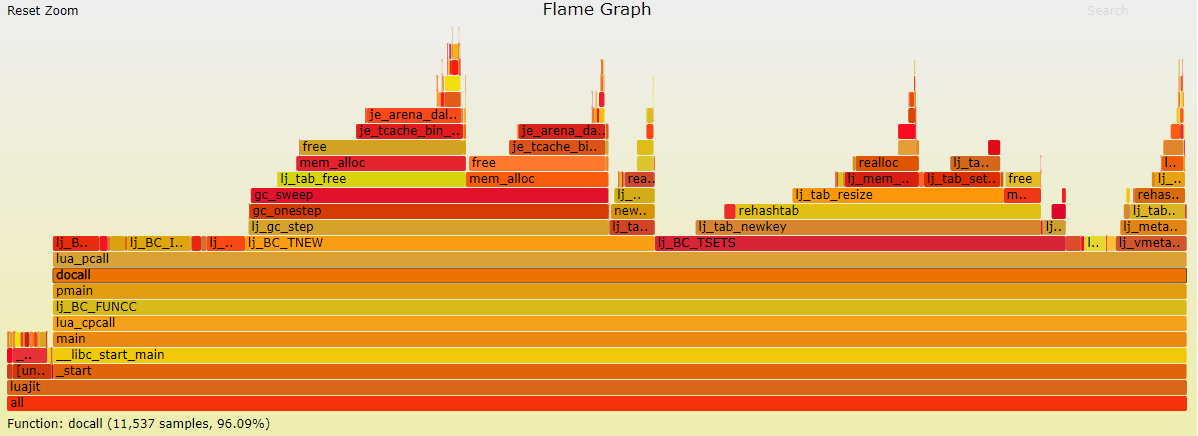
- gc_sweep在总的采样占比上已经变得很少,这点从打log上面就能看出
- free占比gc_sweep的时间比重增加,说明减少了遍历的时间消耗
注意点
- 从给table设置constant之后完整的一次gc之前,不能主动调用full gc否则会导致table子元素没有被标记,这样就会被误删除,导致访问的时候出现内存问题
- table不能设置weak
- table元素只能是table、string、number,不能有function,线程
结论
可以看到优化在常驻内存table大的时候很明显,主要提升了两个方面的速度: - 在GCSpropagate阶段减少不必要的遍历,加快遍历速度,同时减少了新临时变量的生成
- 在GCSweep阶段,减少不必要的遍历,同时因为加快遍历速度,需要free的临时变量变少,所以减少了GCSweep的时间
标签:遍历,对象,Lua,step,GC,内存,table,gc,机制 来源: https://www.cnblogs.com/gangtie/p/12724295.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。