最近在写一个专利的方案,涉及到知识图谱的内容,对于一些大厂的方案浅层次做了研究,总结内容记录如下。
知识图谱是什么?
根据百度百科
知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱,是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。
知识图谱是由 Google 公司在 2012 年提出来的一个新的概念。从学术的角度,知识图谱的定义:“知识图谱本质上是语义网络(Semantic Network)的知识库”。但这有点抽象,所以换个角度,从企业实际应用的角度出发其实可以简单地理解:知识图谱是一组围绕知识对象的多关系图(Multi-relational Graph,多关系图一般包含多种类型的节点和多种类型的边)。
需要特别解释清除的是知识图谱和机器学习的区别,考下图,机器学习通常是面向某一个具体任务,比如说下围棋、识别猫、人脸识别、语音识别等等。通常而言,在很多任务上它能够取得非常优秀的结果,同时它也有非常多的局限性,比如说它需要海量的训练数据,以及非常强大的计算能力,同时它也有非常多的局限性,比如说难以进行任务上的迁移,而且可解释性比较差。知识图谱能够广泛地适用于不同的任务。相比深度学习,知识图谱中的知识可以沉淀,可解释性非常强,类似于人类的思考。
需要特别解释清除的是知识图谱和机器学习的区别,参考下图,机器学习通常是面向某一个具体任务,比如说下围棋、识别猫、人脸识别、语音识别等等。通常而言,在很多任务上它能够取得非常优秀的结果,同时它也有非常多的局限性,比如说它需要海量的训练数据,以及非常强大的计算能力,同时它也有非常多的局限性,比如说难以进行任务上的迁移,而且可解释性比较差。知识图谱能够广泛地适用于不同的任务。相比深度学习,知识图谱中的知识可以沉淀,可解释性非常强,类似于人类的思考。

知识图谱分成两大类,一类是开放域知识图谱,另一类是垂直领域知识图谱。这两类知识图谱有明确的区别。开放域知识图谱关注的实体的语义信息,比较常用的两类关系是isA Relation、isPropertyOf Relation,这一类知识图谱构建关注的是概率,即关系具有不确定性。开放域知识图谱包括WordNet、KnowItAll、NELL 以及 Microsoft Concept Graph。垂直领域知识图谱关注的实体以及实体之间的联系,垂直领域的知识图谱我们会基于业务场景定义自己的联系类型,例如 DayOfbirth、LocatedIn、SpouseOf 等,这种联系是非黑即白的,我们关注的是准确率,垂直知识领域的代表包括:Freepase、Yago、Google Knowledge Graph。
本篇综述后续的内容主要涉及垂直领域知识图谱展开。
基本概念
知识图谱的基本组成三要素:实体、属性、关系。实体-关系-实体 三元组;实体-属性-属性值三元组。在知识图谱中,有一类特殊的实体叫做本体,也叫做概念或语义类。它是一些具共性的实体构成的集合。比如说,比尔盖茨和乔布斯都是人,微软和苹果都是公司。
