标签:轨迹 第二课 MC 笔记 周博磊 policy TD gamma 策略
第三课:Model-free prediction和Model-free control
-
什么是MDP已知?:
- 马尔可夫决策过程中它的奖励 \(R\) 以及状态转移概率矩阵 \(P\) 都是暴露给agent的,就是环境是提前提供给你的,你是已知的。
- 所以我们能够用策略迭代的方法policy iteration和值迭代的方法value iteration来寻找最佳的策略
-
MDP,policy evalution,policy iteration和value iteration用来解决
已知MDP的环境 -
Model-free:就是
未知MDP的情况,agent通过跟环境进行交互,获得观测以及奖励,来调整自身的行为,通过一系列的观测收集到的数据,来调整自己的策略。Model-free并没有直接获取整个环境的转移状态以及奖励函数,而是通过agent跟环境进行交互,采集到了很多的轨迹数据,这些轨迹数据可以表征成\(\{S_1,A_1,R_1,S_2,A_2,R_2,...,S_t,A_t,R_t\}\)
agent就从这些轨迹当中获取信息,改进自己的策略,以达到获得更多奖励的一个目的。因为现实情况下MDP都没有现成的模型可以用,所以只能用model-free的办法(例如围棋,我们很难知道它的奖励 \(R\) 以及状态转移概率矩阵 \(P\) )。
-
Model-free prediction:在我们没法获取MDP模型的情况下,如果根据策略来估计它的价值,主要包含下面两种方法:
- 蒙特卡洛采样法(Monte Carlo policy evalution)
- 时序差分学习法(Temporal Difference (TD)learning)
-
Monte Carlo (MC) policy evalution:(只能用在一些有终止的马尔可夫决策过程)
-
算取每个轨迹获取的奖励过后,把很多轨迹的奖励进行一个平均,(例如求某个状态 \(s\) 的价值 \(v(s)\) ,计算所有的轨迹中状态 \(s\) 一共走过多少次,然后计算所有走过状态 \(s\) 的轨迹的一个奖励,所有的奖励之和来除以走过状态 \(s\) 的轨迹的条数,来取平均值),来估算每个状态下的价值,有了每个状态下的价值后,那么我们就可以知道在某个策略下它对应的价值了。
-
Monte Carlo (MC) policy evalution伪代码:To evalute state \(v(s)\)
Every time-step \(t\) that state is visited in an episode
Increment counter \(N(s) \leftarrow N(s)+1\)
Increment total return \(S(s) \leftarrow S(s)+G_t\)
Value is estimated by mean return \(v(s)=S(s)/N(s)\)
