标签:实战 ELK log ip 192.168 企业级 格式 日志 logstash
企业级实战模块五:ELK收集Web服务访问日志实战案例
ELK收集日志的几种方式
ELK收集日志常用的有两种方式,分别是:
-
不修改源日志的格式,而是通过logstash的grok方式进行过滤、清洗,将原始无规则的日志转换为规则的日志。
-
修改源日志输出格式,按照需要的日志格式输出规则日志,logstash只负责日志的收集和传输,不对日志做任何的过滤清洗。
这两种方式各有优缺点,第一种方式不用修改原始日志输出格式,直接通过logstash的grok方式进行过滤分析,好处是对线上业务系统无任何影响,缺点是logstash的grok方式在高压力情况下会成为性能瓶颈,如果要分析的日志量超大时,日志过滤分析可能阻塞正常的日志输出。因此,在使用logstash时,能不用grok的,尽量不使用grok过滤功能。
第二种方式缺点是需要事先定义好日志的输出格式,这可能有一定工作量,但优点更明显,因为已经定义好了需要的日志输出格式,logstash只负责日志的收集和传输,这样就大大减轻了logstash的负担,可以更高效的收集和传输日志。另外,目前常见的web服务器,例如apache、ng inx等都支持自定义日志输出格式。因此,在企业实际应用中,第二种方式是首选方案。
1 ELK收集Apache访问日志实战案例
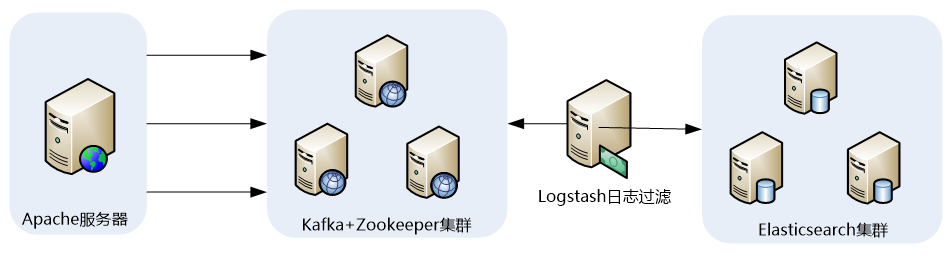
1.1 ELK收集Apache访问日志应用架构
这里我们还是以ELK+Filebeat+Kafka+ZooKeeper构建大数据日志分析平台一节的架构进行介绍:
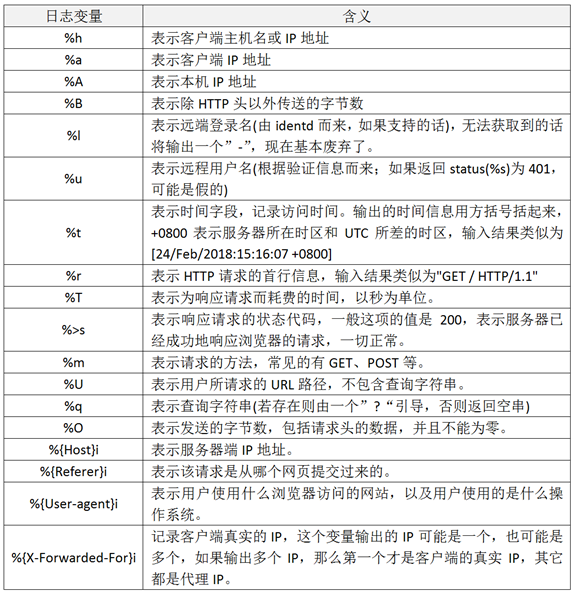
1.2 apache的日志格式与日志变量
apache支持自定义输出日志格式,但是,apache有很多日志变量字段,所以在收集日志前,需要首先确定哪些是我们需要的日志字段,然后将日志格式定下来。要完成这个工作,需要了解apache日志字段定义的方法和日志变量的含义,在apache配置文件httpd.conf中,对日志格式定义的配置项为LogFormat,默认的日志字段定义为如下内容:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
1.3 自定义apache日志格式
这里定义将apache日志输出为json格式,下面仅列出apache配置文件httpd.conf中日志格式和日志文件定义部分,定义好的日志格式与日志文件如下:
LogFormat "{\"@timestamp\":\"%{%Y-%m-%dT%H:%M:%S%z}t\",\"client_ip\":\"%{X-Forwarded-For}i\",\"direct_ip\": \"%a\",\"request_time\":%T,\"status\":%>s,\"url\":\"%U%q\",\"method\":\"%m\",\"http_host\":\"%{Host}i\",\"server_ip\":\"%A\",\"http_referer\":\"%{Referer}i\",\"http_user_agent\":\"%{User-agent}i\",\"body_bytes_sent\":\"%B\",\"total_bytes_sent\":\"%O\"}" access_log_json
CustomLog logs/access.log access_log_json
这里通过LogFormat指令定义了日志输出格式,在这个自定义日志输出中,定义了13个字段,定义方式为:字段名称:字段内容,字段名称是随意指定的,能代表其含义即可,字段名称和字段内容都通过双引号括起来,而双引号是特殊字符,需要转移,因此,使用了转移字符“\”,每个字段之间通过逗号分隔。此外,还定义了一个时间字段 @timestamp,这个字段的时间格式也是自定义的,此字段记录日志的生成时间,非常有用。CustomLog指令用来指定日志文件的名称和路径。
需要注意的是,上面日志输出字段中用到了body_bytes_sent和total_bytes_sent发送字节数统计字段,这个功能需要apache加载mod_logio.so模块,如果没有加载这个模块的话,需要安装此模块并在httpd.conf文件中加载一下即可。
1.4 验证日志输出
apache的日志格式配置完成后,重启apache,然后查看输出日志是否正常,如果能看到类似如下内容,表示自定义日志格式输出正常:
