标签:ch return int 0x20 register dfs 搜索
0x21 树与图的遍历
树与图的深度优先遍历
深度优先遍历,就是在每个点\(x\)上面的的多条分支时,任意选择一条边走下去,执行递归,直到回溯到点x后再走其他的边
int head[N];
bool v[N];
struct edge
{
int v , next;
}e[N];
inline void dfs( int x )
{
v[x] = 1;
for( register int i = head[x] ; i ; i = e[i].next)
{
register int y = e[i].next;
if( v[y] ) continue;
dfs( y ) ;
}
return ;
}树的DFS序
一般来说,我们在对树的进行深度优先时,对于每个节点,在刚进入递归时和回溯前各记录一次该点的编号,最后会产生一个长度为\(2N\)的序列,就成为该树的\(DFS\)序
\(DFS\)序的特点时:每个节点的\(x\)的编号在序列中恰好出现两次。设这两次出现的位置时\(L[x]\),\(R[x]\),那么闭区间\([L[x],R[x]]\)就是以\(x\)为根的子树的\(DFS\)序
inline void dfs( int x )
{
a[ ++ tot ] = x; // a储存的是DFS序
v[ x ] = 1;
for( register int i = head[x] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( v[y] ) continue;
dfs( y );
}
a[ ++ tot ] = x;
return ;
}树的深度
树中各个节点的深度是一种自顶向下的统计信息
起初,我们已知根节点深度是\(0\).若节点\(x\)的深度为\(d[x]\),则它的节点\(y\)的深度就是\(d[y] = d[x] + 1\)
inline void dfs( int x )
{
v[ x ] = 1;
for( register int i = head[ x ] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( v[ y ] ) continue;
d[ y ] = d[ x ] + 1; // d[]就是深度
dfs( y );
}
return ;
}树的重心
对于一个节点\(x\),如果我们把它从树中删除,呢么原来的一颗树可能会被分割成若干个树。设\(max\_part(x)\)表示在删除节点\(x\)后产生子树中最大的一颗的大小。使\(max\_part(p)\)最下的\(p\)就是树的重心
inline void dfs( int x )
{
v[ x ] = 1 , size[ x ] = 1;//size 表示x的子树大小
register int max_part = 0; // 记录删掉x后最大一颗子树的大小
for( register int i = head[ x ] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( v[y] ) continue;
dfs( y );
size[x] += size[y];
}
max_part = max ( max_part , n - size[x] );
if( max_part < ans ) //全局变量ans记录重心对应的max_part
{
ans = max_part;
pos = x;//pos 重心
}
return ;
}图的联通块划分
若在一个无向图中的一个子图中任意两个点之间都存在一条路径(可以相互到达),并且这个子图是“极大的”(不能在扩展),则称该子图是原图的一个联通块
如下代码所示,cnt是联通块的个数,v记录的是每一个点属于哪一个联通块
inline void dfs( int x )
{
v[ x ] = cnt;
for( register int i = head[x] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( v[y] ) continue;
dfs(y);
}
return ;
}
for( register int i = 1 ; i < = n ; i ++ )
{
if( v[i] ) continue;
cnt ++ ;
dfs( i );
}图的广度优先搜索遍历
树与图的广度优先遍历是利用一个队列来实现的
queue< int > q;
inline void bfs()
{
q.push( 1 ) , d[1] = 1;
while( !q.empty() )
{
register int x = q.front(); q.pop();
for( register int i = head[ x ] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( d[y] ) continue;
d[y] = d[x] + 1;
q.push(y);
}
}
return ;
}上面的代码中,我们在广度优先搜索中顺便求了个树的深度\(d\)
拓扑排序
给定一张有向无环图,若一个序列A满足图中的任意一条边(x,y)x都在y的前面呢么序列A就是图的拓扑排序
求拓扑序的过程非常简单我们只需要不断将入度为0的点加入序列中即可
- 建立空拓扑序列A
- 预处理出所有入度为deg[i],起初把入度为0的点入队
- 取出对头节点x,并把x放入序列A中
- 对于从x出发的每条边(x,y),把deg[y]减1,若deg[y] = 0 ,把y加入队列中
- 重复3,4直到队列为空,此时A即为所求
inline void addedge( int x , int y )
{
e[ ++ tot ].v = y , e[ tot ].next = head[x] , head[x] = tot;
deg[x] ++;
}
inline void topsort()
{
queue< int > q;
for( register int i = 1 ; i <= n ; i ++ )
{
if( !deg[i] ) q.push( i );
