标签:数仓 Redshift 视图 Amazon 流式 摄取 数据
Amazon Redshift 是一种快速、可扩展、安全且完全托管的云数据仓库,可以帮助用户通过标准 SQL 语言简单、经济地分析各类数据。相比其他任何云数据仓库,Amazon Redshift 可实现高达三倍的性能价格比。数万家客户正在借助 Amazon Redshift 每天处理 EB 级别的数据,借此为高性能商业智能(BI)报表、仪表板应用、数据探索和实时分析等分析工作负载提供强大动力。
我们很激动地为 Amazon Kinesis Data Streams 发布了 Amazon Redshift 流式摄取功能,借此用户无需事先将数据存储在 Amazon Simple Storage Service(Amazon S3)中,即可将 Kinesis 数据流摄取到云数据仓库中。流式摄取可以帮助用户以极低延迟,在几秒钟内将数百 MB 数据摄取到 Amazon Redshift 云数据仓库集群。
本文将介绍如何围绕 Amazon Redshift 云数据仓库创建 Kinesis 数据流,生成并加载流式数据,创建物化视图,并查询数据流并对结果进行可视化呈现。此外本文还讲介绍流式摄取的好处和常见用例。
云数据仓库有关流式摄取的需求
很多客户向我们反馈称想要将批处理分析能力进一步拓展为实时分析能力,并以低延迟高吞吐量的方式访问自己存储在数据仓库中的流式数据。此外,还有很多客户希望将实时分析结果与数据仓库中的其他数据源相结合,借此获得更丰富的分析结果。
Amazon Redshift 流式摄取的主要用例均具备这样的特征:用于处理不断生成的(流式)数据,并且需要在数据生成后很短的时间(延迟)里处理完成。从IoT设备到系统遥测,从公共事业服务到设备定位,数据来源五花八门。
在流式摄取功能发布前,如果希望从 Kinesis Data Steams 摄取实时数据,需要将数据暂存至 Amazon S3,然后使用 COPY 命令加载。这通常会产生数分钟的延迟,并且需要在从数据流加载数据的操作之上建立数据管道。但现在,用户已经可以直接从数据流摄取数据。
解决方案概述
