标签:Index int records key printf NULL Structures block
Hash Tables
The hash table is a main-memory data structure, in such a structure there is a hash function that takes a search key as an argument and computes from it an integer in the range 0 to \(B-1\), \(B\) is the number buckets. A bucket is a linked list, we store records by linking them to buckets.
If we have a record with a search key of \(K\), we first use the hash function to compute from it an integer, then we find the bucket of the target range.
Secondary-Storage Hash Tables
A hash table has to store so many records that they must be kept mainly in secondary storage.
A bucket consists of blocks, rather than pointers to the records. If a bucket has too many records, a chain of overflow blocks can be added to the bucket to hold more records.
We shall assume that the location of the first block for many bucket \(i\) can be found given \(i\).
Here's an illustration of a hash table:
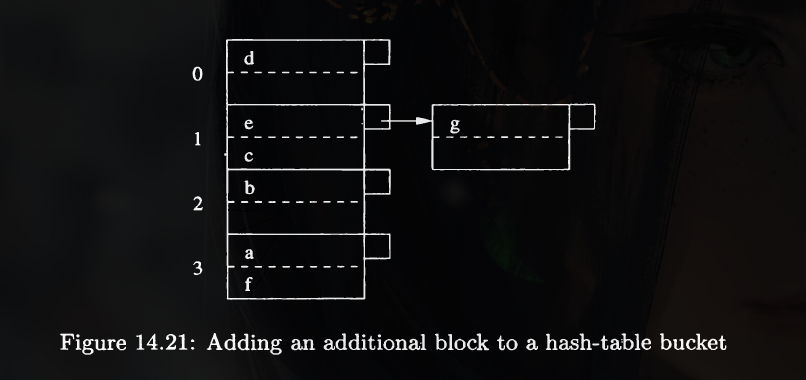
And, the number of buckets, which is \(B\), is not constant. The ones with constant number of buckets are called static hash tables.
In fact, as the number of records grows, to optimize the efficiency of the hash table, we can try to add more buckets. Cause if a bucket contains too many blocks, it will take a lot of time searching the target block.
Extensible Hash Tables
For an extensible hash table, the major additions to the simpler static hash table structure are:
- There is a level of indirection for the buckets, which is an array of pointers to blocks represents the buckets, instead of the array holding the data blocks themselves.
- The array of pointers can grow, its length is always the power of 2.
- Certain buckets can share a block if the total number of records in those buckets can fit in the block.
- The hash function \(h\) computes for each key a sequence of \(k\) bits for some large \(k\), say 32. However, the bucket numbers will at all times use some smaller number of bits, say \(i\) bits, from the beginning or end of this sequence. The bucket array will have \(2^i\) entries when \(i\) is the number of bits used.
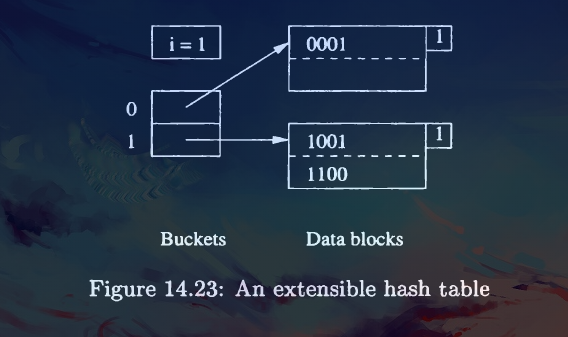
In the above case, we use hash function to compute a 4 bits sequence from a search key, and we only take 1 bit of them. So there are only 2 entries in bucket array.
Insertion Into Extensible Hash Tables
To insert a record with a search key \(K\), we first compute a sequence from \(K\), take the first \(i\) bits of the sequence. Then we find the target pointer by the bits, and finally get the target block following the pointer.
See if there is any available room in the block, if is, insert the record and we're done.
If no room, there are two possibilities, depending on the number \(j\), which indicates how many bits of the hash value are used to determine membership in the block (the value of \(j\) can be found in the "nub" of each block in the figure.).