{"@timestamp":"2021-10-9T0:17:28+0800","client_ip":"192.168.50.21","direct_ip": "192.168.5.13","request_time":0,"status":200,"url":"/img/logstash1.png","method":"GET","http_host":"192.168.5.3","server_ip":"192.168.5.3","http_referer":"http://192.168.5.13/img/","http_user_agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0","body_bytes_sent":"163006","total_bytes_sent":"163266"}
在这个输出中,可以看到,client_ip和direct_ip输出的异同,client_ip字段对应的变量为“%{X-Forwarded-For}i”,它的输出是代理叠加而成的IP列表,而direct_ip对应的变量为%a,表示不经过代理访问的直连IP,当用户不经过任何代理直接访问apache时,client_ip和direct_ip应该是同一个IP。
1.5 配置filebeat
filebeat是安装在业务服务器上的,关于filebeat的安装与基础应用,在前面章节已经做过详细介绍了,这里不再说明,仅给出配置好的filebeat.yml文件的内容:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/httpd/access.log
fields:
log_topic: apachelogs
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
name: 192.168.5.3
output.kafka:
enabled: true
hosts: ["192.168.5.4:9092", "192.168.5.5:9092", "192.168.5.6:9092"]
# version: "2.2.2"
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
这个配置文件中,是将apache的访问日志/var/log/httpd/access.log内容实时的发送到kafka集群topic为apachelogs中。需要注意的是filebeat输出日志到kafka中配置文件的写法。
1.6 配置logstash
下面直接给出logstash事件配置文件kafka_apache_into_es.conf的内容:
输入:
input {
kafka {
bootstrap_servers => "192.168.5.4:9092,192.168.5.5:9092,192.168.5.6:9092“ #指定输入源中kafka集群的地址。
topics => "apachelogs" # 指定输入源中需要从哪个topic中读取数据。
group_id => "logstash"
codec => json {
charset => "UTF-8" # 将输入的json格式进行UTF8格式编码。
}
add_field => { "[@metadata][tagid]" => "apacheaccess_log" } #增加一个字段,用于标识和判断,在output输出中会用到。
}
}
过滤:
filter {
if [@metadata][tagid] == "apacheaccess_log" {
mutate {
gsub => ["message", "\\x", "\\\x"] # 这里的message就是message字段,也就是日志的内容。这个插件的作用是将message字段内容中UTF-8单字节编码做替换处理,这是为了应对URL有中文出现的情况。
}
if ( 'method":"HEAD' in [message] ) { # 如果message字段中有HEAD请求,就删除此条信息。
drop {}
}
json { # 这是启用json解码插件,因为输入的数据是复合的数据结构,只是一部分记录是json格式的。
source => "message" # 指定json格式的字段,也就是message字段。