Amazon Redshift 流式摄取可让用户直接连接到 Kinesis Data Streams,彻底消除了通过 Amazon S3 暂存数据并载入集群所导致的延迟和复杂性。借此,用户可以使用 SQL 命令连接并访问流式数据,并直接在数据流的基础上创建具体化试图,借此简化数据管道。物化视图亦可包含 ELT(提取、加载和转换)管道所需的 SQL 转换。
定义了物化视图后,即可刷新视图以查询最新流式数据。这意味着我们可以使用 SQL 对流式数据执行下游处理和转换,并且无需付出额外成本,随后即可使用原有的 BI 和分析工具进行实时分析。
Amazon Redshift 流式摄取会作为数据流的使用者来完成自己的工作,物化视图则可看作所要使用的流式数据的登陆区。刷新物化视图时,Amazon Redshift 计算节点会将每个数据分片分配给一个计算切片。每个计算切片会开始处理所分配数据分片中的数据,直到物化视图达到与数据流对等的程度。物化视图的第一次刷新可从数据流的 TRIM_HORIZON 中获取数据,后续刷新则可从上一次刷新所产生的最后一个 SEQUENCE_NUMBER 中读取数据,直到其状态与流式数据实现对等。整个流程如下图所示。
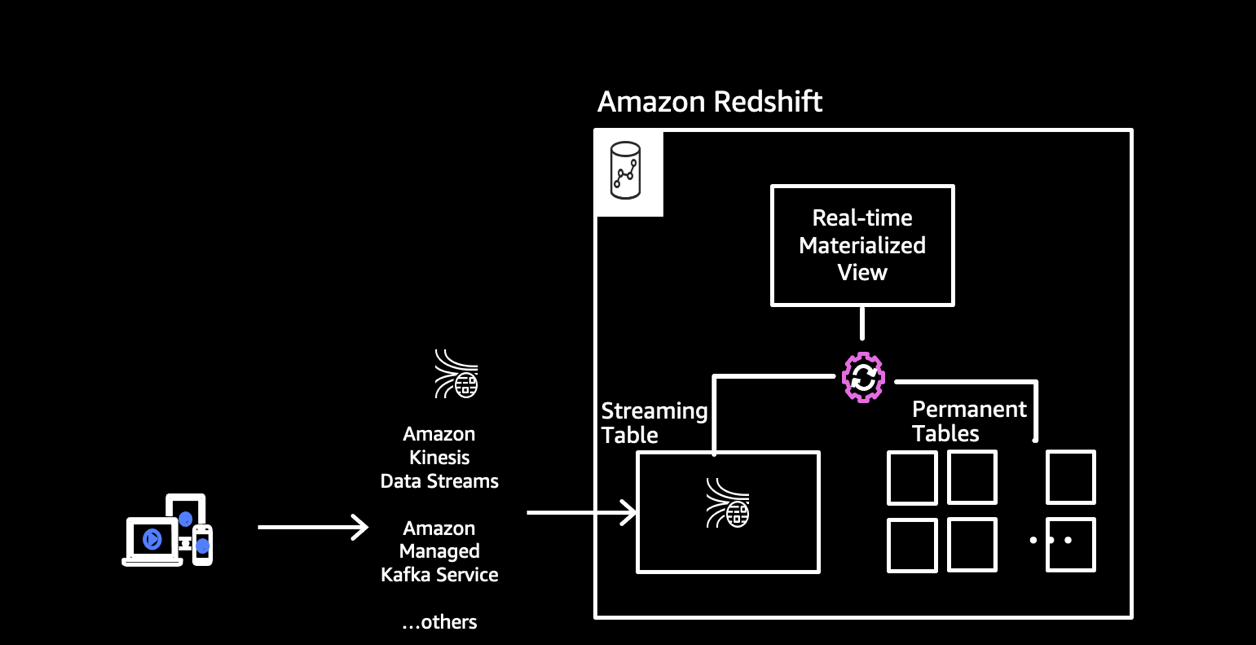
在 Amazon Redshift 中设置流式摄取需要执行两个步骤。首先,我们需要创建一个外部 Schema 以映射至 Kinesis Data Streams,随后需要创建一个物化视图以便从数据流中拉取数据。物化视图必须能够增量维护。
创建 Kinesis 数据流
首先我们需要创建接收流式数据的 Kinesis 数据流。
-
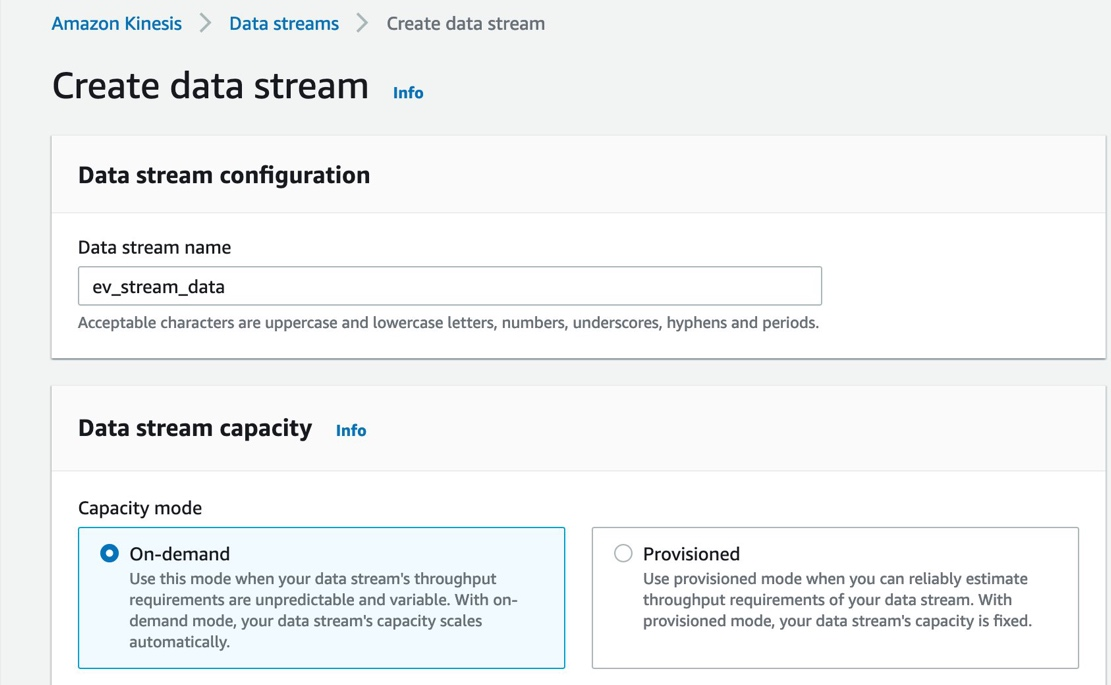
在 Amazon Kinesis 控制台中选择 Data streams。
-
选择 Create data stream。
-
为 Data stream name 输入
ev_stream_data。 -
为 Capacity mode 选择 On-demand。
-
按需提供其他配置以创建数据流。
使用 Kinesis Data Generator 生成流式数据
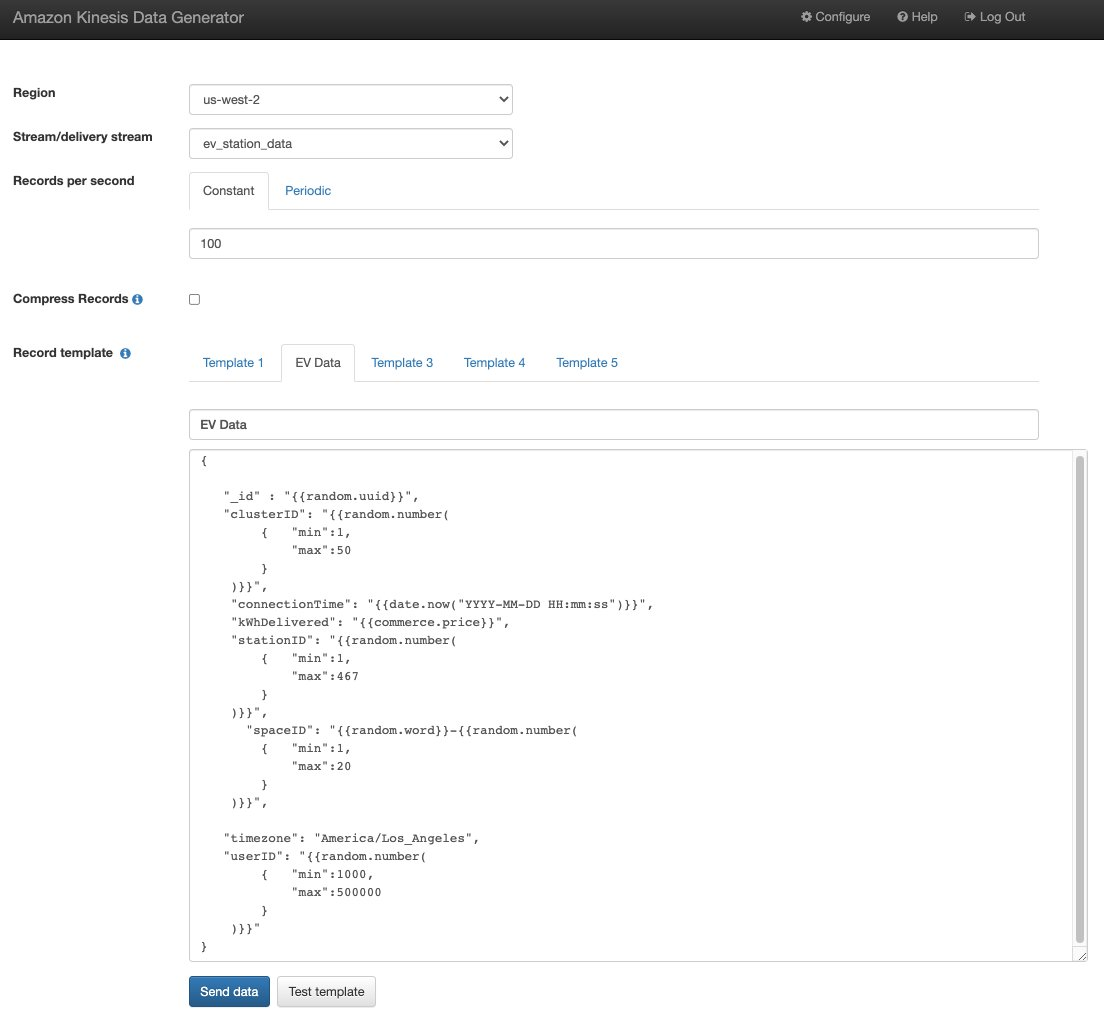