}
while( !q.empty() )
{
register int x = q.front(); q.pop();
a[ ++ cnt ] = x;
for( register int i = head[x] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( -- deg[y] == 0 ) q.push( y );
}
}
return ;
}AcWing 164. 可达性统计
这道题的题意很简单,但是如果直接裸的计算会超时,所以要用拓扑序
首先求拓扑序,因为拓扑序中的每一个点都时由前面的点到的所以我们反过来从最后一个点开始
假设我们已经求得了\(x\)后面每一个点的所能到达的点,呢么我们对所有以x为起点的边所到达的点所能到达的点取并集就是\(x\)所等到达的所有的点
然后如果们要储存每个点所到达的点,如果我们用二维数组来存,会爆空间,所以为了节约空间可以用<bitset>来存
#include <bits/stdc++.h>
using namespace std;
const int N = 30010;
int n , m , head[N] , d[N] , a[N] , tot , cnt ;
bitset< N > f[N];
struct edge
{
int v , next;
}e[N];
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 1 ) + ( x << 3 ) + ch - '0';
ch = getchar();
}
return x;
}
inline void addedge( int u , int v )
{
e[ ++ tot ].v = v , e[ tot ].next = head[u] , head[u] = tot;
d[ v ] ++;
}
inline void topsort()
{
queue< int > q;
for( register int i = 1 ; i <= n ; i ++ )
{
if( !d[i] ) q.push( i );
}
while( !q.empty() )
{
register int x = q.front(); q.pop();
a[ ++ cnt ] = x;
for( register int i = head[x] ; i ; i = e[i].next )
{
register int y = e[i].v;
if( -- d[y] == 0 ) q.push( y );
}
}
return ;
}
int main()
{
n = read() , m = read();
for( register int i = 1 ; i <= m ; i ++ )
{
register int a = read() , b = read();
addedge( a , b );
}
topsort();
for( register int i = cnt , j = a[i] ; i ; i -- , j = a[i] )
{
f[j][j] = 1;
for( register int k = head[j] ; k ; k = e[k].next ) f[j] |= f[ e[k].v ];
}
for( register int i = 1 ; i <= n ; i ++ ) printf( "%d\n" , f[i].count() );
return 0;
}0x22 深度优先搜索
深度优先搜索算法\((Depth-First-Search)\)是一种用于遍历或搜索树或图的算法
沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点\(v\)的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
AcWing 165. 小猫爬山
这道题时dfs最基础的题目了
我们只需设计搜索的状态这道题就可以轻易的写出来
我们设(x,y)是搜索的状态即前x个小猫用了y个缆车
我们要转移的情况只有两种
- 小猫上前y辆缆车
- 小猫上y+1辆缆车(新开一辆)
所以我们只要枚举就好
然后就是如何优化算法
首先假如我们已经得到一个解pay,若此时的大于pay则不可能会更优,所以可以自己而回溯
然后我们把小猫从大到小排序可以排除很多不可能是结果的情况
#include <bits/stdc++.h>
using namespace std;
const int N = 20;
int n , w , c[N] , f[N], pay = N;
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline void dfs( int x , int y )
{
if( x > n )
{
pay = min( pay , y );
return ;
}
if( y > pay ) return ;
for( register int i = 1 ; i <= y ; i ++ )
{
if( f[i] + c[x] > w ) continue;
f[i] += c[x];
dfs( x + 1 , y );
f[i] -= c[x];
}
y ++;
f[y] += c[x];
dfs( x + 1 , y );
f[y] = 0;
return ;
}
inline bool cmp( int x , int y ) { return x > y; }
int main()
{
n = read() , w = read();
for( register int i = 1 ; i <= n ; i ++ ) c[i] = read();
sort( c + 1 , c + 1 + n , cmp );
dfs( 1 , 0 );
cout << pay << endl;
return 0;
}AcWing 166. 数独
这是一道经典的搜索题,不过是数据加强过的版本,所有直接搜索会T
必须要进行一些优化
首先我们想自己玩数独的时候是怎么玩的
肯定是首先填可能的结果最少的格子,在也是这道题优化的核心
如何快速的确定每个格子的情况?
