标签:DCN 卷积 deformable DCNv2 论文 v2 Deformable
目标检测论文阅读:DCN v2
Deformable ConvNets v2
论文链接:https://arxiv.org/pdf/1811.11168.pdf
代码链接:尚未公开
deformable是最近非常著名的针对Object形状进行建模的一种特殊CNN。之前,我写过一篇博客介绍这篇文章,需要的同学可以先了解一下。概括来说,deformable中卷积采样的位置较规则传统的CNN来说更加灵活,从而可以对形变进行建模。但是,这种方法也有着它自身的问题,今天我们就来看看deformable的改进版本。
1. Background
介绍v2之前,需要先了解本文的核心观点。文章认为,对于positive的样本来说,采样的特征应该focus在roi内,如果特征中包含了过多超出roi的内容,那么结果会受到影响和干扰。而negative样本则恰恰相反,引入一些超出roi的特征有助于帮助网络判别这个区域是背景区域。 在这一前提下,我们对v1版本与常规CNN进行分析。
首先引入下面三个概念:
Effective receptive fields:在理论感受野的基础上进行了进一步的分析,相比而言最大的特点呈现高斯分布,具体需要看提出这一概念的论文,下面同理
Effective sampling/bin locations:和v1相比,额外计算网络结点的梯度来作为强度,红色代表高强度、蓝色代表低强度
Error-bounded saliency regions:指能得到和full image相同响应的最小区域
下面是一个样例图(从左到右依次是小目标、大目标、背景类/从上到下依次是有效采样位置、有效感受野和Error-bounded saliency regions):
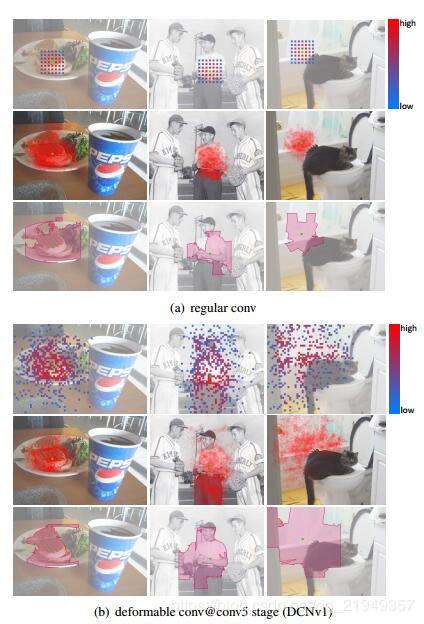
可以看到:
- 从有效感受野和Error-bounded saliency regions来看,传统CNN实际上也具备一定的对形变建模能力,并非完全的方形
- v1版本的deformable增加了CNN对形变建模能力,对前景类更好地覆盖了整个Object,对背景类囊括了更多的Context信息
- 从有效采样位置可以发现,传统CNN对形变的建模能力很有可能是通过调整卷积核的值来实现的,中心位置幅值高、越往边缘幅值越低
另外,v1版本虽然提高了建模能力,Error-bounded saliency regions仍然包括了很多Object无关的区域,这会导致性能的下降。基于以上考虑,本文提出了三点改进策略:
- 增加deformabel convolution的使用,在更多阶段上使用deformable convolution
- 丰富对形变建模的能力,不但可以改变位置,还可以调整不同位置的幅值
- 设计了一个mimicking loss策略,来进一步强迫Positive样本focus到object的内部
2. Method
More Deformable Conv Layers
因为v1版本没有考虑到幅值的问题,只考虑采样位置,因此在可视化的时候并没有得到充分正确的结果,影响了后续的探究,本文称之为misleading offset visualization。在v1中,VOC的性能已经达到了饱和,在COCO上的性能则因为该问题没有得到充分的研究。 本文将conv3~5中的所有3x3 conv layers替换成了deformable convolutions,得到了更好的结果。而进一步的替换并不会导致性能提升。
Modulated Deformable Modules
之前我们在v1那篇博客里说过,传统卷积对某个feature map卷积时候,以(x, y)为中心,会计算整个3x3共9个格子内的值。相应的,deformable卷积会学习大小和feature map相同、channel为9x2的新的特征层。因此新层在每个位置有18个值,可以组合成9组横纵坐标偏移量,代表feature map在对应的位置进行卷积时,这9个格子需要偏移的位置。
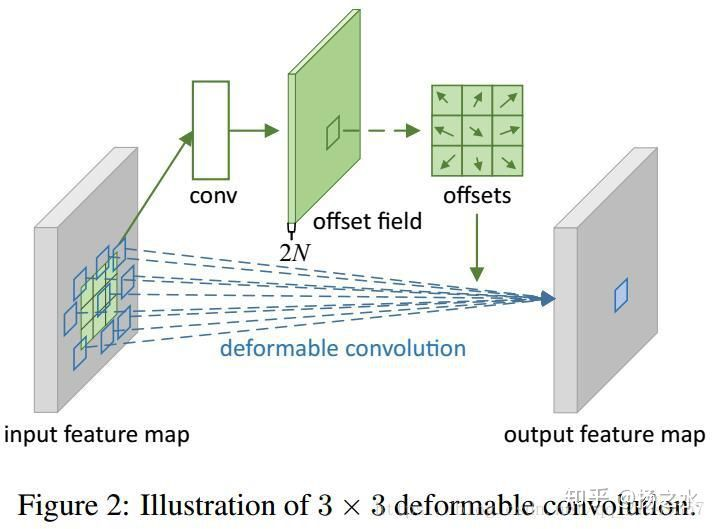
v2版本则进一步增加了9个通道,共27个通道,多出来的9个通道用于计算9个格子的幅值大小。用公式来表示,则为:

