标签:Search 子网 DNA Knowledge 训练 supernet path teacher block
DNA
2020-CVPR-Blockwisely Supervised Neural Architecture Search with Knowledge Distillation
来源:ChenBong 博客园
- Institute:DarkMatter AI Research,Monash University,Sun Yat-sen University
- Author:Changlin Li,Jiefeng Peng,Liuchun Yuan
- GitHub:https://github.com/changlin31/DNA 140+
- Citation: 28
Motivation
共享参数的超网训练(SPOS)作为子网的性能评估器的准确性是很差的(进而导致后续搜索到的子网不是最佳的),由于超网空间太大,因此随机采样的训练方式不可能保证每个子网都得到充分的训练。
之前的工作发现,当supernet的空间越小,supernet对每个子网的性能评估的准确度越高。
但supernet空间又不能太小,如何保证supernet空间足够大的情况下,又能使supernet中的每个子网都能得到充分的训练?
Introduction
将 supernet 划分为相互独立的不同 block,平行训练不同的 block,最后再选择每个 block 中的最佳路径,组合成最终的网络。
这样组合出来的子网,每个路径都有充分的训练,即使用supernet作为评估器对不同子网的评估准确度较高。
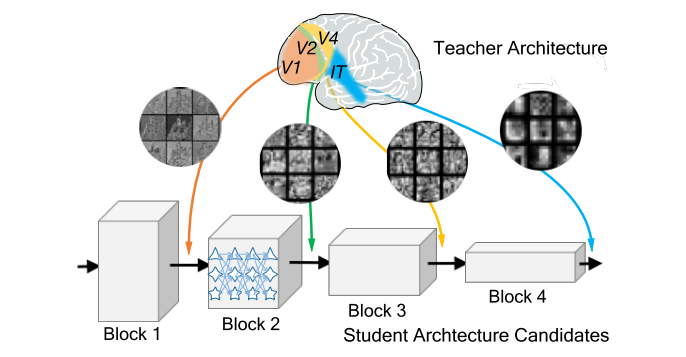
难点在于如何单独训练中间的某个block?引入 teacher model,用 teacher model 中间block的输入输出,来监督 student supernet 中间 block 的学习。
