一、 预备知识:方程组解的存在性及引入
最小二乘法可以用来做函数的拟合或者求函数极值。在机器学习的回归模型中,我们经常使用最小二乘法。我们先举一个小例子来走进最小二乘法。
某次实验得到了四个数据点\((x,y):(1,6)、(2,5)、(3,7)、(4,10)\) (下图中红色的点)。我们希望找出一条与这四个点最匹配的直线 \(y = \theta_{1} + \theta_{2}x\) ,即找出在某种"最佳情况"下能够大致符合如下超定线性方程组的 \(\theta_{1}\) 和 \(\theta_{2}\) ,我们把四个点代入该直线方程可得:
\[\theta_{1} + 1 \theta_{2} = 6\\ \theta_{1}+2\theta_{2}=5\\ \theta_{1}+3\theta_{2}=7\\ \theta_{1}+4\theta_{2}=10 \]我们要求的是\(\theta_{1}\)和\(\theta_{2}\) 两个变量,但是这里列出了四个方程组,我们是无法求解的。我们现在以向量空间的角度来解释为何无解,以及最小二乘法如何处理这种无解的情况。
\[Ax = b\\ \begin{bmatrix} 1 & 1 \\ 1 & 2 \\ 1 & 3 \\ 1 & 4 \\ \end{bmatrix} _{4\times2} \begin{bmatrix} \theta1\\ \theta2 \end{bmatrix}_{2\times1} = \begin{bmatrix} 6\\ 5\\ 7\\ 10 \end{bmatrix}_{4\times1} \]我们将四个方程组成的方程组写成矩阵形式。矩阵A代表系数,\(x\)即待求的参数,\(b\)是每个方程对应的值。
从线性代数的角度来看,要判断\(Ax=b\)是否有解可以从向量空间角度来看。
这里先给出向量空间的性质:
-
向量空间要求取其任意取两个列向量\(v\)和\(w\),\(v+w\)或者\(cv\)(c是一个常数)都要属于该向量空间,并且任意列向量数乘的排列组合\(cv+dw+ek\)(c,d,e表示常数,v,w,k表示任意的列向量)也要属于该向量空间。若满足此条件,则可说明这是一个向量空间。
-
最大的向量空间是某个维度的全部空间,比如四维空间就是就是向量空间\(R_4\)的最大向量空间,最小向量空间是零空间,即由0组成的向量空间。
要看一个方程组有没有解,我们要看矩阵A的列向量所有的排列组合是否能够表示向量b的值。矩阵A有四个方程,即矩阵A由四个分量组成,所以它的向量空间记为\(R^4\),而列向量有两个,列向量的所有排列组合组成的空间是列空间(column space),列空间是\(R^4\)的子空间。对于矩阵\(A_{m\times n}\),如果\(m>n\),就像这个例子\(m=4,n=2\),二维的列向量排列组合所得到的列向量空间撑死也只能充满整个二维空间(如果有列的线性无关项就更少了),而对于四维的向量空间\(R^4\),这个例子中列向量空间是远远达不到的。那么,当向量\(b\)的值在列向量空间之外时,就无法求解反之则有解。所以说,只要向量\(b\)是A的列向量的排列组合就能使\(x\)有解。
顺便再从另外一个角度来思考,为什么对于\(Ax=0\)来说是一定有解的呢?很简单的啦,你发现列向量的排列组合肯定是能够得到0向量的,只需要让列向量和0进行数乘即可。所以0向量\(b\)一定是能由列向量的排列组合得到,因此它一定有解。
注意:\(m>n\)不一定就代表无解,有时候矩阵可能会有行的线性无关项,某行线性无关就是说某一行可以通过另外两行进行乘、加操作后得到。\(m>n\)的方程组可以叫做超定方程组。而曲线拟合的最小二乘法要解决的问题,实际上就是以上超定方程组最小二乘解的问题。
我们把A的咧空间抽象成一个超平面,b可以抽象成一个向量。当对于无解的超定方程组时(即b不在超平面上),我们可以在超平面上找一个最接近的向量b,假设这个最接近的向量是Ax*(其中x*就是最优的参数解),那么,向量b和向量Ax*之间的距离应该是最小的。所以可以通过最小化b和Ax*之间的距离来求出x*。
二、 最小二乘法的原理及解释
