标签:Kinesis STREAM Amazon S3 AWS lab1 Lab1 数据处理 Data
为了使练习更加贴近实际业务场景,我们将模拟从应用程序中生成交易订单事件,在这种情况下是与交易流水、交易日期、客户编号、产品编号和一些数据相对应的事件流。在此教程中,将完成以下三个步骤的实验:
• 创建 Amazon Kinesis Data Stream
• 创建 Amazon Kinesis Data Analytics 应用程序
• 创建 Amazon Kinesis Data Firehose 将数据传送到 Amazon S3(Lab2 和 Lab3 需要用到)
上述三个步骤的实验的架构图如下
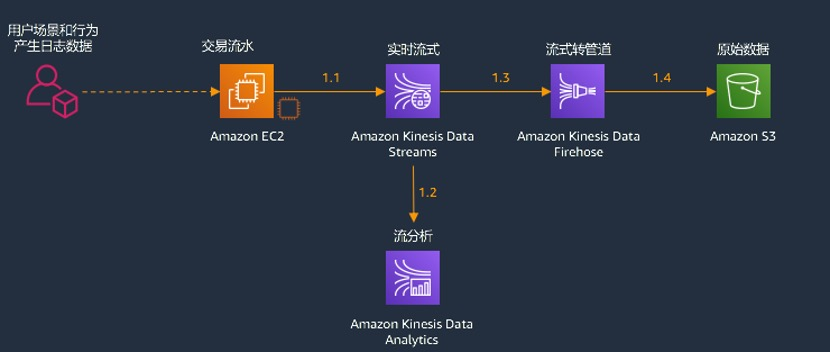
Kinesis 流数据产生
发送模拟数据
登录准备阶段部署的 EC2,保存如下代码到 ec2-user 的 home 目录下,我使用的 AWS 区域为us-east-1,如果你在其他区域创建的 EC2,请修改代码里面的region_name。
