标签:10 知乎 Faster Deformable self ch grid RCNN DETR
计算机视觉 目标检测 物体识别 深度学习(Deep Learning) 卷积神经网络(CNN)
如何看待商汤的Deformable DETR?能否取代Faster-RCNN范式?
Deformable DETR比DETR训练快10x,能否取代Faster-RCNN目标检测范式呢?
DETRarxiv.orgDeformable DETRarxiv.org
9 个回答
Deformable DETR主要是将之前DETR直接使用特征图进行训练变为注意力之后的特征图。将之前DETR花费时间学习到的Sparse Att map快速得到。
无意义内容分割线
可变性att部分:

可变形注意力Query部分是特征图线性投影后的结果,元是特征图直接预测offset(2*核元素数),权重(核元素数,后面过Softmax归一化)。Key则是原始特征图。对于每个PIXEL预测周围PIXEL特征之和。相对可变形卷积可以认为是卷积Kernel的参数按位置变化了。
多尺度可变形att:
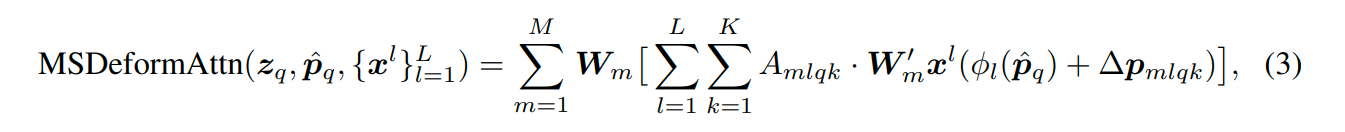
加入了多层尺度att,也就是考虑不同尺度,因为meshgrid归一化了,坐标其实通用。
可变形TransformerEncoder部分:
用上述多尺度可变形att代替DETR transformer att部分(3尺度,不带FPN,多尺度可变形att自带融合多尺度加成)。加入可学习尺度嵌入和固定的位置嵌入。
可变形TransformerDecoder部分:
cross-att使用多尺度可变att,self-att保持。 预想参考点是目标中心,然后Decoder俺中心信息去预测box类别。
补充优化:迭代bbox结果优化和两级预测。
预测部分是用了K为4 M为8。也就是单个尺度的采样其实很少,也是为了省空间。往可解释性上说,感觉上多层ATT其实是在某个目标周围多次采样(试探),然后确认是不是在目标中心,同时边界大概在哪。多次试探后确认,高尺度决定个大概后,低尺度精细化?感觉这个Offset多次猜?
实现倒是简单,这是一个M=1情况下的可变形Att的实现。如
@立夏之光 所说,K=1就是个Warp,如果要保证稀疏,所有目标区域都要往Reference Point集中?如果作者能给最后激活图看看也许更好。
class DFMAtt(nn.Module):
def __init__(self, in_ch,out_ch, k):
super().__init__()
self.conv = nn.Conv2d(in_ch, out_ch, 1, 1, 0,bias=True)
self.k=k
self.out_ch=out_ch
offset_list=[]
for x in range(k):
conv = nn.Conv2d(in_ch, 2, 1, 1, 0,bias=True)
offset_list.append(conv)
self.offset_conv=nn.ModuleList(offset_list)
self.weight_conv= nn.Sequential(nn.Conv2d(in_ch, k, 1, 1, 0,bias=True),nn.Softmax(1))
def forward(self,input):
b, c, h, w = input.size()
proj_feat=self.conv(input)
offsets=[]
for x in range(self.k):
flow = self.offset_conv[x](input)
offsets.append(flow)
offsetweights= torch.repeat_interleave(self.weight_conv(input),self.out_ch,1)
feats=[]
for x in range(self.k):
flow=offsets[x]
flow = flow.permute(0, 2, 3, 1)
grid_y, grid_x = torch.meshgrid(torch.arange(0, h), torch.arange(0, w))
grid = torch.stack((grid_x, grid_y), 2).float()
grid.requires_grad = False
grid = grid.type_as(proj_feat)
vgrid = grid + flow
vgrid_x = 2.0 * vgrid[:, :, :, 0] / max(w - 1, 1) - 1.0
vgrid_y = 2.0 * vgrid[:, :, :, 1] / max(h - 1, 1) - 1.0
vgrid_scaled = torch.stack((vgrid_x, vgrid_y), dim=3)
feat = F.grid_sample(proj_feat, vgrid_scaled, mode='bilinear', padding_mode='zeros')
feats.append(feat)
feat=torch.cat(feats,1)*offsetweights
feat= sum(torch.split(feat,self.out_ch,1))
return feat 知乎
发现更大的世界
打开
知乎
发现更大的世界
打开
 Chrome
继续
Chrome
继续
手码抢答。
开启了人人(并不)都可以玩得起 DETR 的时代,contribution 自然是相当大。如果 DETR 能引领一个大发展,那么本文之于 DETR,应该相当于 ResNet 之于 AlexNet。
和
@余昌黔 大佬的 Representative Graph Neural Network 在思路上有很强的一致性。都是对全连接 Transformer 的计算量进行优化,为每个 query 采样 K 个 key-value pair。考虑到 feature map 上的冗余,采样点能够很好的概括关键信息。不过私以为最大的性能收益,来源于这一方法可以自然地引入多尺度特征。
个人也有个疑问之处,Table 2的第三行已经可以吊打 DETR(Table 1第四五行)。这里 K=1 时,方法退化为
@大大拉头 Semantic flow 里的 warping 操作。跟据经验,这个操作无法取得如此大的增益。希望作者们能来介绍下,实现还做了哪些改进呐。没有 MS input 的情况下,是用了 DC5 吗?