这里最后的delta mk就是新增加的需要学习的幅值。同理,v1版本中的deformable RoIpooling也用相同的方式“进化”:
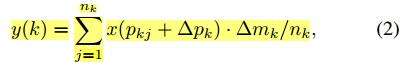
R-CNN feature mimicking
新的deformable conv通过设置幅值的方式排除过于丰富的context信息,关注roi区域,为了更好地实现这一目的,作者增加了一个R-CNN分支作为额外的guidance。
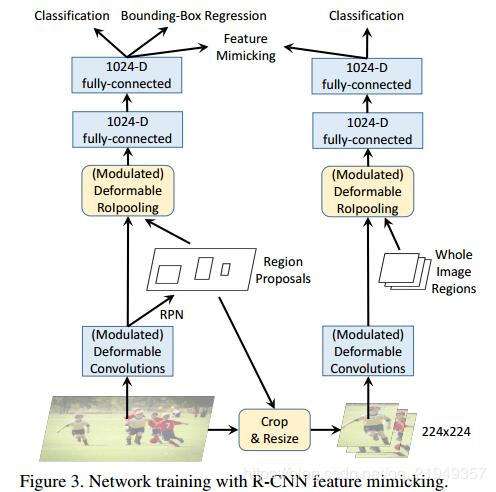
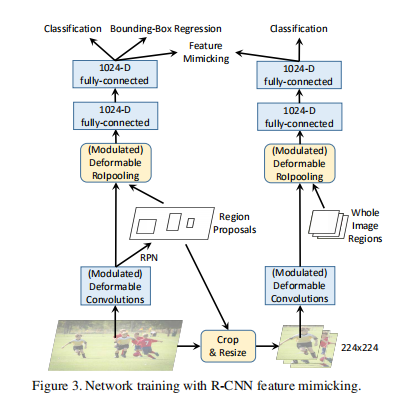
如图所以,右面即为新增加的分支,该分支与原来的分支共享权重。但是其输入不同,是RPN阶段得到的Roi直接crop and resize下来的。在经过2-fc层后,产生的特征进行比较,计算mimic loss:
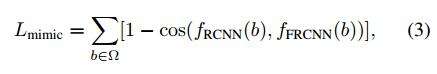
本身R-CNN分支因为输入是crop下来的图片,是理所当然只会关注object内部的,而它的存在,就相当于一个teacher,可以强迫原来的faster rcnn网络只关注Object内部的信息。当然,仅限于positive examples,因为negative examples需要更多的context信息来帮助判别,作者也通过实验证明了只用FG的Mimic loss > FG&BG都用的mimic loss > 不使用mimic loss。
3. 实验结果
从实验结果可以看到,v2和v1相比提高了3.7个百分点(和regular相比提高更大),是非常好的一种方法,也期待着源码能够尽早开源~
发布于 2018-12-24 目标检测 卷积神经网络(CNN) 计算机视觉
文章被以下专栏收录
推荐阅读
目标检测论文阅读:RepPoints(Anchor Free)
目标检测论文阅读:RepPoints 论文链接: https://arxiv.org/abs/1904.11490 代码链接: https://github.com/microsoft/RepPoints 这周来看一下anchor free领域的一个比较新的算法reppoin…
扬之水发表于从目标检测...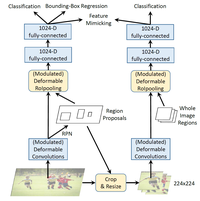
论文阅读-可变形卷积v2: More Deformable, Better Results
我是觉觉啊发表于计算机科学...目标检测论文阅读:YOLOv1-YOLOv3(一)
关于YOLO(You only look once)的大名,想必搞目标检测的应该也是无人不知了。这位github画风新奇,连个人简历也少女心满满的独角兽控推出的三个版本的YOLO不仅速度快得没朋友,performa…
扬之水
基于深度学习的目标检测算法综述(二)
vision6 条评论
写下你的评论...-
 fyk2018-12-25
fyk2018-12-25
目前已经开源了deformable conv和pooling部分的代码,整体结构的代码还没开放
-
 扬之水 (作者) 回复fyk2018-12-28
扬之水 (作者) 回复fyk2018-12-28
deformable开源了,v2没有
-
 王康康2018-12-29
王康康2018-12-29
我问个问题,连采样点的权重都学出来了,还要卷积核干啥?这不是多此一举吗
-
扬之水 (作者) 回复王康康2019-01-07
pooling是没有幅值这个概念的,卷积似乎和权重确实有点重复
-
 Jordan Belfort2019-01-04
Jordan Belfort2019-01-04
请教个问题,论文中说将conv3-conv5所有卷积换成deform conv, 不是应该有13层deform conv吗?论文里说12层是不是写错了?
-
扬之水 (作者) 回复Jordan Belfort2019-01-07
我算的也是13,作者为什么说12就不太清楚了,可能要等代码release了
论文阅读:DCNv2
1、论文总述
这篇paper是DCNv1的升级版,文章认为,对于positive的样本来说,采样的特征应该focus在roi内,如果特征中包含了过多超出roi的内容,那么结果会受到影响和干扰。而negative样本则恰恰相反,引入一些超出roi的特征有助于帮助网络判别这个区域是背景区域。
看这篇anchor free目标检测论文 论文阅读:Objects as Points(也叫CenterNet)的时候,许多大佬的解读都是认为RepPoints是在DCNv2的进化版,因为RepPoints的卷积也都是用可变形卷积来提取特征,但训练时候对取样点有对应的损失函数,可以对DCN的自由的采样点进行监督,让其学到有用的ROI内部的特征;
还有一点就是RepPoints可以学到目标的几何特征,而DCN不能,DCN只是学到目标用来识别分类的特征,并不能用这些来进行box的回归。
从DCNv2的训练也能看出来其实,训练时候需要RCNN的mimicking来更好地让DCNV2学习目标的特征,只是分类用的。
理解这篇paper时候,发现了一个写的很好的博客,写的比较清晰而且全面,所以就不自己写了,链接为:Deformable ConvNets v2算法笔记
In this paper, we present a new version of Deformable
ConvNets, called Deformable ConvNets v2 (DCNv2), with
enhanced modeling power for learning deformable convolutions. This increase in modeling capability comes in two
complementary forms.
The first is the expanded use of deformable convolution layers within the network. Equipping more convolutional layers with offset learning capacity allows DCNv2 to control sampling over a broader range of
feature levels.
The second is a modulation mechanism in
the deformable convolution modules, where each sample