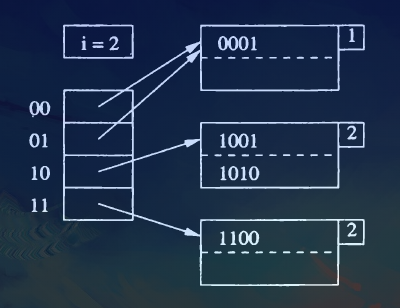
If \(j==i\), then we need to increase \(i\) by 1, which means doubling the length of the bucket entries. Now we need new indexes for the bucket. Suppose originally we use an index \(w\), after the length increment, we use \(w0\) and \(w1\) to index two different entries.
If \(j<i\):
-
If \(j<i\), means there are overfull records in the current block. So we need to add one more block to the bucket.
-
For now, we split the block into two. Distribute records in \(B\) to the two blocks, based on the value of their \((j+1)\)st bit —— records whose key has 0 in that bit stay in \(B\) and those with 1 there go to the new block.
-
Put \(j+1\) into the block "nub" to indicate the number of bits used to determine membership.
-
Adjust the pointers in the bucket array so entries that formerly pointed to \(B\) now point either to \(B\) or the new block, depending on their \((j+1)\)st bit.
The "adjust" may be a little hard to understand. For example:
In the above case, when we need to insert a record with a hash value of "1001". And as we see, \(j\) already equals to \(i\), so we first need to expand the bucket array by increasing \(i\) by 1.
Next, we need to adjust three records: 1001, 1010, 1001. Cause their first 2 bits are the same, so we need to split the current block, one of which is pointed by 100 index and another of which is pointed by 101 index.
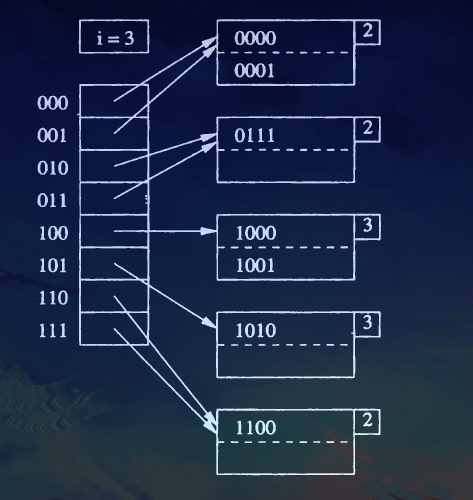
Since there is a chance that all the records may go into one of the blocks, if so, we need to repeat the process on the overfull block.
Linear Hash Tables
Extensive hash tables have some obvious defects:
- When the bucket array need to double its size, it's a substantial work. So when you insert some certain records, it may take a long time to get it done.
- As the size of the bucket array grows, the memory may be not able to hold it anymore. So part of the extensive hash table may get transported to disk. This causes a sudden increment of disk I/O operation and drags the DB operation speed down.
- If the number of records per block is small. There is a chance that two records have a very similar hash value, for example, the first 20 bits of the hash value are the same. In this case, we have to split millions of blocks in this bucket. Even though maybe there are only like 3 records in our hash table.