我们可以使用 Amazon Kinesis Data Generator(KDG)工具和下列模板,以聚合的方式生成 JSON 格式的数据:
{
"_id" : "{{random.uuid}}",
"clusterID": "{{random.number(
{ "min":1,
"max":50
}
)}}",
"connectionTime": "{{date.now("YYYY-MM-DD HH:mm:ss")}}",
"kWhDelivered": "{{commerce.price}}",
"stationID": "{{random.number(
{ "min":1,
"max":467
}
)}}",
"spaceID": "{{random.word}}-{{random.number(
{ "min":1,
"max":20
}
)}}",
"timezone": "America/Los_Angeles",
"userID": "{{random.number(
{ "min":1000,
"max":500000
}
)}}"
}下图展示了 KDG 控制台中的模板。
加载参考数据
上一个步骤中,我们介绍了如何使用 Kinesis Data Generator 将聚合数据载入数据流。本节我们需要将与电动汽车充电站相关的参考数据载入到集群。
请从奥斯丁市开放数据门户下载插电式电动汽车充电站网络数据。将数据集中的经纬度数据拆分开,并将其载入到具备如下 Schema 的表中:
CREATE TABLE ev_station
(
siteid INTEGER,
station_name VARCHAR(100),
address_1 VARCHAR(100),
address_2 VARCHAR(100),
city VARCHAR(100),
state VARCHAR(100),
postal_code VARCHAR(100),
no_of_ports SMALLINT,
pricing_policy VARCHAR(100),
usage_access VARCHAR(100),
category VARCHAR(100),
