贝叶斯优化: 一种更好的超参数调优方式
简介
本文受 浅析 Hinton 最近提出的 Capsule 计划 启发,希望以更通俗的方式推广机器学习算法,让有数学基础和编程能力的人能够乐享其中。
目前人工智能和深度学习越趋普及,大家可以使用开源的Scikit-learn、TensorFlow来实现机器学习模型,甚至参加Kaggle这样的建模比赛。那么要想模型效果好,手动调参少不了,机器学习算法如SVM就有gamma、kernel、ceof等超参数要调,而神经网络模型有learning_rate、optimizer、L1/L2 normalization等更多超参数可以调优。
很多paper使用一个新的模型可以取得state of the art的效果,然后提供一组超参数组合方便读者复现效果,实际上这些超参数都是“精挑细选”得到的,背后有太多效果不好的超参数尝试过程被忽略,大家也不知道对方的超参数是如何tune出来的。因此,了解和掌握更好的超参数调优方法在科研和工程上是很有价值的,本文将介绍一种更好的超参数调优方式,也就是贝叶斯优化(Bayesian Optimization),以及开源调参服务Advisor的使用介绍。
超参数介绍
首先,什么是超参数(Hyper-parameter)?这是相对于模型的参数而言(Parameter),我们知道机器学习其实就是机器通过某种算法学习数据的计算过程,通过学习得到的模型本质上是一些列数字,如树模型每个节点上判断属于左右子树的一个数,或者逻辑回归模型里的一维数组,这些都称为模型的参数。
那么定义模型属性或者定义训练过程的参数,我们称为超参数,例如我们定义一个神经网络模型有9527层网络并且都用RELU作为激活函数,这个9527层和RELU激活函数就是一组超参数,又例如我们定义这个模型使用RMSProp优化算法和learning rate为0.01,那么这两个控制训练过程的属性也是超参数。
显然,超参数的选择对模型最终的效果有极大的影响。如复杂的模型可能有更好的表达能力来处理不同类别的数据,但也可能因为层数太多导致梯度消失无法训练,又如learning rate过大可能导致收敛效果差,过小又可能收敛速度过慢。
那么如何选择合适的超参数呢,不同模型会有不同的最优超参数组合,找到这组最优超参数大家会根据经验、或者随机的方法来尝试,这也是为什么现在的深度学习工程师也被戏称为“调参工程师”。根据No Free Lunch原理,不存在一组完美的超参数适合所有模型,那么调参看起来是一个工程问题,有可能用数学或者机器学习模型来解决模型本身超参数的选择问题吗?答案显然是有的,而且通过一些数学证明,我们使用算法“很有可能”取得比常用方法更好的效果,为什么是“很有可能”,因为这里没有绝对只有概率分布,也就是后面会介绍到的贝叶斯优化。