https://imgs.wzlinux.com/aws/lab1.sh
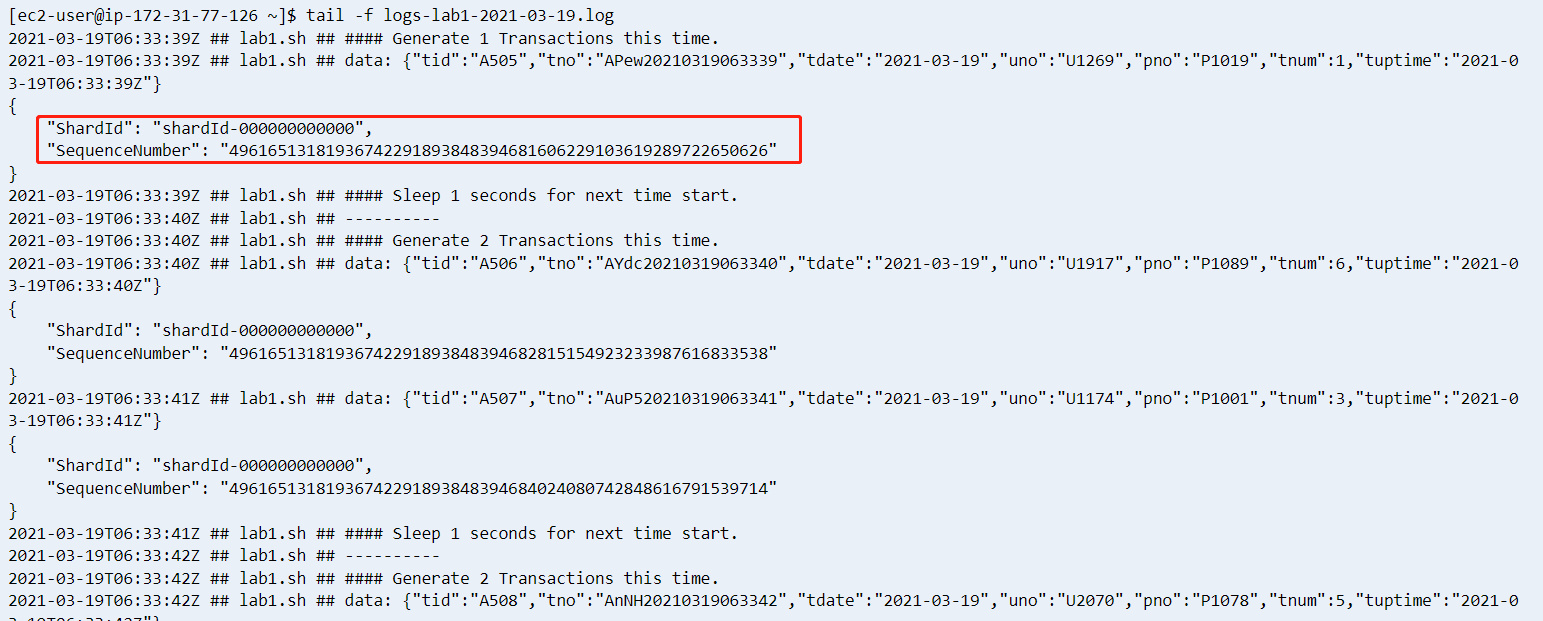
然后执行如下代码开始给 Kinesis Data Streams 流平台发送模拟数据(这个2021-03-19在系统内是个交易日期,方便后续作为关键字查找,没有特殊的含义)
[ec2-user@ip-172-31-77-126 ~]$ sh lab1.sh kds-lab1 2021-03-19 &
[1] 2768lab1.sh会往 kds 流里面灌数据,格式为
- tid: 交易id
- tno: 交易编号
- tdate: 交易日期
- uno: 客户编号
- pno: 产品编号
- tnum: 交易数量
- tuptime: 时间戳
如下仅供参考
{
"tid": "123",