Apendix1
C++ Implementation of Extensive Hash Tables
/**********************************************
> File Name : extensiveHashTable.cpp
> Author : lunar
> Email : lunar_ubuntu@qq.com
> Created Time : Thu 04 Feb 2021 09:32:37 PM CST
> Location : Shanghai
> Copyright@ https://github.com/xiaoqixian
**********************************************/
#include <stdio.h>
#include <stdlib.h>
#include <cstring>
#include <unistd.h>
#define RED "\e[0;31m"
#define CYAN "\e[0;36m"
#define MAGENTA "\e[0;35m"
#define NONE "\e[0m"
struct Record {
u_int32_t key;
char* str;
Record(u_int32_t key, const char* s) {
if (strlen(s) > 100) {
printf("s length out of limits.\n");
this->str = NULL;
} else {
str = new char[10];
this->key = key;
strcpy(this->str, s);
}
}
};
/* In our case, 4 record pointers per block.*/
struct Block {
u_int32_t j;
Record* records[4];
Block() {
j = 1;
for (int k = 0; k < 4; k++) {
records[k] = NULL;
}
}
};
class ExtensiveHashTable {
private:
u_int32_t i;
Block** bucketArray;
char* toBinary(u_int32_t key, u_int32_t length, bool output, bool toPrint);
char* toReverseBinary(u_int32_t key, u_int32_t length);
int toDecimal(const char* hash, u_int32_t length);
char* hash(u_int32_t key);
void expand();
Block* findBlock(const u_int32_t key);
int findLocation(const u_int32_t key);
void adjustNewBlock(Block* oldBlock, Block* newBlock, int location);
public:
ExtensiveHashTable(u_int32_t size);
Record* search(const u_int32_t key, Block* b);
void insertRecord(Record* r);
void deleteRecord(const u_int32_t key);
void displayTable();
};
/* Transform a integer into its binary form. */
char* ExtensiveHashTable::toBinary(u_int32_t key, u_int32_t length = 32, bool output = true, bool toPrint = false) {
if (length == 0) {
printf("toBinary length = 0 is not allowed.\n");
return NULL;
}
u_int32_t temp = key;
char* res;
if (!toPrint)
res = new char[length];
else {
res = new char[length+1];
res[length] = '\0';
}
int index = 0;
while (key && index < length) {
if (key & 0x00000001) {
res[index++] = '1';
} else {
res[index++] = '0';
}
key >>= 1;
}
while (index < length) {
res[index++] = '0';
}
if (output)
printf("%d to binary: %s\n", temp, res);
return res;
}
char* ExtensiveHashTable::toReverseBinary(u_int32_t key, u_int32_t length = 32) {
char* res = new char[length+1];
res[length] = '\0';
int index = length-1;
while (key && index > -1) {
if (key & 0x00000001) {
res[index--] = '1';
} else {
res[index--] = '0';
}
key >>= 1;
}
while (index > -1) {
res[index--] = '0';
}
return res;
}
int ExtensiveHashTable::toDecimal(const char* hash, u_int32_t length = 32) {
if (length == 0) {
return 0;
}
int res = 0;
for (int k = 0; k < length; k++) {
if (hash[k] == '0') {
continue;
} else if (hash[k] == '1') {
res += (1<<(length-k-1));
} else {
printf(RED "Unknown char in the binary form.\n" NONE);
return -1;
}
}
return res;
}
/* For simlicity, in our case, I won't implement hash functions in
* the cpp standard library.
* So I create a simple "hash" function with no hashing, I'll just
* transform a decimal integer into its binary form. And disorder it
* in a certain way.
*/
char* ExtensiveHashTable::hash(u_int32_t key) {
printf("Hash key = %d.\n", key);
if (key < 1<<4) {
} else if (key < 1<<8) {
u_int32_t low4Bits = key & 0x0000000f;
key >>= 4;
low4Bits <<= 4;
key |= low4Bits;
} else if (key < 1<<16) {
u_int32_t low8bits = key & 0x000000ff;
key >>= 8;
low8bits <<= 8;
key |= low8bits;
} else {
u_int32_t low16Bits = key & 0x0000ffff;
key >>= 16;
low16Bits <<= 16;
key |= low16Bits;
}
printf("After hash key = %d.\n", key);
return toBinary(key);
}
void ExtensiveHashTable::expand() {
if (this->i >= 32) {
printf("Buckets array length out of bounds.\n");
return ;
}
Block** temp = new Block*[1<<((this->i)+1)]{NULL};
if (temp == NULL) {
printf(RED "allocate memory failed.\n" NONE);
return ;
}
int k = 0, p = 0;
(this->i)++;
while (k < 1<<(this->i)) {
int j = this->bucketArray[p]->j;
for (int m = 0; m < (1<<(this->i-j)); m++) {
temp[k+m] = this->bucketArray[p];
}
k += (1<<(this->i-j));
p += (1<<(this->i-1-j));
}
delete[] (this->bucketArray);
this->bucketArray = temp;
}
/*
* When we need to split a block, this block may be connected by multiple
* pointers, and we need to divide part of them to point to the new block.