By law of large numbers, \(v(s) \rightarrow v^\pi(s)\;as\; N(s) \rightarrow \infty\)
-
还有一个重要的公式:
-
-
Temporal Difference (TD)learning:(在策略 \(\pi\) 的经验下学习 \(v_\pi\))
-
最简单的一种算法是
TD(0)算法:(estimated return也叫TD target)Update \(v(S_t)\) toward estimated return \(R_{t+1}+\gamma v(S_{t+1})\)
\(v(S_t) \leftarrow v(S_t)+\alpha(R_{t+1}+\gamma v(S_{t+1})-v(S_t))\)
-
TD target:\(R_{t+1}+\gamma v(S_{t+1})\) -
TD error:\(\delta _t=R_{t+1}+\gamma v(S_{t+1})-v(S_t)\)
-
-
蒙特卡洛采样法(MC)和时序差分学习法(TD)的区别:
- 蒙特卡洛采样法中 \(G_t\) 是一个实际得到的值,因为它把一条轨迹都跑完了,然后回来计算每个状态下的价值函数是多少;但是对于 TD learning 来说是没有等整条轨迹走完,向前走一步过后,就开始利用TD target来更新价值函数。
- TD能够在每一步过后,即时的学习,MC必须等到整个episode结束,才能知道奖励,才能进行学习。
- TD可以从不完整的序列上进行学习,MC只能从完整的序列进行学习。
- TD可以在连续环境(没有终止条件)下面进行学习,MC必须要在有终止的环境下学习。
- TD是假设了一个马尔科夫特征,所以TD在马尔可夫环境下具有更高的学习效率,MC并没有这个假设,并没有说当前状态跟之前状态是没有关系的,MC是用实际采样得到这个价值,来估计中间每个状态的价值。所以MC可能在不是马尔可夫的环境下更加的高效。
-
n-step TD
-
例如3-step TD的话,就是向前走三步,然后走三步过后,最前边那个state,利用3步得到的奖励来更新 \(v(s)\)
\(n=1(TD)\) \(G_t^{(1)}=R_{t+1}+\gamma v(S_{t+1})\)
\(n=2\) \(G_t^{(2)}=R_{t+1}+\gamma R_{t+2}+\gamma^2 v(S_{t+2})\)
\(\cdots\)
\(n=\infty (MC)\) \(G_t^{\infty}=R_{t+1}+\gamma R_{t+2}+\cdots +\gamma^{T-t-1}R_T\)
-
n-step return定义为如下:
\[G_t^n=R_{t+1}+\gamma R_{t+2}+ \cdots +\gamma^{n-1} R_{t+n}+\gamma^nv(S_{t+n}) \] -
n-step TD:
\[v(S_t) \leftarrow v(S_t)+\alpha(G_t^n-v(S_t)) \]
-
-
Bootstrapping and Sampling for DP,MC,and TD
