标签:aa abc 05 hadoop yarn Hadoop 集群 YARN nn1
先保证集群5台虚拟机,
| nn1 | nn2 | s1 | s2 | s3 | |
|---|---|---|---|---|---|
| hadoop | 是 | 是 | 是 | 是 | 是 |
| zookeeper | 是 | 是 | 是 | ||
| namenode | 是 | 是 | |||
| jouralnode | 是 | 是 | |||
| datanode | 是 | 是 | 是 |
1.然后启动yarn在nn1机器上:
[hadoop@nn1 hadoop]$ start-yarn.sh然后查看各节点信息
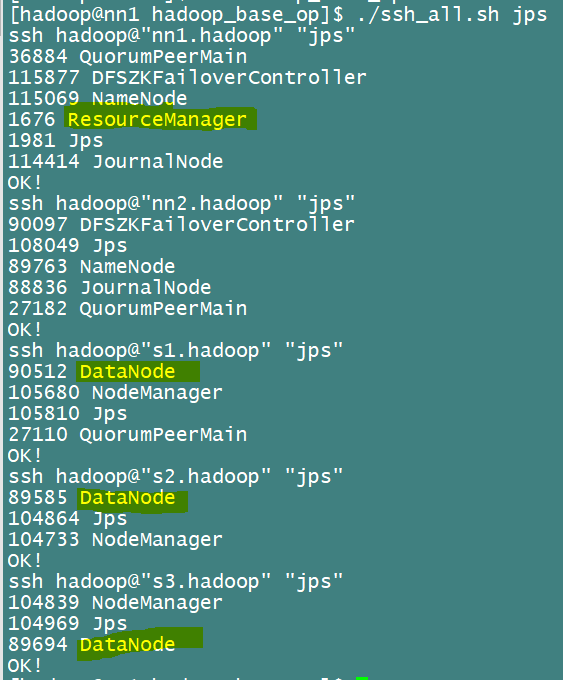
2.配置yarn的HA高可用
高可用就是好几台机器,一台突然挂掉了,其他机器就补上去,刚刚只启动了nn1作为yarn服务器,只有一台,所以这里要在nn2也开一台,来做简单的高可用
###############在nn2控制台操作####################
[hadoop@nn2 ~]$ yarn-daemon.sh start resourcemanager如图查看jps
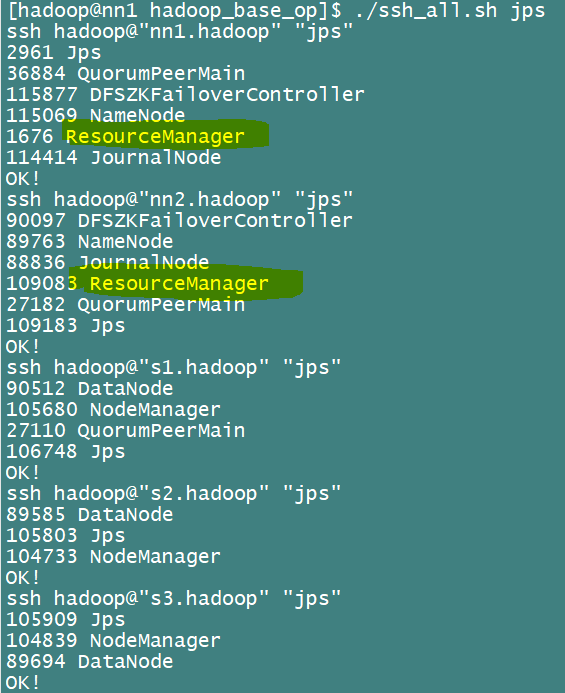