知识图谱提供了三个维度的理解能力:1、是什么,概念是什么,建立核心概念是什么的关联体系。例如“维修洗衣机”,“维修”是什么,“洗衣机”是什么。2、什么样,核心概念某一方面的属性,对核心概念某一方面的细化。“带露台的餐厅”、“亲子游乐园”、“水果千层蛋糕”中“带露台”、“亲子”、“水果千层”这些都是核心概念某一个方面的属性,所以需要建立核心概念对应属性以及属性值之间的关联。3、给什么,解决搜索概念和承接概念之间的代沟,例如“阅读”、“逛街”、“遛娃”等没有明确对应的供给概念,所以建立搜索和供给概念之间的关联网络,解决这一类问题。

知识图谱一般包含三类节点:taxonomy节点、原子节点、复合节点,包含四类关系:同义、概念属性、概念承接、自定义关系。
taxonomy节点:在概念图谱中,理解一个概念需要合理的知识体系,预定义好的Taxonomy知识体系作为理解的基础,在预定义的体系中分为两类节点:第一类在团购场景中可以作为核心品类出现的。例如,食材、项目、场所;另一类是作为对核心品类限定方式出现的,例如,颜色、方式、风格。这两类的节点的定义都能帮助搜索、推荐等的理解。 原子节点:组成图谱最小语义单元节点,有独立语义的最小粒度词语,例如网红、狗咖、脸部、补水等。定义的原子概念,全部需要挂靠到定义的Taxonomy节点之上。 复合节点:由原子概念以及对应属性组合而成的概念节点,例如脸部补水、面部补水等。复合概念需要和其对应的核心词概念建立上下位关系。 同义关系:语义上的同义/上下位关系,例如脸部补水-syn-面部补水等。定义的Taxonomy体系也是一种上下位的关系,所以归并到同义/上下位关系里。 概念属性:是典型的CPV(Concept-Property-Value)关系,从各个属性维度来描述和定义概念,例如火锅-口味-不辣,火锅-规格-单人等,示例如下 概念承接属性:基于业务场景为核心与散发主体之间构建的属性。例如,团购网站定义了「事件」为核心场景,定义了「场所」、「物品」、「人群」、「时间」、「功效」等能够满足用户需求的一类供给概念。以事件“美白”为例,“美白”作为用户的需求,可以有不同的供给概念能够满足,例如美容院、水光针等。如下图所示: 自定义主体关系:从业务场景为核心,构建的核心关系,例如团购网站常见的两类关系:POI(Point of Interesting)、SPU(Standard Product Unit),这些常常是比较能发挥知识图谱在业务上价值的地方。在搜索、推荐等业务场景,最终的目的是能够展示出符合用户需求的POI,所以建立POI/SPU-概念的关系是整个购物场景常识性概念图谱重要的一环,也是比较有价值的数据。

构建知识图谱
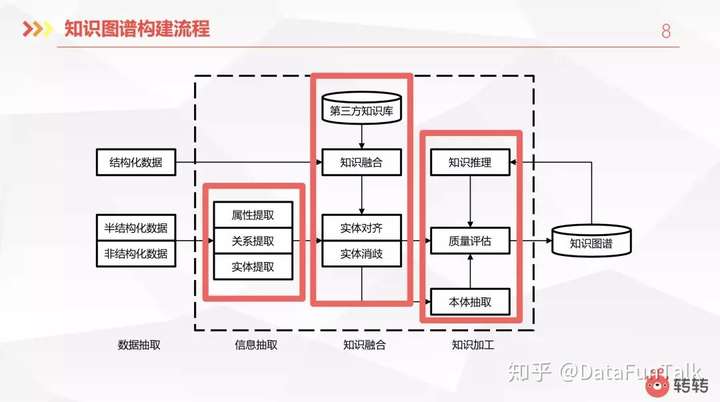
构建知识图谱通常包含:数据处理、信息抽取、知识融合、知识加工四个步骤。
数据处理