自动调参算法
说到自动调参算法,大家可能已经知道了Grid search(网格搜索)、Random search(随机搜索),还有Genetic algorithm(遗传算法)、Paticle Swarm Optimization(粒子群优化)、Bayesian Optimization(贝叶斯优化)、TPE、SMAC等。
这里补充一个背景,机器学习模型超参数调优一般认为是一个黑盒优化问题,所谓黑盒问题就是我们在调优的过程中只看到模型的输入和输出,不能获取模型训练过程的梯度信息,也不能假设模型超参数和最终指标符合凸优化条件,否则的话我们通过求导或者凸优化方法就可以求导最优解,不需要使用这些黑盒优化算法,而实际上大部分的模型超参数也符合这个场景。其次是模型的训练过程是相对expensive的,不能通过快速计算获取大量样本,我们知道DeepMind用增强学习模型DQN来打Atari游戏,实际上每一个action操作后都能迅速取得当前的score,这样收集到大量样本才可以训练复杂的神经网络模型,虽说我们也可以用增强学习来训练超参数调优的模型,但实际上一组超参数要训练一个模型需要几分钟、几小时、几天甚至几个月的时间,无法快速获取这么多样本数据,因此需要有更“准确和高效”的方法来调优超参数。
像遗传算法和PSO这些经典黑盒优化算法,我归类为群体优化算法,也不是特别适合模型超参数调优场景,因为需要有足够多的初始样本点,并且优化效率不是特别高,本文也不再详细叙述。
目前业界用得比较多的分别是Grid search、Random search和Bayesian Optimization。网格搜索很容易理解和实现,例如我们的超参数A有2种选择,超参数B有3种选择,超参数C有5种选择,那么我们所有的超参数组合就有2 * 3 * 5也就是30种,我们需要遍历这30种组合并且找到其中最优的方案,对于连续值我们还需要等间距采样。实际上这30种组合不一定取得全局最优解,而且计算量很大很容易组合爆炸,并不是一种高效的参数调优方法。
业界公认的Random search效果会比Grid search好,Random search其实就是随机搜索,例如前面的场景A有2种选择、B有3种、C有5种、连续值随机采样,那么每次分别在A、B、C中随机取值组合成新的超参数组合来训练。虽然有随机因素,但随机搜索可能出现效果特别差、也可能出现效果特别好,在尝试次数和Grid search相同的情况下一般最值会更大,当然variance也更大但这不影响最终结果。在实现Random search时可以优化,过滤随机可能出现过的超参数组合,不需要重复计算。
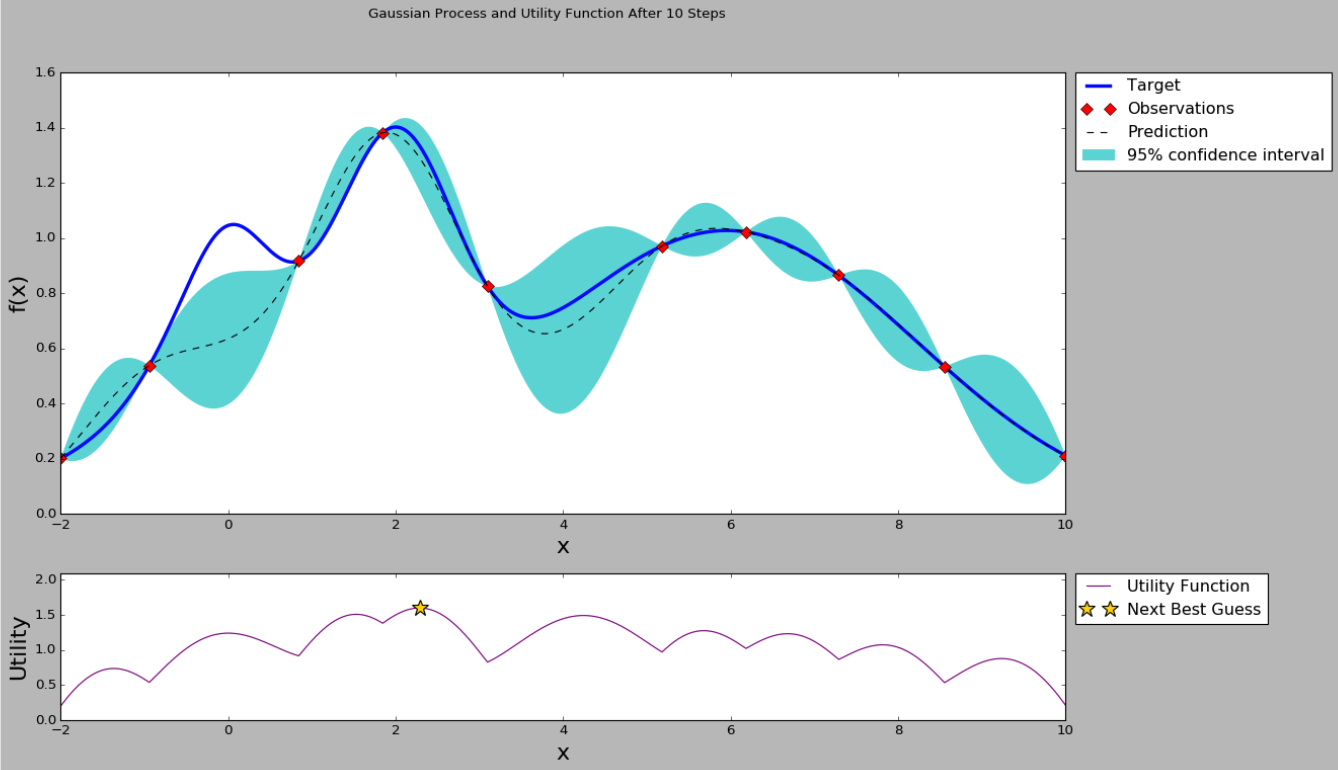