"tno": "AwGi20200904131249",
"tdate": "2021-03-19",
"uno": "U1030",
"pno": "P1002",
"tnum": 10,
"tuptime": "2021-03-19T13:15:48Z"
}系统会生成一个日志文件,查看同一个目录下的日志文件,出现如下字样表示启动成功
准备S3存储桶
因为S3桶是全球唯一的命名,所以为了区分,我们采用如下的方式命名S3存储桶,如下所示
lab-AccountId-wzlinux-com打开EC2客户端,使用如下命令创建S3桶(也可以直接在控制台创建,此处略)
aws s3 mb s3://lab-921283538843-wzlinux-com/
aws s3 ls | grep lab如下

创建S3终端节点
为了方便内网访问 S3 存储桶,此处我们配置 S3 终端节点。登录并打开 VPC 控制台,往下拉选择左边的终端节点,选中 S3(在搜索框里面输入 S3 并回车即可搜索),选择对应 VPC(此处我们只有一个默认VPC)和路由表:
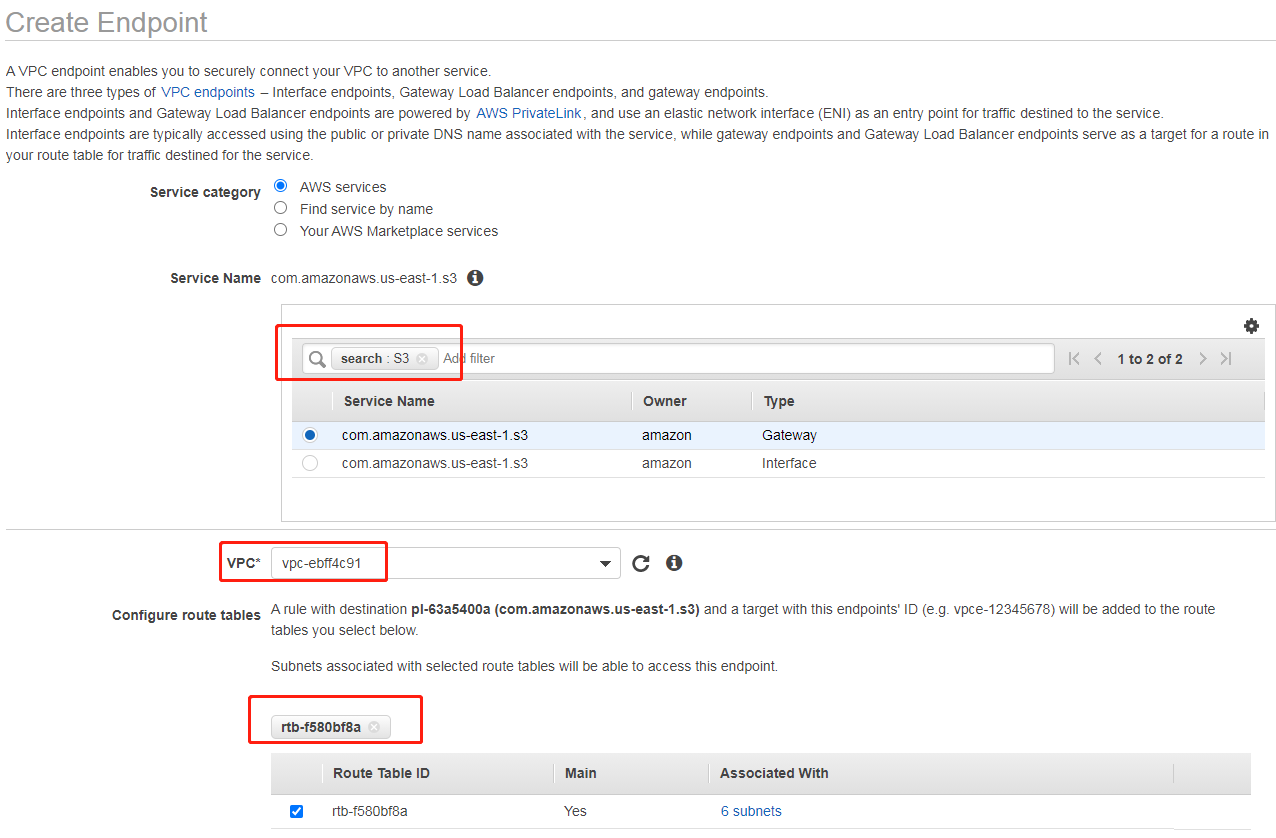
其他默认,点击“创建终端节点”即可。
Kinesis 流数据分析
本实验演示配置数据流管道(为 Lab2/3 准备),并实时对流数据进行在线分析等。
配置 Kinesis Data Firehose
KFH(Kinesis Data Firehose)是提供实时交付的完全托管服务,可以把流数据发往诸如 Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon Elasticsearch Service (Amazon ES)、Splunk 以及支持的第三方服务提供商(包括 DatAdog、MongoDB 和 NewRelic)拥有的任何自定义 HTTP 端点或 HTTP 端点。