首先就是要先处理数据。互联网上的数据基本上都是结构化的,非结构化的和半结构化的。结构数据一般就是公司的业务数据。这些数据都存储到数据库里,从库里面抽取出来做一些简单的预处理就可以拿来使用。半结构化数据和非结构化数据,比如对商品的描述,或是标题,可能是一段文本或是一张图片,这就是一些非结构化数据了。但它里面是存储了一些信息的,反映到的是知识图谱里的一些属性。所以需要对它里面进行一个抽取,这是构建知识图谱中比较费时费力的一个工作。
信息抽取:从数据里需要抽取的其实就是之前所提到的实体、属性、关系这些信息。对于实体的提取就是NLP里面的命名实体识别。这里相关的技术都比较成熟了,从之前传统的人工词典规则的方法,到现在机器学习的方法,还有深度学习的一些使用。比如说,从一段文本里面,我们提取出来比尔盖次这个实体以及微软这个实体,然后再进行一个关系提取。比尔盖次是微软的创始人,会有这么一个对应的关系。另外还有属性提取,比如比尔盖茨的国籍是美国。在这些提取完成之后都是一些比较零散的信息,然后在再加之前用结构化信息所拿到的东西以及从第三方知识库里面所拿到的信息做一个融合。
知识融合:主要进行实体对齐和实体消歧。关于实体对齐。举例来说,比尔盖茨这四个字是中文名称,Bill Gates是他的英文名称,但其实这两个指的是同一个人。由于文本的不一样,开始的时候导致这是两个实体。这就需要我们对它进行实体对齐,把它统一化。另外是实体消歧。举例来说,苹果是一种水果,但是在某些上下文里面,它可能指的是苹果公司。这就是一个实体歧义,我们需要根据上下文对它进行实体消歧。
知识加工:主要进行本体抽取。比如之前提到的微软和苹果,它们的实体是公司。从文本里面可能无法直接提取出来,它们是公司。那么需要一些方法对他们进行抽取。然后搭建出本体库,比如说公司是一个机构,它是有这种上下流的关系的。对于平级的也需要计算一个他们的相识度,比如比尔盖茨和乔布斯在实体层面,他们是比较相似的。他们都属于人这个实体。他们跟公司的差别还是挺大的,所以需要一个相似度的计算。
在以上步骤完成之后需要对知识库进行质量评估,这是一个避免不了的人工步骤。在做完质量评估以后,最终形成知识图谱。形成知识图谱以后,有些关系可能是无法直接得到的,然后需要进行知识推理,这可以对知识图谱进行扩展。比如,猫是猫科动物。猫科动物是哺乳动物。这就可以推理出来,猫是哺乳动物。但是这个推理也不是随便就可以推出来的。比如,比尔盖茨是美国人,比尔盖茨创建了一个公司,但这个公司并不一定是美国的。
设计案例

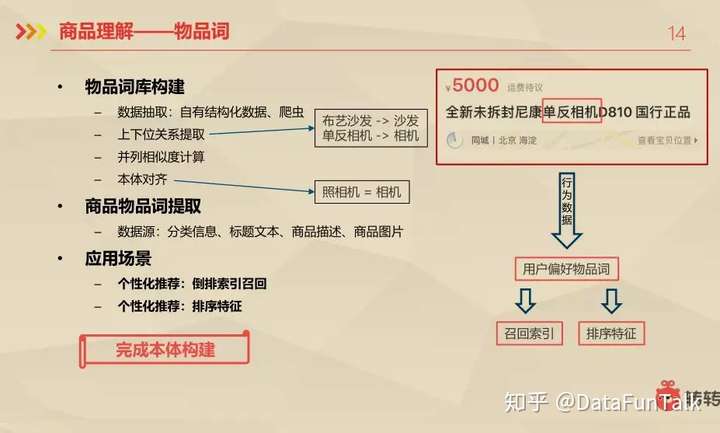
**商品理解——物品词 **:首先从商品中提取出它的物品词,然后根据用户的行为数据得出用户偏好物品词,接着根据这个用户偏好物品词进行召回或是排序特征。那么具体的实现方案:
先是物品词库的构建,不断地挖掘当前都有哪些东西,以及以后还打算做哪些东西。这部分的数据大部分是从我们自有的结构化数据那里拿到的,也有一部分是从外部爬去得到的,还有是从命名实体识别得到的。
接着是上下位关系提取,沙发是个实体,布艺沙发也是个实体。布艺沙发也是沙发的一种,它们是一个上下位的关系。
然后是并列相似度计算。像布艺沙发和皮质沙发的相似度是比较高的,而沙发和相机的相似度就比较低。还有是文本对齐。类似于同义词,比如,相机和照相机其实是指代的同一个东西。