实际上Grid search和Random search都是非常普通和效果一般的方法,在计算资源有限的情况下不一定比建模工程师的个人经验要好,接下来介绍的Bayesian Optimization就是“很可能”比普通开发者或者建模工程师调参能力更好的算法。首先贝叶斯优化当然用到了贝叶斯公式,这里不作详细证明了,它要求已经存在几个样本点(同样存在冷启动问题,后面介绍解决方案),并且通过高斯过程回归(假设超参数间符合联合高斯分布)计算前面n个点的后验概率分布,得到每一个超参数在每一个取值点的期望均值和方差,其中均值代表这个点最终的期望效果,均值越大表示模型最终指标越大,方差表示这个点的效果不确定性,方差越大表示这个点不确定是否可能取得最大值非常值得去探索。因此实现贝叶斯优化第一步就是实现高斯过程回归算法,并且这里可以通过类似SVM的kernel trick来优化计算,在后面的开源项目Advisor介绍中我们就使用Scikit-learn提供的GaussianProgressRegressor,最终效果如下图,在只有3个初始样本的情况下我们(通过100000个点的采样)计算出每个点的均值和方差。
从曲线可以看出,中间的点均值较大,而且方差也比较大,很有可能这个点的超参数可以训练得到一个效果指标好的模型。那为什么要选均值大和方差大的点呢?因为前面提到均值代表期望的最终结果,当然是越大越好,但我们不能每次都挑选均值最大的,因为有的点方差很大也有可能存在全局最优解,因此选择均值大的点我们成为exploritation(开发),选择方差大的点我们称为exploration(探索)。那么究竟什么时候开发什么时候探索,并且开发和探索各占多少比例呢?不同的场景其实是可以有不同的策略的,例如我们的模型训练非常慢,只能再跑1组超参数了,那应该选择均值较大的比较有把握,如果我们计算力还能可以跑1000次,那么就不能放弃探索的机会应该选择方差大的,而至于均值和方差比例如何把握,这就是我们要定义的acquisition function了。acquisition function是一个权衡exploritation和exploration的函数,最简单的acquisition function就是均值加上n倍方差(Upper condence bound算法),这个n可以是整数、小数或者是正数、负数,更复杂的acquisition function还有Expected improvement、Entropy search等等。在原来的图上加上acquisition function曲线,然后我们求得acquisition function的最大值,这是的参数值就是贝叶斯优化算法推荐的超参数值,是根据超参数间的联合概率分布求出来、并且均衡了开发和探索后得到的结果。
