标签:架构 Intel 芯片 CPU 工作 处理器 原理 ARM
1. 大致感受一下 CPU (Central Processing Unit)是什么
- 家用电脑里的 Intel , AMD 处理器
- 手机里,高通的骁龙处理器,三星的Exynos,华为的麒麟,千元机的 MTK(台湾联发科技,MediaTek);苹果的 A12。
- 商用电脑 Intel

Major parts of a CPU
上图中,你可以看到,CPU 里有两部分:
- 一部分叫做 Control Unit,负责控制,比如计数器,指令寄存等等。
- 一部分叫做 Logic Unit,负责运算,比如加法器,累加器,等等。有些也会把“数据总线”归于逻辑运算单元里。
- 其实 CPU里还有存储单元等其他单元,比如 L1,L2,L3 Cache 等等。
输入设备就是 鼠标,键盘,触控板,触摸屏等, 用户通过这些东西对电脑进行输入指令,CPU识别指令后进行运算,进行输出,一般输出给了屏幕。 在这里举一个例子:用户通过触摸屏,对手机进行操作,比如说点击播放音乐,CPU接收到指令后,命令 DAC(Digital-to-Analog Converter)解码,扬声器接收到音频信号进行播放,屏幕显示歌词。
CPU 就类似于一个管理者,他不去做“苦力”活,让更专业的人去做更专业的事。这样就能最大程度上的提高了 整个系统的效率。CPU 虽然叫做 中央处理器,所以它不仅仅是处理,而是对一些更基本的处理器进行控制:
“苦力活”指的是 CPU 并没有驱动大电流的能力,比如安装好‘驱动软件‘之后,CPU就可以和显示屏上的处理器就行沟通,显示屏上的处理器再来控制显示屏的‘驱动电路’ (Driver),驱动电路驱动显示屏显示图案。在工业上,苦力活用 PLC[1]来控制。一般的,PLC 会受到更上层 CPU 的控制。
更为专业的工作指的是:比如图形处理会交给 GPU [2]来做;音频的解码交给‘声卡’ [3]AD/DA; 更为高级的音频处理,比如说“降噪耳机”就需要一种叫做 DSP(Digital Signal Processor)[4]进行处理;在为复杂一些的处理,比如说苹果笔记本上的触摸板会有一个专门识别触摸的芯片,叫单片机[5]。新的 MAC PRO 加入了 FPGA(Field-Programmable Gate Array) [6]视频剪辑卡,可以做到 3条8K 视频同时剪辑。
computer architecture计算机的架构[7](ISA,Instruction Set Architecture)是一个非常宽泛的概念:
- Instruction Set Architecture 指令集架构(ISA)[8](精简指令集(Reduced instruction set computing,RISC),复杂指令集(Complex Instruction Set Computer,CISC))
- Microarchitecture 微架构 [9]( 比如 L123 cache)
2. CPU 的命名——通俗易懂,商业目的
最简单的例子就是苹果的 A(APPLE) 系列处理器,手机上用的就是 A10,A12;iPad上用的就是 A12X[10];手表上用的就是 S(Syetem in Package SiP)等等[11]
Intel 的稍微复杂一点,看下图[12]:
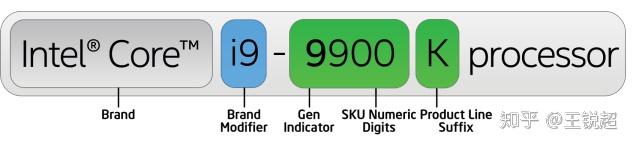
文中大量引用了 Intel core i9-9900K 的原因是由于它的相关信息比较全,比较容易拿过来讲解。
- Brand -- 商标
- Brand Modifier, 产品型号,比如i3, i5, i7, i9
- Gen Indicator, 产品代,比如2019年是第九代产品,2020年初就会更新第十代产品。这个代不仅代表了它的制程工艺,也代表了它的架构
- SKU(Stock Keeping Unit), 这个如果是小白就直接理解为越大越好。比如我可以负责任的告诉你,9980XE[13],性能上是要比 9900K 要好很多的
- Suffix,后缀,这里一般都是标明 芯片是否能够超频,电压是标压还是低压
3. CPU 的外形,接口,封装[14]
3.1 封装
整个芯片其实非常非常小,我们外界能看到的产品是对他进行封装好之后的效果,封装当然是主要为了保护芯片,但还有一个很重要的作用就是为了更好的和外界进行沟通(交换信息)。随着封装技术的发展,芯片引脚的密度越来越大,芯片集成程度越来越高。我放几张图,让大家看一下科技的进步把:
最经典的封装方法:Dual in-line package,DIP(双列直插封装)[15],学过数电的都接触过这种封装的芯片,这种芯片一般都是有引脚的。
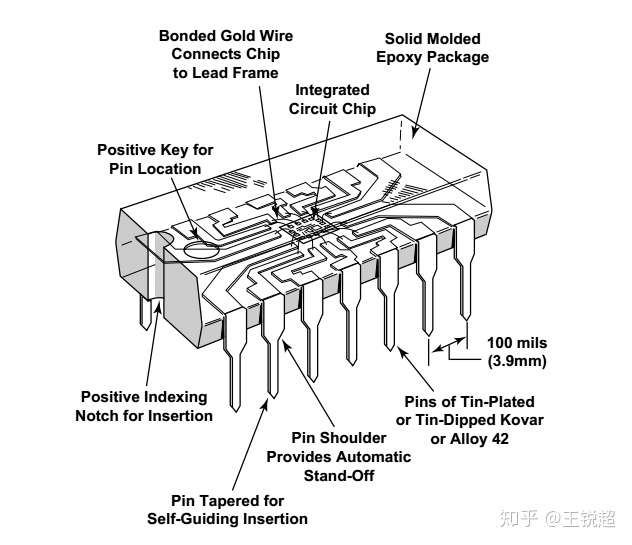
Dual in-line package,这也是早期的芯片封装方式
芯片引脚插入电路,和这种封装配套的技术叫做:“Through-hole technology“[16]当然这个电路穿孔技术在集成电路里还有另一层意思,比如 3D NAND RAM 里面的穿层技术(这个讲到 Flash 的时候会讲)
DIP 封装是不能满足芯片引脚数目的提高的,此时就有了密度更大的封装方式。PC CPU 里,目前最为复杂的封装方法就是这样的:i9-9900K FCLGA-1151 (LGA) 封装方法[17],每一个金黄色的点,都是 CPU 和外界进行联系的方式,每一个引脚的功能和使用方法可以查 data sheet 。

Intel core i9-9900K FCLGA-1151 (LGA)
随着系统的设计复杂,之前的封装结构已经不能满足了,于是就有了更为复杂的封装结构:System on a chip,SoC[18],Soc 我会在下一小节的 芯片结构里面用 A12X [10]作为解释。追求更高电路密度的方法就是 Package on package ‘叠电路’[19],但是由于散热问题反而效果并不特别好,举例就是 iPhone X 的双层电路板结构[20]。而目前追求电路复杂程度的极致,叫做 System in package, SiP[21],把整块电路版想办法做到一起,比如 Apple watch 4 的 S4 芯片[22]。

S4 来源 ifixit
3.2 总线——CPU 与外部沟通
想要理解CPU是怎么和外界进行沟通的,我们可以查看相对应的 CHIPSET ---Z390[23]来大概感受一下:
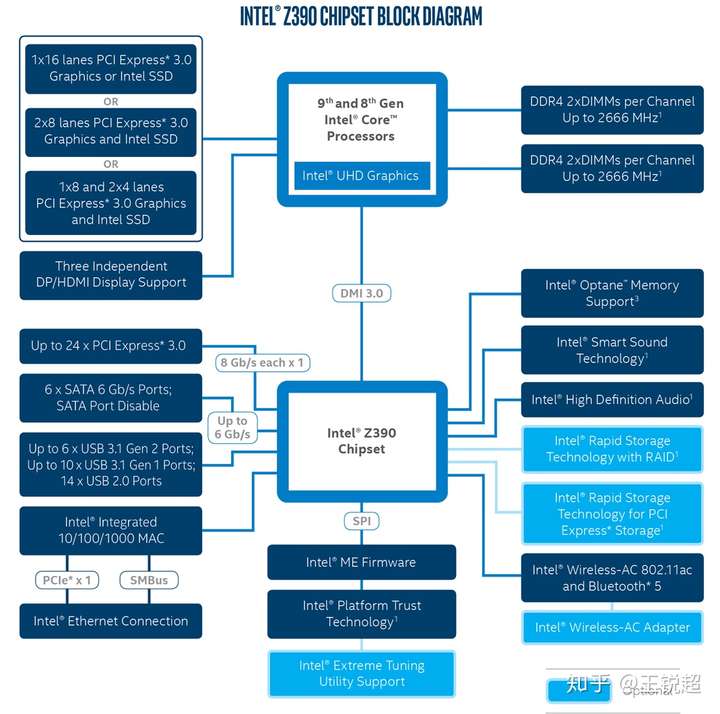
- 看图右上角,CPU 与 DDR4 是直接相连
- 图左上角,一共 16条 PCIe(Peripheral Component Interface Express),可以分给SSD也可以分给显卡(一般这里分给显卡,SSD接在 Chipset 分出来的24条 PCIe)
- 左上往下看,3个DP口
- DMI 3.0总线,接 Chipset,之后进行细分,比如直接与 Optane 存储相连。
- ······
- Double Port (DP) uses a PCIe 3.0 ×4 link to provide two Thunderbolt 3 ports (DSL6540, JHL6540, JHL7540)
- Single Port (SP) uses a PCIe 3.0 ×4 link to provide one Thunderbolt 3 port (DSL6340, JHL6340, JHL7340)
- Low Power (LP) uses a PCIe 3.0 ×2 link to provide one Thunderbolt 3 port (JHL6240).