打开 Kinesis 管理控制台,在左侧菜单栏选择 Delivery streams,在界面上点击“Create Delivery Stream”。

输入传输流的名字(此处为 lab1-kfh),并选择准备过程中创建的 Kinesis 数据流(此处为kds-lab1),然后点击下一步
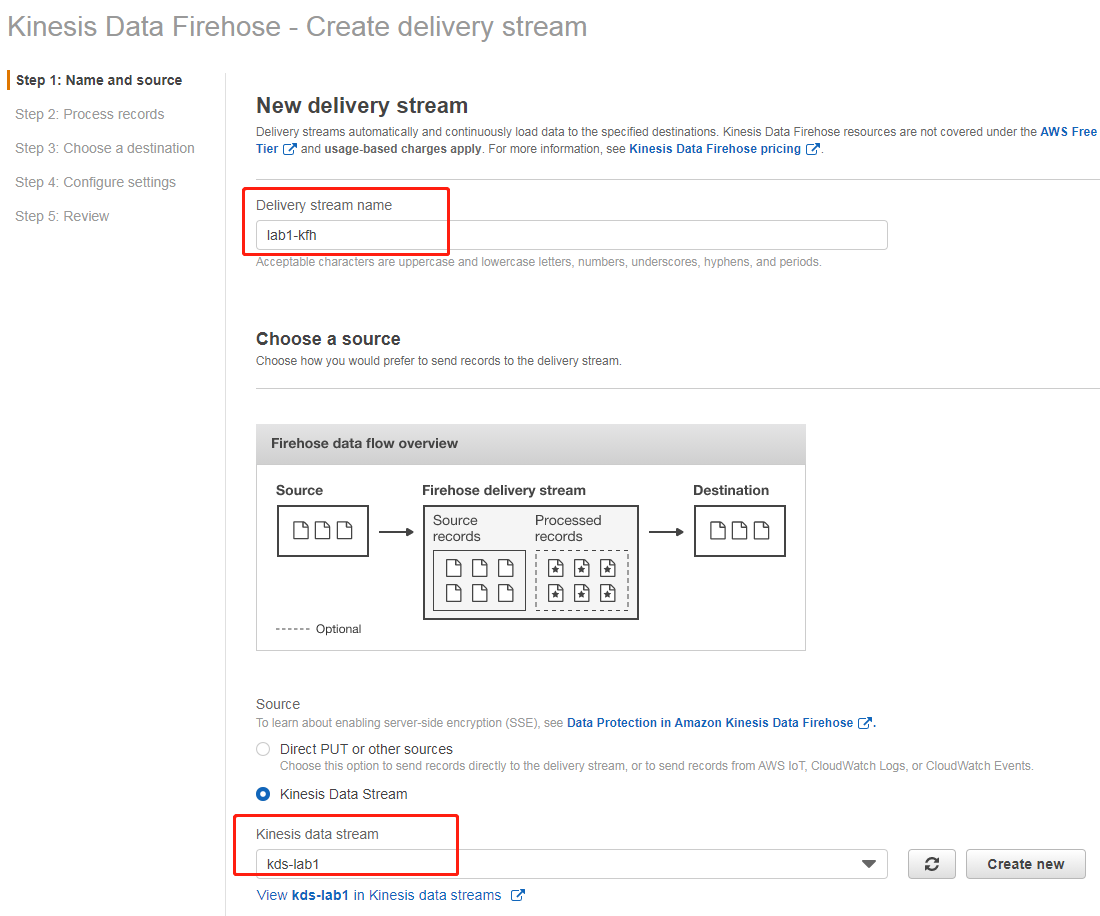
第二步处理记录选择默认,第三步目标我们选择 S3,并选择之前创建的存储桶(此处为:lab-921283538843-wzlinux-com)
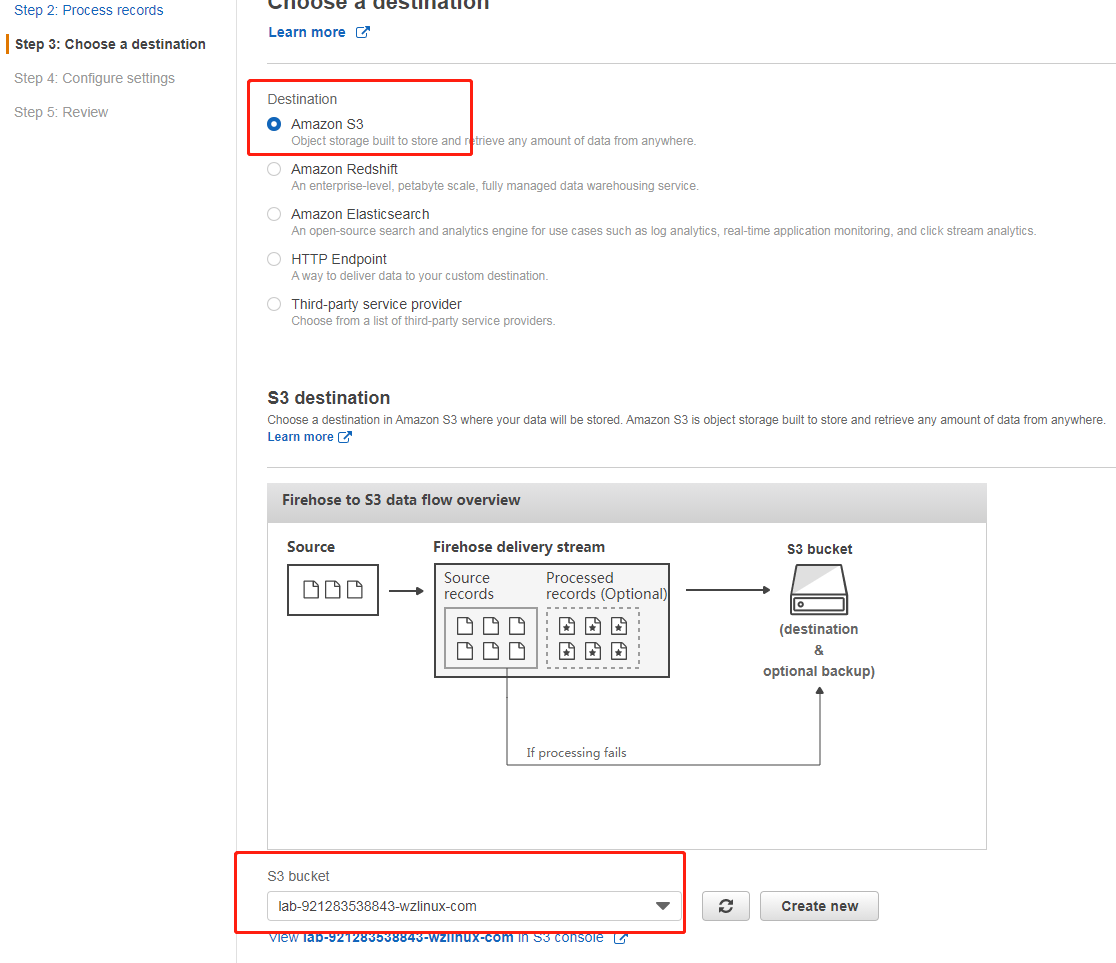
然后在 S3 前缀和后缀分配输入名字lab1-input/和lab1-error/,如下
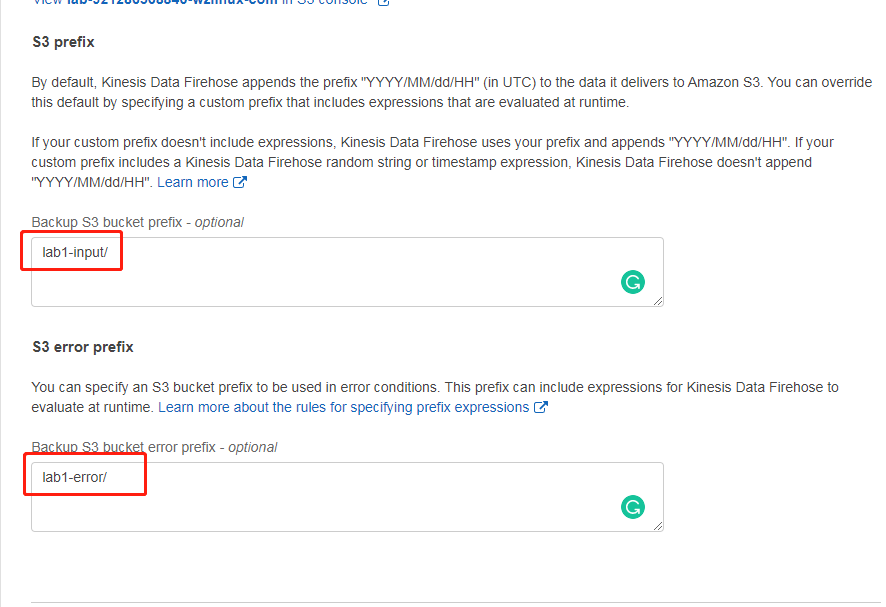
配置缓冲的时候,设置为“1”M和“60”秒,其他默认,点击下一步,然后审核并点击“Create delivery stream”