not only undergoes a learned offset, but is also modulated
by a learned feature amplitude. The network module is thus
given the ability to vary both the spatial distribution and the
relative influence of its samples.
To fully exploit the increased modeling capacity of
DCNv2, effective training is needed. Inspired by work on
knowledge distillation in neural networks [2, 22], we make
use of a teacher network for this purpose, where the teacher
provides guidance during training. We specifically utilize
R-CNN [17] as the teacher. Since it is a network trained for
classification on cropped image content, R-CNN learns features unaffected by irrelevant information outside the region
of interest. To emulate this property, DCNv2 incorporates a
feature mimicking loss into its training, which favors learning of features consistent to those of R-CNN. In this way,
DCNv2 is given a strong training signal for its enhanced
deformable sampling. (R-CNN [17] as the teacher这个我也是第一次见,对我启发很大。)
参考文献
1、Deformable Convolution v1, v2 总结
3、论文阅读:Deformable ConvNets v2: More Deformable, Better Results
4、如何评价 MSRA 视觉组最新提出的 Deformable ConvNets V2?
发布于 2019-11-25(9条消息) Deformable ConvNets v2算法笔记_AI之路-CSDN博客
论文:Deformable ConvNets v2: More Deformable, Better Results
论文链接:https://arxiv.org/abs/1811.11168
这篇博客介绍个人非常喜欢的一篇目标检测文章:DCN v2,也就是Deformable ConvNets论文的升级版,效果提升很明显,思想很简洁。主要的改进包括:
1、在特征提取网络的更多层中引入deformable convolution结构,从后面的实验来看,这个操作虽然简单,但是效果提升非常明显,只不过在v1论文中使用PASCAL VOC数据集,所以难以观察到这部分提升。
2、改进deformable结构,我们知道不管是deformable convolution还是deformable RoI pooling,主要通过引入offset,使得特征提取过程能够更加集中于有效信息区域,而这篇论文在v1的基础上引入了modulation,modulation简单而言就是权重,通过分配不同权重给经过offset修正后的区域,实现更加准确的特征提取。
3、第2点的想法很好,但是从作者的实验来看(Table1或Table2的最后2行),仅仅通过第2点带来的提升还是比较有限的,主要原因在于现有的损失函数难以监督模型对无关紧要的区域设置较小的权重,因此在模型训练阶段引入RCNN feature mimicking,这部分受论文Revisiting rcnn: On awakening the classification power of faster rcnn的启发,不过实现方式不一样,这篇文章通过联合训练RCNN网络提供有效的监督信息,发挥modulation的权重作用,使得提取到的特征更加集中于有效区域,因此和第2点是紧密结合的。
首先看看这篇文章用到的3个可视化指标,参看Figure1,Figure1是关于常规卷积、DCNv1和DCNv2的对比图,用来说明Deformable convolution的效果。
1、effective sampling locations, 也就是有效的计算区域,这个在DCNv1论文中看得比较多了,简而言之就是几个卷积层叠加后从输出中的某个点往前推算出参与该点计算的特征点区域,在Figure1中就是往前推算3层得到的图,因此点数最多为9^3=729,常规卷积因为有重叠,所以看到的只有49个(a中第一行),可变卷积因为涉及越界,所以实际点数少于729,一般在200左右(b中第一行)。
2、effective receptive fields,也就是有效感受野,可以通过梯度来计算,不同于理论感受野。
3、error-bounded saliency region,表示当以完整的输入图像进行计算和只以输入图像的部分区域进行计算时,模型得到的输出相同时的最小区域,简而言之,这部分区域(saliency region)是对模型输出影响较大的区域。
从Figure1中可以得到几个结论:
1、基于常规卷积层的深度网络对于形变目标有一定的学习能力,比如(a)中的最后一行,基本上都能覆盖对应的目标区域或者非目标区域,这主要归功于深度网络的拟合能力,这种拟合能力有点强行拟合的意思,所以才有DCN这种设计。
2、DCNv1对于形变目标的学习能力要比常规卷积强,能够获取更多有效的信息。比如(b)中的最后一行,当输出点位置在目标上时(前2张图),影响区域相比常规卷积而言更大。
3、DCNv2对于形变目标的学习能力比DCNv1更强,不仅能获取更多有效的信息,而且获取的信息更加准确,比如©中的最后一行,目标区域更加准确。因此简单来讲,DCNv1在有效信息获取方面的recall要高于常规卷积,而DCNv2不仅有较高的recall,而且有较高的precision,从而实现信息的精确提取。

