标签:架构 py 中间件 爬虫 scrapy EGINE 安装 下载
scrapy架构介绍
# 框架---》架构
# 1 spiders:爬虫(咱们的代码)
# 2 engin :引擎(大总管)
# 3 scheduler:调度器(排队,谁先爬谁后爬,去重)
# 4 downloader:下载器(真正的负责发送http请求,获取数据,性能很高,基于twisted,性能很高的网络框架)
# 5 piplines:管道(保存数据)
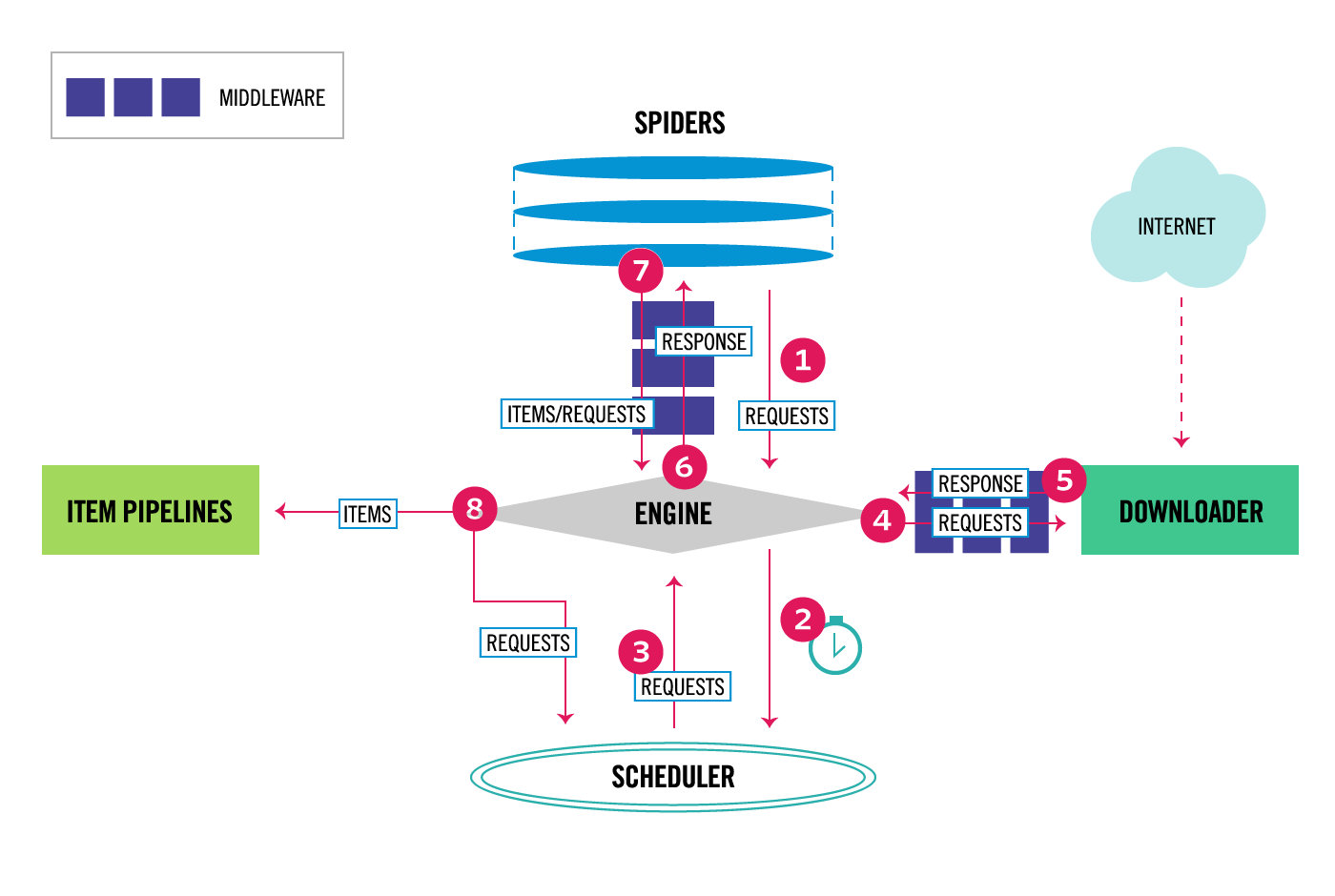
# 引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。
# 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
# 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
# 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,
# 爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
7 scrapy目录介绍,scrapy项目创建,爬虫创建,启动爬虫
# scrapy是爬虫界的django
# 1 创建scrapy项目 ---》对比django
scrapy startproject myfirstscrapy
# 2 创建爬虫----》对比django创建app
scrapy genspider cnblogs cnblogs.com
# 目录介绍
firstscrapy # 项目名
firstscrapy # 文件夹
spiders # 文件夹,一个个的爬虫
cnblogs.py # 其中一个爬虫,重点写代码的地方(解析数据,发起请求)*****
items.py # 类比djagno的models,表模型--》类 ***
middlewares.py # 中间件:爬虫中间件和下载中间件都在里面 ***
pipelines.py # 管道,做持久化需要在这写代码 ***
settings.py # 配置文件 **
scrapy.cfg # 上线配置,开发阶段不用
# 启动爬虫,爬取数据
scrapy crawl 爬虫名字 --nolog
# 或者在项目路径下新建main.py--->右键运行
from scrapy.cmdline import execute
execute(['scrapy','crawl','cnblogs','--nolog'])
标签:架构,py,中间件,爬虫,scrapy,EGINE,安装,下载 来源: https://www.cnblogs.com/zhengkaijian/p/16548519.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。