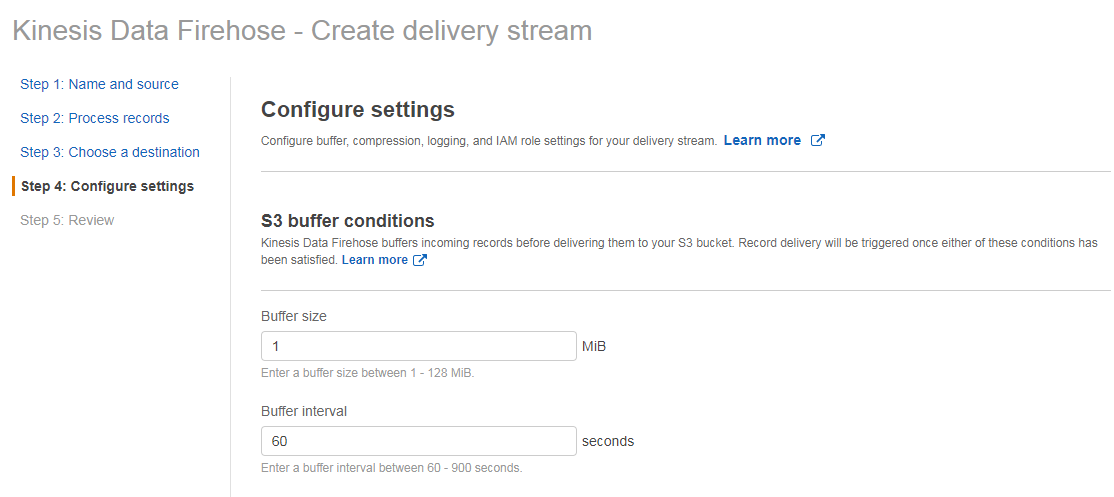
大概过 1 分钟左右,就可以在 S3 存储桶里面看到对应的数据输出。
配置 Kinesis Data Analytics
打开 Kinesis 管理控制台,在左侧菜单栏选择“Data Analytics”,在界面上点击“Create application”,然后输入名字(此处为kas-lab1)和运行时(SQL)即可
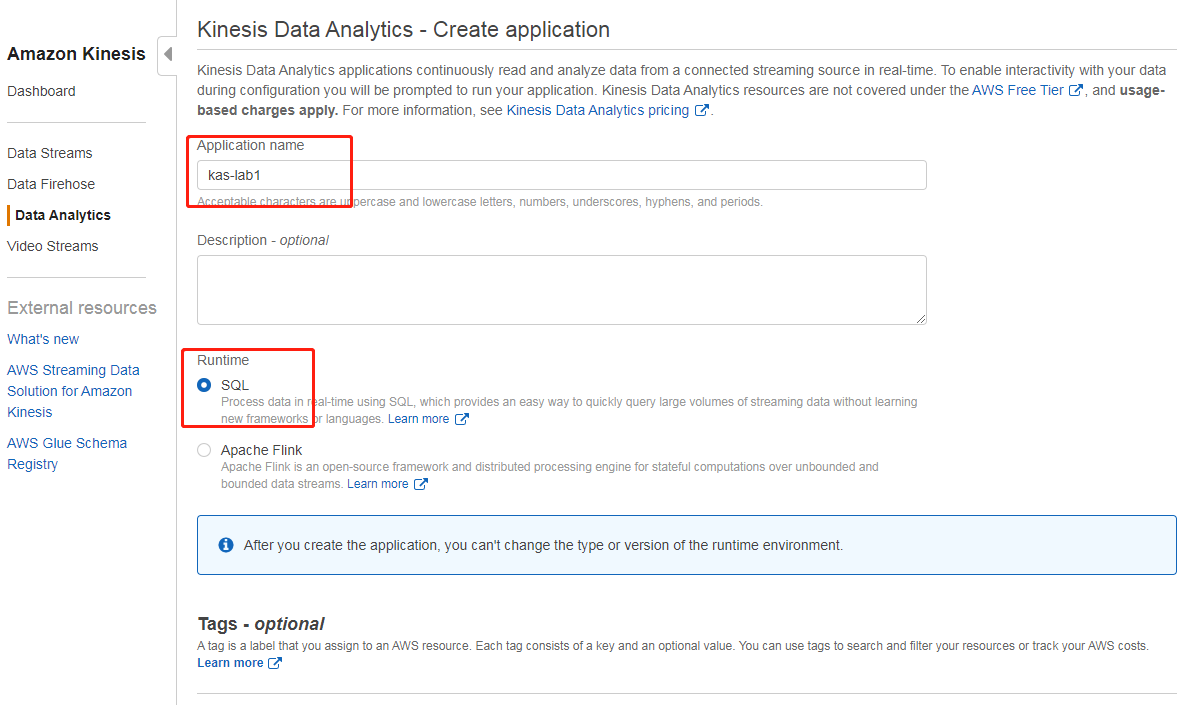
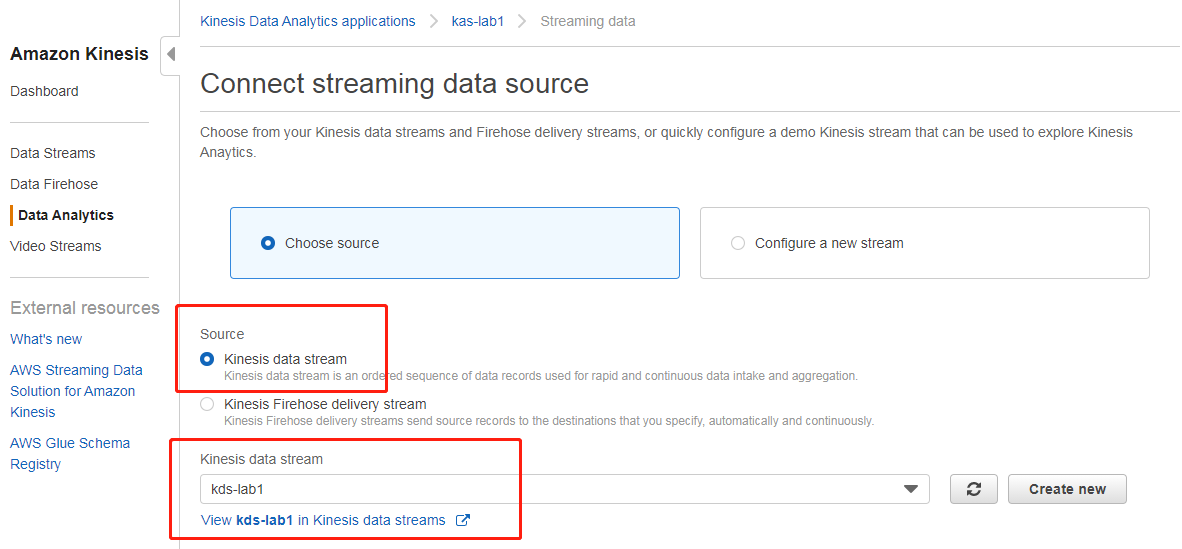
创建成功后,选择连接数据流(连接到之前准备阶段创建的 kds 数据流,此处为kds-lab1,已经通过脚本在送数据了)
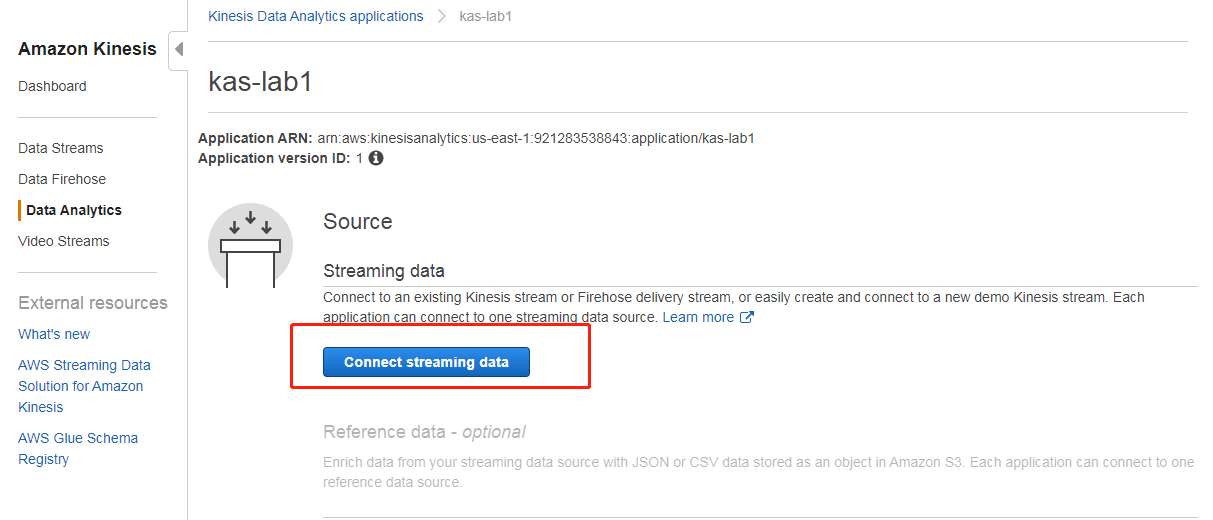
然后点击左下角的发现架构,开始获取元数据
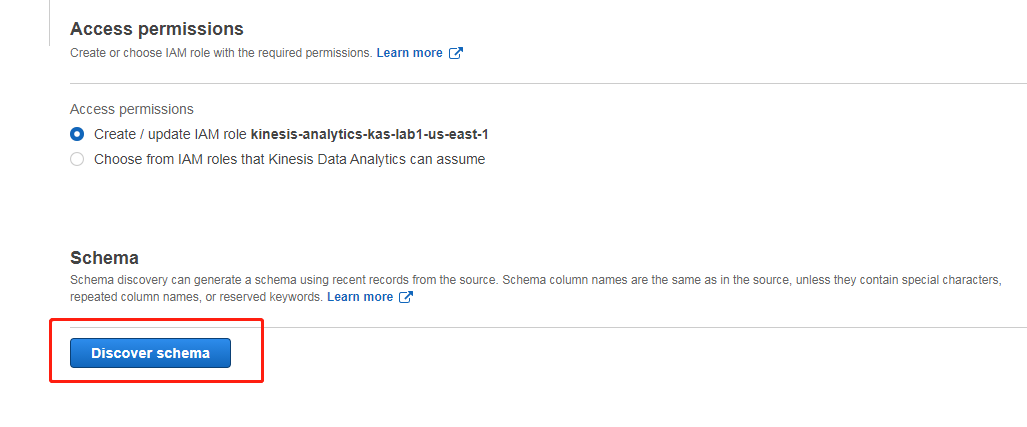