subcategory VARCHAR(100),
port_1_connector_type VARCHAR(100),
voltage VARCHAR(100),
port_2_connector_type VARCHAR(100),
latitude DECIMAL(10, 6),
longitude DECIMAL(10, 6),
pricing VARCHAR(100),
power_select VARCHAR(100)
) DISTTYLE ALL创建物化视图
我们可以使用 SQL 从数据流中访问自己的数据,并直接在数据流的基础上创建物化视图,借此简化数据管道的搭建。为此请执行如下操作:
-
创建一个外部 Schema,以便将数据从 Kinesis Data Streams 映射至 Amazon Redshift 对象:
CREATE EXTERNAL SCHEMA evdata FROM KINESIS
IAM_ROLE 'arn:aws:iam::0123456789:role/redshift-streaming-role';-
创建一个 Amazon Identity and Access Management(IAM)角色(相关策略请参考流式摄取上手指南)。
随后即可创建用于使用流式数据的物化视图。我们可以选择使用 SUPER 数据类型来存储 JSON 格式的有效载荷,或使用 Amazon Redshift JSON 函数将JSON数据解析为单独的列。本文我们将使用第二种方法,因为 Schema 已经定义好了。
-
创建物化视图,使其根据数据流中的 UUID 值进行分布,并按
approximatearrivaltimestamp值排序:
CREATE MATERIALIZED VIEW ev_station_data_extract DISTKEY(5) sortkey(1) AS
SELECT approximatearrivaltimestamp,
partitionkey,
shardid,
sequencenumber,
json_extract_path_text(from_varbyte(data, 'utf-8'),'_id')::character(36) as ID,