add_field => { "[@metadata][direct_ip]" => "%{direct_ip}"} # 这里添加一个字段,用于后面的判断。
remove_field => "@version" # 从这里开始到最后,都是移除不需要的字段,前面九个字段都是filebeat传输日志时添加的,没什么用处,所以需要移除。
remove_field => "prospector"
remove_field => "beat"
remove_field => "source"
remove_field => "input"
remove_field => "offset"
remove_field => "fields"
remove_field => "host"
remove_field => "message" # 因为json格式中已经定义好了每个字段,那么输出也是按照每个字段输出的,因此就不需要message字段了,这里是移除message字段。
}
mutate {
split => ["client_ip", ","] # 这是对client_ip这个字段按逗号进行分组切分,因为在多级代理情况下,client_ip获取到的IP可能是IP列表,如果是单个ip的话,也会进行分组,只不过是分一个组而已。
}
mutate {
replace => { "client_ip" => "%{client_ip[0]}" } # 将切分出来的第一个分组赋值给client_ip,因为client_ip是IP列表的情况下,第一个IP才是客户端真实的IP。
}
if [client_ip] == "-" { # 这是个if判断,主要用来判断当client_ip为"-"的情况下,当direct_ip不为"-"的情况下,就将direct_ip的值赋给client_ip。因为在client_ip为"-"的情况下,都是直接不经过代理的访问,此时direct_ip的值就是客户端真实IP地址,所以要进行一下替换。
if [@metadata][direct_ip] not in ["%{direct_ip}","-"] { # 这个判断的意思是如果direct_ip非空。
mutate {
replace => { "client_ip" => "%{direct_ip}" }
}
} else {
drop{}
}
}
mutate {
remove_field => "direct_ip" # direct_ip只是一个过渡字段,主要用于在某些情况下将值传给client_ip,因此传值完成后,就可以删除direct_ip字段了。
}
}
}
输出:
output {
if [@metadata][tagid] == "apacheaccess_log" { # 用于判断,跟上面input中[@metadata][tagid]对应,当有多个输入源的时候,可根据不同的标识,指定到不同的输出地址。
elasticsearch {
hosts => ["192.168.5.8:9200","192.168.5.9:9200","192.168.5.10:9200"] # 这是指定输出到elasticsearch,并指定elasticsearch集群的地址。
index => "logstash_apachelogs-%{+YYYY.MM.dd}" # 指定apache日志在elasticsearch中索引的名称,这个名称会在Kibana中用到。索引的名称推荐以logstash开头,后面跟上索引标识和时间。
}
}
}
1.7 配置Kibana
filebeat收集数据到kafka,然后logstash从kafka拉取数据,如果数据能够正确发送到elasticsearch,我们就可以在Kibana中配置索引了。
登录Kibana,首先配置一个index_pattern,点击kibana左侧导航中的Management菜单,然后选择右侧的Index Patterns按钮,最后点击左上角的Create index pattern。
2 ELK收集Nginx访问日志实战案例
2.1 ELK收集Nginx访问日志应用架构
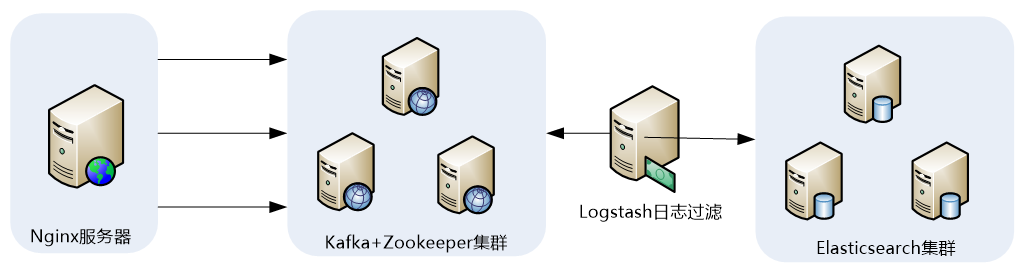
2.2 Nginx的日志格式与日志变量
Nginx跟Apache一样,都支持自定义输出日志格式,在进行Nginx日志格式定义前,先来了解一下关于多层代理获取用户真实IP的几个概念。
-
remote_addr:表示客户端地址,但有个条件,如果没有使用代理,这个地址就是客户端的真实IP,如果使用了代理,这个地址就是上层代理的IP。