最小二乘法的原理还是很简单的,形式如下:
\[目标函数 = \sum (观测值 - 理论值)^2 \]观测值(样本值)就是我们的多组样本,理论值(预测值)就是我们假设的拟合函数对应的值。目标函数也叫做损失函数,如上所说,我们的目标是得到使损失函数最小化时拟合函数的模型(即此时对应的参数)。举一个最简单的一元线性回归的例子,比如我们有m个样本,每个样本只有一个特征:
\[(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...(x^{(m)},y^{(m)}) \]我们选定一个用于拟合曲线的函数为:
\[h_{\theta}(x) = \theta_{0} + \theta_{1}x \]我们的目标函数一般形式为:
\[J(\theta_{0},\theta_{1}) = \sum_{i=1}^m(y^{(i)}-h_{\theta}(x))^2\\=\sum_{i=1}^m(y^{(i)}-\theta_{0}-\theta_{1}x^{(i)})^2 \]我们就是要求出当函数\(J(\theta_0,\theta_1)\)最小时的\(\theta_0\)和\(\theta1\)。
下面这张图是第一部分的四个数据点(红色),以及用最小二乘法拟合的曲线(蓝色的直线)。通过图像形象的表示就是最小二乘法要根据预先选择的拟合函数(\(y=\theta_0+\theta_1 x\))找到一条曲线,让所有的绿色线段的距离加起来的值最小。
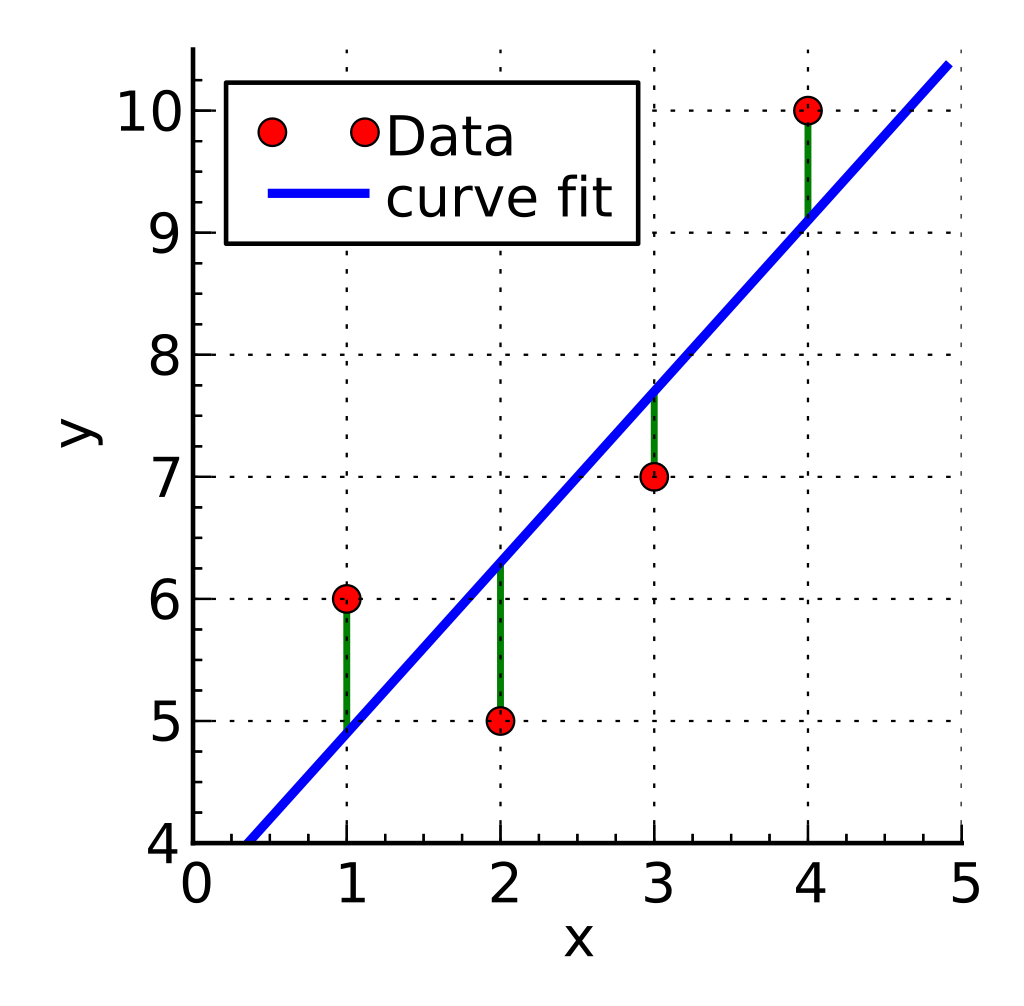
下面我们会通过代数法和矩阵法来进行求解过程的推导。
三、用代数法求解最小二乘法
代数解法就是分别对参数\(\theta_0,\theta_1\)分别求偏导数,并令其等于0,得到一个关于\(\theta_0\)和\(\theta_1\)的二元方程组。求解这个方程组就可以得到\(\theta_0\)和\(\theta_1\)的值,求导后得到以下方程组:
\[\frac{\partial E(\theta_0,\theta_1)}{ \partial \ \theta_0} =\sum_i^m(y^{(i)}-\theta_0 -\theta_1x^{(i)}) = 0 \tag{1} \]\[\frac{\partial E(\theta_0,\theta_1)}{ \partial \ \theta_1} =\sum_i^m(y^{(i)}-\theta_0-\theta_1x^{(i)})x^{(i)} = 0 \tag{2} \](1)和(2)组成了一个二元一次方程组,可以求出\(\theta_0\)和\(\theta_1\)的值:
\[b = \theta_0 = \frac{1}{m} \sum_{i=1}^m(y^{(i)}-\theta_1x^{(i)})\\ \]\[w = \frac{\sum_{i=1}^my_{i}(x^{(i)}- \overline x)}{\sum_{i=1}^m(x^{(i)})^2-\frac{1}{m}(\sum_{i=1}^mx^{(i)})^2} \tag{其中$\overline x = \frac{1}{m}\sum_{i=1}^mx^{(i)}$为$x$的均值} \]这个方法很容易推导到多个样本特征的非线性拟合。原理和上面的一样,都是用损失函数对各个参数求导为0,然后求解方程组得到参数值。
四、用矩阵法求解最小二乘法
因为矩阵运算可以取代循环(也就是将其向量化),可以让矩阵法比代数法要更加的简洁。
对于一个数据集,样本由\(n\)个类似的,我们用最小二乘法来对\(w\)和\(b\)来进行估计。为了方便讨论,我们把\(w\)和\(b\)进行合并乘一个向量 \(\hat w = (w_i;b)\);(这里为了比较好分辨,就不要再用\(\theta_0 \theta_1\)来表示了,用\(w,b\))把。把数据集表示成一个\(M \times N+1\)大小的矩阵\(X\),其中每行对应一条数据,该行的前N列对应于数据的N个属性值(特征值),最后一个元素恒置为1,目的是当\(X\hat w\)时令1与\(\hat w\)中的b相乘,则所得的每行都是$x_1^Tw_1 +b $的形式。