4. Computer Architecture 系统架构
4.1 架构到底是什么?[26]复杂指令集(CISC)和精简指令集(RISC)是什么?[27]
CPU的这两大架构:ARM和X86
要了解X86和ARM,就得先了解复杂指令集(CISC)和精简指令集(RISC)
从CPU发明到现在,有非常多种架构,从我们熟悉的X86,ARM,到不太熟悉的MIPS,IA64,它们之间的差距都非常大。但是如果从最基本的逻辑角度来分类的话,它们可以被分为两大类,即所谓的“复杂指令集”与“精简指令集”系统,也就是经常看到的“CISC”与“RISC”。 Intel和ARM处理器的第一个区别是,前者使用复杂指令集(CISC),而后者使用精简指令集(RISC)。属于这两种类中的各种架构之间最大的区别,在于它们的设计者考虑问题方式的不同。
我们可以继续举个例子,比如说我们要命令一个人吃饭,那么我们应该怎么命令呢?我们可以直接对他下达“吃饭”的命令,也可以命令他“先拿勺子,然后舀起一勺饭,然后张嘴,然后送到嘴里,最后咽下去”。从这里可以看到,对于命令别人做事这样一件事情,不同的人有不同的理解,有人认为,如果我首先给接受命令的人以足够的训练,让他掌握各种复杂技能(即在硬件中实现对应的复杂功能),那么以后就可以用非常简单的命令让他去做很复杂的事情——比如只要说一句“吃饭”,他就会吃饭。但是也有人认为这样会让事情变的太复杂,毕竟接受命令的人要做的事情很复杂,如果你这时候想让他吃菜怎么办?难道继续训练他吃菜的方法?我们为什么不可以把事情分为许多非常基本的步骤,这样只需要接受命令的人懂得很少的基本技能,就可以完成同样的工作,无非是下达命令的人稍微累一点——比如现在我要他吃菜,只需要把刚刚吃饭命令里的“舀起一勺饭”改成“舀起一勺菜”,问题就解决了,多么简单。这就是“复杂指令集”和“精简指令集”的逻辑区别。
从几个方面比较ARM与X86架构
Intel和ARM的处理器除了最本质的复杂指令集(CISC)和精简指令集(RISC)的区别之外,下面我们再从以下几个方面对比下ARM和X86架构。
一、制造工艺
ARM和Intel处理器的一大区别是ARM从来只是设计低功耗处理器,Intel的强项是设计超高性能的台式机和服务器处理器。
一直以来,Intel都是台式机的服务器行业的老大。然而进入移动行业时,Intel依然使用和台式机同样的复杂指令集架构,试图将其硬塞入给移动设备使用的体积较小的处理器中。但是Intel i7处理器平均发热率为45瓦。基于ARM的片上系统(其中包括图形处理器)的发热率最大瞬间峰值大约是3瓦,约为Intel i7处理器的1/15。其最新的Atom系列处理器采用了跟ARM处理器类似的温度控制设计,为此Intel必须使用最新的22纳米制造工艺。一般而言,制造工艺的纳米数越小,能量的使用效率越高。ARM处理器使用更低的制造工艺,拥有类似的温控效果。比如,高通晓龙805处理器使用28纳米制造工艺。
二、64位计算
对于64位计算,ARM和Intel也有一些显著区别。Intel并没有开发64位版本的x86指令集。64位的指令集名为x86-64(有时简称为x64),实际上是AMD设计开发的。Intel想做64位计算,它知道如果从自己的32位x86架构进化出64位架构,新架构效率会很低,于是它搞了一个新64位处理器项目名为IA64。由此制造出了Itanium系列处理器。
同时AMD知道自己造不出能与IA64兼容的处理器,于是它把x86扩展一下,加入了64位寻址和64位寄存器。最终出来的架构,就是 AMD64,成为了64位版本的x86处理器的标准。IA64项目并不算得上成功,现如今基本被放弃了。Intel最终采用了AMD64。Intel当前给出的移动方案,是采用了AMD开发的64位指令集(有些许差别)的64位处理器。

而ARM在看到移动设备对64位计算的需求后,于2011年发布了ARMv8 64位架构,这是为了下一代ARM指令集架构工作若干年后的结晶。为了基于原有的原则和指令集,开发一个简明的64位架构,ARMv8使用了两种执行模式,AArch32和AArch64。顾名思义,一个运行32位代码,一个运行64位代码。ARM设计的巧妙之处,是处理器在运行中可以无缝地在两种模式间切换。这意味着64位指令的解码器是全新设计的,不用兼顾32位指令,而处理器依然可以向后兼容。
三、异构计算
ARM的big.LITTLE架构是一项Intel一时无法复制的创新。在big.LITTLE架构里,处理器可以是不同类型的。传统的双核或者四核处理器中包含同样的2个核或者4个核。一个双核Atom处理器中有两个一模一样的核,提供一样的性能,拥有相同的功耗。ARM通过big.LITTLE向移动设备推出了异构计算。这意味着处理器中的核可以有不同的性能和功耗。当设备正常运行时,使用低功耗核,而当你运行一款复杂的游戏时,使用的是高性能的核。
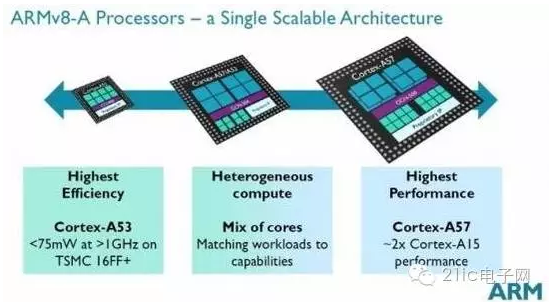
这是什么做到的呢?设计处理器的时候,要考虑大量的技术设计的采用与否,这些技术设计决定了处理器的性能以及功耗。在一条指令被解码并准备执行时,Intel和ARM的处理器都使用流水线,就是说解码的过程是并行的。
为了更快地执行指令,这些流水线可以被设计成允许指令们不按照程序的顺序被执行(乱序执行)。一些巧妙的逻辑结构可以判断下一条指令是否依赖于当前的指令执行的结果。Intel和ARM都提供乱序执行逻辑结构,可想而知,这种结构十分的复杂,复杂意味着更多的功耗。
Intel处理器由设计者们选择是否加入乱序逻辑结构。异构计算则没有这方便的问题。ARM Cortex-A53采用顺序执行,因此功耗低一些。而ARM Cortex-A57使用乱序执行,所以更快但更耗电。采用big.LITTLE架构的处理器可以同时拥有Cortex-A53和Cortex-A57核,根据具体的需要决定如何使用这些核。在后台同步邮件的时候,不需要高速的乱序执行,仅在玩复杂游戏的时候需要。在合适的时间使用合适的核。
此外,ARM具有其与X86架构电脑不可对比的优势,该优势就是:功耗。
其实它们的功耗主要是由这几点决定的。首先,功耗和工艺制程相关。ARM的处理器不管是哪家主要是靠台积电等专业制造商生产的,而Intel是由自己的工厂制造的。一般来说后者比前者的工艺领先一代,也就是2-3年。如果同样的设计,造出来的处理器应该是Intel的更紧凑,比如一个是22纳米,一个是28纳米,同样功能肯定是22纳米的耗电更少。
那为什么反而ARM的比X86耗电少得多呢。这就和另外一个因素相关了,那就是设计。
设计又分为前端和后端设计,前端设计体现了处理器的构架,精简指令集和复杂指令集的区别是通过前端设计体现的。后端设计处理电压,时钟等问题,是耗电的直接因素。先说下后端怎么影响耗电的。我们都学过,晶体管耗电主要两个原因,一个是动态功耗,一个是漏电功耗。动态功耗是指晶体管在输入电压切换的时候产生的耗电,而所有的逻辑功能的0/1切换,归根结底都是时钟信号的切换。如果时钟信号保持不变,那么这部分的功耗就为0。这就是所谓的门控时钟(Clock Gating)。而漏电功耗可以通过关掉某个模块的电源来控制(Power Gating)。当然,其中任何一项都会使得时钟和电源所控制的模块无法工作。他们的区别在于,门控时钟的恢复时间较短,而电源控制的时间较长。此外,如果条单条指令使用多个模块的功能,在恢复功能的时候,并不是最慢的那个模块的时间,而可能是几个模块时间相加,因为这牵涉到一个上电次序(Power Sequence)的问题,也就是恢复工作时候模块间是有先后次序的,不遵照这个次序,就无法恢复。而遵照这个次序,就会使得总恢复时间很长。所以在后端这块,可以得到一个结论,为了省电,可以关闭一些暂时不会用到的处理器模块。但是也不能轻易的关闭,否则一旦需要,恢复的话会让完成某个指令的时间会很长,总体性能显然降低。此外,子模块的门控时钟和电源开关通常是设计电路时就决定的,对于操作系统是透明的,无法通过软件来优化。
再来看前端。ARM的处理器有个特点,就是乱序执行能力不如X86。换句话说,就是用户在使用电脑的时候,他的操作是随机的,无法预测的,造成了指令也无法预测。X86为了增强对这种情况下的处理能力,加强了乱序指令的执行。此外,X86还增强了单核的多线程能力。这样做的缺点就是,无法很有效的关闭和恢复处理器子模块,因为一旦关闭,恢复起来就很慢,从而造成低性能。为了保持高性能,就不得不让大部分的模块都保持开启,并且时钟也保持切换。这样做的直接后果就是耗电高。而ARM的指令强在确定次序的执行,并且依靠多核而不是单核多线程来执行。这样容易保持子模块和时钟信号的关闭,显然就更省电。
此外,在操作系统这个级别,个人电脑上通常会开很多线程,而移动平台通常会做优化,只保持必要的线程。这样使得耗电差距进一步加大。当然,如果X86用在移动平台,肯定也会因为线程少而省电。凌动系列(ATOM)专门为这些特性做了优化,在一定程度上降低乱序执行和多线程的处理能力,从而达到省电。
现在移动处理器都是片上系统(SoC)架构,也就是说,处理器之外,图形,视频,音频,网络等功能都在一个芯片里。这些模块的打开与关闭就容易预测的多,并且可以通过软件来控制。这样,整体功耗就更加取决于软件和制造工艺而不是处理机架构。在这点上,X86的处理器占优势,因为Intel的工艺有很大优势,而软件优化只要去做肯定就可以做到。
ARM和X86现在发展如何?
关于X86架构和ARM架构这两者谁将统一市场的争执一直都有,但是也有人说这两者根本不具备可比性,X86无法做到ARM的功耗,而ARM也无法做到X86的性能。现在ARM架构已经具备了进入服务器芯片的能力,众多芯片研发企业纷纷采用ARM架构研发服务器芯片无疑将促进其繁荣, 2015年一款采用ARM架构的Windows 10平板现身,这也是目前曝光的全球首款非X86架构、运行Windows系统的平板产品。
同时,经过数年的努力,2016年AMD终于推出了首个基于ARM架构的处理器——Opteron A1100。AMD希望能够凭借这一处理器挑战Intel在数据中心服务器市场的霸主地位。
这样看来,Intel在服务器芯片市场将会逐渐失去霸主地位,而且,Intel已然错过了移动 CPU 市场,现在它正试图跳进千万亿的物联网领域,具体表现如何,看时间的考验吧。
RISC(精简指令集计算机)和CISC(复杂指令集计算机)的区别
RISC(精简指令集计算机)和CISC(复杂指令集计算机)是当前CPU的两种架构。它们的区别在于不同的CPU设计理念和方法。
CPU架构是厂商给属于同一系列的CPU产品定的一个规范,主要目的是为了区分不同类型CPU的重要标示
早期的CPU全部是CISC架构,它的设计目的是要用最少的机器语言指令来完成所需的计算任务。比如对于乘法运算,在CISC架构的CPU上,您可能需要这样一条指令:MUL ADDRA, ADDRB就可以将ADDRA和ADDRB中的数相乘并将结果储存在ADDRA中。将ADDRA, ADDRB中的数据读入寄存器,相乘和将结果写回内存的操作全部依赖于CPU中设计的逻辑来实现。这种架构会增加CPU结构的复杂性和对CPU工艺的要求,但对于编译器的开发十分有利。比如上面的例子,C程序中的a*=b就可以直接编译为一条乘法指令。今天只有Intel及其兼容CPU还在使用CISC架构。
RISC架构要求软件来指定各个操作步骤。上面的例子如果要在RISC架构上实现,将ADDRA, ADDRB中的数据读入寄存器,相乘和将结果写回内存的操作都必须由软件来实现,比如:MOV A, ADDRA; MOV B, ADDRB; MUL A, B; STR ADDRA, A。这种架构可以降低CPU的复杂性以及允许在同样的工艺水平下生产出功能更强大的CPU,但对于编译器的设计有更高的要求。
复杂指令集计算机(CISC)
长期来,计算机性能的提高往往是通过增加硬件的复杂性来获得.随着集成电路技术.特别是VLSI(超大规模集成电路)技术的迅速发展,为了软件编程方便和提高程序的运行速度,硬件工程师采用的办法是不断增加可实现复杂功能的指令和多种灵活的编址方式.甚至某些指令可支持高级语言语句归类后的复杂操作.至使硬件越来越复杂,造价也相应提高.为实现复杂操作,微处理器除向程序员提供类似各种寄存器和机器指令功能外.还通过存于只读存贮器(ROM)中的微程序来实现其极强的功能 ,好处理在分析每一条指令之后执行一系列初级指令运算来完成所需的功能,这种设计的型式被称为复杂指令集计算机(Complex Instruction Set Computer-CISC)结构.一般CISC计算机所含的指令数目至少300条以上,有的甚至超过500条.
精简指令集计算机(RISC)
采用复杂指令系统的计算机有着较强的处理高级语言的能力.这对提高计算机的性能是有益的.当计算机的设计沿着这条道路发展时.有些人没有随波逐流.他们回过头去看一看过去走过的道路,开始怀疑这种传统的做法:IBM公司没在纽约Yorktown的JhomasI.Wason研究中心于1975年组织力量研究指令系统的合理性问题.因为当时已感到,日趋庞杂的指令系统不但不易实现.而且还可能降低系统性能.1979年以帕特逊教授为首的一批科学家也开始在美国加册大学伯克莱分校开展这一研究.结果表明,CISC存在许多缺点.首先.在这种计算机中.各种指令的使用率相差悬殊:一个典型程序的运算过程所使用的80%指令.只占一个处理器指令系统的20%.事实上最频繁使用的指令是取、存和加这些最简单的指令.这样一来,长期致力于复杂指令系统的设计,实际上是在设计一种难得在实践中用得上的指令系统的处理器.同时.复杂的指令系统必然带来结构的复杂性.这不但增加了设计的时间与成本还容易造成设计失误.此外.尽管VLSI技术现在已达到很高的水平,但也很难把CISC的全部硬件做在一个芯片上,这也妨碍单片计算机的发展.在CISC中,许多复杂指令需要极复杂的操作,这类指令多数是某种高级语言的直接翻版,因而通用性差.由于采用二级的微码执行方式,它也降低那些被频繁调用的简单指令系统的运行速度.因而针对CISC的这些弊病.帕特逊等人提出了精简指令的设想即指令系统应当只包含那些使用频率很高的少量指令.并提供一些必要的指令以支持操作系统和高级语言.按照这个原则发展而成的计算机被称为精简指令集计算机(Reduced Instruction Set Computer-RISC)结构.简称RISC.