json_extract_path_text(from_varbyte(data, 'utf-8'),'clusterID')::varchar(30) as clusterID,
json_extract_path_text(from_varbyte(data, 'utf-8'),'connectionTime')::varchar(20) as connectionTime,
json_extract_path_text(from_varbyte(data, 'utf-8'),'kWhDelivered')::DECIMAL(10,2) as kWhDelivered,
json_extract_path_text(from_varbyte(data, 'utf-8'),'stationID')::DECIMAL(10,2) as stationID,
json_extract_path_text(from_varbyte(data, 'utf-8'),'spaceID')::varchar(100) as spaceID,
json_extract_path_text(from_varbyte(data, 'utf-8'),'timezone')::varchar(30) as timezone,
json_extract_path_text(from_varbyte(data, 'utf-8'),'userID')::varchar(30) as userID
FROM evdata."ev_stream_data";-
刷新这个物化视图:
REFRESH MATERIALIZED VIEW ev_station_data_extract;目前的预览版中,物化视图不会自动刷新,因此我们需要在 Amazon Redshift 中计划一个查询,每分钟刷新一次物化视图。相关说明请参考在 Amazon Redshift 数据仓库中计划 SQL 查询。
查询数据流
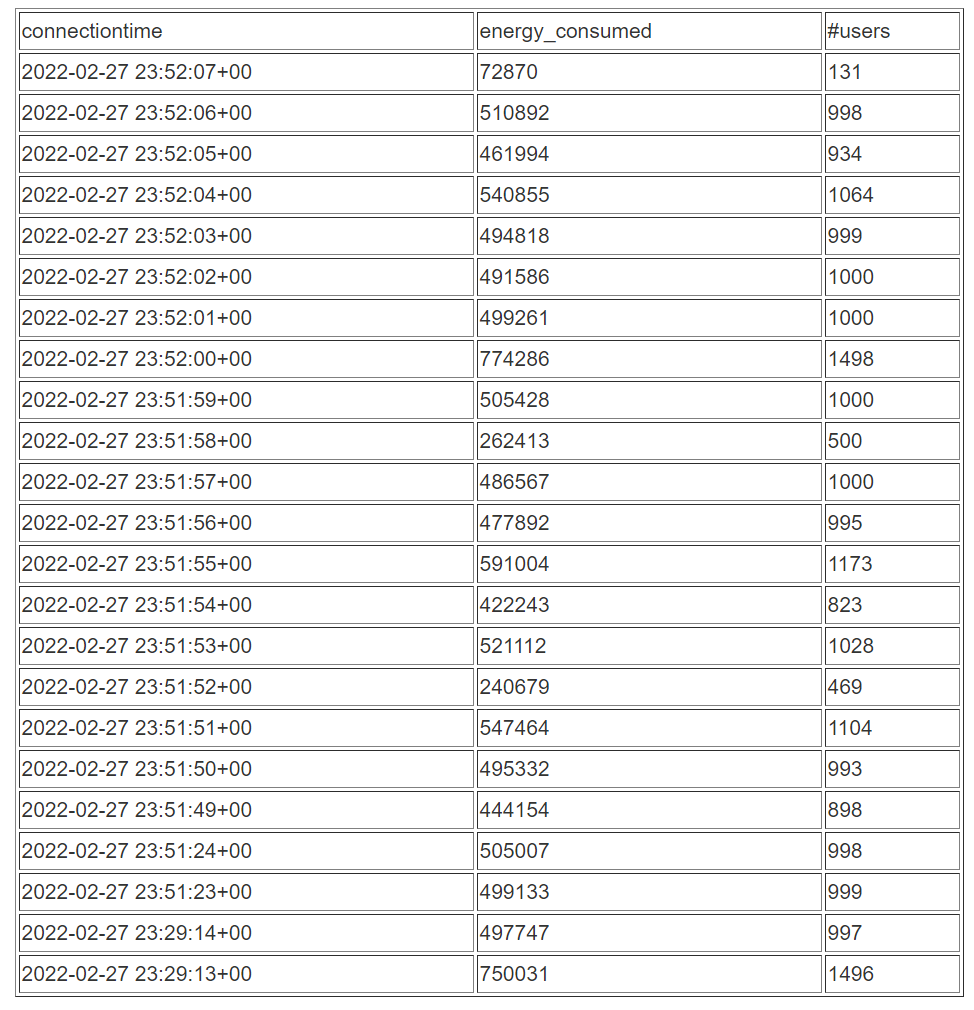
随后即可查询刷新后的物化视图以查看使用情况统计数据:
