使用大量组件架构快速启动您的 NLP 代码
典型的 NLP 预测管道从引入文本数据开始。来自不同来源的文本数据具有不同的特征,因此在对其应用任何模型之前需要进行一定量的预处理。
在本文中,我们将首先介绍预处理的原因,并在此过程中介绍不同类型的预处理。然后,我们将介绍各种文本清理和预处理技术以及python代码。出于教学目的,本文中提供的所有代码片段都按其相应的类别进行分组。由于库的特殊性,预处理步骤中存在固有的顺序依赖关系,因此请不要忘记参考本文中有关建议执行顺序的部分,以免遭受大量痛苦和错误。
虽然代码片段可以在Jupyter Notebook中执行和测试,但它们的全部好处是通过将它们重构为具有统一且定义良好的API的python类(或模块)来实现的,以便在类似生产的sklearn管道中易于使用和可重用性。本着这种精神,本文以一个 sklearn 转换器结束,其中包含本文中概述的所有文本预处理技术和管道调用的示例。
为什么要进行预处理?
NLP中的所有技术,从简洁的词袋到花哨的BERT,都需要一个共同点来表示文本——词向量。虽然BERT及其花哨的表亲不需要文本预处理,尤其是在使用预训练模型时(例如,它们依赖于词组算法或其变体,从而消除了词干和词形还原等的需要),但更简单的NLP模型极大地受益于文本预处理。
从词向量的角度来看,每个词都只是一个数字向量。因此,足球这个词与足球不同。踢,踢和踢完全不同。理论上,在非常大的语料库上进行训练可以为足球/足球以及踢/踢/踢生成类似的向量表示。但是我们可以立即大大缩短词汇量,因为我们知道这些不仅仅是从我们的角度来看相似的单词,而是相同的单词。类似地,助动词(in,was as as等)连词(和自)几乎出现在每个句子中,从NLP的角度来看,对句子没有任何意义。切掉这些将减少句子/文档的矢量尺寸。
文本预处理的类型
下图捕获了文本处理技术的长(但并非详尽)非正式列表。本文仅实现带有虚线边框的绿色框中的那些。其中一些不需要介绍,而其他一些(例如实体规范化、依赖关系解析)是高级的,并且本身包含某些词汇/ML 算法。
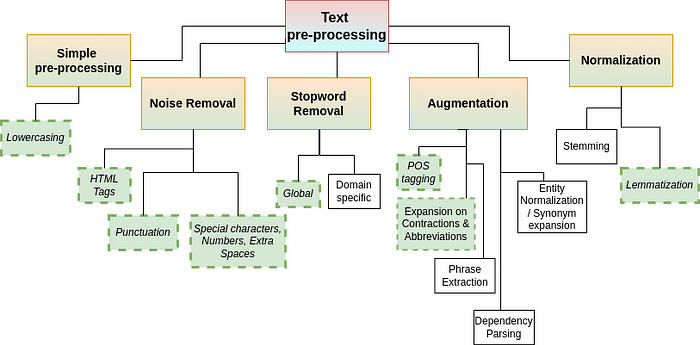 图1.文本预处理技术(图片来自作者)
图1.文本预处理技术(图片来自作者)
下面的表 1 总结了受这些预处理影响的变化。由于特定处理而导致的更改显示在“之前”和“之后”列中突出显示。“之后”列中没有突出显示,表示由于预处理,“之前”中突出显示的文本已被删除。
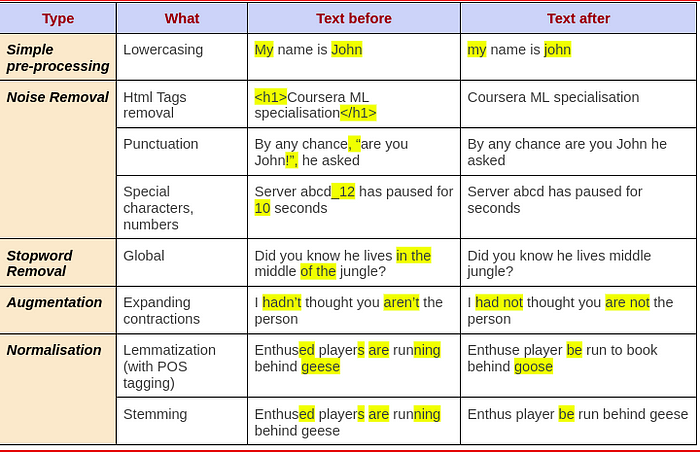 表 1.每种类型的文本预处理的影响
表 1.每种类型的文本预处理的影响
看到一切在行动
好了,理论够多了。让我们编写一些代码来让它做有用的事情。与其一次进行一类预处理,不如在实践中按顺序执行某些操作是最好的。例如,删除 html 标记(如果有)作为第一个预处理步骤,然后词形还原与小写相结合,然后进行其他清理
- 所需库
除了 numpy 和 pandas 之外,还应在 Python 3.5+ 上安装以下模块。
pip install nltk pip install beautifulsoup4 pip install contractions pip install Unidecode pip install textblob pip install pyspellchecker
2. 使用熊猫加载数据帧
import pandas as pddf = pd.read_csv(“…..”) text_col = df[“tweets”] #tweets is text column to pre-process
3. 下壳
text_col = text_col.apply(lambda x: x.lower())
4. 扩张宫缩
text_col = text_col.apply(
lambda x: " ".join([contractions.fix(expanded_word) for expanded_word in x.split()]))
5. 噪音消除
5.1 删除 html 标签
from bs4 import BeautifulSoup
text_col = text_col.apply(
lambda x: BeautifulSoup(x, 'html.parser').get_text())
5.2 删除数字
text_col = text_col.apply(lambda x: re.sub(r'\d+', '', x))
5.3 用空格替换点
有时文本包含 IP,此类句点应替换为空格。在这种情况下,请使用下面的代码。但是,如果需要将句子拆分为标记,请先将 nltk 标记化与 punkt 一起使用。它理解句号的出现并不总是意味着句子的结束(例如Mrs.夫人),因此会标记化。
标签:代码,python,ipython,影响,模块,数据 来源:
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。