标签:Combiner 聚合 自定义 Reducer MapReduce Key 组件
Combiner 组件的作用
MapReduce 中的 Combiner 组件就是为了避免 MapTask 任务和 ReduceTask 任务之间的过多的数据传输而设置的
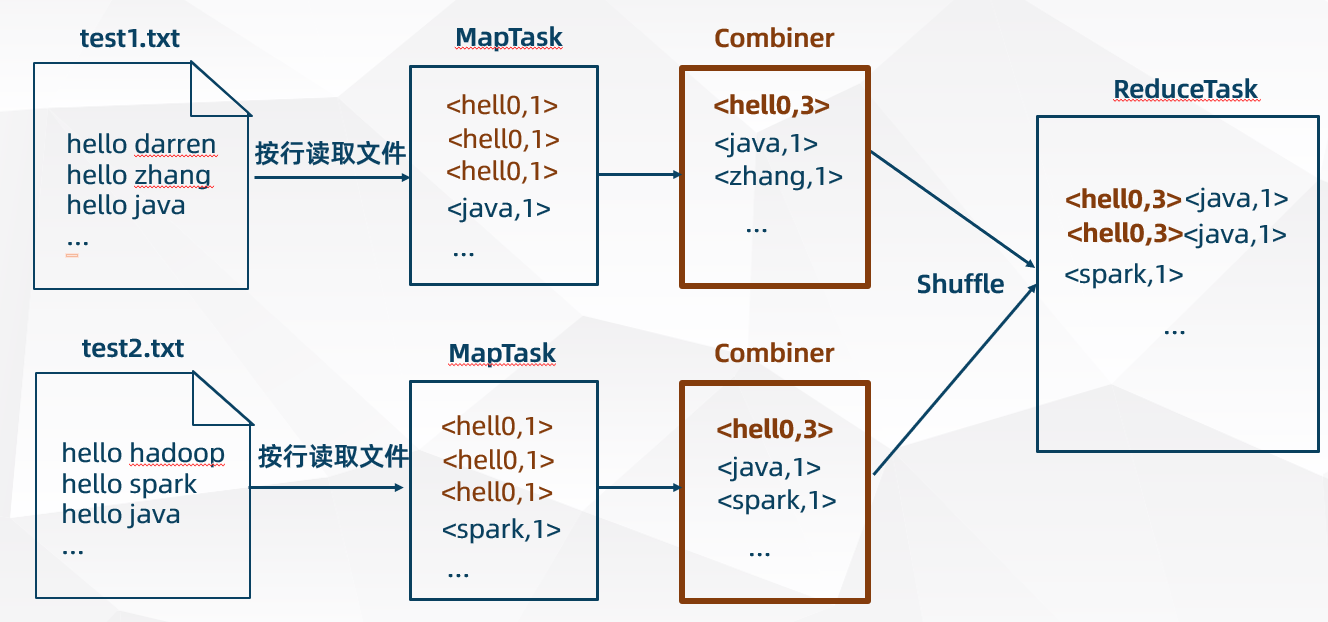
- MapReduce 程序可以在 MapTask 阶段自定义一个 Combiner 组件进行聚合
- Combiner 的工作机制类似于 Reducer,不同的是只针对一个 MapTask 任务进行聚合(局部聚合)
- Combiner 组件可以削减 Mapper 的输出,减少传输到 Reduce中的数据量
- Combiner 组件可以减少网络带宽和 Reducer 的运算负载
设置 Combiner 组件
// 设置maptask端的 局部聚合 Combiner 组件
job.setCombinerClass(MyCombiner.class);
Combiner 组件使用注意事项
- Combiner 组件没有默认实现,必须用户自定义
- 并不是所有的 Job 都适用使用 Combiner 组件,只有操作满足结合律的才可以
- 一般情况 Combiner 组件和 Reducer 进行同样的操作
数据倾斜问题解决方案
步骤一:第一次在 Map 阶段对那些导致了数据倾斜的 Key 加上分区号随机值,这样本来相同的 Key 也会被分到多个 ReduceTask 任务中进行
步骤二:使用 Combiner 组件进行局部聚合,减少传输到 ReducerTask 的数据量,减轻 ReducerTask 的处理压力,节约网络带宽
注:增加ReducerTask 并行度,或者实现自定义分区,将 Key 均匀分配到不同Reducer
标签:Combiner,聚合,自定义,Reducer,MapReduce,Key,组件 来源: https://www.cnblogs.com/ccl971123/p/15646957.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。