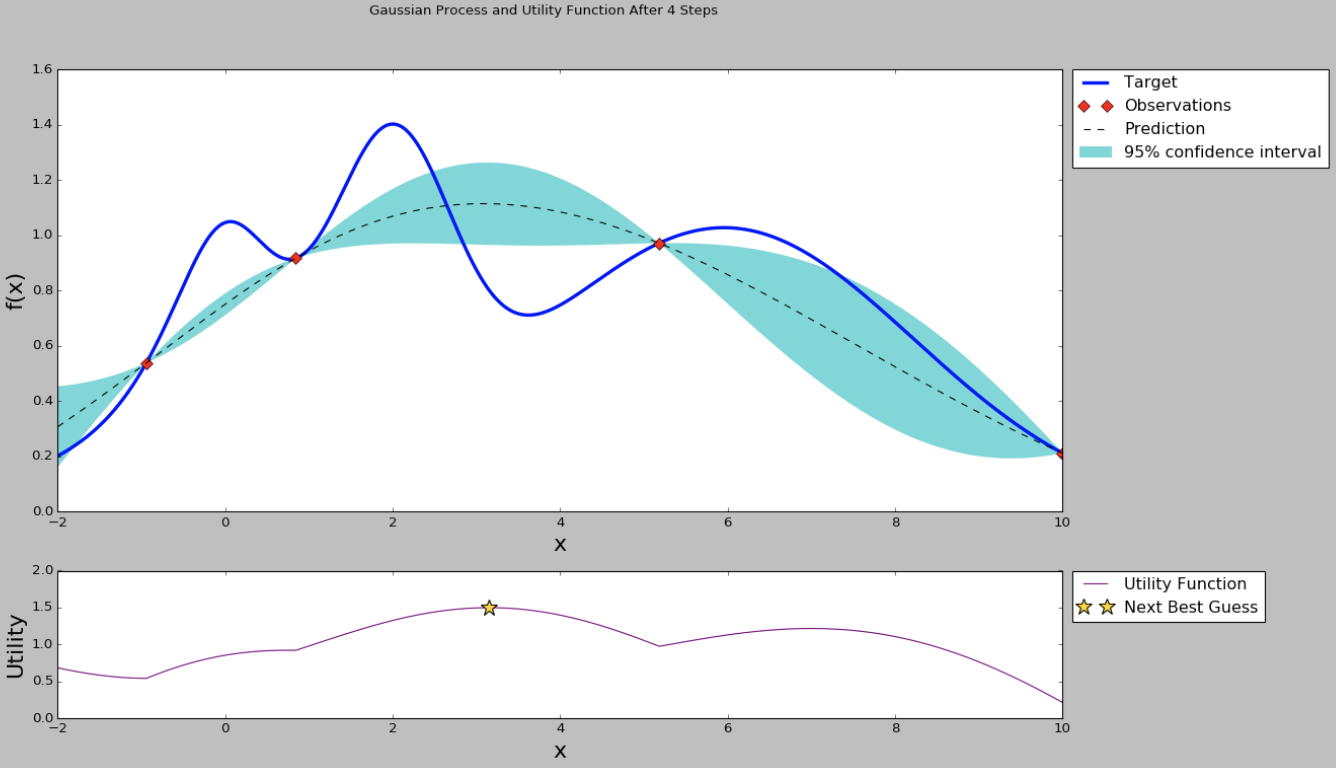
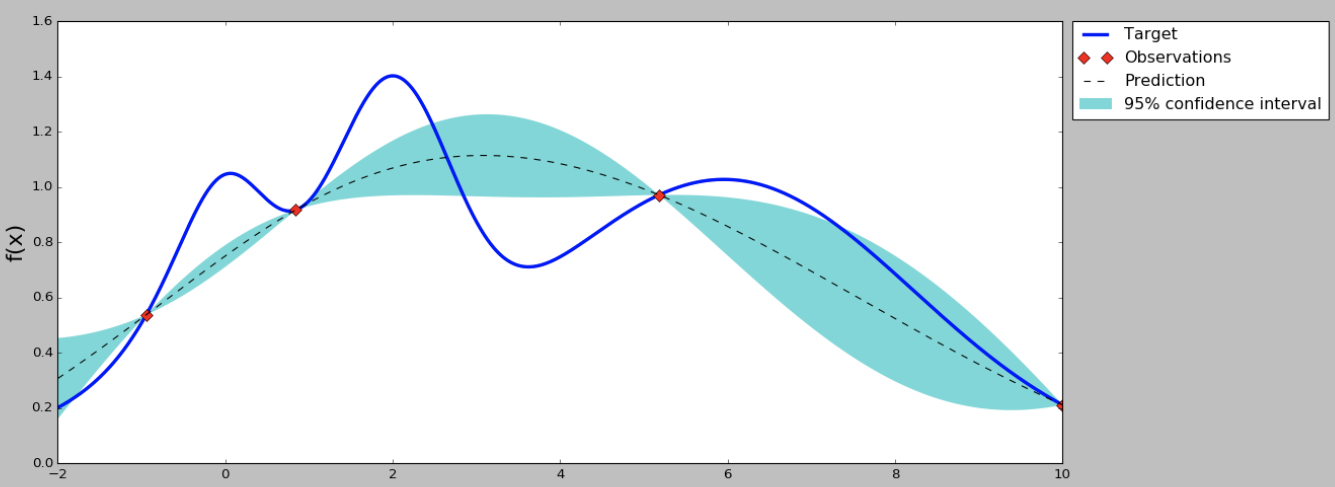
因此如果我们使用贝叶斯优化,那么我们下一个点就取中间偏左的点,使用这个点代表的超参数来训练模型,并且得到这个模型在这住超参数组合下的效果指标。有了新的指标,贝叶斯优化模型的样本就从3个变成了4个,这样可以重新计算超参数之间的后验概率分布和acquisition function,效果如下图。
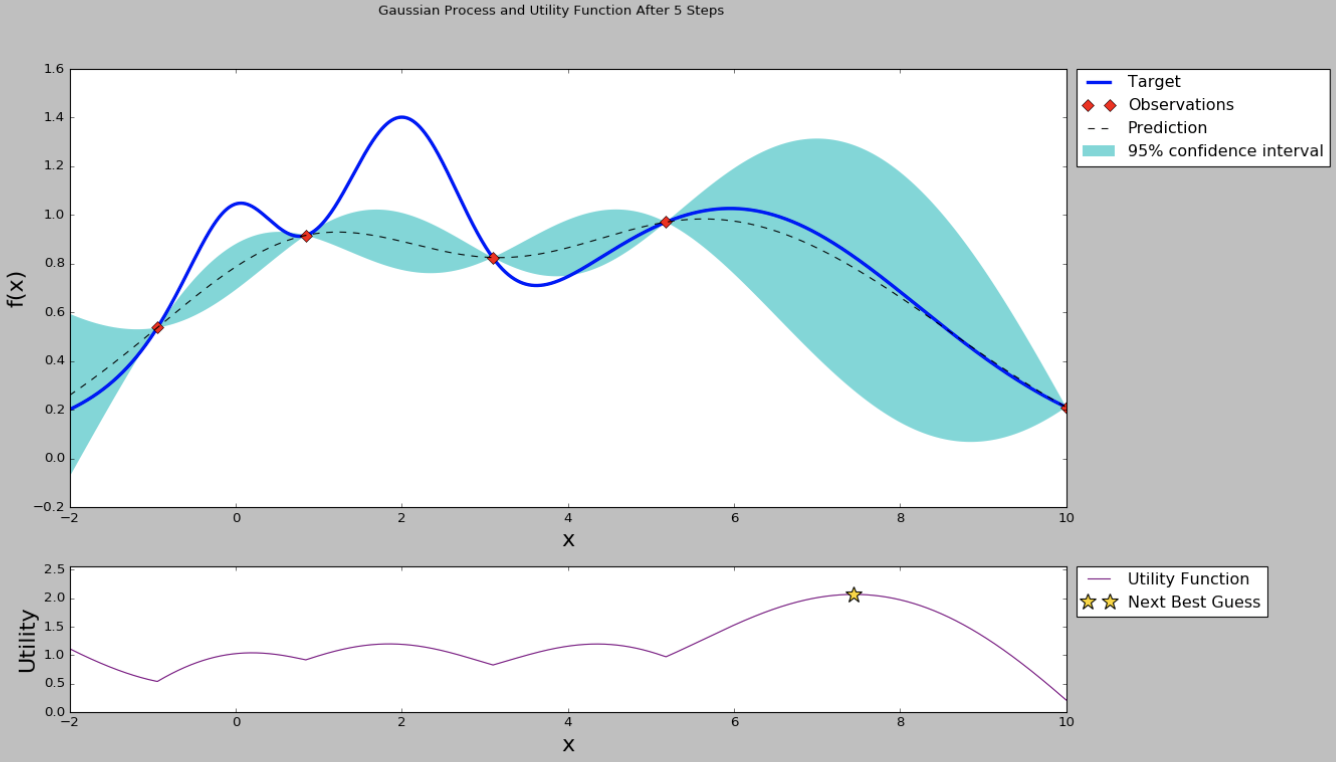
从均值和方差曲线看出,目前右边的点均值不低,并且方差是比较大,直观上我们认为探索右边区域的超参数是“很可能”有价值的。从acquisition function曲线我们也可以看出,右边的点在考虑了开发和探索的情况下有更高的值,因此我们下一个超参数推荐就是右边星号的点。然后我们使用推荐的超参数继续训练,得到新的模型效果指标,加入到高斯过程回归模型里面,得到新的均值-方差曲线和acquisition function曲线。
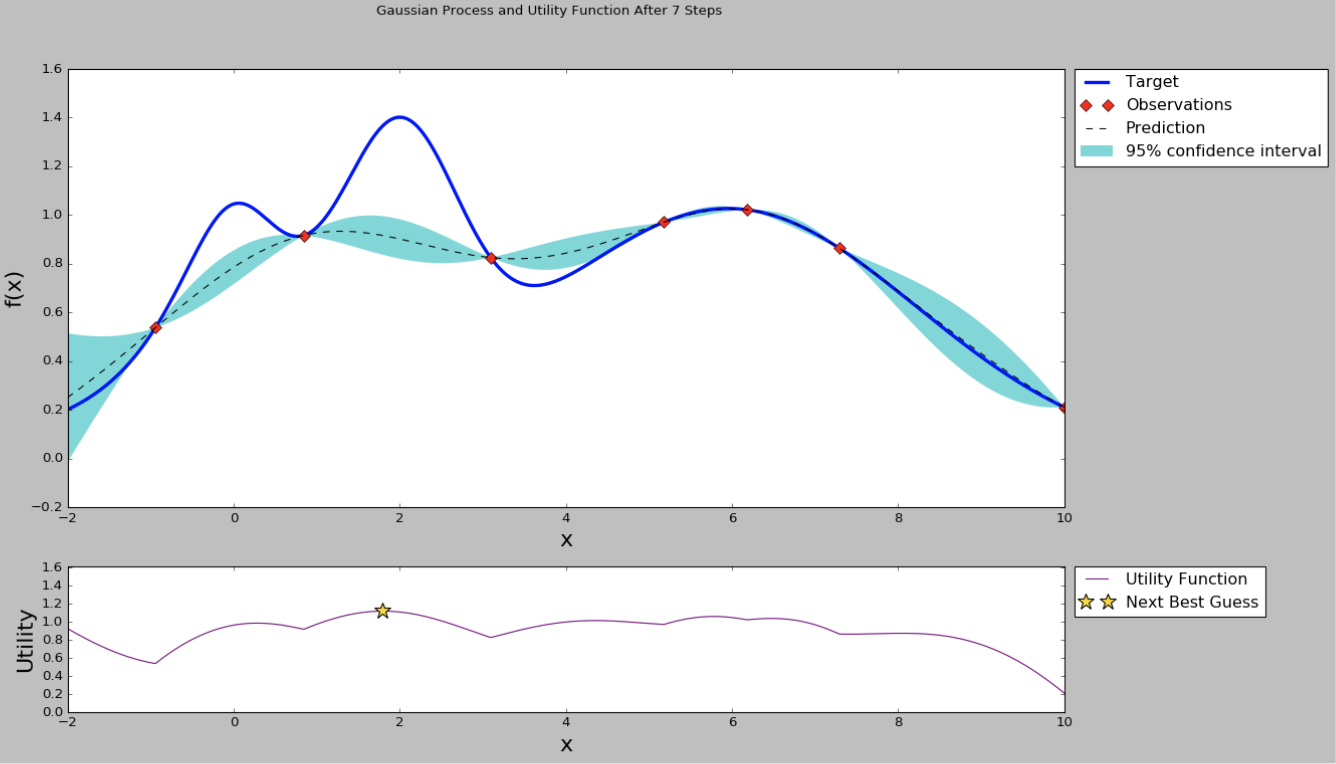
通过不断重复上述的步骤,我们的曲线在样本极少的情况下也可以毕竟最终真实的曲线。当然上面的图是在一个黑盒优化问题上模拟的,因此我们知道真实的曲线形状,现实的机器学习模型的超参数间不一定能画出完整的曲线,但通过符合联合高斯概率分布的假设,还有高斯过程回归、贝叶斯方程等数学证明,我们可以从概率上找到一个“很可能”更好的超参数,这是比Grid search或者Random search更有价值的方法。
注意,前面提到的Bayesian Optimization等超参数优化算法也是有超参数的,或者称为超超参数,如acquisition function的选择就是可能影响超参数调优模型的效果,但一般而言这些算法的超超参数极少甚至无须调参,大家选择业界公认效果比较好的方案即可。
Google Vizier
前面已经介绍了Grid search、Random search和Bayesian Optimization等算法,但并不没有完,因为我们要使用这些自动调参算法不可能都重新实现一遍,我们应该关注于自身的机器学习模型实现而直接使用开源或者易用的调参服务。
近期Google就开放了内部调参系统Google Vizier的论文介绍,感兴趣可以在这里阅读paper https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/46180.pdf