CISC与RISC的区别
我们经常谈论有关"PC"与"Macintosh"的话题,但是又有多少人知道以Intel公司X86为核心的PC系列正是基于CISC体系结构,而 Apple公司的Macintosh则是基于RISC体系结构,CISC与RISC到底有何区别?
从硬件角度来看CISC处理的是不等长指令集,它必须对不等长指令进行分割,因此在执行单一指令的时候需要进行较多的处理工作。而RISC执行的是等长精简指令集,CPU在执行指令的时候速度较快且性能稳定。因此在并行处理方面RISC明显优于CISC,RISC可同时执行多条指令,它可将一条指令分割成若干个进程或线程,交由多个处理器同时执行。由于RISC执行的是精简指令集,所以它的制造工艺简单且成本低廉。
从软件角度来看,CISC运行的则是我们所熟识的DOS、Windows操作系统。而且它拥有大量的应用程序。因为全世界有65%以上的软件厂商都理为基于CISC体系结构的PC及其兼容机服务的,象赫赫有名的Microsoft就是其中的一家。而RISC在此方面却显得有些势单力薄。虽然在RISC上也可运行DOS、Windows,但是需要一个翻译过程,所以运行速度要慢许多。
目前CISC与RISC正在逐步走向融合,Pentium Pro、Nx586、K5就是一个最明显的例子,它们的内核都是基于RISC体系结构的。他们接受CISC指令后将其分解分类成RISC指令以便在遇一时间内能够执行多条指令。由此可见,下一代的CPU将融合CISC与RISC两种技术,从软件与硬件方面看二者会取长补短。
复杂指令集CPU内部为将较复杂的指令译码,也就是指令较长,分成几个微指令去执行,正是如此开发程序比较容易(指令多的缘故),但是由于指令复杂,执行工作效率较差,处理数据速度较慢,PC 中 Pentium的结构都为CISC CPU。
RISC是精简指令集CPU,指令位数较短,内部还有快速处理指令的电路,使得指令的译码与数据的处理较快,所以执行效率比CISC高,不过,必须经过编译程序的处理,才能发挥它的效率,我所知道的IBM的 Power PC为RISC CPU的结构,CISCO 的CPU也是RISC的结构。
咱们经常见到的PC中的CPU,Pentium-Pro(P6)、Pentium-II,Cyrix的M1、M2、AMD的K5、K6实际上是改进了的CISC,也可以说是结合了CISC和RISC的部分优点。
RISC与CISC的主要特征对比
4.2 ARM(RISC)省电么?[28][29]
实验对象
X86方面有两位选手出场,分别是代表Core的2700和代表Atom的N450;ARM方面也有两位选手出场,分别是A8和A9。
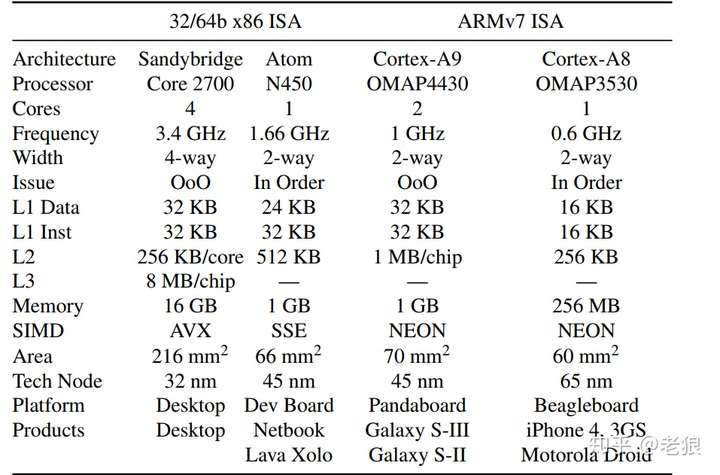
作者选取这两组可谓精心。每方面都有顺序执行和乱序执行的选手。主频也大小不一。
实验手段
测试的workload也精心做了选择:
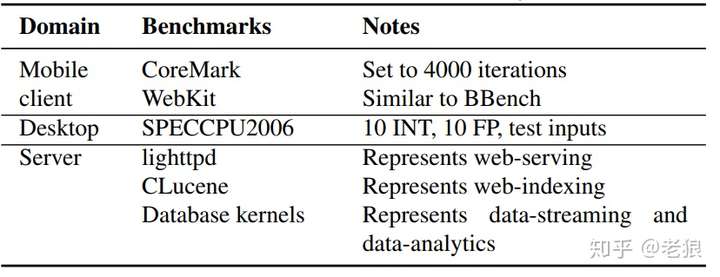
既有Mobile的,也有Server的;在台式机方面,选择权威的SPEC CPU2006来测试,分别测试了INT和FP。
测试的挑战
如果我们仔细观察测试对象,会发现它们大不相同,为了能够公平的比较它们,必须剔除掉那些变量,只保留ISA和微结构的影响。这些需要剔除的变量包括:制程、频率、主板和其他元器件耗能等等。其中制程和频率的剔除比较麻烦,因为他们不是线性的关系。作者也是煞费苦心,采用查表等办法来规避。详细内容见参考资料1。
为了让结果清楚,作者采取了归一化(Normalization)的方法。所谓归一化,简单理解就是设其中某个量是1,其他按照比例是多少。这个我们一会看结果会用到。
实验结果
平均能耗结果归一到A8上,因为A8能耗最低:
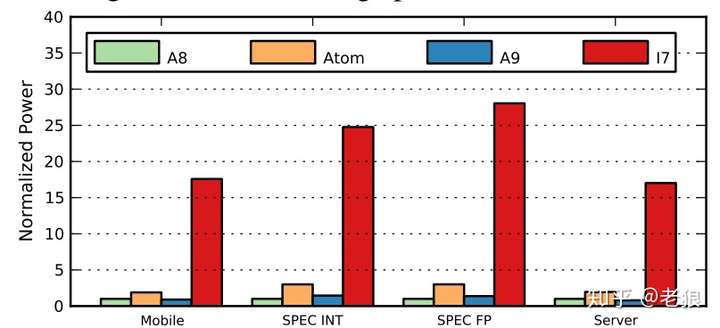
可以看到i7高高在上,比其他高出一大截。如前面所述,我们要剔除掉制程、频率等无关变量。那么剔除掉之后怎么样了呢?还是归一到A8:
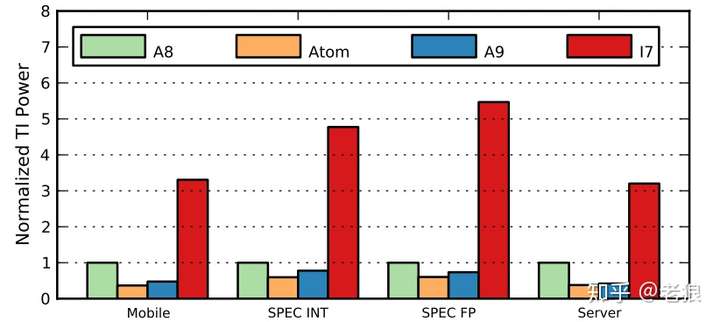
从中可以看出A8的内耗虽然比i7小,但比A9和Atom要高不少。这就是结论吗?不是,因为这是平均能耗,而我们要看整体功耗,即干一件事情总体要消耗多少能量。那就是
整体能耗(能耗效率)= 平均能耗 X 所需时间:
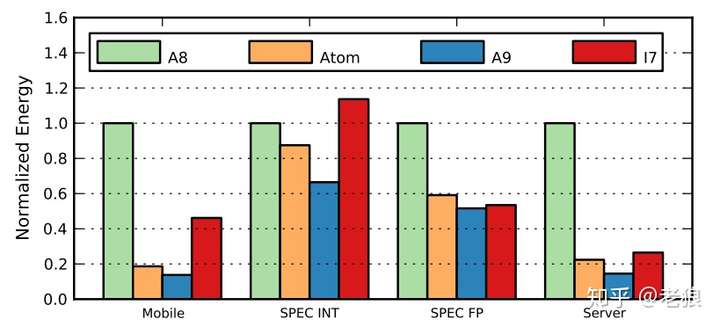
结果还是归一化到A8上面。这个结果就很有意思了,与绝大多数人认为的不同,ARM A8恰恰是能耗效率最差的那个,尤其在服务器领域,只有在SPEC整数测试中比i7略好。而A9则是最好的。ATOM在除了在浮点测试中,其他情况下都比i7要好。
结论
我们看最后看看能源效率和性能Performance的Trade-offs图:
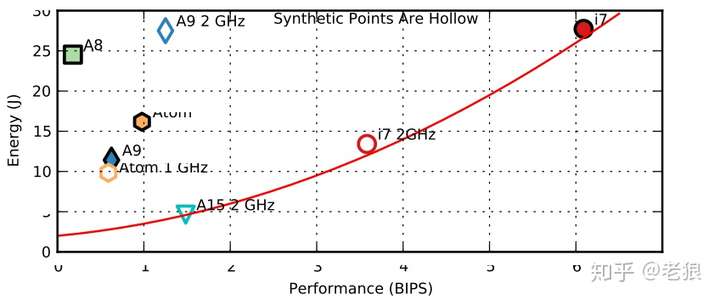
A8高耗能低性能,十分糟糕;i7高性能高耗能;A9和Atom取得了平衡。
当然我并不是建议大家都用Atom或者A9去取代i7,而是要打破一种ISA决定能耗效率的迷思。实际上ISA对能耗效率影响不大,而更多的取决于微架构如是否乱序执行等等。我们今天看到的ARM占据低端低功耗,X86占据高端高功耗更多的是ecosystem和历史习惯影响,随着ARM和X86各自拿出高功耗和低功耗产品,市场还在演进中。就像《终结者》中的一句名言:未来尚未决定,一切仍是未知之数,命运的种子依旧掌握在我们的手中!