- Bootstrapping:update involves an estimate
- MC does not bootstrap
- DP bootstraps
- TD bootstraps
- Sampling:update samples an expectation
- MC samples
- DP does not sample
- TD samples
- TD相当于是MC和DP的结合
- Bootstrapping:update involves an estimate
-
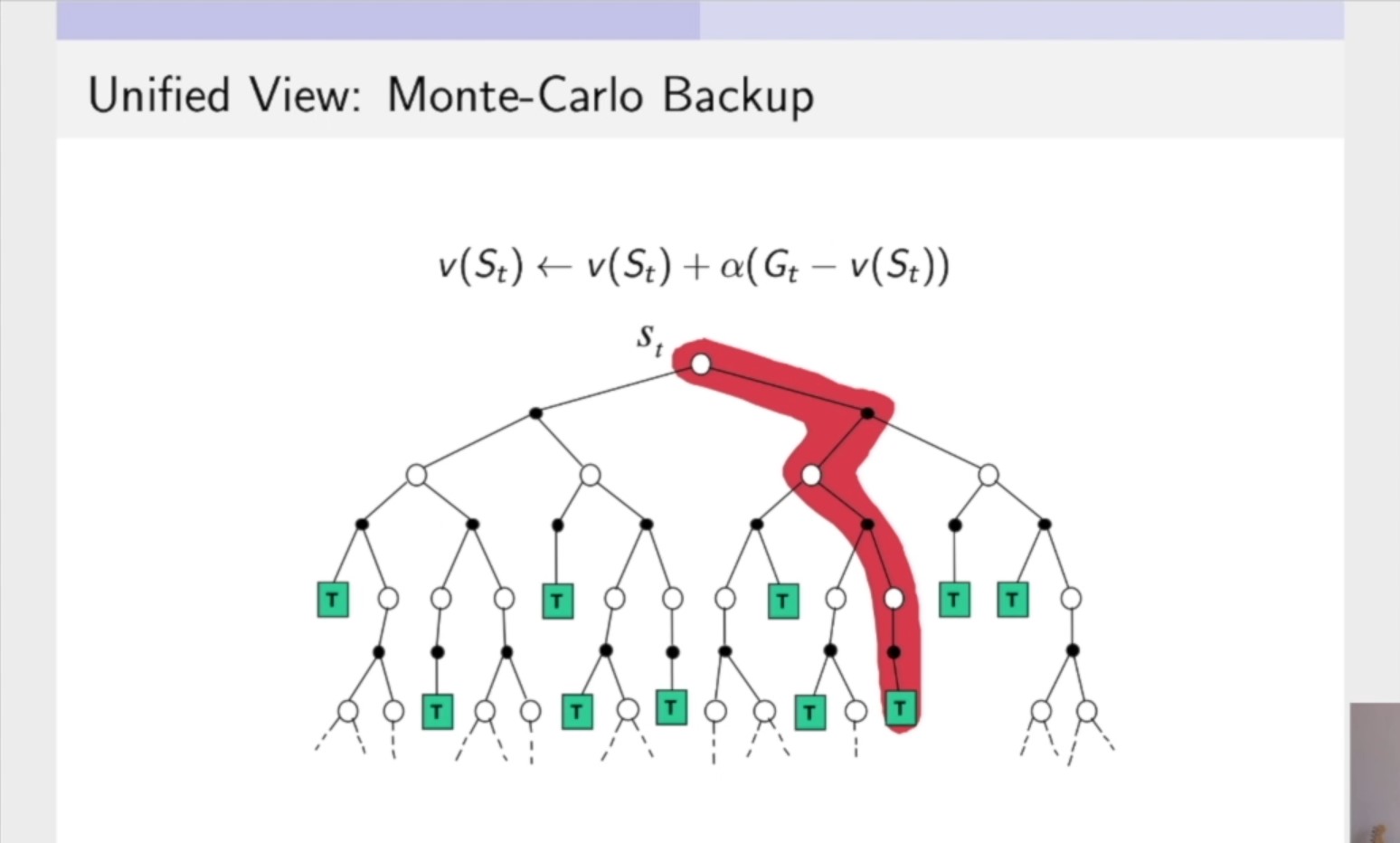
Bootstrapping and Sampling for DP,MC,and TD的可视化(图片来自b站周博磊老师的强化学习纲要教学视频)
- 动态规划,就是把所有的未来与当前状态相关联一步的状态都计算出来,把它加和起来,所以我们求解 \(v(S_t)\) 就是把红色区域的部分全部求解出来,累加得到值。
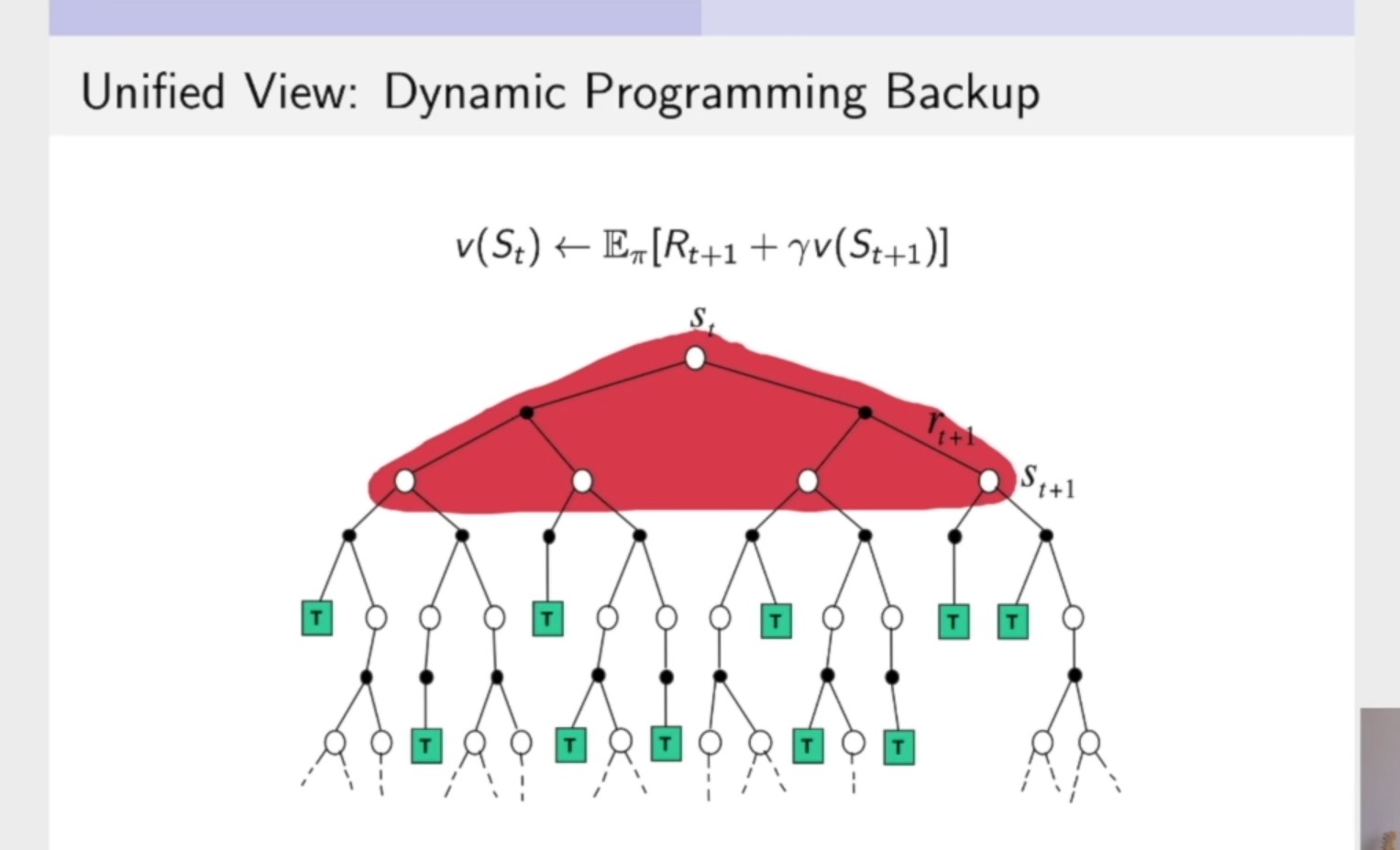
- 蒙特卡洛:在一个轨迹上进行更新,更新这个轨迹上的所有状态。
- 时序差分:TD(0)只向前走一步,实际到达的那个状态,在下一个状态然后进行bootstrap,得到 TD error,然后跟它实际得到的奖励进行加和起来。

-
使用 \(\epsilon-Greedy\) 探索的蒙特卡洛方法:
- ①:初始化 \(Q(S,A)\) 表格,等参数(第一行)。②:利用当前的策略,进行随机探索,得到一些轨迹。(第四行)③:有这些轨迹过后,开始更新 \(Q(S,A)\) (第七行)④:进一步更新自己的策略,得到下一阶段的策略,再利用下一阶段更好的策略进行数据的采集。(第十行)

-
Sarsa:On-Policy TD Control
- on-policy:我们只有同一个policy,即利用这个policy采集数据,也是对这个policy进行优化。
- 一步 \(\epsilon-greedy\) policy,然后bootstrap动作价值函数。:
- Sarsa的伪代码如下

- ①:初始化Q表格 \(Q(S,A)\) 。②:根据当前的策略进行采样,通过Q表格 \(Q(S,A)\) 采样一个 \(A\),就得到了第一个 \(A\)。③:采取action就会得到奖励 \(R\) 和下一个状态 \(S'\) 。④:再一次通过 Q表格 \(Q(S,A)\) 进行采样得到 \(A'\) 。⑤:收集到所有的数据过后,我们就可以用来更新Q表格 \(Q(S,A)\) 。⑥:更新过后,就会向前走一步,\(S \leftarrow S'\;A \leftarrow A'\)。
-
Q-learning:Off-Policy Control
-
我们让target policy和behavior policy一起提升
-
target policy:在Q table上直接greedy(贪婪的,就是直接选取收益最大的action)选取一个action
\[\pi (S_{t+1})=arg\,max_{a'}Q(S_{t+1},a') \] -