const int n = 9;
int row[n] , col[n] , cell[3][3];
// row[] 表示行 col表示列 cell[][] 表示格子我们用一个九位二进制数来表示某一行、某一列、或某一个中可以填入的数,其中1表示可以填,0表示不能填
对于\((x,y)\)这个点我们只需\(row[x] \bigcap col[y] \bigcap cell[\frac{x}{3}][\frac{y}{3}]\)就可以知道这个点可以填入数字的集合然后用lowbit()把每一位取出来即可
而在二进制中的交集就是$& $操作,所以取交集的函数就是
inline int get( int x , int y )
{
return row[ x ] & col[ y ] & cell[ x / 3 ][ y / 3];
}
还有什么优化呢,lowbit()的时间复杂度是\(O(log(n))\)我们可以通过预处理把一些操作变成\(O(1)\)的
首先每次lowbit()得到的并不是最后一个一定位置而是一个二进制数,可以用这个maps[],\(O(1)\)查询最后一为的具体位置
for( register int i = 0 ; i < n ; i ++ ) maps[ 1 << i ] = i;其次对于每个二进制数中有多少个\(1\)的查询也是很慢的,可以用这个ones[],\(O(1)\)查询一个二进制数中有多少个\(1\)
for( register int i = 0 , s = 0 ; i < 1 << n ; i ++ , s = 0)
{
for( register int j = i ; j ; j -= lowbit( j ) ) s ++;
ones[ i ] = s;
}剩下就是常规的\(DSF\)
#include <bits/stdc++.h>
#define lowbit( x ) ( x & -x )
using namespace std;
const int N = 100 , n = 9;
int maps[ 1 << n ] , ones[ 1 << n ] , row[n] , col[n] , cell[3][3];
char str[N];
inline void init() //初始化
{
for( register int i = 0 ; i < n ; i ++ ) row[i] = col[i] = ( 1 << n ) - 1 ;
for( register int i = 0 ; i < 3 ; i ++ )
{
for( register int j = 0 ; j < 3 ; j ++ ) cell[ i ][ j ] = ( 1 << n ) - 1;
}
}
inline int get( int x , int y ) //取交集
{
return row[ x ] & col[ y ] & cell[ x / 3 ][ y / 3];
}
inline bool dfs( int cnt )
{
if( !cnt ) return 1; // 已经填满
register int minv = 10 , x , y;
for( register int i = 0 ; i < n ; i ++ )
{
for( register int j = 0 ; j < n ; j ++ )
{
if( str[ i * 9 + j ] != '.' ) continue;
register int t = ones[ get( i , j ) ];
if( t < minv ) // 找到可能情况最少的格子