参考资料:
[1]: https://research.cs.wisc.edu/ve
4.3 性能差别大么?[30]
说x86和ARM处理器“实际执行效果差不多”其实有所不妥。楼主也说了比较的几个设备主要是windows平板,ipad和智能手机。这些平台上的程序都是移动环境下的应用,大多逻辑简单功能单一,没什么“计算”可言。ARM处理器本身定位于嵌入式平台,应付轻量级、目的单一明确的程序,现在应用在移动设备上正是得心应手。x86定位于桌面和服务器,这些平台上很多应用是计算密集型的,比如多媒体编辑、科研计算、模拟等等。因此将x86和ARM在移动环境下做对比得出“差不多”是不好的。
由于定位的不同,ARM处理器基于精简指令集(RISC)架构。指令集数量少就可以简化硬件逻辑的设计,减少晶体管数量,也就意味着低功耗。而且由于移动平台应用通常简单,程序的控制流不复杂,执行效率没有必要很高,所以流水线、分支预测等硬件逻辑都比较简单。这些都降低了晶体管总量。同时因为移动设备有电池的能源限制,ARM的电源管理是作为重要部分特别设计了的。比如移动设备的处理器在待机时通常只以极低的主频在运行,甚至可以暂时关闭闲置的核心、协处理器来降低功耗。
x86就截然不同。x86是复杂指令集(CISC)架构,存在很多机器指令,只为了高效地完成一项专门任务(比如MMX, SSE中的指令)。这就使得硬件的逻辑很复杂,晶体管数量庞大。为了高效地进行运算,x86架构有较长的流水线以达到指令级并行(ILP)。长流水线带来的一个弊端,就是当遇到分支时,如果预载入分支指令不是未来真实的分支,那么要清空整个流水,代价较高。所以x86为此还必须有复杂的分支预测机构,确保流水线的效率。再加上多级cache,支持超线程、虚拟化等等,x86的复杂度其实相当高。
4.4 谁是未来?[31]
ARM vs. x86 不是一个技术问题,而是一个商业问题。为什么这么说呢?且听我细细分解:
首先,「x86 比 ARM 功耗高」这一点,在事实上已经不再成立了,具体的数据和分析可以参考 [1]。文章比较长,数据也很多,如果没空看也没关系,看看最后一页的这张表就行了:
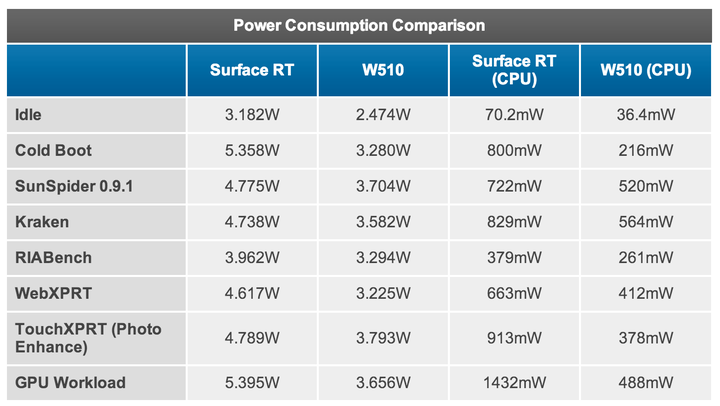
这里比较的是两个平板设备:采用 NVIDIA Tegra 3 (40nm ARM 处理器) 的 Microsoft Surface RT 平板电脑和采用 Intel Clover Trail Atom (32nm x86 处理器) 的 Acer W510 平板电脑。可以看到,每一个测试项目中 Atom 的功耗都比 Tegra 3 低不少。这还不是最要命的,更要命的是 Atom 的性能比 Tegra 3 高,也就是说 Atom 可以在更短的时间内完成同样的任务然后进入低功耗休眠状态以节省电力,而且在休眠状态下 Atom 的功耗也只有 Tegra 3 的差不多一半。
当然,Atom 并不能完全代表 x86 处理器,Tegra 3 也只是诸多 ARM 处理器中比较费电的一款,但这个例子的教育意义在于它打破了传统上认为「ARM 比 x86 省电」的迷思:没错,在对性能要求不高的情况下,ARM 的确比 x86 省电,因为 ARM 天生就是为低功耗这一目标打造的;但随着应用的不断深入,人们对移动设备的性能要求越来越高,目前在高端平板【或者说普通笔记本替代品】这个尺度的应用上以 Atom 为代表的 x86 处理器已经具有相当的功耗优势。假以时日,在给定性能基础上 x86 做到比 ARM 功耗更低并不存在太大技术上的障碍。
其次,处理器功耗只是整个设备功耗的一部分,甚至不是最主要的部分,特别是在触屏移动设备上还有屏幕、无线通讯模块这样的耗能大户。比如从上面那张表可以看出,处理器的功耗占总功耗的比例,在绝大多数情况下都不超过 20%,实际使用场合下的功耗占比更是会低于 10%【处理器大部分时候在休眠】。技术的进步可以相对快速的降低处理器的功耗,但由于物理规律的限制【比如屏幕始终需要维持足够的亮度、无线通讯始终是需要发射足够强的电磁波】,设备上的其他耗能大户功耗降低的幅度要小得多。这就意味着单纯削减处理器功耗以延长续航时间的边际效用会越来越小,到一定程度后对整个设备的续航时间的影响变得微乎其微、花大成本提高处理器功耗的回报太低以至于不经济。Intel 的下一代平台 Haswell 之所以要强调全平台的低功耗也部分是出于这个原因。当然目前我们还没有到那个时候,现在还不用操心这个,但要记住这一点。
————技术/商业分割线————
好了,如果现在你和我一样相信 Intel 有能力在功耗和性能上都战胜 ARM,为什么现在绝大部分移动设备采用的是 ARM 而不是 x86 处理器呢?或者说为什么 Intel 会在移动市场上如此「失败」呢?
因为 ARM 代表的产业模式对于 Intel 而言是一场商业灾难。
Intel 这么多年习惯的模式是生产制造几十、几百美元的处理器,在这个价位上的生产制造毛利率高得吓人。而正是丰厚的毛利率使得 Intel 敢于付出高昂的代价研发下一代处理器技术和生产线制程,从而保持领先竞争对手至少一个代际的技术优势。比如现在 Intel 的主流 Core 系列的制程是 22nm,同时期的 ARM 还处于 40nm 到 32nm 或者 32nm 到 28nm 的过渡阶段,而 Intel 已经在新建 14nm 的生产线了。
反观一片 ARM 处理器才卖几美元,利润率微薄,即便出货量大不少【不要忘了出货量和生产线投入之间的准线性关系】,却也不能满足 Intel 这样的巨鳄【巨饿?XD】的胃口,更不能让它保持目前的「高研发/高毛利相互驱动」的商业模式。不玩自家的游戏规则,Intel 沦为二三流厂商那是分分钟可能发生的危险。Intel 管理层不希望看到这个未来,Intel 的股东们更不希望。
另外,移动 SoC 市场中公司之间的合作模式也不适合 Intel。为了节省制造成本和降低功耗,移动 SoC 经常需要集成多家厂商的 IP 块于一片上,那么两个问题就随之而来了:1) Intel 会不会授权自己的 IP 块给其他厂商,比如苹果?这可不是 Intel 擅长的,因为授权设计的收入比销售最终产品的收入要低得多;2) 最终生产的时候用谁的生产线?Intel 可不会白白的让出自己投入巨资研发制造的最新制程的生产线给别人用;就算 Intel 愿意,别人也不见得用得起,毕竟有低毛利率的限制。而 ARM 则没有这些顾虑:ARM 设计和生产是分离的,设计的 IP 块可以单独授权给各家厂商自行定制整合,而制造采用的是比较成熟的生产线,成本低、可选厂家也多。
这就是为什么 Intel 在移动领域涉足很晚也很勉强、为什么功耗低、单价更低的 Atom 处理器始终比最先进的 Core 处理器落后一两代的原因。非不能也,乃不为也;因何不为?利益使然尔!
然而市场现实是台式机、笔记本的出货量稳步下降,Intel 寄予厚望的 Ultrabook 不成气候也没能让笔记本市场死灰复燃;与此同时,移动设备份额稳步飙升,ARM 处理器的性能在多数场合都能满足需求【good enough】,甚至有威胁 Intel 在服务器市场的潜能。这一切都迫使 Intel 不得不面对 ARM 这个难题;而这个难题的主要症结不在于技术,而在于 Intel 能不能否定自我、推倒重来。
[1]: AnandTech - The x86 Power Myth Busted: In-Depth Clover Trail Power Analysis
5. 芯片结构
设计芯片时会考虑到芯片的用途,根据用途而设计芯片。比如为了自动驾驶,那么肯定我们需要更多的神经网络处理 NPU,CPU选取 Cortex-A72[32][33]。下面我举几个例子,来感受一下内部结构的区别。
5.1 :X86,Intel Coffee Lake[34][35]
这个芯片,就是非常单纯的,性能至上的芯片。
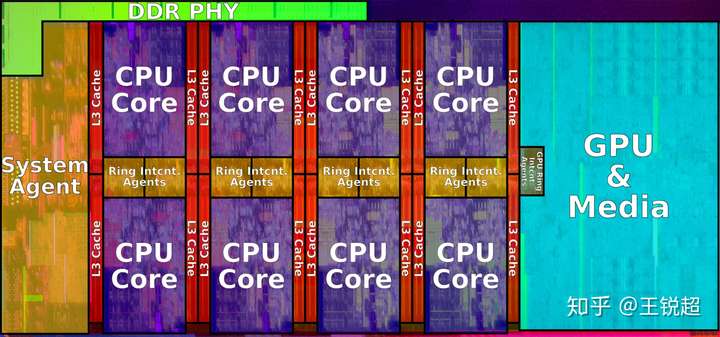
Intel core i9-9900K
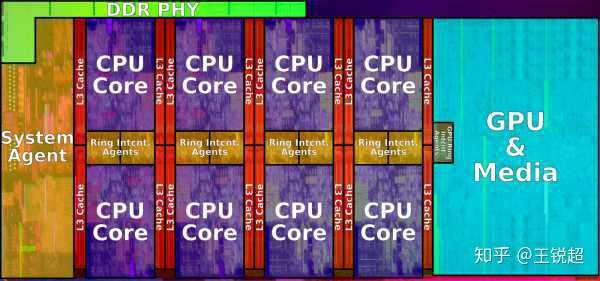
如果拿放大镜去看,就可以看到CPU 内部长这个样子,当然图中的颜色都是为了方便大家看清楚是干啥的专门上色的哈。从图中可以看到,芯片中间紫色部分是 8个 CPU核心(俗称8核 i9),8个核心 share 红色的 L3 cache;左边蓝色的是‘核显’ Intel® UHD Graphics 630,System Agent 是负责和外部进行沟通的。为了更方便的理解每一部分是做什么的,请看下面两张图:
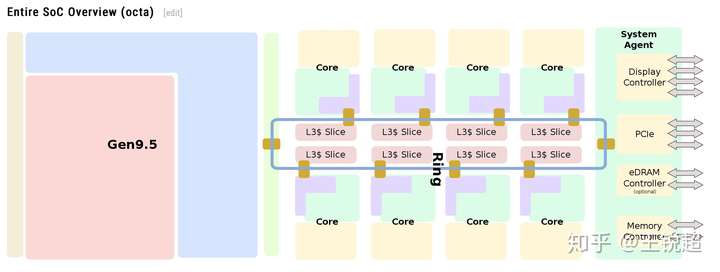
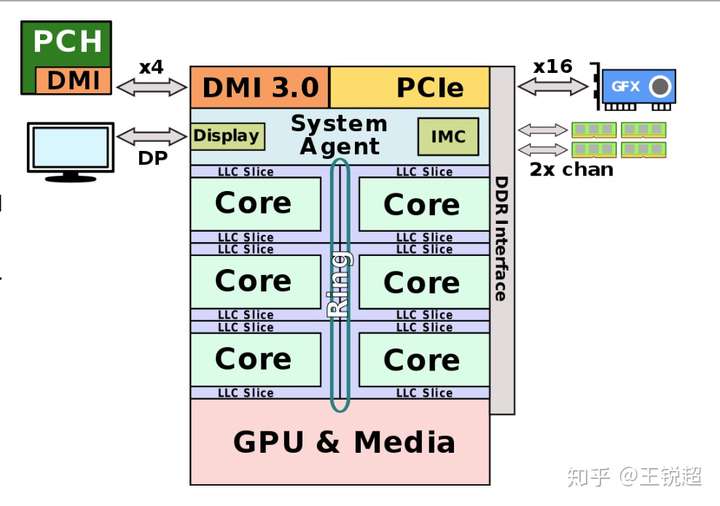
注:图中是一个 6核心的展示图
每一个‘core‘内部结构我就不展示了,感兴趣戳这里[36]。
5.2 ARM,A12X bionic[37][38][39]
目前手机市场最强核心 apple A12X,架构ARMv8.3 (ARM), 制程工艺7nm,这个芯片就是上文所提到的‘高度集成’其他功能的芯片。

在 3.1 章节封装部分,我说 A12X 是SoC 封装,在这里我就详细的解释一下:看下图,如果你把这张 A12 X的图 和 9900K 的图进行对比你会发现:图中右侧,系统一共8核CPU(4大Vortex,4小 tempest);神经网络处理器 NPU 在芯片中间;左上角系统 GPU,可以看到,系统左侧右下角,集成了很多很多‘CPU’之外的芯片,比如 ISP image signal Processor,景深 Depth Engine等 ,详情戳引用。[39]
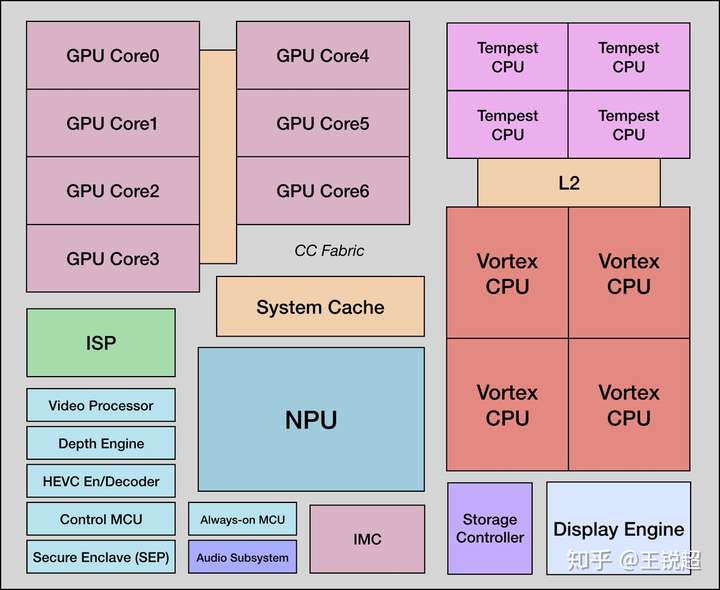
为了对比方便,我把9900K的图拿过来,可以看到,9900K 并没有上图中下面那么多其他的核心。
5.3 FSD Chip(特斯拉自动驾驶芯片)[40]

这个芯片,自动驾驶芯片,看一下内部结构就知道,2个大大的NPU占据了系统的绝大部分空间,主要就是在算神经网络。
6. 芯片生产
6.1 生产工艺 Lithography
Lithography refers to the semiconductor technology used to manufacture an integrated circuit, and is reported in nanometer(nm), indicative of the size of features built on the semiconductor.