发现后的架构和数据格式跟我们预期的一致,所以此处不做更改,直接保存即可
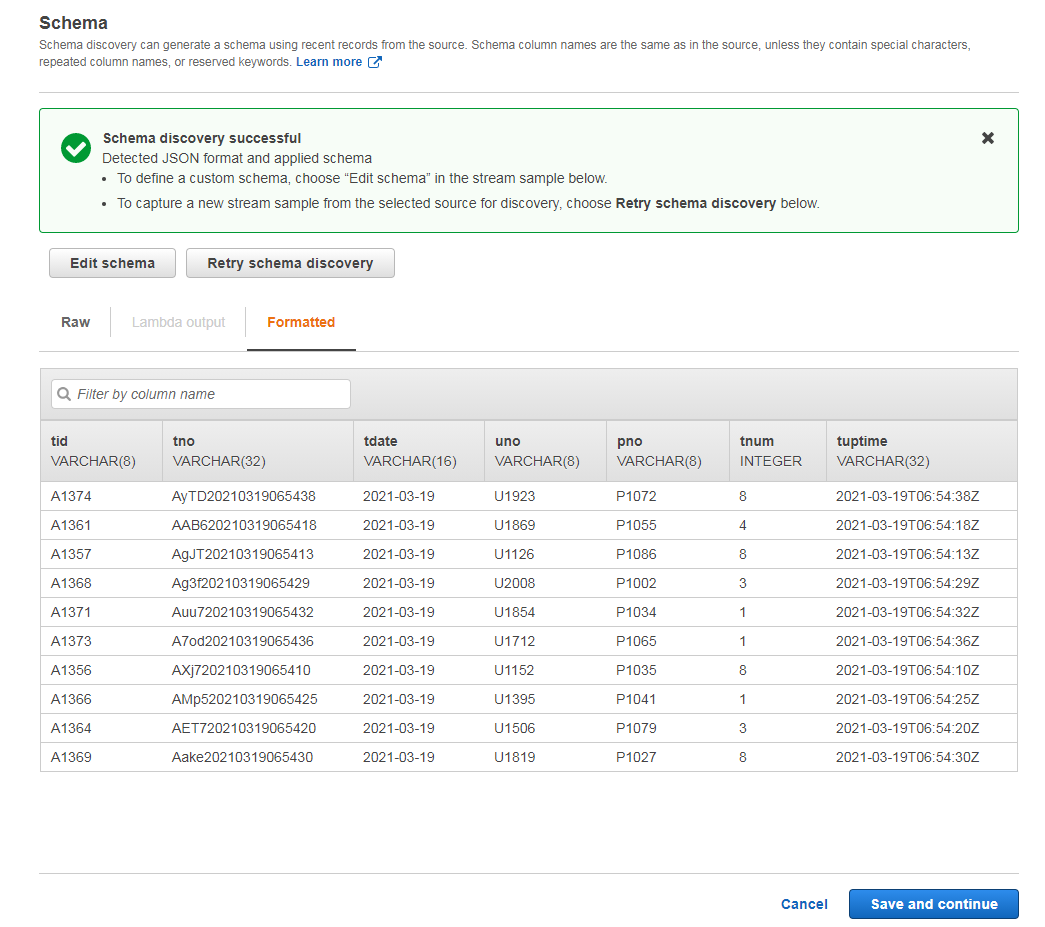
接下来我们选择用 SQL 做实时分析
然后使用如下 SQL 代码,保存并运行(我们此处演示按 1 分钟聚合,如果有其他聚合时间要求,可以修改最下面的60 这个数字即可)
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (count_tno integer,sum_tnum integer);
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM count(*), sum("tnum")
FROM "SOURCE_SQL_STREAM_001"