{
minv = t;
x = i , y = j ;
}
}
}
for( register int i = get( x , y ) ; i ; i -= lowbit( i ) ) // 枚举这个格子填那些数
{
register int t = maps[ lowbit(i) ];
row[x] -= 1 << t , col[y] -= 1 << t; // 打标记
cell[ x / 3 ][ y / 3 ] -= 1 << t;
str[ x * 9 + y ] = t + '1';
if( dfs(cnt - 1 ) ) return 1;
row[x] += 1 << t , col[y] += 1 << t; // 删除标记
cell[ x / 3 ][ y / 3 ] += 1 << t;
str[ x * 9 + y ] = '.';
}
return 0;
}
int main()
{
for( register int i = 0 ; i < n ; i ++ ) maps[ 1 << i ] = i;
for( register int i = 0 , s = 0 ; i < 1 << n ; i ++ , s = 0)
{
for( register int j = i ; j ; j -= lowbit( j ) ) s ++;
ones[ i ] = s; // i 这个数二进制中有多少个 1
}
while( cin >> str , str[0] != 'e' )
{
init();
register int cnt = 0;
for( register int i = 0 , k = 0 ; i < n ; i ++ )
{
for( register int j = 0 ; j < n ; j ++ , k ++ )
{
if(str[k] == '.' ) { cnt ++ ; continue; } //记录有多少个数字没有填
register int t = str[k] - '1'; // 把已经填入的数字删除
row[ i ] -= 1 << t;
col[ j ] -= 1 << t;
cell[ i / 3 ][ j / 3 ] -= 1 << t;
}
}
dfs( cnt );
cout << str << endl;
}
return 0;
}0x23 剪枝
剪枝,就是减小搜索树的规模、尽早的排除搜索树中不必要的成分
- 优化搜索顺序
在一些问题中,搜索树的各个层次、各个分支的顺序是不固定的。不同的搜索顺序会产生不同的搜索树形态,其规模相差也很大。我们可以通过优先搜索更有可能出现结果的分支来提前找到答案 - 排除等效冗余
在搜索的过程中,如果能够判定搜索树上当前节点的几个分支是等效的,这我们搜索其中一个分支即可 - 可行性剪枝
在搜索的过程中对当前的状态进行检查,如果无论如何都不可能走到边界我们就放弃搜索当前子树,直接回溯 - 最优性剪枝
在搜索过程中假设我们已经找到了某一个解,如果我们目前的状态比已知解更劣就放弃继续搜索下去因为无法比当前解更优呢么后面情况累加起来后一定比当前解更劣,所以直接回溯 - 记忆化
可以记录每个状态的结果,在每次遍历过程中检查当前状态是否已经被访问过,若果被访问过直接返回之前搜索的结果
AcWing 167.木棒
这是一道经典的剪枝题
优化搜索顺序
- 把木棍从大到小排序,优先尝试比较长的木棍,越短的木棍适应能力越强
排除等效冗余
限制加入木棍的顺序必须是递减的,因为假如有两根木棍\(x,y(x<y)\),先加入\(x\)和先加入\(y\)是等效的
如果上一根木棍失败且和当前木棍长度相同,这当前木棍一定失败