当系统架构结构确定好了之后,就可以进行生产了。虽然我在这里写的,让你感觉可能是设计和生产是独立的两个过程,但其实不是,在芯片设计的第一个环节,打开芯片设计软件,建立工程的起始,就要选择生产的工艺。在芯片设计之初,我们要选择一个最小尺寸(举个例子),比如 ,那么其他所有器件的尺寸都要是这个数的整数倍(一般是偶数倍),比如们宽度是
,比如导线宽度
这样。
而人们常说的 7nm工艺指的就是这个 ,对应在具体的电路图上:
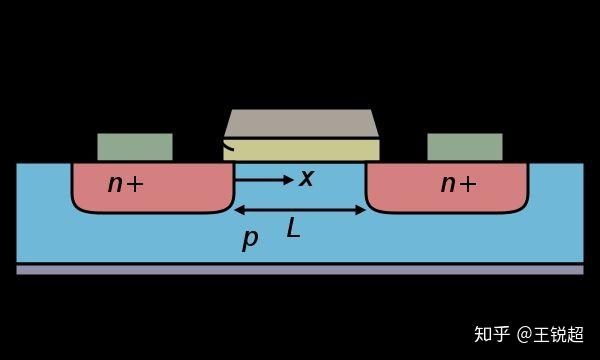 如果是25nm工艺之前。横截面,L 就是我们所说的制程工艺距离。——Behind the nanoscale process is the true and false: Intel invincible technology failed?
如果是25nm工艺之前。横截面,L 就是我们所说的制程工艺距离。——Behind the nanoscale process is the true and false: Intel invincible technology failed?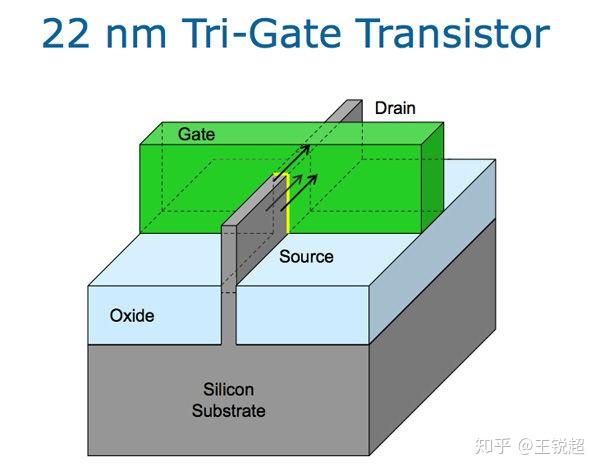
22 nm 后 finFET
22nm之前,门是一个2维的门,之后为了更高的效率,需要用 3维 的门,Intel对这个称之为‘FinFET’。这里有个视频,Intel 官方讲解 Tri-gate的具体原理,一看就懂了:Intel 22nm 3D-Tri-Gate-Transistoren[41],这里还有个文章解释:先进工艺22nm FDSOI和FinFET简介[42]
再往后,14nm以下,还没有一种统一的方案,各个厂商走的方案都不一样(详情可以戳这里),不过可以上两张图[43][44]来感受一下:
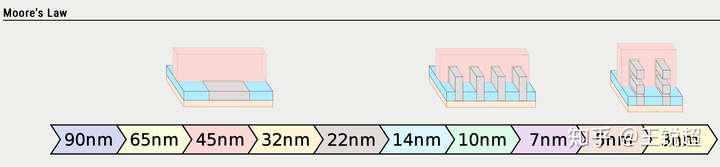
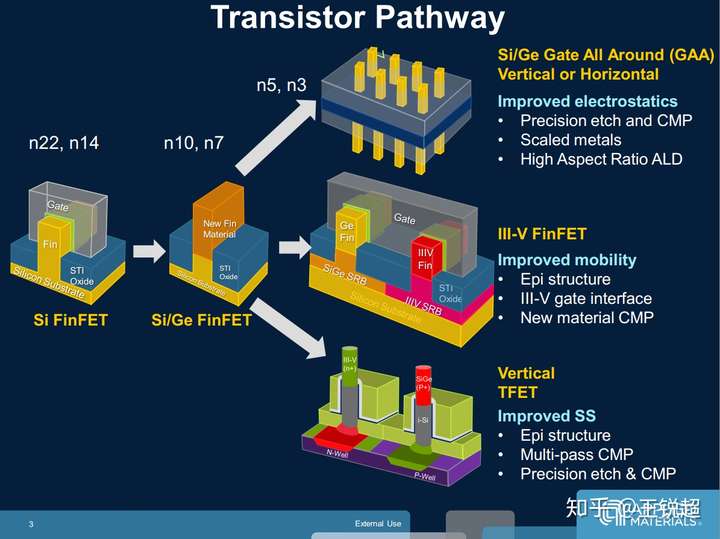
6.2 工艺具体参数
我相信所有人听到的对于 CPU 最多的描述就是 xx nm 工艺,比如今年最新的就是三星/TSMC的 7nm 工艺制成的的 CPU ,因特尔卡在了 10nm止步不前,但是没有人告诉你,这是由于不同厂商对这个距离的定义不一样所造成的一个巨大误会,不过实在是太专业了,就不具体解释了,简单记住一件事就好 Intel 10nm 等于 TSMC 7nm)[45][46]
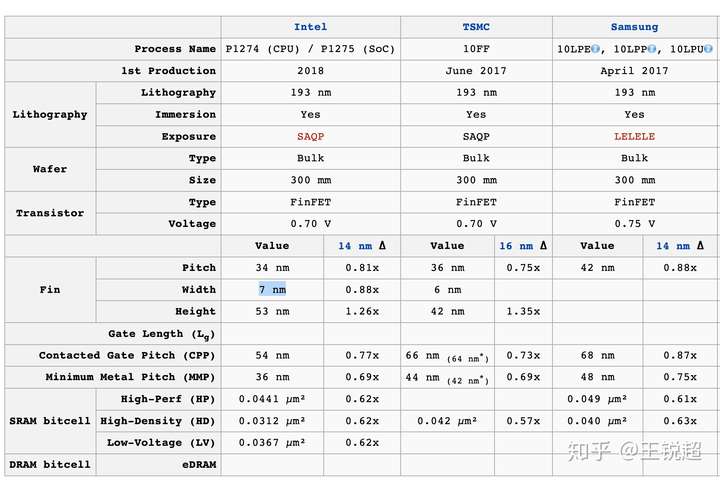 这张图是 10nm工艺的三家对比,我们可以看出,Intel 的多项指标都是好于 TSMC 与 Samsung 的
这张图是 10nm工艺的三家对比,我们可以看出,Intel 的多项指标都是好于 TSMC 与 Samsung 的
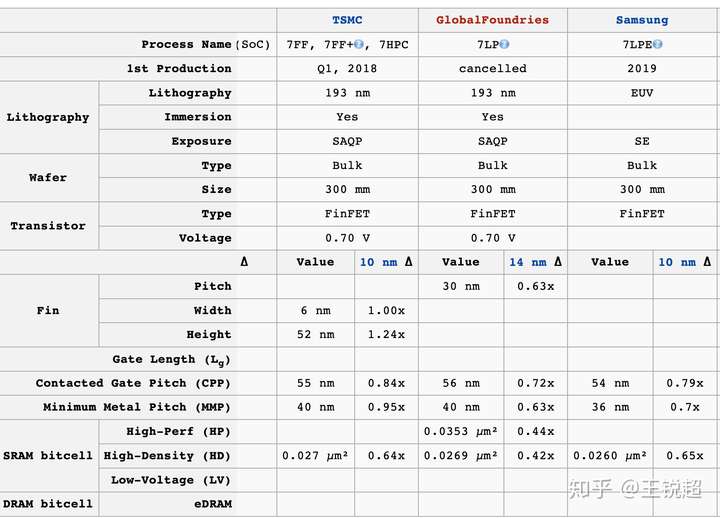
我们看指标,号称 7nm的 TSMC 和 Samsung 和 10nm 的 Intel 的指标几乎是差不多的。
为了方便大家理解,放上一张渲染图吧[47]:
 WikiChip’s Transistor Diagram (simplified)
WikiChip’s Transistor Diagram (simplified)
6.3 光刻印刷
现在最先进的光刻机用的光是‘极紫光 EUV’ (波长 小于 紫光(193nm)),其实光刻印刷是一件非常神奇一的事情,在我看来最迷人的是这两件:
- 光印原理与流程,电路是怎么一层层的印刷上去的
- 光刻机怎么用波长这么大的光波刻蚀仅仅 7nm 的沟壑的。
把沙子提纯成高精度的 SI die,然后把它切成非常薄的片 wafer,光刻机就一层层的刻,下面我贴一张一个最简单的 Pmos 为底的 CMOS刻蚀过程[48] :
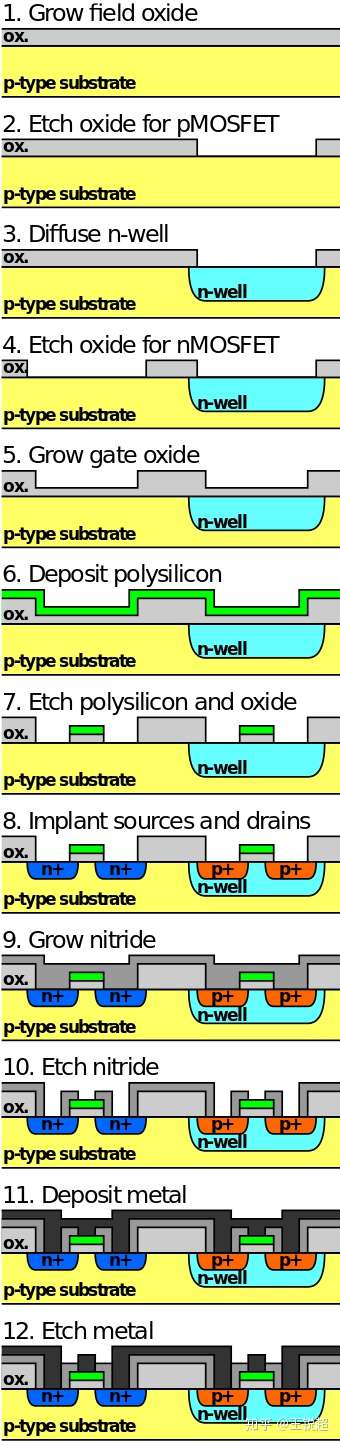 Simplified process of fabrication of a CMOS inverter on p-type substrate in semiconductor microfabrication.
Simplified process of fabrication of a CMOS inverter on p-type substrate in semiconductor microfabrication.