*/
void ExtensiveHashTable::adjustNewBlock(Block* oldBlock, Block* newBlock, int location) {
int count = this->i - oldBlock->j + 1;
int k = 0, up = 0, temp = location;
while (count) {
int low1bit = location & 0x00000001;
if (low1bit) {
up += (1<<k);
}
k++;
location >>= 1;
count--;
}
int start = temp - up + (1<<(this->i-oldBlock->j));
if (start < 0) {
printf(RED "Adjust new block error\n" NONE);
return ;
}
for (k = 0; k < (1<<(this->i-oldBlock->j)); k++) {
printf(MAGENTA "Bucket Array[%d] = newBlock\n" NONE, start+k);
this->bucketArray[start+k] = newBlock;
}
}
ExtensiveHashTable::ExtensiveHashTable(u_int32_t size = 1) {
this->i = size;
bucketArray = new Block*[1<<i];
for (int k = 0; k < 1<<i; k++) {
bucketArray[k] = new Block();
}
printf("Initial an ExtensiveHashTable instance.\n");
}
int ExtensiveHashTable::findLocation(const u_int32_t key) {
char* hashBin = hash(key);
if (hashBin == NULL) {
printf(RED "Hash error.\n" NONE);
return -1;
}
int hashVal = toDecimal(hashBin, this->i);
delete[] hashBin;
if (hashVal >= (1<<(this->i)) || hashVal < 0) {
printf(RED "Hash value error.\n" NONE);
return -1;
}
return hashVal;
}
/* If no such record, return NULL.*/
Block* ExtensiveHashTable::findBlock(const u_int32_t key) {
int hashVal = findLocation(key);
if (hashVal == -1) {
printf(RED "Find location error.\n" NONE);
return NULL;
}
Block* p = this->bucketArray[hashVal];
if (p == NULL) {
printf(RED "No such block with key = %d.\n" NONE, key);
return NULL;
}
return p;
}
Record* ExtensiveHashTable::search(const u_int32_t key, Block* b = NULL) {
if (b == NULL) {
b = findBlock(key);
}
if (b == NULL) {
return NULL;
}
for (Record* r:(b->records)) {
if (r != NULL && r->key == key) {
printf("Searched record with key = %d, str = %s.\n", key, r->str);
return r;
}
}
printf("No such record with key = %d.\n", key);
return NULL;
}
void ExtensiveHashTable::insertRecord(Record* r) {
if (r == NULL) {
printf("Can't insert NULL record!\n");
return ;
}
Block* b = findBlock(r->key);
if (b == NULL) {
printf(RED "Exists NULL pointer in the bucket array.\n" NONE);
return ;
}
if (search(r->key, b) != NULL) {
printf(RED "Key duplicated, insertion terminated.\n" NONE);
return ;
}
for (int k = 0; k < 4; k++) {
if (b->records[k] == NULL) {
b->records[k] = r;
printf("Successfully inserted a record with key = %d in block %d\n", r->key, findLocation(r->key));
//printf("this->i = %d\n", this->i);
displayTable();
return ;
}
}
/*
* No space in the current block.