如过当前木棍已经拼成一个完整的木棍,当后面拼接过程中失败则当前木棍无论怎么拼都一定会失败,因为在重新尝试的过程中会使用更多更小的木棍来拼成当前木棍,但更小的木棍的适用性更强,却失败了,所以用更长的木棍尝试也一定会失败
#include <bits/stdc++.h>
#pragma GCC optimize(3,"Ofast","inline")
#pragma GCC optimize(2)
using namespace std;
const int N = 100;
int n , m , a[N] , sum , cnt , len ;
bool v[N];
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline bool cmp( int x , int y ) { return x > y; }
inline bool dfs( int stick , int cur , int last)
{
if ( stick == cnt ) return 1;
if ( cur == len ) return dfs( stick + 1 , 0 , 1 );
register int fail = 0;
for (register int i = last; i <= n; i++) // 剪枝 2
{
if( v[i] || cur + a[i] > len || fail == a[i] ) continue;
// fail == a[i] 剪枝 3
v[i] = 1;
if ( dfs( stick , cur + a[i] , i + 1 ) ) return 1;
v[i] = 0 , fail = a[i];
if ( cur == 0 || cur + a[i] == len ) break;
// cur + a[i] = len 剪枝 4
}
return 0;
}
inline void work()
{
sum = n = 0;
for( register int i = 1 ; i <= m ; i ++ )
{
register int x = read();
if( x > 50 ) continue;
a[ ++ n ] = x , sum += x;
}
sort( a + 1 , a + 1 + n , cmp );
//剪枝 1
for( len = a[1] ; len <= sum ; len ++ )
{
if( sum % len ) continue;
cnt = sum / len;
memset( v , 0 , sizeof( v ) );
if( dfs( 1 , 0 , 1 ) ) break;
}
printf( "%d\n" , len );
return ;
}
int main()
{
while(1)
{
m = read();
if( m == 0 ) break;
work();
}
return 0;
}
0x24 迭代加深
深度优先搜索(\(ID-DSF\))就是每次选择一个分支,然后不断的一直搜索下去,直到搜索边界在回溯,这种算法有一定的缺陷
比如下面这张图,我要红色点走到另一个红色点
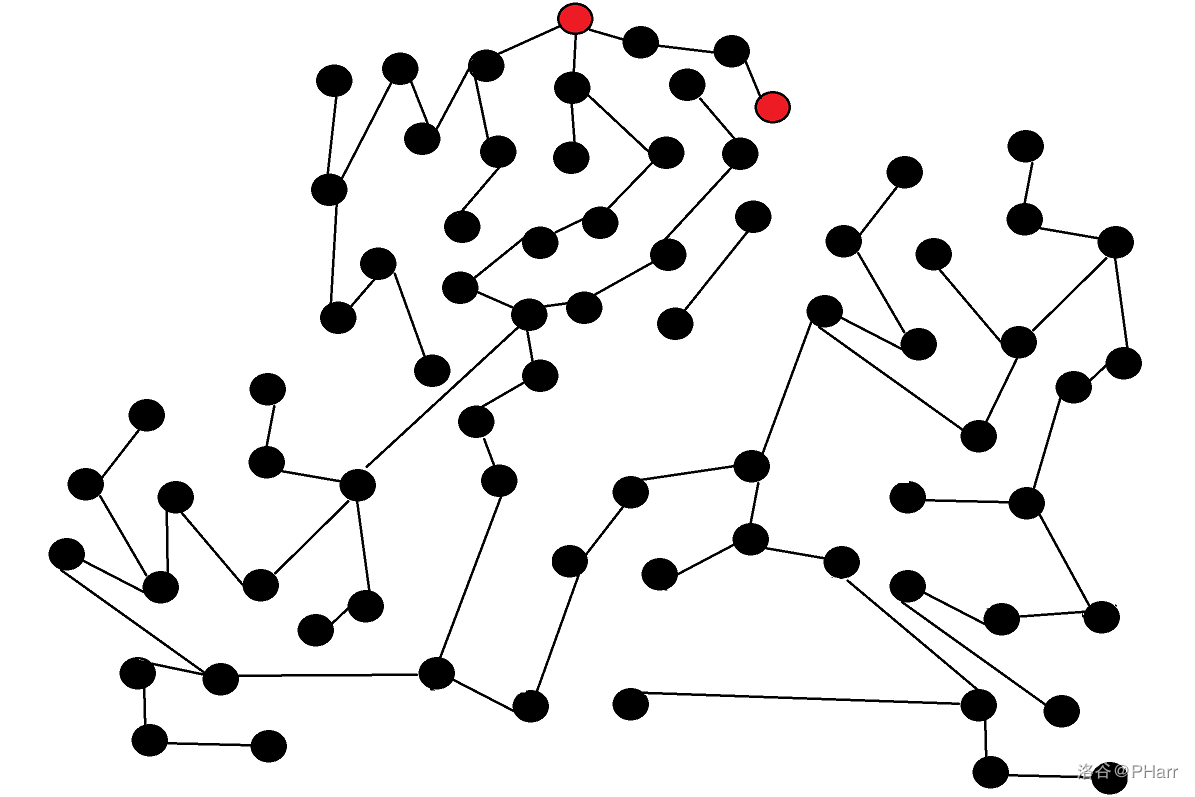
如果用普通的\(DFS\)前面的很多状态都是无用的,因为子树太深了
并且每到一个节点我都要储存很多的东西\(BFS\)很不好存
这是就要用到迭代加深了
AcWing 170. 加成序列
这道题就是一个迭代加深搜索的模板题
为什么是迭代加深搜索呢?