整张wafer 刻完后长这个样子:
 Coffee Lake silicon wafer with 8th generation core 6-core processor dies.(注,图上的颜色不是开玩笑加上去的,wafer 刻完之后真的是五彩斑斓的,由于微观结构反光)
Coffee Lake silicon wafer with 8th generation core 6-core processor dies.(注,图上的颜色不是开玩笑加上去的,wafer 刻完之后真的是五彩斑斓的,由于微观结构反光)
之后芯片被切下来,然后封装,就成了我们市面上所见到的芯片了。更详细的过程可以点击这里:[49][50][51]
电路印刷,不是拿个刷子刷上去这么简单,每一层电路,每一层电路要刷N遍,都需要很多 mask,而每一个mask 都非常之贵。现在电路电路越来越复杂,电路从最早的2面印刷(正反面),到现在的 7 层 10层,导致设计与制造的难度与成本随之上升了。(在这里的层是内部结构,不是说苹果 iPhone X 所用的双层电路板,这是两个概念)
6.4 下脚料与成本
看到这里,你会很自然地想到,从圆形的 silicon wafer 上切正方形(长方形),那么边角肯定是且不出来的。对,没错,你放大看上面的图就会知道,几乎是wafer 边上一圈全都是废了的。而且这个问题会随着我们需要生产的芯片的面积增大而更严重(里面芯片面积大了,边边废的更多)
所以不是说生产芯片的厂商不想生产更大的芯片,而是说成本会急剧上升,现在这么做是不经济实惠的。
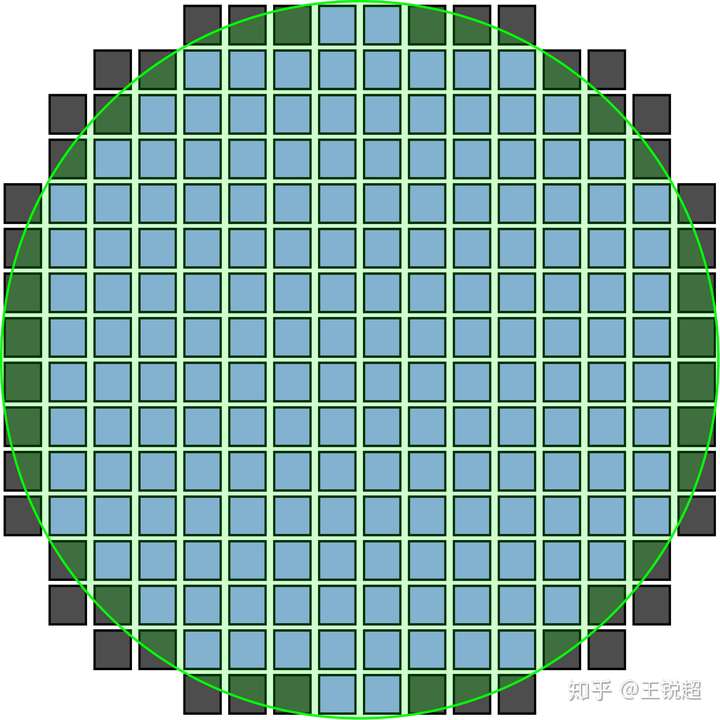 Wafermap showing fully patterned dies, and partially patterned dies which don't fully lie within the wafer.
Wafermap showing fully patterned dies, and partially patterned dies which don't fully lie within the wafer.
为什么不能生产长方形的 wafer?非要生产圆形的? 硅提纯的整个流程(Czochralski process)[52]就是会产生圆形的SI晶体,把它切成片就是 wafer。
 Crystal of Czochralski grown silicon.
Crystal of Czochralski grown silicon.
肯定你想到了,如果 wafer 直径越大,那么其实有效利用的面积相对增大了,现在的wafer主流是 300mm,厚度是775um[53]。你是不是觉得非常小?为啥不生产更大直径的 wafer??原因是由于用 Czochralski process 来生产 SI 晶体,直径越大,难度越高,成本已经不是线性增长,而是指数级增长。
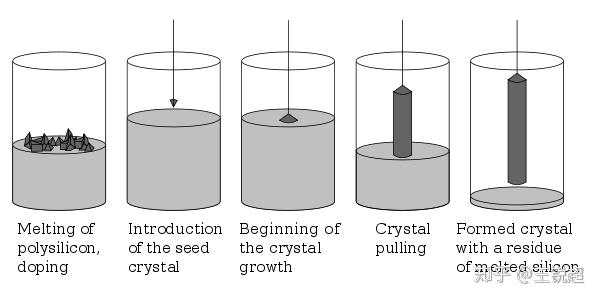 Czochralski process
Czochralski process
那有没有更好的生产 Si 晶体的方法呢?目前还没有,其他的方法反而成本更高。
芯片产业虽然是最高科技,但是它本质还是‘产业’是以盈利为目的的。芯片制造与设计要考虑的非常重的一部分就是如何减少成本,而上面的晶元的问题只是冰山一角,真正的 cost 的大头根本不是晶元,生产过程中一个 mask 就要 millions $来计算,所有外行觉得买个光刻机再加一个设计团队不就能生产芯片了?
真的并不是,它就算花重金做出来,它没有‘经济利益’,是个赔本赚吆喝的过程。
6.5 芯片的‘体质’ Process variation[54] 以及市场细分
OK,6.4提到了芯片生产商其实是以经济利益为驱动的,但是芯片生产不是生产‘时尚快消品’,不是说要生产出来不同的型号,不同主频,不同缓存的 CPU 来进行‘市场细分’,以剥削消费者。事实上,芯片都是生产出来之后,根据体质的好坏再进行分类包装的。比如:
- 生产一个6核 i7,发现坏了一个核心,这时候就直接屏蔽掉两个核心变成 4核i7卖;
- 目的是生产16MiB 的 L3 cache,但是坏了2M,那么就在屏蔽一点,按 12Mib 来卖;
- 设计主频是 2.6GHz 的,由于‘体质‘不好,达不到2.6的 就按2.4卖,再不好的就按2.2来卖。
更详细的请戳这里:同型号同款 CPU 为什么会有「体质」之分?[55]
我还想补充一下:“wafer 边缘的芯片更容易体质不好,中心的体质会相对好的比例多一些”,这个是有争议性的。[56][57]不过有一件事就是现代芯片设计过程,考虑到了大量的可能会出现偏差的过程,在设计过程中尽量的避免了。
除了上述市场细分之外,苹果和 Intel 有深度合作的排他协议,能拿到最上乘品质的芯片,其他厂商再分中上乘的品质芯片,最后散装的一般都是最差的。mac 里的CPU 是没有散装卖的,虽然很多人会说苹果特供芯片就是普通芯片贴牌,其实准确的说是专门质检过的。
7. CPU 的历史以及未来发展方向
1946年,人类历史上第一台由电子管组成的电脑 ENIAC [58],但是你们肯定听说过它占地多么大,需要多么大的电能;现代电路的发展其实是从 1947年 bell 实验室发明的第一个晶体管开始算起[59],更准确的说是1960年的场效应管 FET[60]。
场效应管就是第六章里提到的最基本单元,但由于半导体物理实在是复杂,我并不想多去阐述具体运作原理,大家简单记得电路里最基本的东西就这个:
 所有的FET都有栅极(gate)、漏极(drain)、源极(source)三个端;除了結型場效應管外,所有的FET也有第四端,被称为体(body)、基(base)、块体(bulk)或衬底(substrate)
所有的FET都有栅极(gate)、漏极(drain)、源极(source)三个端;除了結型場效應管外,所有的FET也有第四端,被称为体(body)、基(base)、块体(bulk)或衬底(substrate)
有了 FET,有了Si芯片,有了光印刷,集成电路突飞猛进发展,摩尔这时候站出来说的摩尔定律就是在这个背景下提出的。
然而到奔腾四[61]后,CPU 的主频上限已经被卡住了。原因是‘现代’集成电路的能效比其实超级低,大概1%,就是说大部分供电都会转化成热量散失掉了,只有1% 的能量变成了我们运算用的。当我第一次接触各种‘漏电流’的时候,我都对这个世界充满了绝望,what?整个芯片所有地方都在漏,没有不漏的。
由于能效比这么低,造成的结果就是CPU 非常的热,为了不让他烧坏,CPU 有非常夸张的散热方式,一个大风扇的风冷,或者液冷(水冷)。如果用液冷给他降温,奔腾四就能超频到 5GHz ;但是根本不经济实惠,所以从此集成电路在追求更高的能效比。但绝对不是简简单单的追求能效比,还有诸多考虑的问题。
至于未来的问题,强烈推荐阅读 矽说 的这三篇文章,以及相关问题讨论,在此我就不费口舌了:
- 李一雷:摩尔定律何去何从之一:摩尔定律从哪里来?摩尔定律到极限了吗?
- 李一雷:摩尔定律何去何从之二:More Moore or More Than Moore?
- 李一雷:摩尔定律何去何从之三:Beyond CMOS
- CPU 的摩尔定律是不是因为 10 纳米的限制已经失效了?10 纳米之后怎么办?
Ok,上面第一部分就是个综述,下面的内容会更加细节以及深度,正文部分:我觉得大部分领域相关的回答有一个通病就是他们并没有深入的思考芯片里的逻辑和它的物理结构之间的关系,也就是一个非常‘浮于表面’的回答,知其然,不知其所以然。
1. 为什么 MOSFET 是 逻辑电路的最基本单元,为什么电路最基本的逻辑是‘非’,以及为什么逻辑是“与非’ ‘或非’而不是 ‘ 与’ ‘或‘,我在这篇文章[62]中解释了一部分,就搬运过来了。
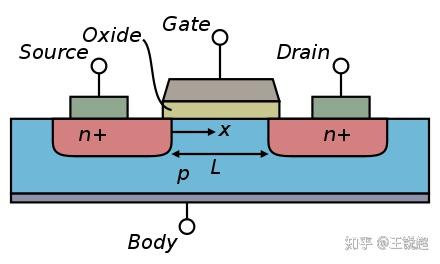
metal–oxide–semiconductor field-effect transistor 是最最最基本的结构,根据掺‘杂’不同,分为 PMOS&NMOS,一个PMOS +一个 NMOS 组成了 CMOS[63],而现代处理器的最基本运算单元就是这个 CMOS,看下图。
 电路最基本逻辑结构 CMOS ---‘非门’,非逻辑
电路最基本逻辑结构 CMOS ---‘非门’,非逻辑
如果横过来看:

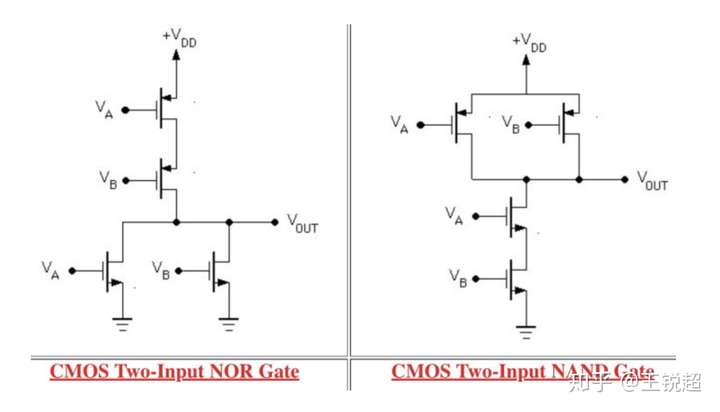
OK,之前我们是用一个1 P + 一个N组成的一个 CMOS,我们稍加改变,让电路稍微复杂一点点,由两个 P两个N ,就会形成 “与非门”,“或非门”,NOR, NAND。下图是逻辑结构,如果你感兴趣,可以看看 N Pmos 的原理,以及为什么它们能形成这两个逻辑。
于是,‘与’逻辑门的结构 就是一个 ‘与非’+ ‘非‘,组合起来得到;同理,‘或’逻辑,就是‘或非’+‘非‘。同理,其它更复杂的逻辑运算都是通过最基本的 CMOS 组合起来得到的,比如:
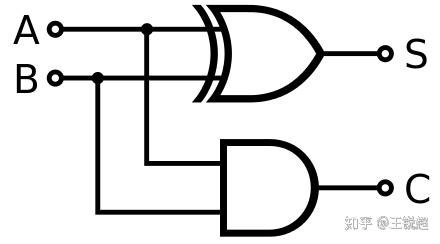 半加器,half ader
半加器,half ader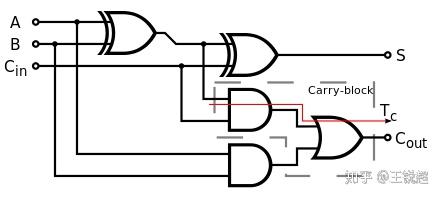 全加器,adder,ALU
全加器,adder,ALU 多路选择器,MUX,
多路选择器,MUX, 简单版 CPU
简单版 CPU
更复杂的结构我就不贴出来了,你感兴趣的话是可以查查相关的资料,但有一件事你要明白,这些复杂的功能,都是由最简单的 CMOS 组成的,而由于结构决定了最基本的逻辑单元是 非。
我说的肯定是不全的,这里有一个推荐阅读:HTG Explains: How Does a CPU Actually Work?,加了更多的最基本的单元,BUS,Memory,Clock, Stepper 等介绍。
2. 把‘电子’ 装进盒子里的各种储存单元:register(俗称寄存器,L0 cache),cache(SRAM),DRAM(俗称内存), Flash Drive (俗称‘闪存’)
这一小节里的所有储存单元的基本原理都是,用一个容器来储存电荷,我们规定有足够多的电荷的时候,就为逻辑1,没有足够多的时候,就为逻辑0.