使用固定的 teacher,将 student supernet 划分为与 teacher 相同的 block,将 teacher 的每个 block 的输入输出作为 student supernet 对应block的训练数据<X, Y>,平行训练 student supernet 中的每个 block
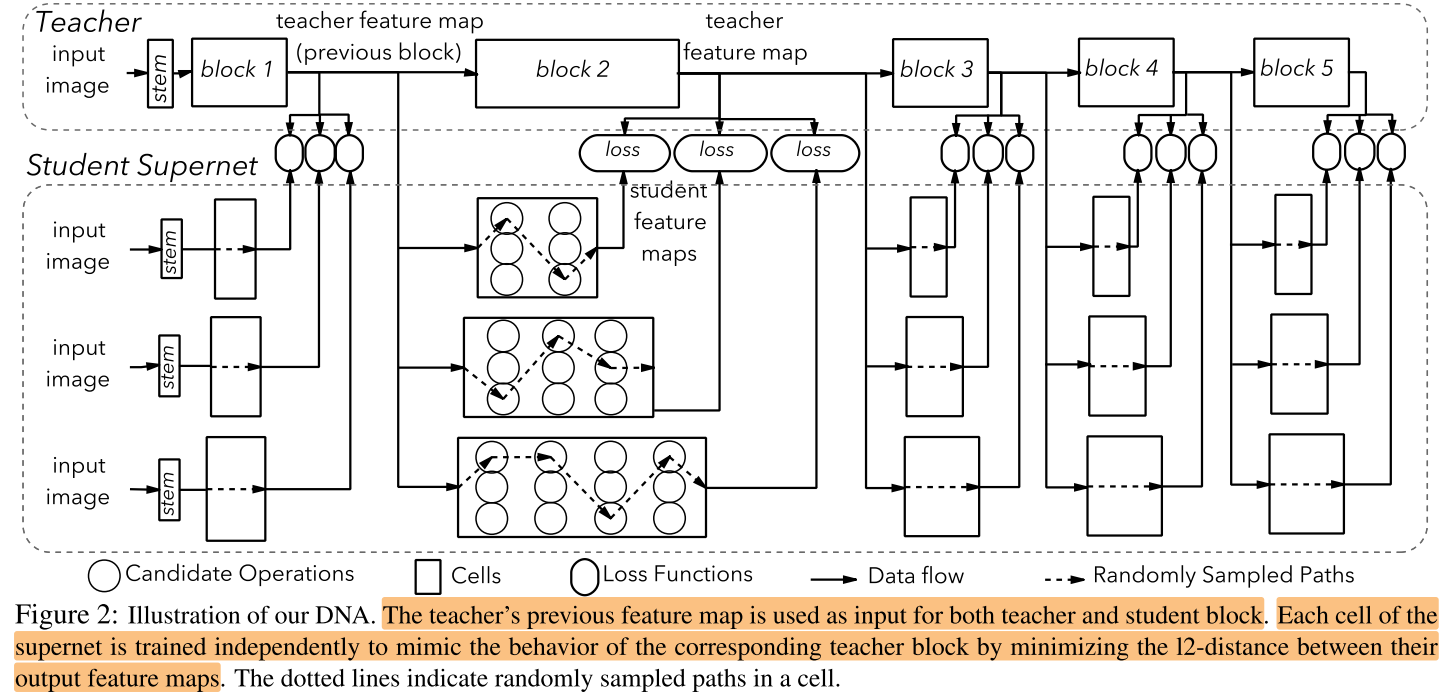
Contribution
- 将supernet划分为多个block,使得不同路径能得到充分训练
- inter layer KD 和 nas 的结合
Method
Pipeline
将 supernet 划分为N个blcok:
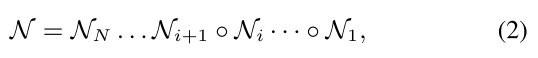
每个blcok可以单独训练,相当于训练多个很小的 supernet \(\mathcal A_i\):
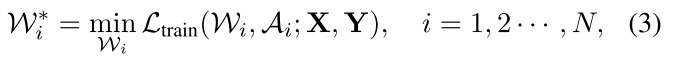
最终的最佳结构是在每个block中的最佳的path组合起来:
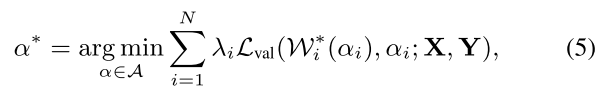
细节
Supernet 结构
teacher:EfficientNet-B0 (#Params=5.28M)
MobileNet V2 block
- kernel sizes of {3, 5, 7}
- expansion rates {3, 6}

student supernet 训练:inter layer KD
- teacher 参数不更新
- 训练时,每个block随机激活一条 path,可以将每个 block 看做一个小的 supernet,因此不同 block 的训练是互不影响的
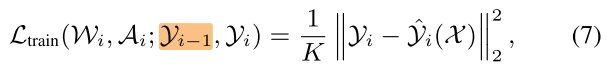
\(K\) 是 feature map \(\mathcal Y_i\) 的通道数
student supernet 评估与搜索
eval: 每个 block 中的 \(10^4\) 个 sub-path 分别评估,记录下ranking
