标签:面试官 遍历 BST 美团 int 二叉树 root 节点
https://labuladong.gitee.io/algo/2/18/27/
读完本文,你不仅学会了算法套路,还可以顺便去 LeetCode 上拿下如下题目:
———–
其实二叉树的题目真的不难,无非就是前中后序遍历框架来回倒嘛,但是对于有的题目,不同的遍历顺序时间复杂度不同。
之前面试美团,就遇到一道二叉树算法题,当时我是把解法写出来了,面试官说如果用后序遍历,时间复杂度可以更低。
本文就来分析一道类似的题目,通过二叉树的后序遍历,来大幅降低算法的复杂度。
手把手刷二叉树第一期 说过二叉树相关题目最核心的思路是明确当前节点需要做的事情是什么。
我们再看看后序遍历的代码框架:
void traverse(TreeNode root) {
traverse(root.left);
traverse(root.right);
/* 后序遍历代码的位置 */
/* 在这里处理当前节点 */
}
看这个代码框架,你说后序遍历什么时候出现呢?
如果当前节点要做的事情需要通过左右子树的计算结果推导出来,就要用到后序遍历。
很多时候,后序遍历用得好,可以大幅提升算法效率。
我们今天就要讲一个经典的算法问题,可以直观地体会到这一点。
这是力扣第 1373 题「二叉搜索子树的最大键值和」,函数签名如下:
int maxSumBST(TreeNode root);
题目会给你输入一棵二叉树,这棵二叉树的子树中可能包含二叉搜索树对吧,请你找到节点之和最大的那棵二叉搜索树,返回它的节点值之和。
二叉搜索树(简写作 BST)的性质不用我多介绍了吧,简单说就是「左小右大」,对于每个节点,整棵左子树都比该节点的值小,整棵右子树都比该节点的值大。
比如题目给了这个例子:
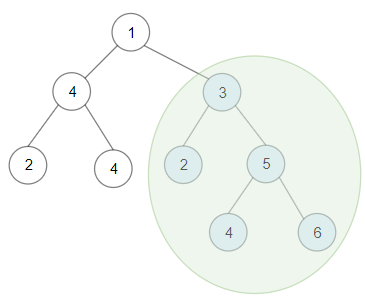
如果输入这棵二叉树,算法应该返回 20,也就是图中绿圈的那棵子树的节点值之和,因为它是一棵 BST,且节点之和最大。
那有的读者可能会问,根据 BST 的定义,有没有可能一棵二叉树中不存在 BST?
不会的,因为按照 BST 的定义,任何一个单独的节点肯定是 BST,也就是说,再不济,二叉树最下面的叶子节点肯定是 BST。
比如说如果输入下面这棵二叉树:
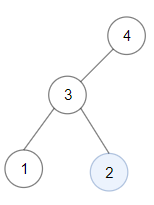
两个叶子节点 1 和 2 就是 BST,比较一下节点之和,算法应该返回 2。
好了,到这里,题目应该解释地很清楚了,下面我们来分析一下这道题应该怎么做。
刚才说了,二叉树相关题目最核心的思路是明确当前节点需要做的事情是什么。
那么我们想计算子树中 BST 的最大和,站在当前节点的视角,需要做什么呢?
1、我肯定得知道左右子树是不是合法的 BST,如果这俩儿子有一个不是 BST,以我为根的这棵树肯定不会是 BST,对吧。
2、如果左右子树都是合法的 BST,我得瞅瞅左右子树加上自己还是不是合法的 BST 了。因为按照 BST 的定义,当前节点的值应该大于左子树的最大值,小于右子树的最小值,否则就破坏了 BST 的性质。
3、因为题目要计算最大的节点之和,如果左右子树加上我自己还是一棵合法的 BST,也就是说以我为根的整棵树是一棵 BST,那我需要知道我们这棵 BST 的所有节点值之和是多少,方便和别的 BST 争个高下,对吧。
根据以上三点,站在当前节点的视角,需要知道以下具体信息:
1、左右子树是否是 BST。
2、左子树的最大值和右子树的最小值。
3、左右子树的节点值之和。
只有知道了这几个值,我们才能满足题目的要求,后面我们会想方设法计算这些值。
现在可以尝试用伪码写出算法的大致逻辑:
// 全局变量,记录 BST 最大节点之和
int maxSum = 0;
/* 主函数 */
public int maxSumBST(TreeNode root) {
traverse(root);
return maxSum;
}
/* 遍历二叉树 */
void traverse(TreeNode root) {
if (root == null) {
return;
}
/******* 前序遍历位置 *******/
// 判断左右子树是不是 BST
if (!isBST(root.left) || !isBST(root.right)) {
goto next;
}
// 计算左子树的最大值和右子树的最小值
int leftMax = findMax(root.left);
int rightMin = findMin(root.right);
// 判断以 root 节点为根的树是不是 BST
if (root.val <= leftMax || root.val >= rightMin) {
goto next;
}
// 如果条件都符合,计算当前 BST 的节点之和
int leftSum = findSum(root.left);
int rightSum = findSum(root.right);
int rootSum = leftSum + rightSum + root.val;
// 计算 BST 节点的最大和
this.maxSum = Math.max(maxSum, rootSum);
/**************************/
// 递归左右子树
next:
traverse(root.left);
traverse(root.right);
}
/* 计算以 root 为根的二叉树的最大值 */
int findMax(TreeNode root) {}
/* 计算以 root 为根的二叉树的最小值 */
int findMin(TreeNode root) {}
/* 计算以 root 为根的二叉树的节点和 */
int findSum(TreeNode root) {}
/* 判断以 root 为根的二叉树是否是 BST */
boolean isBST(TreeNode root) {}
这个代码逻辑应该是不难理解的,代码在前序遍历的位置把之前的分析都实现了一遍。
其中有四个辅助函数比较简单,我就不具体实现了,其中只有判断合法 BST 的函数稍有技术含量,前文 二叉搜索树操作集锦 写过,这里就不展开了。
稍作分析就会发现,这几个辅助函数都是递归函数,都要遍历输入的二叉树,外加 traverse 函数本身的递归,可以说是递归上加递归,所以这个解法的复杂度是非常高的。
但是根据刚才的分析,像 leftMax、rootSum 这些变量又都得算出来,否则无法完成题目的要求。
我们希望既算出这些变量,又避免辅助函数带来的额外复杂度,鱼和熊掌全都要!