behavior policy可以是一个完全的随机的policy,但是我们采取的是 \(\epsilon-greedy\) ,(刚开始随机性是很高的,然后慢慢的降低)
-
因此Q-learning target:
\[R_{t+1}+\gamma Q(S_{t+1},A')=R_{t+1}+\gamma Q(S_{t+1},arg\,max_{a'}Q(S_{t+1},a'))\\ =R_{t+1}+\gamma \,max_{a'} Q(S_{t+1,a'}) \] -
因此Q-learning update:
\[Q(S_t,A_t) \leftarrow Q(S_t,A_t)+\alpha\, [R_{t+1}+\gamma \,max_{a}Q(S_{t+1},a)-Q(S_t,A_t)] \] -
Q-learning伪代码如下:

-
这里跟Sarsa算法很大不同的是:对第二个action的采样,在Sarsa中我们要根据target policy进行两次对action的采样。在Q-learning中第一个采样我们是用behavior policy采样出来的,我们并没有采样第二个action,而是在Q table中取一个收益max的action。然后我们对Q table进行更新,然后当前的状态进入到下一个状态。
-
-
On-policy Learning vs. Off-policy Learning
- On-policy Learning就是我们的目的是学到最佳策略,在学习过程中我们只利用一种策略,既利用这个策略进行轨迹的采集,也进一步进行策略的优化,都是用的同一个策略。例子: \(\epsilon-greedy\)
- Off-poilcy Learning就是我们在策略的学习过程中保留两种不同的策略。第一个策略是我们进行优化的策略,是希望学到最佳的策略。另外一个策略是我们用来探索的策略,因为是用来探索的策略,所以我们可以让这个策略更加的激进对环境进行探索。所以我们学习的是
target policy:π,但是我们利用的数据,采集到的轨迹是用第二个策略behavior policy:μ产生。
-
Off-policy Learning的好处
- 因为可以利用一个更加激进的behavior policy,所以我们可以学到一个更加优化的策略。
- 可以从其他的数据中进行学习,因为这些轨迹可能是人,或者其他agent产生的,那么就可以进行一个模仿学习。
- 我们可以反复利用一些老的策略产生的轨迹。因为探索轨迹的过程中,我们要用到很多的计算机资源,如果我们之前产生的轨迹,对于我们现在优化的轨迹不能利用的话,这样就浪费了很多资源。
-
周博磊老师在GitHub上提供的源码:https://github.com/cuhkrlcourse/RLexample
标签:轨迹,第二课,MC,笔记,周博磊,policy,TD,gamma,策略 来源: https://www.cnblogs.com/52dxer/p/14400336.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。