-
X-Forwarded-For:简称XFF,这是一个HTTP扩展头,格式为 X-Forwarded-For: client, proxy1, proxy2,如果一个HTTP请求到达服务器之前,经过了三个代理 Proxy1、Proxy2、Proxy3,IP 分别为 IP1、IP2、IP3,用户真实IP为 IP0,那么按照 XFF标准,服务端最终会收到以下信息:
X-Forwarded-For: IP0, IP1, IP2
由此可知,IP3这个地址X-Forwarded-For并没有获取到,而remote_addr刚好获取的就是IP3的地址。
还要几个容易混淆的变量,这里也列出来做下说明:
-
$remote_addr:此变量如果走代理访问,那么将获取上层代理的IP,如果不走代理,那么就是客户端真实IP地址。
-
$http_x_forwarded_for:此变量获取的就是X-Forwarded-For的值。
-
$proxy_add_x_forwarded_for:此变量是$http_x_forwarded_for和$remote_addr两个变量之和。
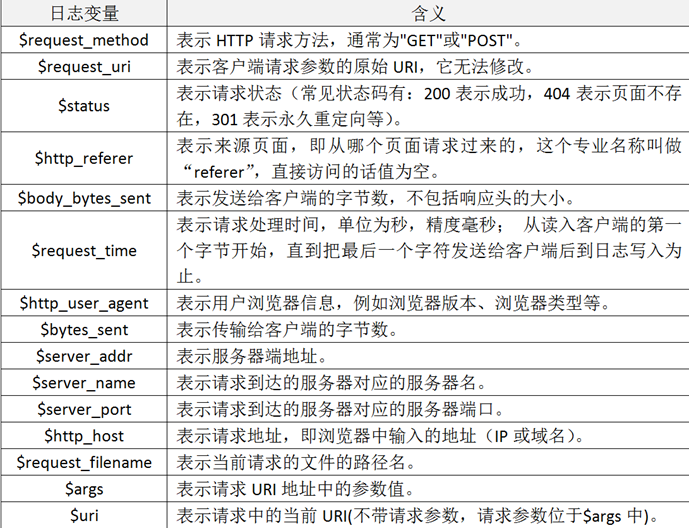
2.3 自定义Nginx日志格式
在掌握了Nginx日志变量的含义后,接着开始对它输出的日志格式进行改造,这里我们仍将Nginx日志输出设置为json格式,下面仅列出Nginx配置文件nginx.conf中日志格式和日志文件定义部分,定义好的日志格式与日志文件如下:
map $http_x_forwarded_for $clientRealIp {
"" $remote_addr;
~^(?P<firstAddr>[0-9\.]+),?.*$ $firstAddr;
}
log_format nginx_log_json '{"accessip_list":"$proxy_add_x_forwarded_for","client_ip":"$clientRealIp","http_host":"$host","@timestamp":"$time_iso8601","method":"$request_method","url":"$request_uri","status":"$status","http_referer":"$http_referer","body_bytes_sent":"$body_bytes_sent","request_time":"$request_time","http_user_agent":"$http_user_agent","total_bytes_sent":"$bytes_sent","server_ip":"$server_addr"}';
access_log /var/log/nginx/access.log nginx_log_json;
2.4 验证日志输出
{"accessip_list":"192.168.50.21, 192.168.5.7","client_ip":"192.168.5.13","http_host":"192.168.5.3","@timestamp":"2021-10-28T0:26:35+08:00","method":"GET","url":"/img/guonian.png","status":"304","http_referer":"-","body_bytes_sent":"1699956","request_time":"0.000","http_user_agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36","total_bytes_sent":"1700201","server_ip":"192.168.5.3"}
在这个输出中,可以看到,client_ip和accessip_list输出的异同,client_ip字段输出的就是真实的客户端IP地址,而accessip_list输出是代理叠加而成的IP列表
Nginx中获取客户端真实IP的方法很简单,无需做特殊处理,这也给后面编写logstash的事件配置文件减少了很多工作量。
2.5 配置filebeat
filebeat是安装在业务服务器上的,这里给出配置好的filebeat.yml文件的内容:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