SELECT to_timestamp(connectionTime, 'YYYY-MM-DD HH24:MI:SS') as connectiontime
,SUM(kWhDelivered) AS Energy_Consumed
,count(distinct userID) AS #Users
from ev_station_data_extract
group by to_timestamp(connectionTime, 'YYYY-MM-DD HH24:MI:SS')
order by 1 desc;结果如下表所示。
接下来,我们可以将物化视图与参考数据联接起来,进而分析过去5分钟里充电站的使用量数据,并按照充电站的类型进行细分:
SELECT to_timestamp(connectionTime, 'YYYY-MM-DD HH24:MI:SS') as connectiontime
,SUM(kWhDelivered) AS Energy_Consumed
,count(distinct userID) AS #Users
,st.category
from ev_station_data_extract ext
join ev_station st on
ext.stationID = st.siteid
where approximatearrivaltimestamp > current_timestamp -interval '5 minutes'
group by to_timestamp(connectionTime, 'YYYY-MM-DD HH24:MI:SS'),st.category
order by 1 desc, 2 desc结果如下表所示。
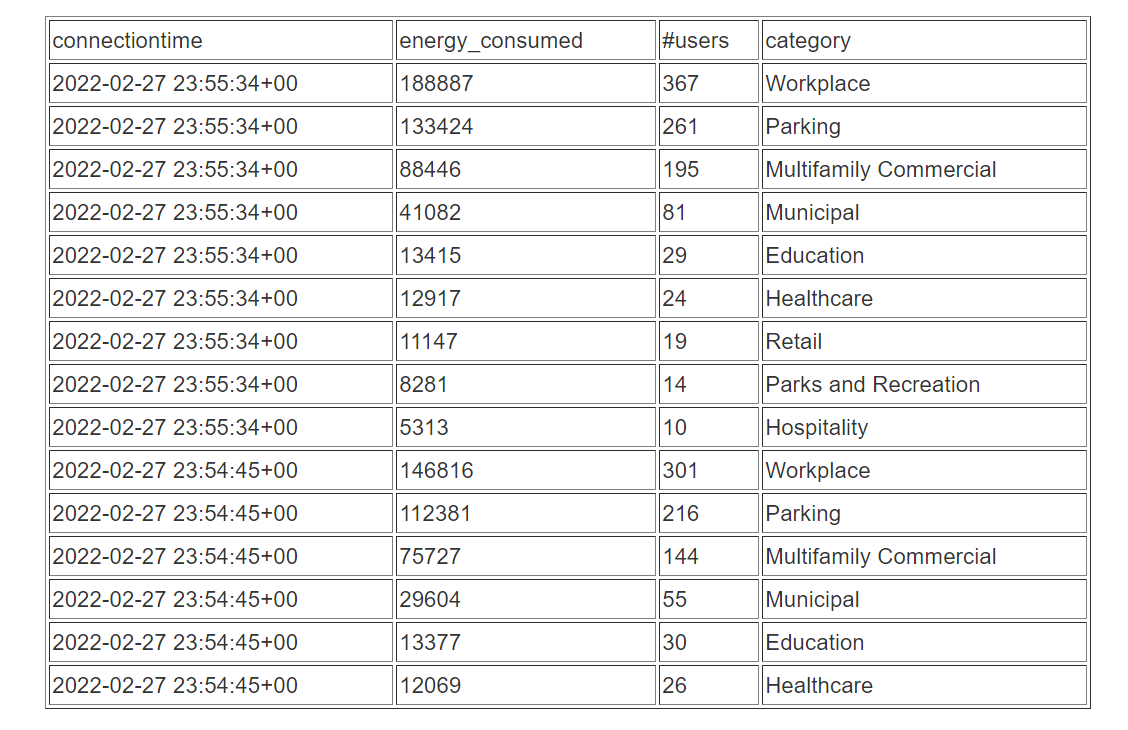
结果的可视化呈现
我们可以使用 Amazon QuickSight 设置一个简单的可视化呈现。相关说明请参考快速上手指南:使用样本数据创建一个具备单一可视化结果的 Amazon QuickSight 分析。
我们在 QuickSight 中创建了一个数据集,借此将物化视图与充电站参考数据联接在一起。