2.0 Computer Memory Hierarchy[64]
 这张图老了L3 cache 没有加上,不过不影响主要理解,
这张图老了L3 cache 没有加上,不过不影响主要理解,
上面这张图解释了,和CPU 关联的相关储存单元,CPU 先从 L0 搜寻有没有存在这里,没有就去L1 搜,在没有就去L2搜,搜到后就送回运算单元。如果你对这部分有更深的兴趣,原图戳这里:[36]
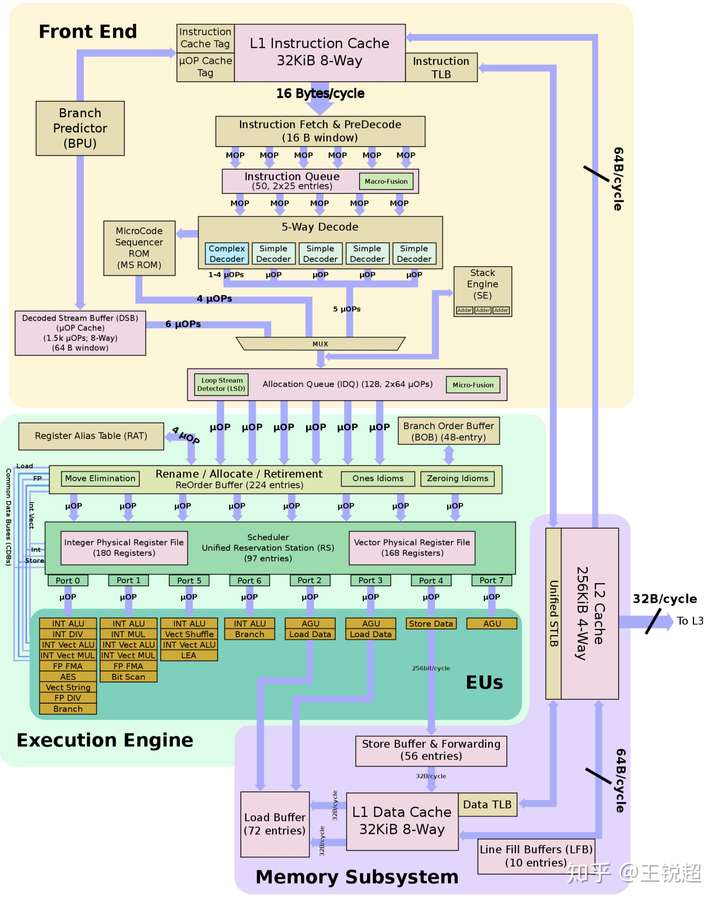 intel - Skylake
intel - Skylake
右边 L2 cache ,出去接 L3 cache(意思是所有外面的信息都会在 L2 停留),Front end 和 Memory subsystem 各有一个32KiB的 L1 cache,那些 Buffer就是一些寄存器。 回忆之前第一部分的一张图[36],CPU的结构:
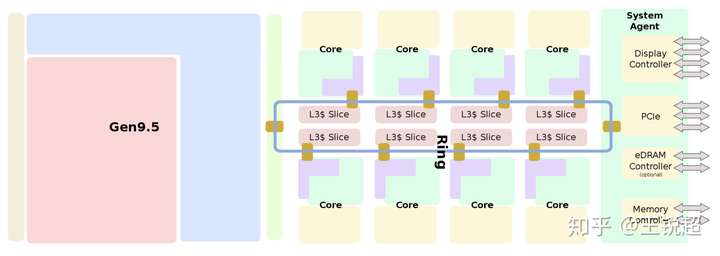 8核 share一个大 L3 cache,所以L3 cache 的作用就是一个CPU内,多核心协同工作。
8核 share一个大 L3 cache,所以L3 cache 的作用就是一个CPU内,多核心协同工作。
2.1 Dynamic random-access memory,DRAM
寄存器懒得讲了,感兴趣自己看维基百科[65]吧,DRAM 在结构上是所有存储单元里最简单的[66]:
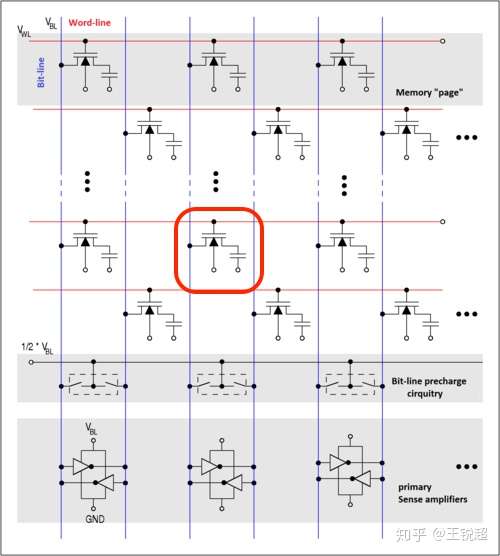 红色地方就是我标注的一个memory cell,由一个 NMOS 接电容接地组成
红色地方就是我标注的一个memory cell,由一个 NMOS 接电容接地组成
看上面红色标记的部分,一个内存的基本单元是 由一个 NMOS 接电容接地组成的;看到这里有电路基础的人肯定能看出来,当门极通电时,NMOS导通,如果供电,那么就会对电容进行充电;而电容接地了,电容的电不断的在散失。能坚持看到这里的人肯定知道 内存是在不断的‘刷新‘(一般来说,64 ms[66]),来维持电的稳定的,所以我们称之为 dynamic-RAM。
当电容里有足够多电荷时,就会有电压;电荷慢慢丢失,那么就会变成0. (一般不会出现让它慢慢丢失的情况,都是不断的刷新给他加新的电进去)
2.2 L1,2,3 cache, SRAM[67]
SRAM 保存电压/电荷的方式十分巧妙,用四个三极管来控制‘保存’一个电荷。同样是一个bit, Dram 只需要一个 NMOS+一个电容,而这个SRAM就需要 6 个三极管。高昂的制作成本,换取的是稳定性与速度。而这种 SRAM 只有 CPU 内部才有,外面也不会有,也买不到。
(ok,那为什么这样的结构会更快呢?答案戳这里[68])
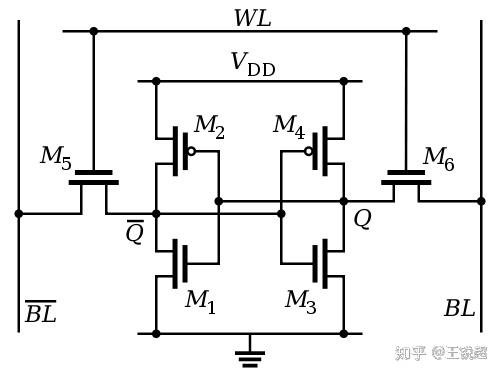 标准 6个transistor 组成的 6T SRAM
标准 6个transistor 组成的 6T SRAM
A typical SRAM cell is made up of sixMOSFETs. Eachbitin an SRAM is stored on fourtransistors(M1, M2, M3, M4) that form two cross-coupled inverters.
2.3 Flash Drive
2.3.1 flash drive 的命名[69]:
the name "flash" was suggested by Masuoka's colleague, Shōji Ariizumi, because the erasure process of the memory contents reminded him of the flash of a camera.
2.3.2 Floating gate
Flash 的最基本单元和之前的 MOS 类似,但是多了一个 floating gate,在电路图中多了一个横线(下图中框框中的mos)来表示。float gate的目的就是存放电荷(电子)。
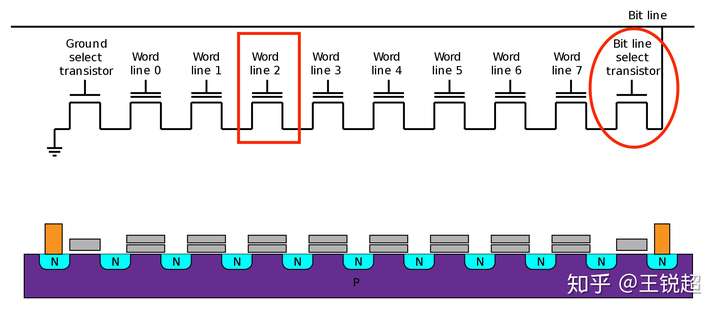 NAND Flash
NAND Flash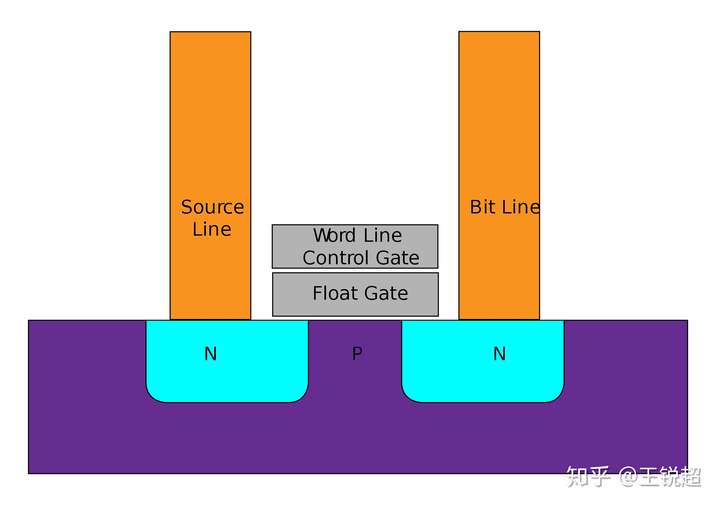 单纯拿过来一个放大了看,中间门极和衬底中间多了一个 float gate。
单纯拿过来一个放大了看,中间门极和衬底中间多了一个 float gate。
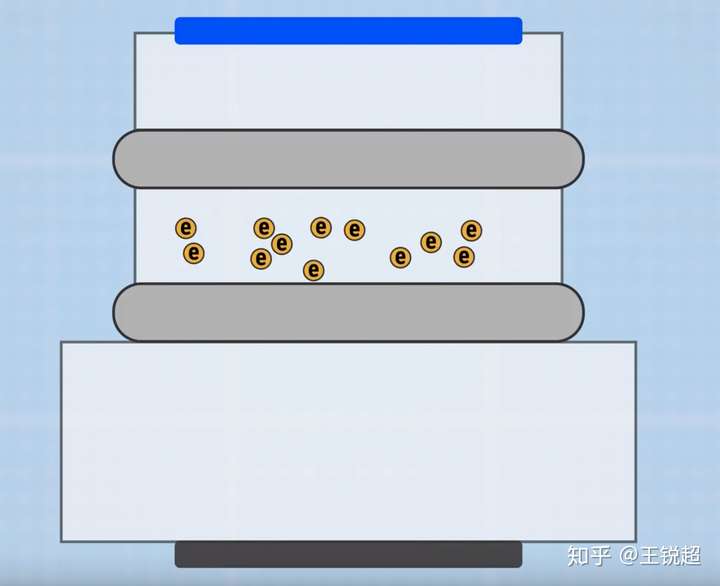
Float gate 里存的是电子,有电压就认为是逻辑1,没有就是逻辑0 。(SLC 状态下)
float gate 和衬底之间只有非常薄薄的一层隔绝层(隔离层就是下图中灰色的部分)。每次写入和读取都会对隔绝层有损害,日积月累,隔绝层就会坏,这时候内存就坏了。
2.3.3 NAND/NOR Flash 都是Toshiba 发明的,但是 NOR 死了(其实还是有的,但是并不普及),下图就是原因:
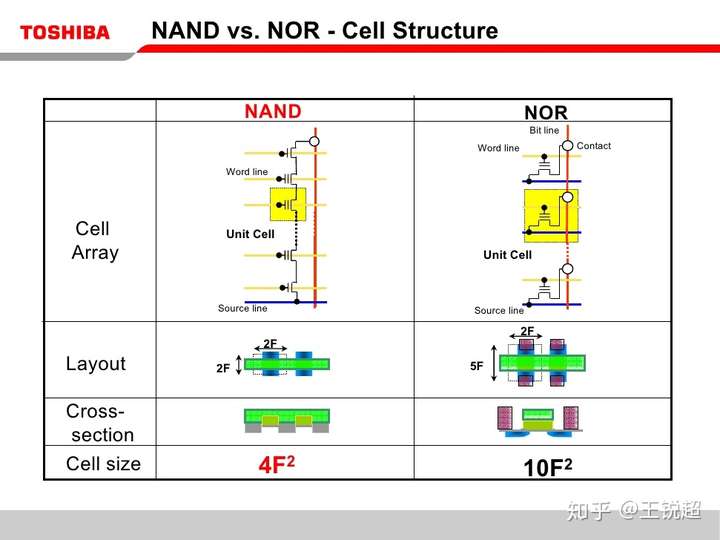 NAND 容量密度更大
NAND 容量密度更大
2.3.4 2D 到 3D NAND[70][71](三星称之为 vertical, VNAND)
简单解释一下吧,之前的储存模式是一层,之后就跟叠积木,建摩天大楼一样盖高层。[72]
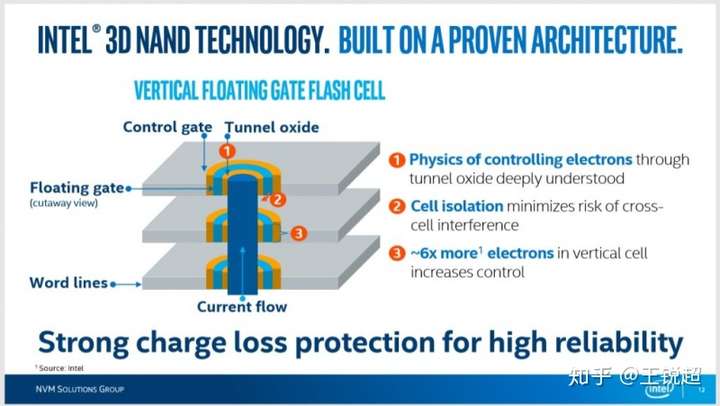
建议观看 Intel 官方介绍视频:英特尔® 3D NAND 技术如何推动存储发展-英特尔® 官网[70]
叠出来效果是这样子的:
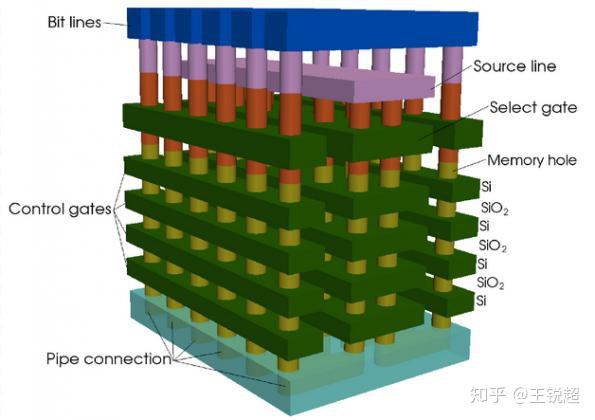 Toshiba takes 3D-NAND to 96-layers, 4 bits per cell
Toshiba takes 3D-NAND to 96-layers, 4 bits per cell
目前来说叠到了 intel 660P,64层 3D QLC[73],三星 970 EVO PLUS,96层 V-MLC[74][75]
2.3.5, SLC --- MLC---TLC----QLC