Figure2是关于常规卷积、DCNv1和DCNv2的对比图,用来说明Deformable RoI pooling的效果。
这里涉及的effective bin location和Figure1中的effective sampling location含义类似,整体上(a)到(c)的实验结果和Figure1中的实验结果一致。(d)和(e)是在模型训练阶段引入的RCNN feature mimicking效果,通过对比(c)和(d)的最后一行图就能明显看出来当RoI在目标上时,(d)中的有效区域更加精确,当RoI不在目标上时,差别不大,这部分后面也有实验证明(Table3)。那么(e)和(d)的对比能说明什么?因为(e)是在常规卷积网络上添加RCNN feature mimicking进行联合训练,但(e)中的有效区域并不准确,原因就在于没有引入modulation和offset,相当于仅有监督信息,但是没有有效的执行点,这也是这篇论文比较有意思的地方。

接下来大概介绍一下modulated deformable convolution,公式如下所示,△mk就是modulation要学习的参数,这个参数的取值范围是[0,1],假如去掉这个参数,那么就是DCNv1中的deformable convolution。

从论文来看,△pk,△mk都是通过一个卷积层进行学习,因此卷积层的通道数是3K,其中2K表示△pk,这和DCNv1的内容是一样的,剩下K个通道的输出通过sigmoid层映射成[0,1]范围的值,就得到△mk。
modulated deformable RoI pooling结构的设计也是同理,公式如下所示,假如去掉△mk参数,那么就是DCNv1中的deformable RoI pooling。