* Two opetions
* */
int j = b->j;
int i = this->i;
if (j == i) {
printf(RED "Need to expand the buckey array.\n" NONE);
printf(RED "Current table layout.\n" NONE);
displayTable();
printf("\n" NONE);
expand();
printf(RED "After expansion layout.\n" NONE);
displayTable();
i = this->i;
}
int hashVal = findLocation(r->key);
printf("Location of key=%d is %s.\n", r->key, toReverseBinary(hashVal, this->i));
if (j < i) {
j++;
printf("j = %d\n", j);
Block* newBlock = new Block();
if (newBlock == NULL) {
printf(RED "New Block allcation error.\n" NONE);
return ;
}
newBlock->j = j;
b->j = j;
/* Adjust the new block.*/
adjustNewBlock(b, newBlock, hashVal);
printf(CYAN "After adjustion.\n" NONE);
displayTable();
int temp = 0;
/* Now we need to distribute these records into two blocks.*/
printf(CYAN "To distribute all pointers in the current block.\n" NONE);
for (int k = 0; k < 4; k++) {
Record* re = b->records[k];
if (re == NULL) {
continue;
}
char* bin = hash(re->key);
char c = bin[j-1];
delete[] bin;
if (c == '0') {
printf("%d stays the same.\n", re->key);
continue;
} else {
newBlock->records[temp++] = re;
b->records[k] = NULL;
printf("%d moves to the new block.\n", re->key);
}
}
/*means all of the pointers go into one of the blocks*/
if (temp == 0 || temp == 4) {
printf("All records go into one of the blocks.\n");
insertRecord(r);
} else {
printf("New block inserting.\n");
char* bin = hash(r->key);
char c = bin[j-1];
if (c == '0') {
for (int k = 0; k < 4; k++) {
if (b->records[k] == NULL) {
b->records[k] = r;
printf("Successfully inserted a record with key = %d in block %s\n", r->key, toReverseBinary(hashVal, this->i));
printf(CYAN "After distribution and insertion.\n" NONE);
displayTable();
return ;
}
}
printf("Record insertion failed.\n");
return ;
} else {
newBlock->records[temp] = r;
printf("Successfully inserted a record with key = %d in block %s\n", r->key, toReverseBinary(hashVal, this->i));
printf(CYAN "After distribution and insertion.\n" NONE);
displayTable();
return ;
}
}
}
}
void ExtensiveHashTable::deleteRecord(const u_int32_t key) {
Block* b = findBlock(key);
if (b == NULL) {
printf("No such record.\n");
return ;
}
for (int k = 0; k < 4; k++) {
Record* re = b->records[k];
if (re != NULL && re->key == key) {
delete[] (re->str);
delete re;
b->records[k] = NULL;
printf("Successfully deleted record with key = %d\n", key);
return ;
}
}
printf("No such record.\n");
}
void ExtensiveHashTable::displayTable() {
printf("this->i = %d in displayTable.\n", this->i);
for (int k = 0; k < (1<<(this->i)); k++) {
char* bin = toReverseBinary(k, this->i);
printf(MAGENTA "%s ", bin);
//printf(MAGENTA "%d ", k);
delete[] bin;
if (this->bucketArray[k] == NULL) {
printf("all null\n");
continue;
}
for (Record* r: (this->bucketArray[k])->records) {
if (r == NULL) {
printf("null ");
} else {
printf("%d ", r->key);
}
}
printf("j = %d\n" NONE, (this->bucketArray[k])->j);
}
}
void test1() {
ExtensiveHashTable eht;
const char* s = "Hello World";
/* Produce random numbers between 0 and 100 to test ExtensiveHashTable for 1000 times.*/
printf("Insert Test.\n");
for (int i = 0; i < 1000; i++) {
printf("\n%d run.\n", i);
u_int32_t key = (u_int32_t)(rand() % 1000);
Record* r = new Record(key, s);
eht.insertRecord(r);
}
printf("\n");
eht.displayTable();
printf("\nSearch Test.\n");
for (int i = 0; i < 1000; i++) {
int key = rand() % 1000;
eht.search(key);
}
printf("Delete Test.\n");
for (int i = 0; i < 1000; i++) {
int key = rand() % 1000;
eht.deleteRecord(key);
}
}
void test2() {
}
int main() {
test1();
}
标签:Index,int,records,key,printf,NULL,Structures,block 来源: https://www.cnblogs.com/lunar-ubuntu/p/14387414.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。