这里相比第一张图,在nn2多了一个resourceManager
##########查看状态############
[hadoop@nn1 hadoop_base_op]$ yarn rmadmin -getServiceState rm1
active
[hadoop@nn1 hadoop_base_op]$ yarn rmadmin -getServiceState rm2
standby打开网页查看http://192.168.10.6:8088/cluster
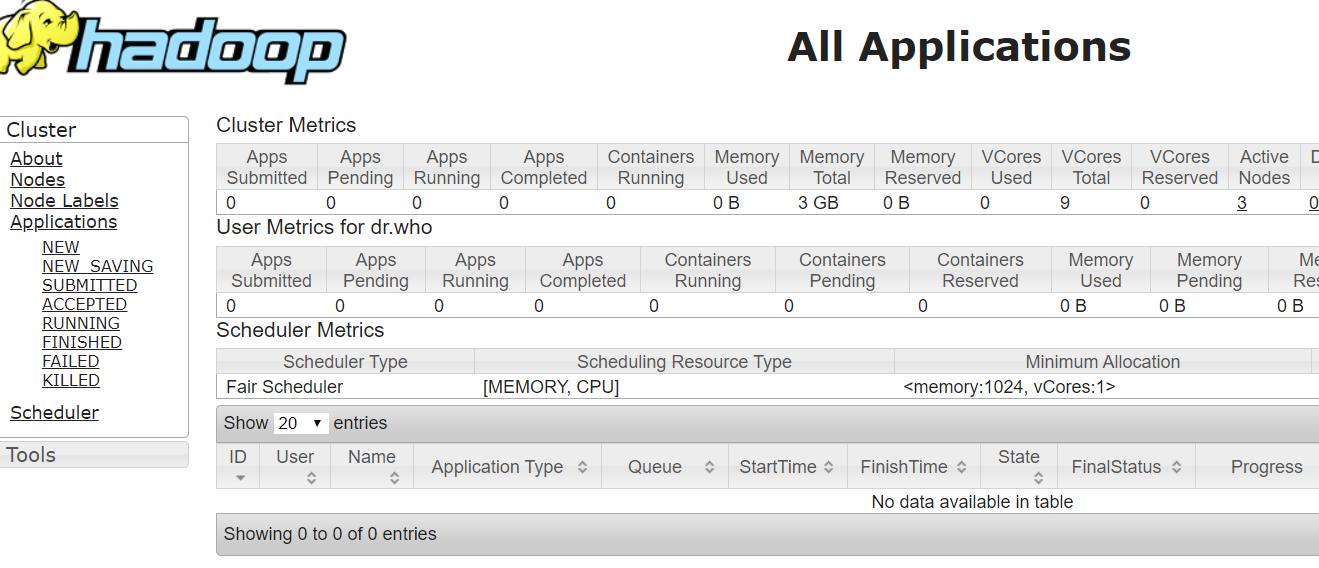
出现hadoop页面就是成功了,这时候因为nn1是active状态,所以你输入http://192.168.10.7:8088/cluster的话,或自动跳转到active机器,也就是自动跳转到nn1的ip上。
启动成功
来,跑个任务试试
用这个集群进行简单的wordcount任务
创建两个文件
vim abc1
aa bbb abc
aa aa
aa bb
aa cc aa
vim abc2
张三 张 三
张
三 张把这两个文件上传到hadoop的hdfs上
[hadoop@nn1 ~]$ hadoop fs -mkdir -p /user/hadoop/abc/input
