标签:hadoop001 sh Master 集群 Spark 之高 spark
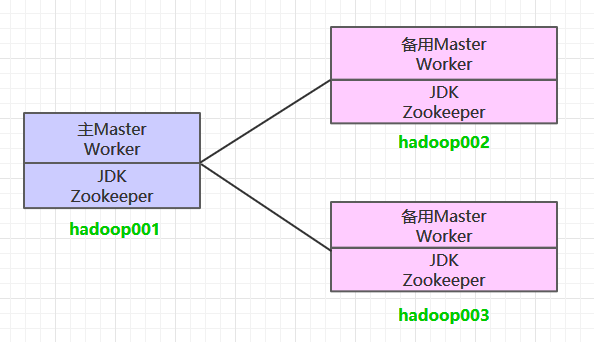
1. 集群规划
这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 和 hadoop003 上分别部署备用的 Master 服务,Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。
2. 前置条件
搭建 Spark 集群前,需要保证 JDK 环境、Zookeeper 集群和 Hadoop 集群已经搭建,相关步骤可以参阅:
3. Spark集群搭建
3.1 下载解压
下载所需版本的 Spark,官网下载地址:spark.apache.org/downloads.h…
下载后进行解压:
# tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
3.2 配置环境变量
# vim /etc/profile
添加环境变量:
export SPARK_HOME=/usr/app/spark-2.2.3-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
3.3 集群配置
进入 ${SPARK_HOME}/conf 目录,拷贝配置样本进行修改:
1. spark-env.sh
cp spark-env.sh.template spark-env.sh # 配置JDK安装位置 JAVA_HOME=/usr/java/jdk1.8.0_201 # 配置hadoop配置文件的位置 HADOOP_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop # 配置zookeeper地址 SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop001:2181,hadoop002:2181,hadoop003:2181 -Dspark.deploy.zookeeper.dir=/spark"
2. slaves
cp slaves.template slaves
配置所有 Woker 节点的位置:
hadoop001 hadoop002 hadoop003
3.4 安装包分发
将 Spark 的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下 Spark 的环境变量。 scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop002:usr/app/ scp -r /usr/app/spark-2.4.0-bin-hadoop2.6/ hadoop003:usr/app/
4. 启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动 ZooKeeper 服务:
zkServer.sh start
4.2 启动Hadoop集群
# 启动dfs服务 start-dfs.sh # 启动yarn服务 start-yarn.sh
4.3 启动Spark集群
进入 hadoop001 的 ${SPARK_HOME}/sbin 目录下,执行下面命令启动集群。执行命令后,会在 hadoop001 上启动 Maser 服务,会在 slaves 配置文件中配置的所有节点上启动 Worker 服务。
start-all.sh
分别在 hadoop002 和 hadoop003 上执行下面的命令,启动备用的 Master 服务:
# ${SPARK_HOME}/sbin 下执行
start-master.sh
4.4 查看服务
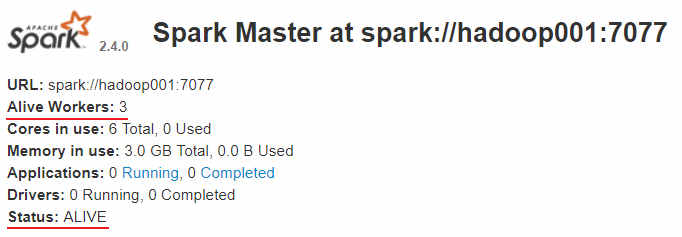
查看 Spark 的 Web-UI 页面,端口为 8080。此时可以看到 hadoop001 上的 Master 节点处于 ALIVE 状态,并有 3 个可用的 Worker 节点。
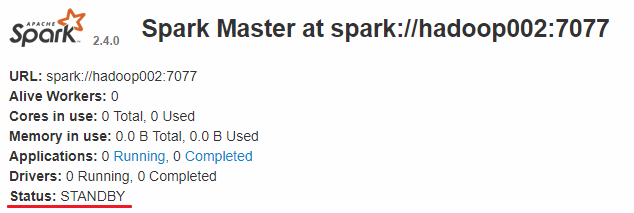
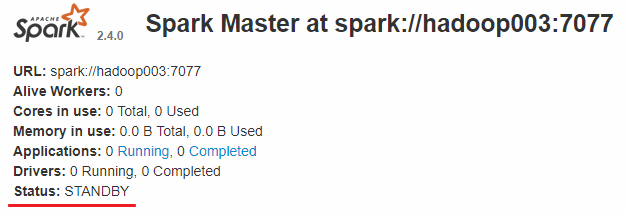
而 hadoop002 和 hadoop003 上的 Master 节点均处于 STANDBY 状态,没有可用的 Worker 节点。
5. 验证集群高可用
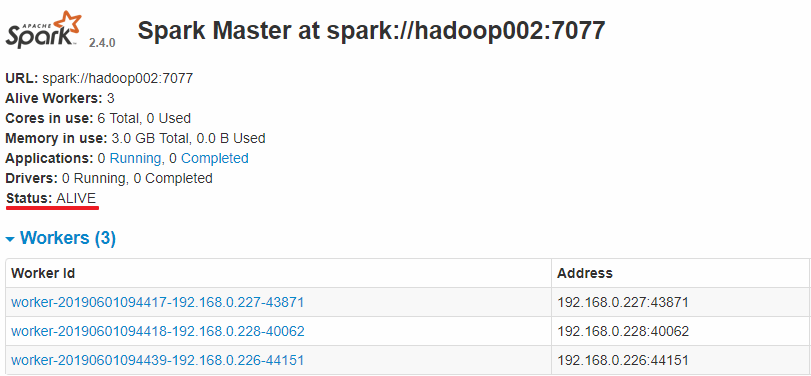
此时可以使用 kill 命令杀死 hadoop001 上的 Master 进程,此时备用 Master 会中会有一个再次成为 主 Master,我这里是 hadoop002,可以看到 hadoop2 上的 Master 经过 RECOVERING 后成为了新的主 Master,并且获得了全部可以用的 Workers。
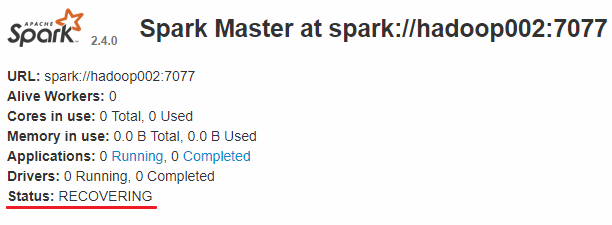
Hadoop002 上的 Master 成为主 Master,并获得了全部可以用的 Workers。
此时如果你再在 hadoop001 上使用 start-master.sh 启动 Master 服务,那么其会作为备用 Master 存在。
6. 提交作业
和单机环境下的提交到 Yarn 上的命令完全一致,这里以 Spark 内置的计算 Pi 的样例程序为例,提交命令如下:
spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ --executor-memory 1G \ --num-executors 10 \ /usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar \ 100
链接:https://juejin.im/post/5d859539f265da03913550e2
标签:hadoop001,sh,Master,集群,Spark,之高,spark 来源: https://www.cnblogs.com/sunfie/p/12433666.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。