\[X = \left[ \begin{matrix} x_{11} & x_{12} & \cdots & x_{1n} & 1 \\ x_{21} & x_{22} & \cdots & x_{2n} & 1 \\ \vdots & \vdots & \ddots & \vdots &\vdots\\ x_{m1} & x_{m2} & \cdots &x_{mn} & 1\\ \end{matrix} \right] = \left[ \begin{matrix} x_1^T & 1 \\ x_2^T & 1 \\ \vdots &\vdots\\ x_m^T & 1\\ \end{matrix} \right] \]再把标记(即数据集的\(y\)值)也写成向量的形式\(y = (y_1;y_2;y_3;...;y_m)\),则有:
\[\hat w^* = \begin{equation} \mathop{\arg\min}_{\hat w} \end{equation} (y - X \hat w )^T(y - X\hat w). \]令\(E_{\hat w} = (y - X \hat w)^T(y - X \hat w)\),对\(\hat w\)求导得到:
\[\frac{\partial E_{\hat w}}{\partial \hat w} = 2 X^T(X\hat w - y) \]令上面的式子为0即可得到\(\hat w\)最优解的闭式解。当\(X^TX\)为满秩矩阵时,令其等于0可以得到,
\[\hat y^* = (X^TX)^{-1}X^Ty \]其中\((X^TX)^{-1}\)是矩阵\((X^TX)\)的逆矩阵,因为只有满秩矩阵才可逆。令\(\hat x_i = (x_i;1)\),则最终学得的多元线性回归模型为 \(f(\hat x_i) = \hat x_i^T(X^TX)^{-1}X^Ty\)。
但是,由于现实生活中\(X^TX\)往往不是满秩矩阵,例如有时候会遇到大量变量,数目甚至超过了样本数目,导致\(X\)的列数多于行数,此时明显不是满秩。从线性方程组角度来思考就是,当因变量过多的时候(即方程个数小于未知数个数的方程组),对于这种方程组我们叫做欠定方程组,该方程组的解不是唯一的,可能有无穷多组解。我们可以引入正则化来解决。这里就先不具体去阐述什么是正则化了。
五、 总结
此部分摘自 刘建平Pinard 博客园对于最小二乘法的总结。
从上面可以看出,最小二乘法适用简洁高效,比梯度下降这样的迭代法似乎方便很多。但是这里我们就聊聊最小二乘法的局限性。
首先,最小二乘法需要计算\(X^TX\)的逆矩阵,有可能它的逆矩阵不存在,这样就没有办法直接用最小二乘法了,此时梯度下降法仍然可以使用。当然,我们可以通过对样本数据进行整理,去掉冗余特征。让\(X^TX\)可逆(满秩,行列式值不为0),然后继续使用最小二乘法。
第二,当样本特征n非常的大的时候,计算\(X^TX\)的逆矩阵是一个非常耗时的工作(\(n\times n\)的矩阵求逆),甚至不可行。此时以梯度下降为代表的迭代法仍然可以使用。那这个\(n\)到底多大就不适合最小二乘法呢?如果你没有很多的分布式大数据计算资源,建议超过10000个特征就用迭代法吧。或者通过主成分分析降低特征的维度后再用最小二乘法。
第三,如果拟合函数不是线性的,这时无法使用最小二乘法,需要通过一些技巧转化为线性才能使用,此时梯度下降仍然可以用。
第四,讲一些特殊情况。当样本量m很少,小于特征数n的时候,这时拟合方程是欠定的,常用的优化方法都无法去拟合数据。当样本量m等于特征数n的时候,用方程组求解就可以了。当m大于n时,拟合方程是超定的,也就是我们常用与最小二乘法的场景了。
标签:推导,矩阵,最小,theta,hat,向量,乘法 来源: https://www.cnblogs.com/boostwei/p/14880143.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。