总结一下,DCN v1中引入的offset是要寻找有效信息的区域位置,DCN v2中引入modulation是要给找到的这个位置赋予权重,这两方面保证了有效信息的准确提取。
接下来看看训练阶段增加RCNN feature mimicking是如何实现的,示意图如Figure3所示,姑且称左边的网络为主网络(Faster RCNN),右边的网络为子网络(RCNN)。实现上大致是用主网络训练过程中得到的RoI去裁剪原图,然后将裁剪到的图resize到224×224大小作为子网络的输入,子网络通过RCNN算法提取特征,最终提取到14×14大小的特征图,此时再结合IoU(此时的IoU就是一整个输入图区域,也就是224×224)作为modulated deformable RoI pooling层的输入得到IoU特征,最后通过2个fc层得到1024维特征,这部分特征和主网络输出的1024维特征作为feature mimicking loss的输入,用来约束这2个特征的差异,同时子网络通过一个分类损失进行监督学习,因为并不需要回归坐标,所以没有回归损失。在inference阶段仅有主网络部分,因此这个操作不会在inference阶段增加计算成本。

那么为什么RCNN feature mimicking方法有效?因为RCNN这个子网络的输入就是RoI在原输入图像上裁剪出来的图像,因此不存在RoI以外区域信息的干扰,这就使得RCNN这个网络训练得到的分类结果更加可靠,以此通过一个损失函数监督主网络Faster RCNN的分类支路训练就能够迫使网络提取到更多RoI内部特征,而这个迫使的过程主要就是通过添加的modulation机制和原有的offset实现。
feature mimicking loss采用cosine函数度量2个输入之间的差异,这是利用了cosine函数能够度量两个向量之间的角度的特性,其中fRCNN(b)表示子网络输出的1024维特征,fFRCNN(b)表示主网络输出的1024维特征,通过对多个RoI的损失进行求和就得到Lmimic。

实验结果部分的内容十分丰富,依次来看看:
Table1和Table2都是在COCO 2017 val数据集上的实验结果,差别仅在于输入图像的短边处理不同,Table1是短边缩放到1000的实验结果,Table2是短边缩放到800的实验结果。以Table1为例,从dconv@c5和dconv@c4-c5这两行的对比可以直接看出即便只是简单将DCNv1中的可变卷积层扩展到c4的网络层,就能有非常明显的效果提升。正如作者所说,当初DCNv1的实验主要是在PASCAL VOC数据集上做的,因此看不到明显提升,切换到COCO数据集就不一样了,因此多关注数据集能够避免一些好的想法夭折。再看看DCNv2的第二个创新点,关于引入modulate,实验对比是dconv@c3~c5+dpool和mdconv@c3-c5+mdpool,提升有,但是不算很明显,这部分可以结合Table3中关于RCNN feature mimicking的实验一起看,在增加这个监督信息进行训练后,效果提升还是比较明显的。

Table3是在COCO 2017 val数据集上关于RCNN feature mimicking是否有效的对比实验,可以看到在DCNv2的基础上增加foreground的IoU进行联合训练提升非常明显,而在常规卷积网络中(regular)的提升非常少,这也说明了仅有监督信息还是不够的,还需要modulation和offset扮演执行者角色进行实际操作。

Table4是在COCO 2017 test-dev数据集上的测试结果,这个实验是为了验证DCNv2的思想在不同特征提取网络中是否有效,这部分关于DCNv2的实验同样引入了RCNN feature mimic损失。可以看出当特征提取网络从ResNet-50升级到ResNet-101和ResNeXt-101时,检测和分割的指标都有所提升,说明了DCNv2的设计确实有效。

Figure4是关于输入图像短边resize到不同尺寸时常规卷积和DCNv2的效果对比。可以看出常规卷积在输入图像短边尺寸变大时(比如超过1000),效果反而下降了,尤其对于大尺寸目标下降更加明显,而DCNv2没有这样的现象。

出现这种现象的原因就在于使用常规卷积时,当输入图像分辨率变大,那么对应的目标尺寸也会变大,但是因为常规卷积的感受野不变,所以能够获取到的特征信息就有限,如Figure5(a)第一行的3个图所示,感受野面积依次递减。DCNv2因为感受野受卷积的offset和modulation控制,因此在图像分辨率变大时仍然可以获取目标的足够信息,如Figure5(b)第一行的3个图所示,效果上基本不受影响。

标签:DCN,卷积,deformable,DCNv2,论文,v2,Deformable 来源: https://www.cnblogs.com/cx2016/p/13828624.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。