与开源的hyperopt、optunity不同,Vizier是一个service而不是一个library,也就是算法开发者不需要自己部署调参服务或者管理参数存储,只需要选择合适的调参算法,如贝叶斯优化,然后Vizier就会根据模型的一些历史指标推荐最优的超参数组合给开发者,直接使用这些超参数会比自己瞎猜或者遍历参数组合得到的效果更好。当然开发者可以使用Vizier提供的Algorithm Playground功能实现自己的自动调参算法,还有内置一些EarlyStopAlgorithm也可以提前发现一些“没有前途”的调优任务提前结束剩下计算资源。
目前Google Vizier已经支持Grid search、Random search已经改良过的Bayesian optimization,为什么是改良过的呢?前面提到贝叶斯优化也需要几个初始样本点,这些样本点一般通过随机搜索要产生,这就有冷启动的代价了,Google将不同模型的参数都归一化进行统一编码,每个任务计算的GaussianProcessRegressor与上一个任务的GaussianProcessRegressor计算的残差作为目标来训练,对应的acquisition function也不是简单的均值乘以n倍方差了,这相当于用了迁移学习模型的概念,从paper的效果看基本解决了冷启动的问题,这个模型被称为(Stacked)Batch Gaussian Process Bandit。
Google Vizier除了实现很好的参数推荐算法,还定义了Study、Trial、Algorithm等非常好的领域抽象,这套系统也直接应用到Google CloudML的HyperTune subsystem中,开发者只需要写一个JSON配置文件就可以在Google Cloud上自动并行多任务调参了。
Advisor开源项目
Google Vizier是目前我看过最赞的超参数自动调优服务,可惜的是它并没有开源,外部也只有通过Google CloudML提交的任务可以使用其接口,不过其合理的基础架构让我们也可以重现一个类似的自动调参服务。
Advisor就是一个Google Vizier的开源实现,不仅实现了和Vizier完全一致的Study、Trial、Algorithm领域抽象,还提供Grid search、Random search和Bayesian optimization等算法实现。使用Advisor很简单,我们提供了API、SDK、Web以及命令行等多种访问方式,并且已经集成Scikit-learn、XGBoost和TensorFlow等开源机器学习框架,基本只要写一个Python函数定义好模型输入和指标就可以实现任意的超参数调优(黑盒优化)功能。