分析题目给的性质
如果使用\(DFS\),你需要搜索很多层,并且第一个找到的解不一定最有解
如果使用\(BFS\),你需要在队列中储存\(M\)个长度为\(n\)的数组(\(M\)是队列长度),不仅储存非常麻烦并且还有可能会爆栈
所以通过迭代加深性质就能很好的解决这个问题
限制序列的长度,不断从已知的数中找两个相加,到边界时判断一下,比较常规
优化搜索顺序
- 为了能够尽早的达到\(n\),从大到小枚举\(i\),\(j\)
排除等效冗余
因为\(i\),\(j\)和\(j\),\(i\)是等效的所以保证\(j \le i\)
不同的\(i\),\(j\)可能出现\(a[i]+a[j]\)相同的情况,对相加结果进行判重
#include <bits/stdc++.h>
using namespace std;
const int N = 105;
int n , m , a[N];
bitset< N > vis;
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline bool ID_dfs( int k )
{
if( k > m ) return a[m] == n;
vis.reset();
for( register int i = k - 1 ; i > 0 ; i -- )
{
for( register int j = k - 1 ; j > 0 ; j -- )
{
register int cur = a[i] + a[j];
if( cur > n || vis[ cur ] || cur < a[ k - 1 ]) continue;
a[k] = cur;
vis[ cur ] = 1;
if( ID_dfs( k + 1 ) ) return 1;
}
}
return 0;
}
inline void work()
{
for( m = 1 ; m <= n ; m ++ )
{
if( ID_dfs( 2 ) ) break;
}
for( register int i = 1 ; i <= m ; i ++ ) printf( "%d " , a[i] );
puts("");
return ;
}
int main()
{
a[1] = 1 , a[2] = 2;
for( n = read() ; n ; n = read() ) work();
return 0;
}双向搜索
除了迭代加深外,双向搜索也可以大大减少在深沉子树上浪费时间
在一些问题中有明确的初始状态和末状态,呢么就可以采用双向搜索
从初状态和末状态出发各搜索一半,产生两颗深度减半的搜索树,在中间交汇组合成最终答案
AcWing 171.送礼物
这到题显然是一个\(DP\),但是由于它数字的范围非常大做\(DP\)肯定会\(T\)
所以这道题的正解就是\(DFS\)暴力枚举所有可能在判断
但是\(n\le 46\)所以搜索的复杂度是\(O(2^{46})\)依然会\(T\)
所以还是要想办法优化,这里用了到了双向搜索的思想
我们将\(a[1\cdots n]\),分成\(a[1\cdots mid]\)和\(a[mid+1\cdots n]\)两个序列
首先现在第一个序列中跑一次\(DFS\)求出所以可以产生的合法情况,去重,排序
然后在第二个序列中再跑一次\(DFS\),求出的每一个解\(x\)就在第一序列产生的结构中二分一个\(y\)满足\(max(x),x\in\{ x | x + y \le W \}\),更新答案
优化
- 优化搜索顺序,从大到小搜索,很常规
- 我们发现第二次\(DFS\)中会多次二分,所以我们可以适当的减少第二个序列长度,来平衡复杂度。换句话来说就是适当的减少二分的次数,根据实测\(mid=\frac{n}{2}+2\)效果最好
#include <bits/stdc++.h>
using namespace std;
const int N = 50;
int w , n ,tot , a[N] , mid , ans , m ;
vector < int > s;
inline int read()
{
register int x = 0;
register char ch = getchar();
while( ch < '0' || ch > '9' ) ch = getchar();
while( ch >= '0' && ch <= '9' )
{
x = ( x << 3 ) + ( x << 1 ) + ch - '0';
ch = getchar();
}
return x;
}
inline void dfs_1( int x , long long sum )
{
s.push_back( sum );
if( x > mid ) return ;
if( sum + a[x] <= w ) dfs_1( x + 1 , sum + a[x] );
dfs_1( x + 1 , sum );
return ;
}
inline void dfs_2( int x , long long sum )
{
register auto t = lower_bound( s.begin() , s.end() , w - sum , greater<int>() );
if( sum + *t <= w ) ans = max( ans , I(sum) + *t );
if( x > n ) return ;
if( sum + a[x] <= w ) dfs_2( x + 1 , sum + a[x] );
dfs_2( x + 1 , sum );
return ;
}
int main()
{
w = read() , m = read() ;
for( register int i = 1 ; i <= m ; i ++ )
{
register int x = read();
if( x > w ) continue;
a[ ++ n ] = x;
}
mid = n >> 1 + 2;
sort( a + 1 , a + 1 + n , greater<int>() );
dfs_1( 1 , 0 );
sort( s.begin() , s.end() );
unique( s.begin() , s.end() );
dfs_2( mid + 1 , 0);
cout << ans << endl;
return 0;
}标签:ch,return,int,0x20,register,dfs,搜索 来源: https://www.cnblogs.com/Mark-X/p/11519097.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。