其实是可以的,只要把前序遍历变成后序遍历,让 traverse 函数把辅助函数做的事情顺便做掉。
其他代码不变,我们让 traverse 函数做一些计算任务,返回一个数组:
// 全局变量,记录 BST 最大节点之和
int maxSum = 0;
/* 主函数 */
public int maxSumBST(TreeNode root) {
traverse(root);
return maxSum;
}
// 函数返回 int[]{ isBST, min, max, sum}
int[] traverse(TreeNode root) {
int[] left = traverse(root.left);
int[] right = traverse(root.right);
/******* 后序遍历位置 *******/
// 通过 left 和 right 推导返回值
// 并且正确更新 maxSum 变量
/**************************/
}
traverse(root) 返回一个大小为 4 的 int 数组,我们暂且称它为 res,其中:
res[0] 记录以 root 为根的二叉树是否是 BST,若为 1 则说明是 BST,若为 0 则说明不是 BST;
res[1] 记录以 root 为根的二叉树所有节点中的最小值;
res[2] 记录以 root 为根的二叉树所有节点中的最大值;
res[3] 记录以 root 为根的二叉树所有节点值之和。
其实这就是把之前分析中说到的几个值放到了 res 数组中,最重要的是,我们要试图通过 left 和 right 正确推导出 res 数组。
直接看代码实现吧:
int[] traverse(TreeNode root) {
// base case
if (root == null) {
return new int[] {
1, Integer.MAX_VALUE, Integer.MIN_VALUE, 0
};
}
// 递归计算左右子树
int[] left = traverse(root.left);
int[] right = traverse(root.right);
/******* 后序遍历位置 *******/
int[] res = new int[4];
// 这个 if 在判断以 root 为根的二叉树是不是 BST
if (left[0] == 1 && right[0] == 1 &&
root.val > left[2] && root.val < right[1]) {
// 以 root 为根的二叉树是 BST
res[0] = 1;
// 计算以 root 为根的这棵 BST 的最小值
res[1] = Math.min(left[1], root.val);
// 计算以 root 为根的这棵 BST 的最大值
res[2] = Math.max(right[2], root.val);
// 计算以 root 为根的这棵 BST 所有节点之和
res[3] = left[3] + right[3] + root.val;
// 更新全局变量
maxSum = Math.max(maxSum, res[3]);
} else {
// 以 root 为根的二叉树不是 BST
res[0] = 0;
// 其他的值都没必要计算了,因为用不到
}
/**************************/
return res;
}
这样,这道题就解决了,traverse 函数在遍历二叉树的同时顺便把之前辅助函数做的事情都做了,避免了在递归函数中调用递归函数,时间复杂度只有 O(N)。
你看,这就是后序遍历的妙用,相对前序遍历的解法,现在的解法不仅效率高,而且代码量少,比较优美。
那肯定有读者问,后序遍历这么好,是不是就应该尽可能多用后序遍历?
其实也不是,主要是看题目,就好比 BST 的中序遍历是有序的一样。
这道题为什么用后序遍历呢,因为我们需要的这些变量都是可以通过后序遍历得到的。
你计算以 root 为根的二叉树的节点之和,是不是可以通过左右子树的和加上 root.val 计算出来?
你计算以 root 为根的二叉树的最大值/最小值,是不是可以通过左右子树的最大值/最小值和 root.val 比较出来?
你判断以 root 为根的二叉树是不是 BST,是不是得先判断左右子树是不是 BST?是不是还得看看左右子树的最大值和最小值?
文章开头说过,如果当前节点要做的事情需要通过左右子树的计算结果推导出来,就要用到后序遍历。
因为以上几点都可以通过后序遍历的方式计算出来,所以这道题使用后序遍历肯定是最高效的。
以我的刷题经验,我们要尽可能避免递归函数中调用其他递归函数,如果出现这种情况,大概率是代码实现有瑕疵,可以进行类似本文的优化来避免递归套递归。
_____________
标签:面试官,遍历,BST,美团,int,二叉树,root,节点 来源: https://www.cnblogs.com/techyu/p/15565423.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。