Advisor使用Python实现,基于Scikit-learn的GPR实现了贝叶斯优化等算法,也欢迎更多开发者参与,开源地址 tobegit3hub/advisor 。
Advisor在线服务
hypertune.cn 是我们提供的在线超参数推荐服务,也是体验Advisor调参服务的最好入口,在网页上我们就可以使用所有的Grid search、Random search、Bayesian optimization等算法功能了。
首先打开 http://hypertune.cn , 目前我们已经支持使用Github账号登录,由于还没有多租户权限隔离因此不需要登录也可以访问全局信息。在首页我们可以查看所有的Study,也就是每一个模型训练任务的信息,也可以在浏览器上直接创建Study。

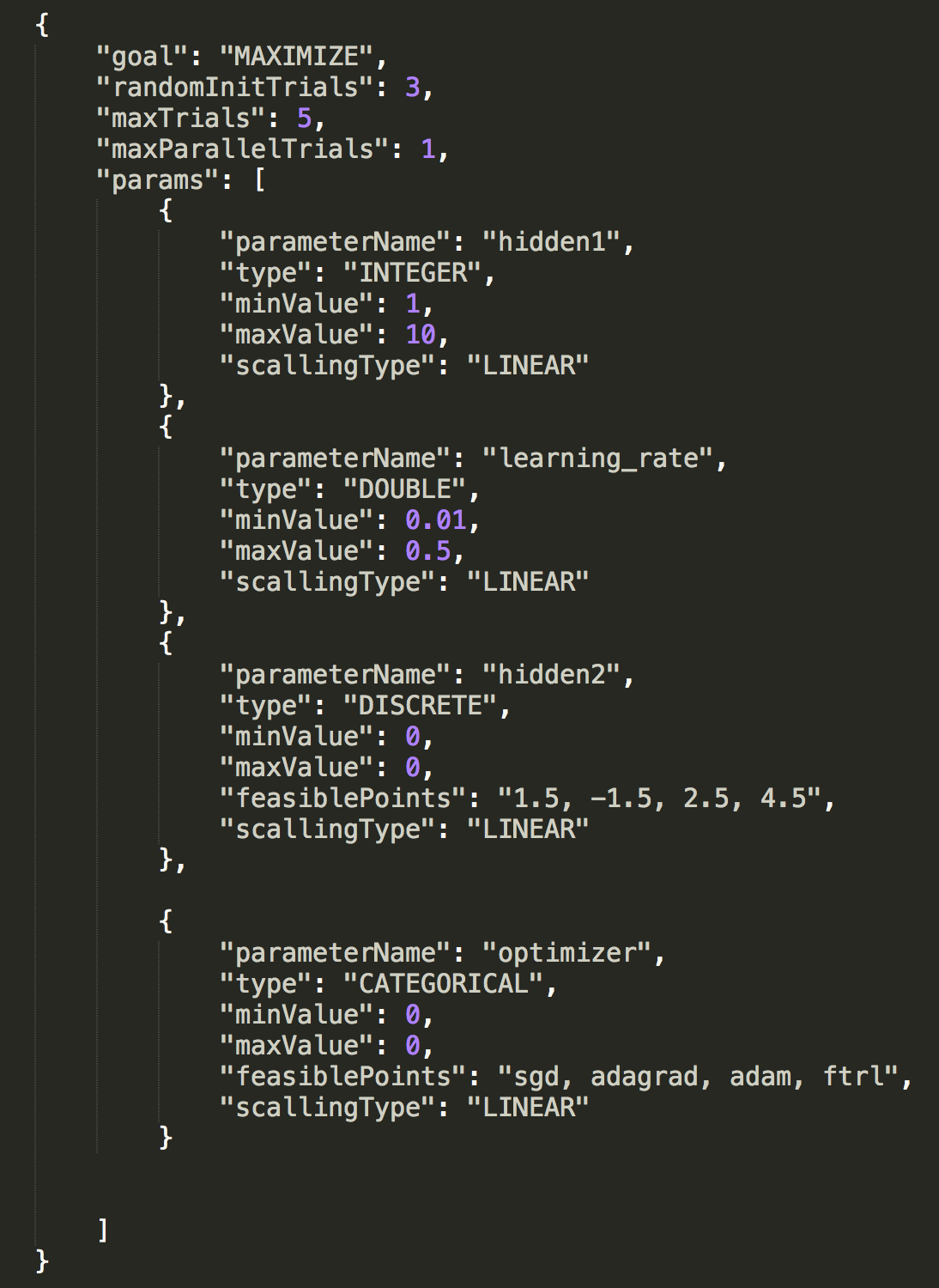
这里需要用户定义Study configuration,也就是模型超参数的search space,和Google Vizier一样我们支持Double、Integer、Discrete和Categorical四种类型的超参数定义,基本涵盖了数值型、字符串、连续型以及离散型的任意超参数类别,更详细的例子如下图。
定义好Study好,我们可以进入Study详情页,直接点击“Generate Suggestions”按钮生成推荐的超参数组合,这会根据用户创建Study选择的调参算法(如BayesianOptimization)来推荐,底层就是基于Scikit-learn实现的联合高斯分布、高斯过程回归、核技巧、贝叶斯优化等算法实现。
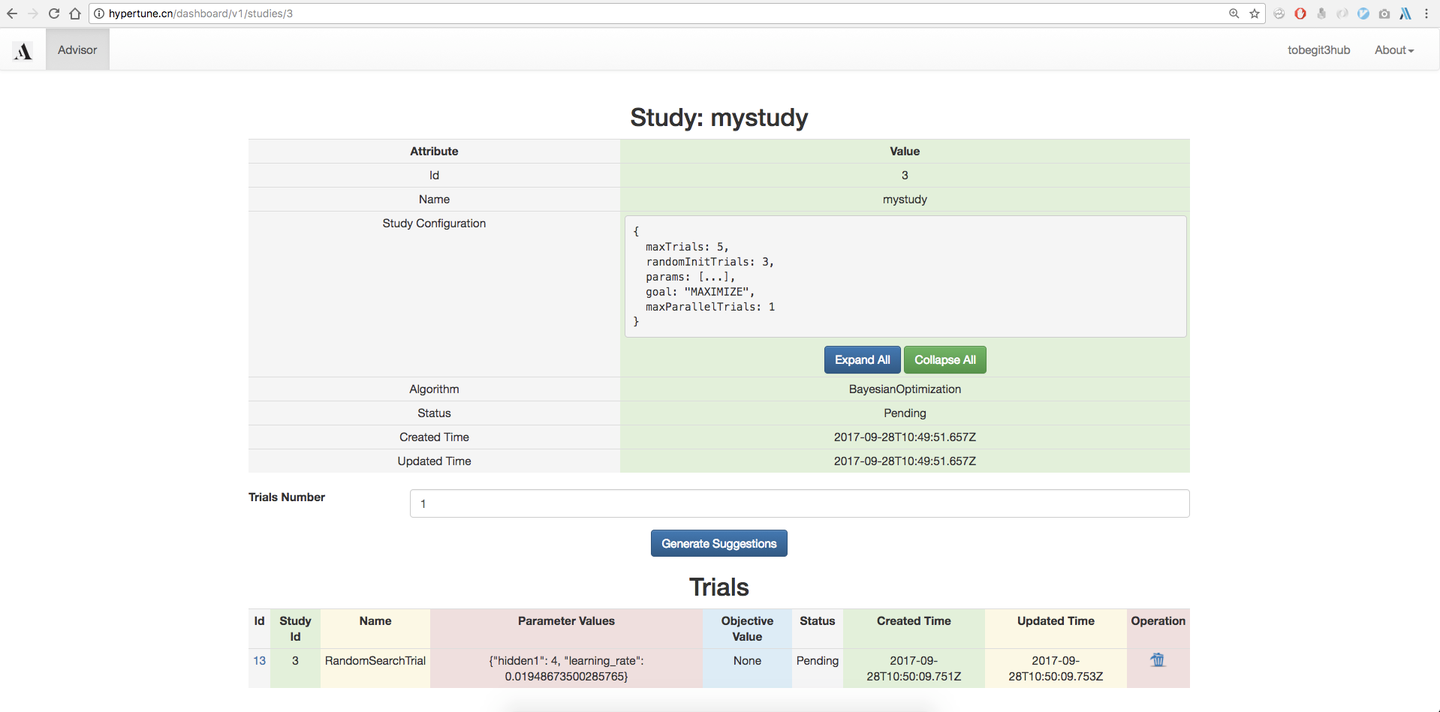
当然我们也可以使用Grid search、Random search等朴素的搜索算法,生成的Trial就是使用的该超参数组合的一次运行,默认是没有objective value的,我们可以在外部使用该超参数进行模型训练,然后把auc、accuracy、mean square error等指标在网页上回填到参数推荐服务,下一次超参数推荐就会基于已经训练得到模型数据,进行更优化、权衡exploritation和exploration后的算法推荐。对于Eearly stop算法,我们还需要每一步的性能指标,因此用户可以提供Training step以及对应的Objective value,进行更细化的优化。
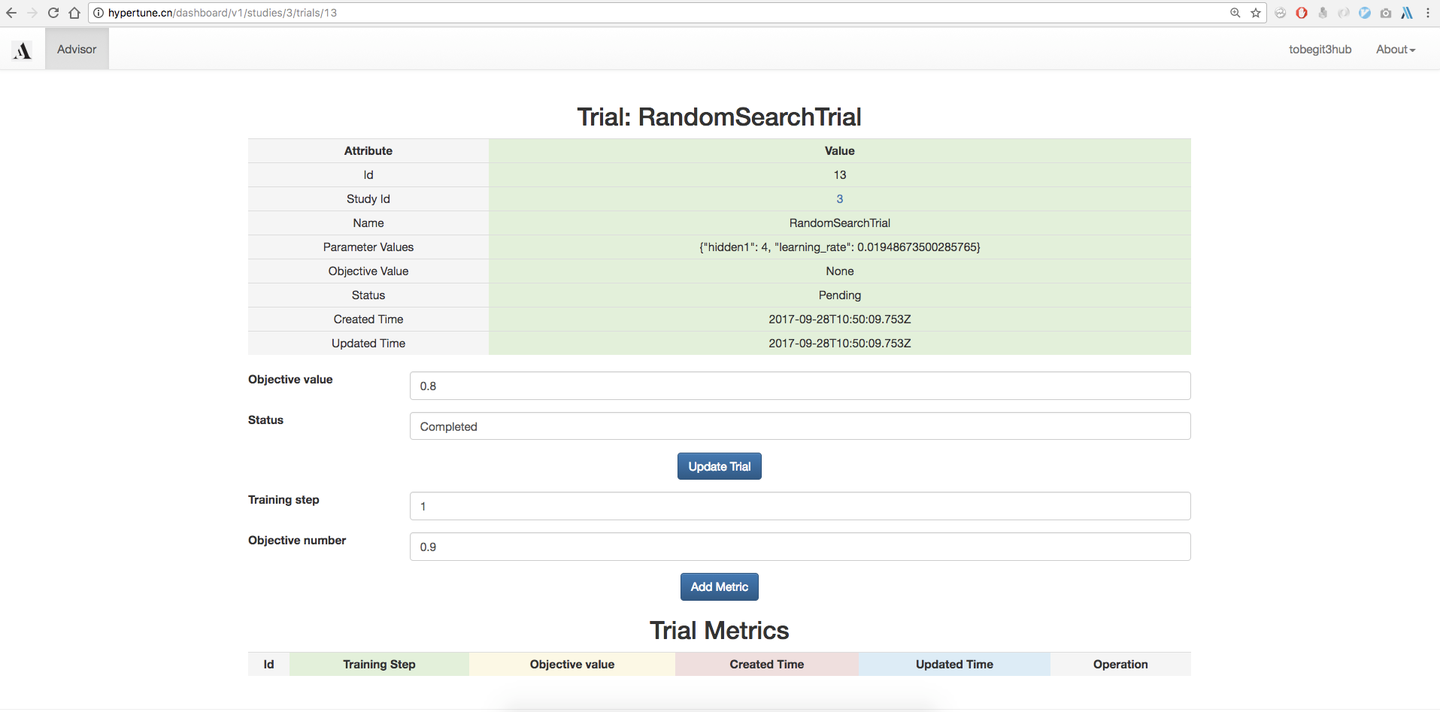