log_topic: nginxlogs
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
name: 192.168.5.3
output.kafka:
enabled: true
hosts: ["192.168.5.4:9092", "192.168.5.5:9092", "192.168.5.6:9092"]
# version: "2.2.2"
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: debug
2.6 配置logstash
由于在Nginx输出日志中已经定义好了日志格式,因此在logstash中就不需要对日志进行过滤和分析操作了,下面直接给出logstash事件配置文件kafka_nginx_into_es.conf的内容:
输入:
input {
kafka {
bootstrap_servers => "192.168.5.4:9092,192.168.5.5:9092,192.168.5.6:9092"
topics => "nginxlogs" #指定输入源中需要从哪个topic中读取数据,这里会自动新建一个名为nginxlogs的topic
group_id => "logstash"
codec => json {
charset => "UTF-8"
}
add_field => { "[@metadata][myid]" => "nginxaccess-log" } #增加一个字段,用于标识和判断,在output输出中会用到。
}
}
过滤:
filter {
if [@metadata][myid] == "nginxaccess-log" {
mutate {
gsub => ["message", "\\x", "\\\x"] #这里的message就是message字段,也就是日志的内容。这个插件的作用是将message字段内容中UTF-8单字节编码做替换处理,这是为了应对URL有中文出现的情况。
}
if ( 'method":"HEAD' in [message] ) { #如果message字段中有HEAD请求,就删除此条信息。
drop {}
}
json {
source => "message"
remove_field => "prospector"
remove_field => "beat"
remove_field => "source"
remove_field => "input"
remove_field => "offset"
remove_field => "fields"
remove_field => "host"
remove_field => "@version“
remove_field => "message"
}
}
}
输出:
output {
if [@metadata][myid] == "nginxaccess-log" {
elasticsearch {
hosts => ["192.168.5.8:9200","192.168.5.9:9200","192.168.5.10:9200"]
index => "logstash_nginxlogs-%{+YYYY.MM.dd}" #指定Nginx日志在elasticsearch中索引的名称,这个名称会在Kibana中用到。索引的名称推荐以logstash开头,后面跟上索引标识和时间。
}
}
}
这个logstash事件配置文件非常简单,没对日志格式或逻辑做任何特殊处理,由于整个配置文件跟elk收集apache日志的配置文件基本相同,因此不再做过多介绍。所有配置完成后,就可以启动logstash了,执行如下命令:
cd /usr/local/logstash
nohup bin/logstash -f kafka_nginx_into_es.conf &
2.7 配置Kibana
Filebeat从nginx上收集数据到kafka,然后logstash从kafka拉取数据,如果数据能够正确发送到elasticsearch,我们就可以在Kibana中配置索引了。
标签:实战,ELK,log,ip,192.168,企业级,格式,日志,logstash 来源: https://www.cnblogs.com/weicunqi/p/15385262.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。