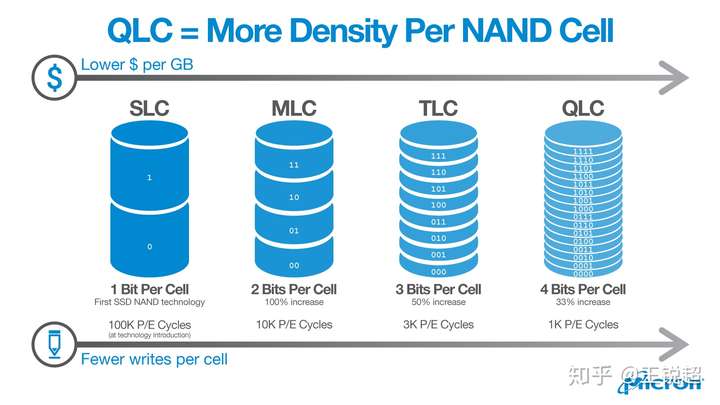 Micron QLC
Micron QLC
以前,一个memory cell 里有电压我们就认为是逻辑1,没电压就认为是逻辑0;科学家们发现这样虽然稳定,但是不经济实惠。于是我们把同一个memory cell 根据电压水平的不同来确定不同的逻辑水平,MLC 就能有2bit ,TLC 3bit,QLC 4bit 这样。
在此我就不扯到底好不好了,感兴趣戳这里看知乎讨论[76][77],反正事实上把:没人跟钱过不去。大部分人(我说的绝大部分人就是这篇文章都看不进去的那些,根本不可能在5年之内把 QLC 写死,谢谢,就算死了,Intel 5年质保。同样的,这篇文章都看不懂的人,一年能几次把 flash 的 cache 给写完,从而把速度掉下去?)来说,又快又便宜就是好事啊。
推荐看这篇测评:https://www.youtube.com/watch?v=OffzVc7ZB-o
2.3.6 '电子危机‘
如果给爱因斯坦说,我们打算做一个容器,装电子,大概就装几十个吧,爱因斯坦会直接怀疑人生的。
你是学物理的,知道电子有小,想把电子装进一个容易有多么不容易。而目前夸张到,每 100mv 只是由 15个电子 来区分。(真的太不稳定了,不过还好,我们依旧可以通过DRAM 的刷新方法来给 Flash 供电,省的存错了)
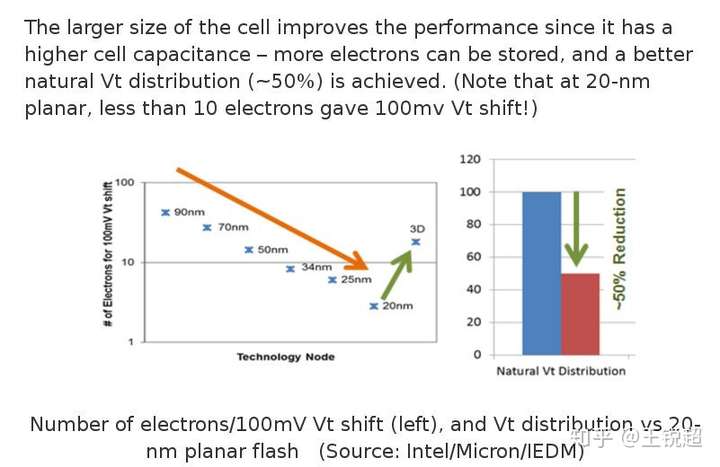 https://twitter.com/alt_kia/status/1046448638199644160
https://twitter.com/alt_kia/status/1046448638199644160
2.3.7 SATA [78]OR PCIe[79] NVMe [80],以及 M.2[81](可简单理解为尺寸)
最新几年的CPU及其 chipset,比如 Z370,虽然还提供SATA,但几乎可以忽略,PCIe 占据了几乎全部总线(除了DMI)的范式。
2.3.8 推荐阅读:
纳米技术走到尽头?固态硬盘闪存如何跳出即将终结的摩尔定律[82]
3 TDP,主频,以及超频
Thermal Design Power (TDP) represents the average power, in watts, the processor dissipates when operating at Base Frequency with all cores active under an Intel-defined, high-complexity workload. Refer to Datasheet for thermal solution requirements.
i9-9900K 的TDP=95W,但是官网是不提供具体损耗的,想知道细节只有前两个方法:1,查datasheet(这个需要问intel 要,而且普通人看不懂);2,做测试[85],发现极限瞬时功率已经到204W ;3,功率计算器,比如 MSI 提供的[86](TDP)。
而其实现在的芯片都在追求能耗比,即 更小的功率有更好的效率。
3.2 瞬时超频的Turbo boost [87]
对于普通用户(非游戏玩家,非专业用户)来说,workload 并不是稳定的,大部分workload 都是非常平稳(低的),在打开软件的瞬间才大。所以瞬时超频就能非常‘聪明’的解决这个问题。
3.3 低压处理器
比如超级本上,我们就限定 功率 TDP = 15W 的基础上,CPU 运行速度越快越好!
芯片里的功耗,最大的功耗就是‘漏’掉了,如果你深入研究会发现,几乎所有地方都在漏,没有不漏的,生产工艺/设计工艺里,有很大一部分都在研究如何减少‘漏电‘的情况。不过先抛开怎么减少的漏电,我们先直观的感受一下 CPU 的功耗是什么[88]:
,C is capacitance, f is frequency, and V is voltage。
这个公式特别好理解,CPU 的功耗和 电路运行的速度成正比,和电路运行的电压的平方成正比。所以想要减少CPU 的功率,就要想办法降低这三个值。
非常的巧:如果我们把 门做小, 电容 C 会随之变小(电路设计里,怎么制作大 C 是个非常大的问题); f 我们想保持不变,减少电压 V 就是最好的办法。这就是你所见到的那些‘超级本’ 用的 “低压处理器“的原因。
如果你还感兴趣,可以继续看这个问题:为什么计算机芯片大都采用低电压大电流的供电方案?[89]
3.4 为什么低电压就很难高功率,为什么超频需要高电压?
有人告诉你说,调高电压,就能超频,但是没有告诉你为什么;在1.2 章节里提到了,我们希望功率低,但频率高,那么唯一可行的办法就是降低 C 以及 降低 V。
你可能会想,V 为什么不能降低?加载到门极上的电压低而运行在高频率(不断的开关)的的时候,CPU 会出错。如果想要‘感性的认识’而不是直接拿过来公式给你展示出来的话就是:‘我们把电压类比成关门的时候用的力气,高电压就好像是用力关门,关门会关的很紧,而低电压的时候(门级电压不够高),关门关不紧,这个时候就会让电子泄露,导致 0/1 混乱。(当然实际上,门级电压是怎么影响运行速度的不是这么计算的,在这里是为了让人更好理解。)
同样的,我们高电压的时候,CPU 就更不容易出错,就可以在更高的速率上运行。这也就是俗称的‘体质’,我借用一下别人的图[55]来让你更好的理解一下:
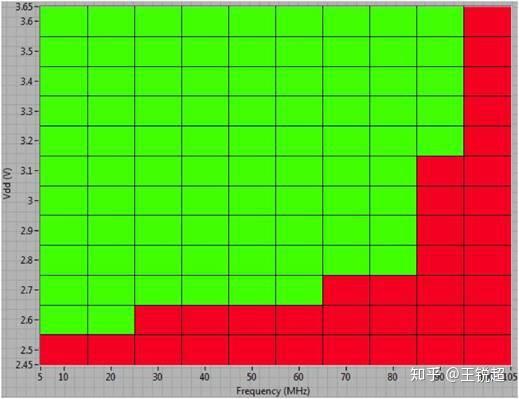
横坐标是 CPU 运行的频率,纵坐标是CPU 运行电压,绿色表示 CPU正常工作,红色表示 CPU 出现错误。从图上可以看清楚,为了保证CPU 处于正常工作状态下更高的频率,就需要更高的电压。
所有些人说‘调高电压就会超频’ 是把因果弄反,不是说我们调高了电压 CPU 就会更高的主频,而是说,想维持CPU 正常工作的前提下,更高的主频需要更高的电压。
标签:架构,Intel,芯片,CPU,工作,处理器,原理,ARM 来源: https://www.cnblogs.com/RQfreefly/p/13701681.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。