除了提供在网页上集成推荐算法,我们也集成了Scikit-learn、XGBoost和TensorFlow等框架,在命令行只要定义一个函数就可以自动实现创建Study、获取Trial以及更新Trial metrics等功能,参考 https://github.com/tobegit3hub/advisor/tree/master/examples 。对于贝叶斯优化算法,我们还提供了一维特征的可视化工具,像上面的图一样直观地感受均值、方差、acquisition function的变化,参考 https://github.com/tobegit3hub/advisor/tree/master/visualization 。
总结
本文介绍了一种更好的超参数调优方法,也就是贝叶斯优化算法,并且介绍了Google内部的Vizier调参服务以及其开源实现Advisor项目。通过使用更好的模型和工具,可以辅助机器学习工程师的建模流程,在学术界和工业界取得更多、更大的突破。
如果你有更好的超参数推荐算法,不妨留言,我们有能力实现并且让更多人用上 :)
编辑于 2018-04-03 机器学习 深度学习(Deep Learning) 模型参数
文章被以下专栏收录
推荐阅读
【推荐系统经典论文(九)】谷歌双塔模型
Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations背景介绍文章核心思想?在大规模的推荐系统中,利用双塔模型对user-item对的交互关系进行建模,学习【用户…
努力搬砖的小李![[科普]如何使用高大上的方法调参数](https://pic3.zhimg.com/v2-ffa474b7ac64b75515738ba909fd578d_250x0.jpg)
[科普]如何使用高大上的方法调参数
袁洋发表于理论与机器...
详解反向传播算法(上)
晓雷发表于晓雷机器学...
关于序列建模,是时候抛弃RNN和LSTM了
机器之心发表于机器之心39 条评论
写下你的评论...-
 Ghost Fan2 年前
我想知道大家调参真的是用算法调的么,感觉算力不够啊
Ghost Fan2 年前
我想知道大家调参真的是用算法调的么,感觉算力不够啊
-
 harryz回复Ghost Fan2 年前
harryz回复Ghost Fan2 年前
并不是,除非为了发调参的论文……
-
 Naraka回复harryz1 年前
Naraka回复harryz1 年前
你可还记得一招从天而降的掌法?
-
 华校专2 年前
最大的问题是,大数据条件下,你找个3到5次就顶天了……
华校专2 年前
最大的问题是,大数据条件下,你找个3到5次就顶天了……
-
 rainoftime2 年前
rainoftime2 年前
SMAC也是基于贝叶斯优化的
-
 杨海宏2 年前
杨海宏2 年前
请问这类贝叶斯优化的算法叫什么
-
 tobe (作者) 回复杨海宏2 年前
tobe (作者) 回复杨海宏2 年前