随后创建一个可以显示耗电量以及连接用户随时间变化的仪表板。该仪表板还会按照类别在地图上显示对应的地点。
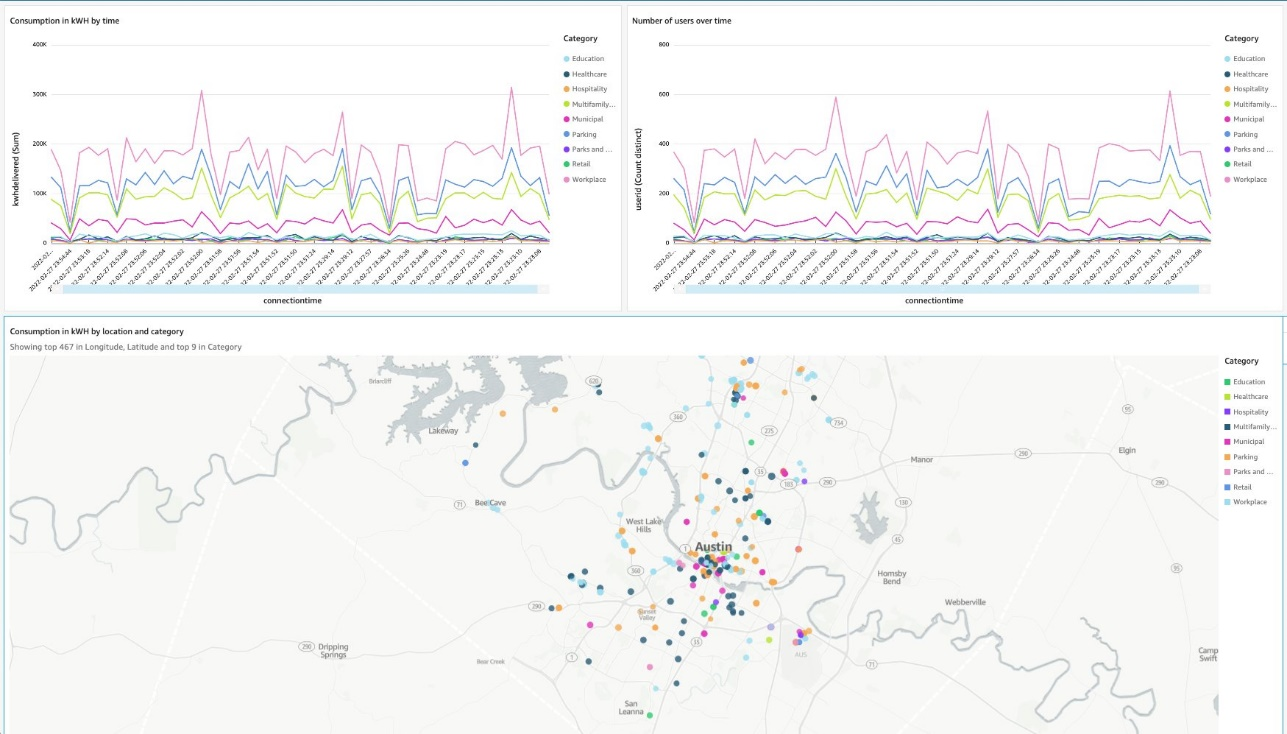
流式摄取所带来的好处
本节我们将介绍流式摄取所能带来的一些好处。
高吞吐量低延迟
Amazon Redshift 能以每秒数 GB 的速度接收并处理来自 Kinesis Data Streams 的数据(吞吐量取决于数据流中数据分片的数量以及 Amazon Redshift 集群配置)。借此我们将能以低延迟高带宽的方式使用流式数据,进而在几秒钟之内从数据中获得见解,不再像以往那样等待数分钟。
如上文所述,Amazon Redshift 直接摄取并拉取的方法最大的优势在于延迟更低,通常只需数秒。这与创建流程以使用流式数据,将数据暂存到 Amazon S3,随后运行 COPY 命令将数据载入 Amazon Redshift 的做法形成了鲜明的对比。由于数据处理过程涉及多个环节,后一种方法往往会产生数分钟的延迟。
设置简单
流式摄取方法可以轻松上手。Amazon Redshift 中的所有设置与配置均可使用 SQL 完成,绝大部分云数据仓库的用户对此已经非常熟悉了。随后,无需管理复杂的管道,即可在几秒钟内获得实时见解。Amazon Redshift 和 Kinesis Data Streams 是完全托管的,用户无需管理基础结构即可运行自己的流式应用程序。
提高生产力
用户无需学习新的技能或语言,即可在 Amazon Redshift 中使用熟悉的 SQL 技能针对流失数据进行丰富的分析工作。此外还可以创建其他物化视图,或针对物化视图创建视图,借此直接在 Amazon Redshift 中使用 SQL 完成大部分ELT数据管道转换工作。
流式摄取用例
通过对流式数据进行近乎实时的分析,很多用例和垂直行业特定应用将变为可能。下文列举的仅仅是诸多用例中的一部分:
-
改善游戏体验:通过分析来自玩家的实时数据,即可专注于游戏转化率、玩家留存率并优化游戏体验。
-
分析在线广告的点击流用户数据:每个客户在一次会话中平均会访问几十个网站,然而营销人员通常只能分析自己网站的访问数据。我们可以分析数据仓库中摄入的已授权点击流数据,借此评估客户的足迹和行为,并即时为客户投放更有针对性的广告。