当以上完成以后,就构架出了一个物品词库。接着就是商品层面,商品物品词提取,使用到的数据源有:分类信息、标题文本、商品描述、商品图片。
商品理解——tag词:后面做了一个商品理解的Tag词,这是物品词的演进,这是服务的升级,刚才我们提取到的是用户感兴趣的东西,但是人往往不会局限于对这个东西感兴趣,还有可能对这类物品有很多的要求。所以需要从属性的角度去挖掘用户的兴趣,比如右下角的例子。对该商品提取出更多的属性。那这个套路和刚才的物品词比较相似。这里需要注意的是,一手化的数据可以从自有结构的数据,爬虫,文本抽取中可以拿到,但是二手数据只能从文本挖掘中抽取。还有属性对齐。还有商品Tag词的提取,他的数据源来源于结构化数据,标题文本,商品描述,商品图片等。应用场景和物品词一致。最后就完成了属性抽取。

后面做了一个商品理解的Tag词,这是物品词的演进,这是服务的升级,刚才我们提取到的是用户感兴趣的东西,但是人往往不会局限于对这个东西感兴趣,还有可能对这类物品有很多的要求。所以需要从属性的角度去挖掘用户的兴趣,比如右下角的例子。对该商品提取出更多的属性。那这个套路和刚才的物品词比较相似。这里需要注意的是,一手化的数据可以从自有结构的数据,爬虫,文本抽取中可以拿到,但是二手数据只能从文本挖掘中抽取。还有属性对齐。还有商品Tag词的提取,他的数据源来源于结构化数据,标题文本,商品描述,商品图片等。应用场景和物品词一致。最后就完成了属性抽取。
Tag词树结构化:上面做完之后,我们发现提取出的key-value属性,都是各自离散存在的。然后会出现数据质量的问题,所以把之前挖掘出的term给提取出来组成一个树,下面是例子。从这个树里面可以追溯到他的所有信息。上面做完之后,我们发现提取出的key-value属性,都是各自离散存在的。然后会出现数据质量的问题,所以把之前挖掘出的term给提取出来组成一个树,下面是例子。从这个树里面可以追溯到他的所有信息。
上面做完之后,我们发现提取出的key-value属性,都是各自离散存在的。然后会出现数据质量的问题,所以把之前挖掘出的term给提取出来组成一个树,下面是例子。从这个树里面可以追溯到他的所有信息。
商品挂靠 :商品挂靠指利用分类信息、商品标题、商品描述、商品图片等数据,对本体库(Tag词树型结构)中的节点进行匹配和生成商品知识路径。同时消岐有可能一个商品会匹配到本体库中的多个本体(物品词)和 对属性节点赋予权值,选取匹配权重最高的本体。
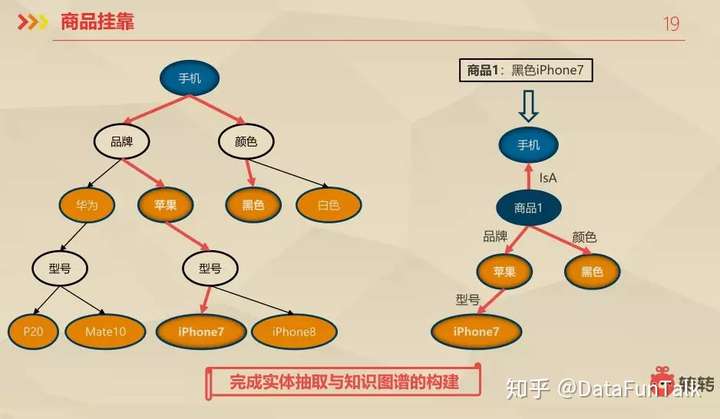
这样的做法还提供了query结构化,对query进行理解,他的应用场景有三部分,个性化推荐和智能搜索,这一块截止,做完了商品库的知识库的构建。后面就是商品挂靠。
参考链接
知识图谱学习入门:美团技术团队知识图谱专题
标签:知识,提取,综述,图谱,实体,概念,属性 来源: https://www.cnblogs.com/kendrick/p/16219896.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。