就叫做Bayesian optimization,其中acquisition function可以有很多种。
-
杨海宏回复tobe (作者)1 年前
一年后重新看到自己的留言= =...谢谢!
-
 Runhua Zhao2 年前
Runhua Zhao2 年前
我用bayes opt, 超参数太多,grid不现实
-
 芥子之川2 年前
MARK
芥子之川2 年前
MARK
-
 xin jin2 年前
xin jin2 年前
不看好贝叶斯优化做自动调参,小样本还行,大数据下,太费时间
-
tobe (作者) 回复xin jin2 年前
可以参考AlphaGo Zero论文,也是用基于Gaussian process的贝叶斯优化调参。
-
 穆文2 年前
神经网络这块儿并不太可行
穆文2 年前
神经网络这块儿并不太可行
-
穆文2 年前
另外要是可以的话,希望能加入对那几篇贝叶斯调参paper的理论解读
-
 小千2 年前
感觉以后会有超超超参数要调
小千2 年前
感觉以后会有超超超参数要调
-
 来咯兔子2 年前
来咯兔子2 年前
目前自己还是比较喜欢使用bayesOptimization,会尝试advisor的。
-
 DeepIn2 年前
DeepIn2 年前
期待更多论文
-
 YcoFlegs2 年前
YcoFlegs2 年前
贝叶斯优化和上限置信区间算法很接近?
-
 屈伟1 年前
屈伟1 年前
http://http://hypertune.cn/好像不能访问了?
-
 Harden回复屈伟1 年前
Harden回复屈伟1 年前
怎么成博彩网站了
-
 冰糖1 年前
冰糖1 年前
http://www.scholat.com/teamwork/teamworkdownloadscholar.html?id=1874&teamId=500 楼主总结的挺好的 贴一个贝叶斯优化在机器学习调参上的论文链接 感兴趣的可以看看
-
 leengsmile1 年前
Berkeley 开源的ray,里面有一个tune模块。楼主觉得如何
leengsmile1 年前
Berkeley 开源的ray,里面有一个tune模块。楼主觉得如何
-
 Kakaflo22thy回复leengsmile2 个月前
Kakaflo22thy回复leengsmile2 个月前
同问啊,最近就在看tune
-
 高飞1 年前
高飞1 年前
这个和hyperopt的模拟退火比哪个好啊
-
rot.cx刚刚
mark
标签:search,模型,贝叶斯,算法,调优,参数,回复 来源: https://www.cnblogs.com/cx2016/p/13025236.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。