search:按照贪心策略,做DFS,按照 block 顺序,优先选取 ranking 高的 sub-path,如果当前 sub-path 的 size 之和超出约束,则抛弃该子树下的所有节点,直至搜索到满足约束的 sub-path 组合,即最佳子网。
Experiments
cost
- train supernet:3*8 GPU days
- eval:0.6 GPU days
- search:less one hour CPU
ImageNet
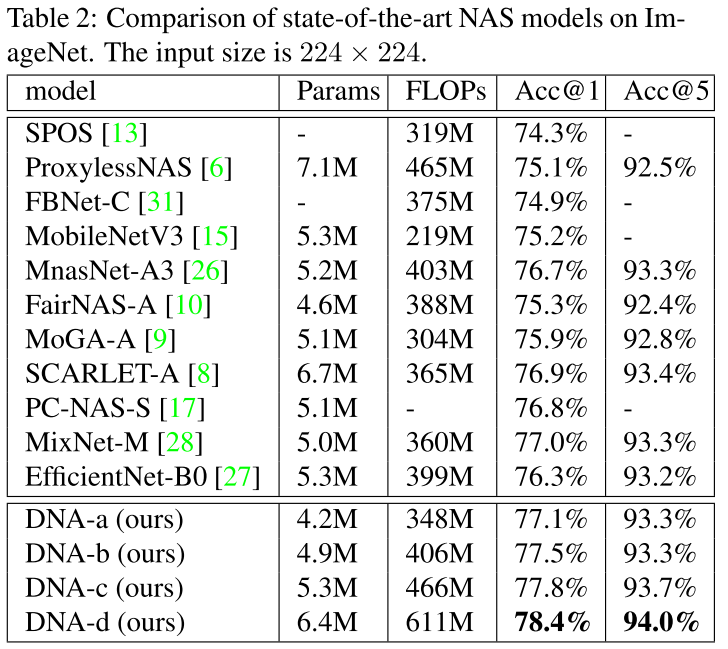
Ablation Study
Ranking
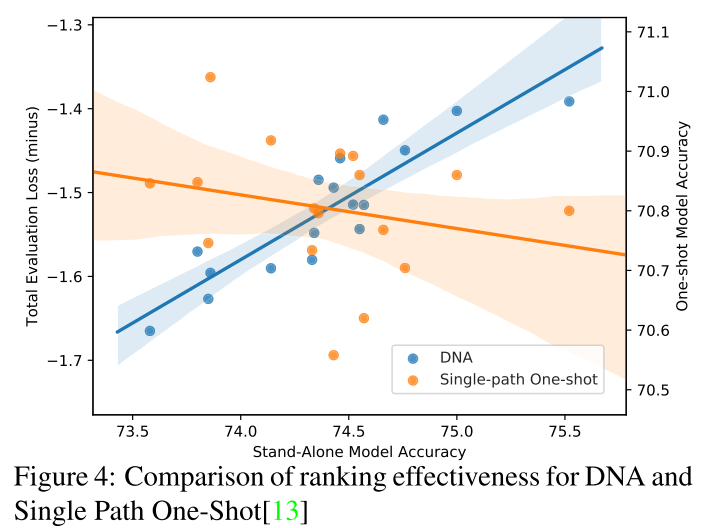
KD feature map 相似性

Teacher size
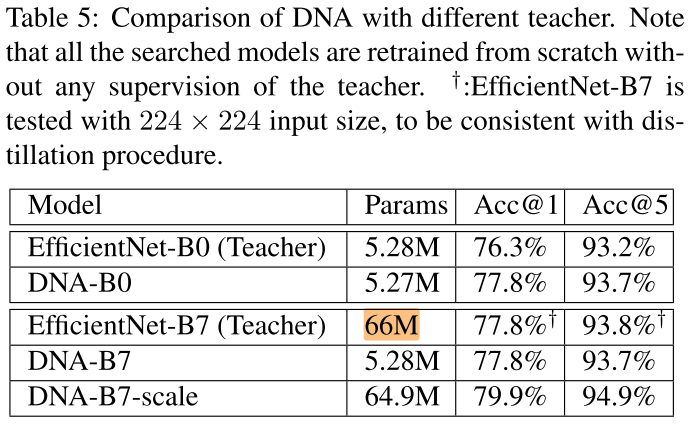
最终性能与 teacher size 和 teacher 性能无关
Conclusion
Summary
- 使用 KD 与 nas 结合较早的文章,需要额外的 teacher model,且 supernet 设计也会受到teacher 结构的影响
- teacher 网络一成不变,不知道如果 teacher 也同时从头训练会如何(协同进化)?
- 将 supernet 不同 stage 解耦独立(平行)训练的想法很 novel
To Read
Reference
https://www.jiqizhixin.com/articles/2020-03-19-8
https://zhuanlan.zhihu.com/p/148522339
https://blog.csdn.net/luzheai6913/article/details/105825587
标签:Search,子网,DNA,Knowledge,训练,supernet,path,teacher,block 来源: https://www.cnblogs.com/chenbong/p/14476748.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。