最近 CV 领域 transformer 相关文章频出,很多人评论 NLP 对 CV 输出。这点是不太赞同的。君不见 CV 领域 attention 文章频出,甚至被视为划水(???)。NLP 里 Sparse Transformer, LinFormer 赞誉一片。但其实 CV 领域早就屡见不鲜。这里可以参见我写过的知乎文章和回答。Transformer 就是 Attention 的一种。捧 Transformer 损 Attention,是本领域最大的乌龙了
编辑于 10-09 继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
先引用一下之前关于DETR的分析吧
王Sr:如何看待End-to-End Object Detection with Transformers?www.zhihu.com
我们可以认为之前的单/多阶段算法、anchor based/free的方法都是local的方法,detr算是完全global的方法,而本文算是重新将detr拉回到了local的思路上,也借此加快了收敛速度。
接下来再对本文做个拆解:
首先本文提出将原始detr的encoder部分换成deformable attention module,这个过程可以理解成是sparse transformer,当然也可以单纯理解成是基于deformable+self attention的fpn的改进(当然这种操作似乎之前也见过,segmentation里的semantic flow,还有VID领域LSTS)
decoder部分iterative bbox refinement和two stage的思路看起来就很像是relationnet,本文没有引用这篇还是有些奇怪
而经过了上面这两点的修改,其实本文和detr的相似度就低了很多,甚至完全可以看做是之前纯local的方式的改进,区别就在于query(之前的local的方法中anchor也可以理解成是一种query)和损失函数的设置。
从这个角度说,其实会引出一个更值得探讨的问题: 检测任务我们究竟需要怎样的query?究竟多少query足够很好的完成检测任务?(detr中只有100个,而之前的方法动辄需要几千个anchor)。这个问题如果可以得到很好的解决,目标检测领域可能会迎来真正的革新。
发布于 10-10 继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
DETR暴力搜索有效特征,Deformable DETR有目的地搜索有效特征,自然高效。
发布于 6 小时前 继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
有完整代码吗?希望早日开源
发布于 10-11 继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
泻药
感觉本质上还是高质量的local patch的提升:)
发布于 10-09 继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
取代的话,detr就取代了。其实性能啥的提上来是迟早的,fb给的baseline毕竟啥也没加。deformable确实是最大创新,如题所示。然而,对于大多数像我这样的穷逼来说,玩不玩得起其实也不是看训练速度,速度慢我可以等,显存不够我只能砸锅炉,并且推理速度也还是捉急。
目测最大瓶颈在六层encoder layer,六层一丢(或者用更好的方式代替),显存掉一大半,跑起来估计得比yolo快。谁要是能搞定这个或许比这篇文章更 牛(逃
编辑于 10-09 真诚赞赏,手留余香 还没有人赞赏,快来当第一个赞赏的人吧! 继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
不能,整体直接预测的话,可解释性和debug方面会更差,不利于工业使用,而且detr本身性能已经问题不大了,后续的工作也只能算是针对性优化了。
发布于 13 小时前 继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
没看过,应该属于优化过程中的产物,最早的是fb,大概率不是。
编辑于 10-10 继续浏览内容
知乎
发现更大的世界
打开
Chrome
继续
广告
相关问题
Faster-RCNN会不会被YOLOv3取代? 7 个回答
如何评价rcnn、fast-rcnn和faster-rcnn这一系列方法? 24 个回答
py-faster-rcnn代码中的bbox_inside_weights的作用是什么? 6 个回答
目标检测SSD相对于YOLO与faster-RCNN做了哪些改进?效果如何呢? 7 个回答
如何看待超越mask-rcnn的blendmask?谁会是下一个mask? 7 个回答
广告
标签:10,知乎,Faster,Deformable,self,ch,grid,RCNN,DETR 来源: https://www.cnblogs.com/cx2016/p/13812583.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。