GROUP BY FLOOR(("SOURCE_SQL_STREAM_001".ROWTIME - TIMESTAMP '1970-01-01 00:00:00') SECOND / 60 TO SECOND);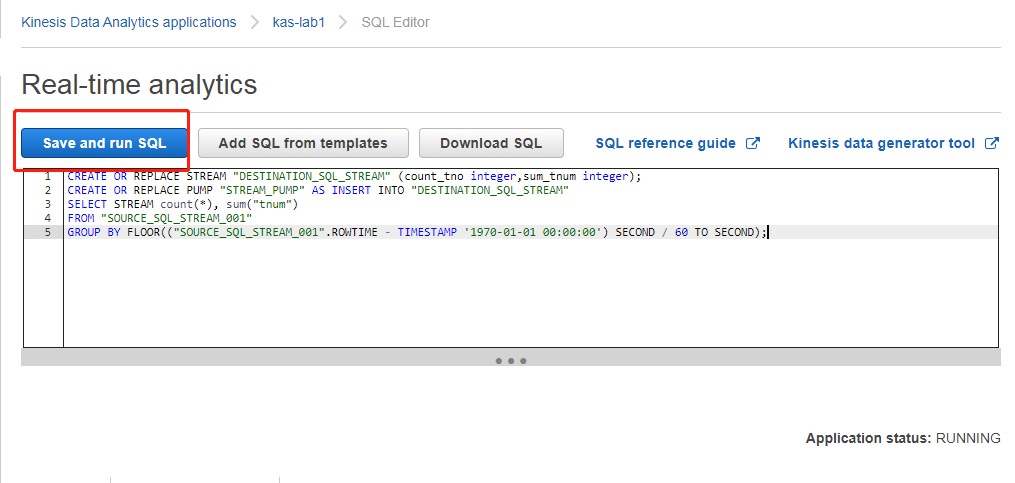
略微等待一小段时间,我们即可看到运行结果,如下所示(和我们的代码预期一致,一分钟一次聚合)
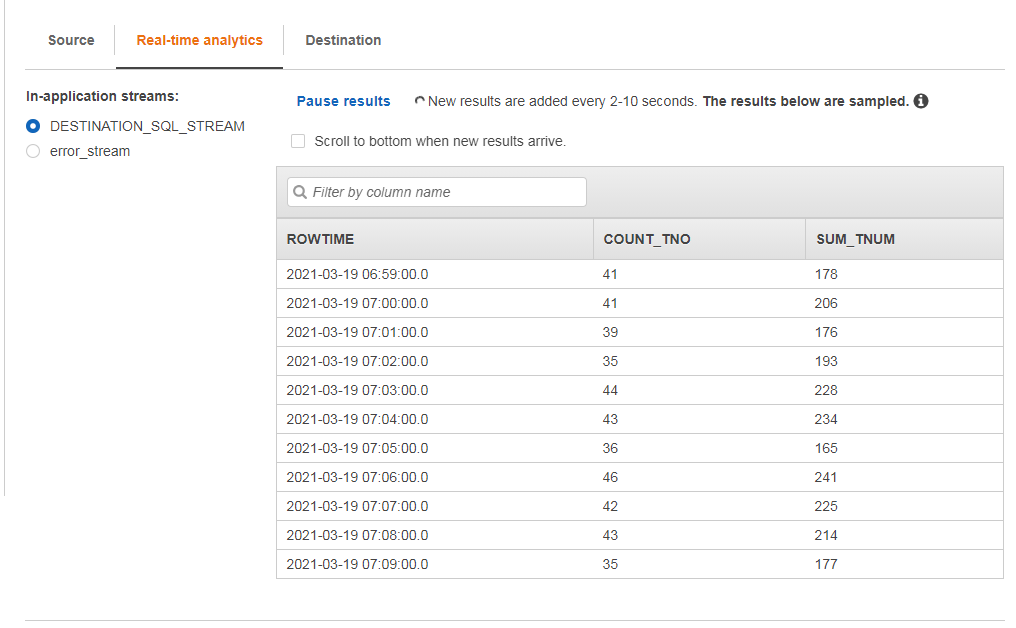
可以在目标页面把查询结果输出到别的地方,例如别的流,别的 S3 存储桶等用于业务用途,此处不做演示。
至此,关于流数据处理的动手实验(Lab1)已经完成。
欢迎大家扫码关注,获取更多信息

标签:Kinesis,STREAM,Amazon,S3,AWS,lab1,Lab1,数据处理,Data 来源: https://blog.51cto.com/wzlinux/2669464
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。