-
通过流式 POS 数据进行实时零售分析:我们可以访问并可视化所有全球销售点(POS)零售交易数据,借此进行实时分析、报表并可视化。
-
提供实时的应用程序洞察力:通过访问并分析来自应用程序日志文件和网络日志的流式数据,开发者和工程师可以围绕问题进行实时排错,打造更优质的产品,并通过警报提醒采取预防性措施。
-
实时分析 IoT 数据:我们可以将 Amazon Redshift 流式摄取与 Amazon Kinesis 服务配合使用来构建实时应用程序,例如设备状态和属性检测,如位置和传感器数据、应用程序监控、欺诈检测、实时仪表板等。我们可以使用 Kinesis Data Streams 摄取流式数据,使用 Amazon Kinesis Data Analytics 进行处理,随后使用 Kinesis Data Streams 以极低的端到端延迟将结果发送给任何数据存储或应用程序。
总结
本文介绍了如何创建 Amazon Redshift 物化视图,进而使用 Amazon Redshift 流式摄取功能从 Kinesis 数据流摄取数据。借助这个全新功能,我们可以轻松构建并维护数据管道,借此以低延迟、高吞吐量的方式摄取并分析流式数据。
流式摄取功能目前为预览版,所有提供了 Amazon Redshift 服务的亚马逊云科技区域均已可以使用该功能。若要上手使用 Amazon Redshift 流式摄取,请在您的当前栈上预配一个 Amazon Redshift 集群,并确认您的集群版本不低于1.0.35480。
详细信息请参考流式摄取(预览),此外也可查看 YouTube 上的使用 Amazon Redshift 流式摄取进行实时分析演示。
本篇作者
Sam Selvan
亚马逊云科技资深解决方案架构师。
标签:数仓,Redshift,视图,Amazon,流式,摄取,数据 来源: https://www.cnblogs.com/AmazonwebService/p/16695345.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。