[hadoop@nn1 ~]$ hadoop fs -put ./abc* /user/hadoop/abc/input查看网页端:
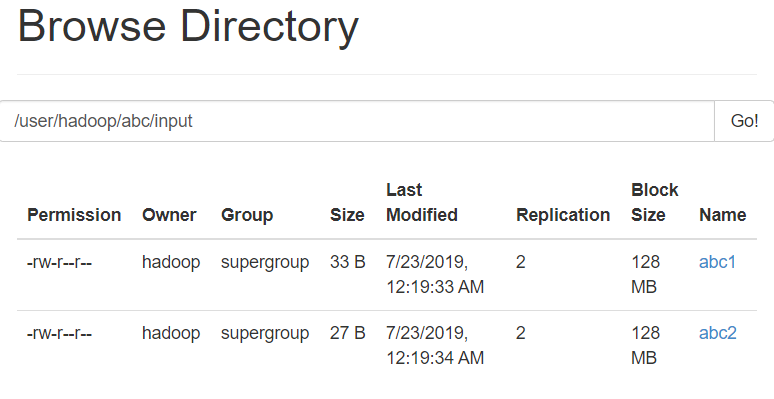
扔到MR里执行下
[hadoop@nn1 ~]$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /user/hadoop/abc/input /user/hadoop/abc/output
查看网页端的状态展示:
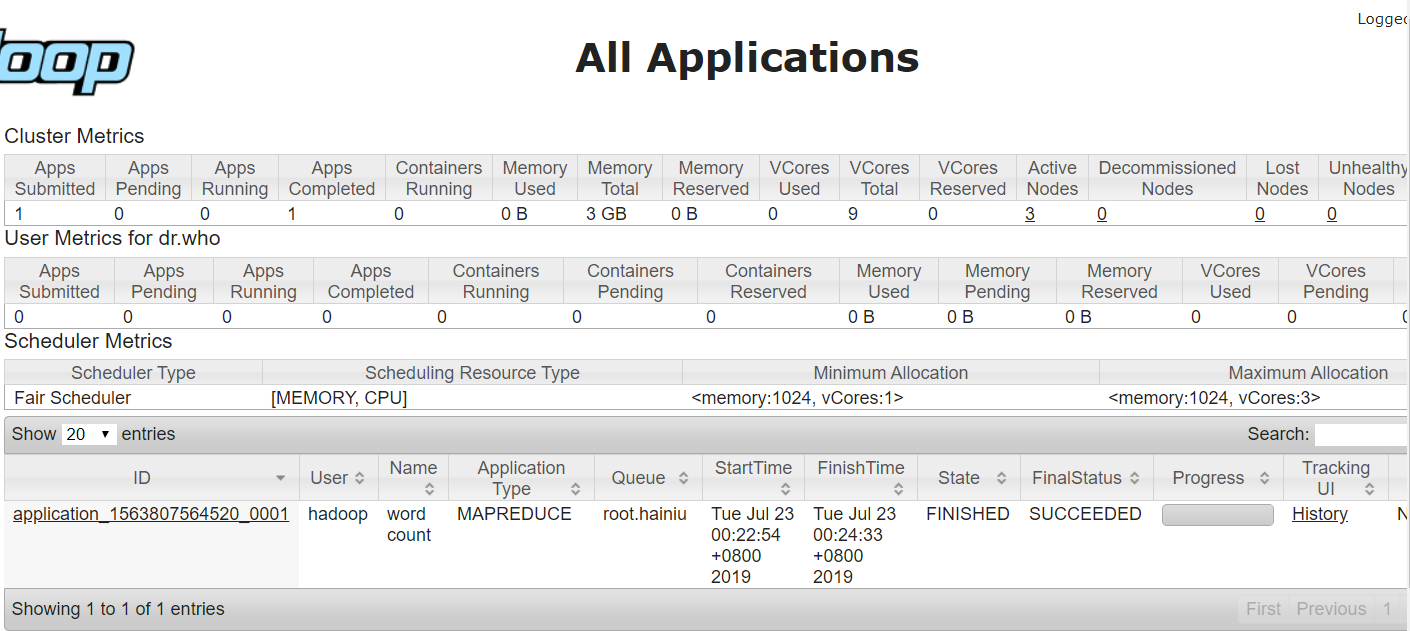
然后我们去hadoop那里查看结果文件
[hadoop@nn1 ~]$ hadoop fs -cat /user/hadoop/abc/output/part-r-00000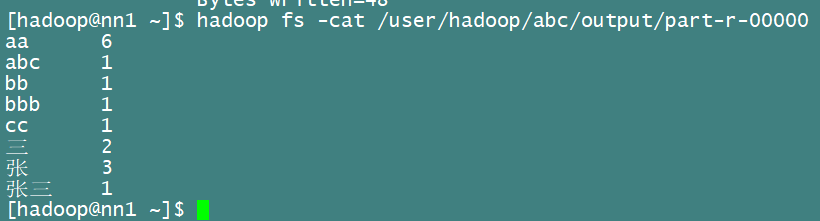
大功告成!!!
标签:aa,abc,05,hadoop,yarn,Hadoop,集群,YARN,nn1 来源: https://www.cnblogs.com/finch-xu/p/11239149.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。