作者:小林coding
计算机八股文网站:https://xiaolincoding.com
大家好,我是小林。
今天跟大家聊聊,常见的缓存更新策略。
- Cache Aside(旁路缓存)策略;
- Read/Write Through(读穿 / 写穿)策略;
- Write Back(写回)策略;
实际开发中,Redis 和 MySQL 的更新策略用的是 Cache Aside,另外两种策略主要应用在计算机系统里。
Cache Aside(旁路缓存)策略
Cache Aside(旁路缓存)策略是最常用的,应用程序直接与「数据库、缓存」交互,并负责对缓存的维护,该策略又可以细分为「读策略」和「写策略」。

写策略的步骤:
- 先更新数据库中的数据,再删除缓存中的数据。
读策略的步骤:
- 如果读取的数据命中了缓存,则直接返回数据;
- 如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
注意,写策略的步骤的顺序顺序不能倒过来,即不能先删除缓存再更新数据库,原因是在「读+写」并发的时候,会出现缓存和数据库的数据不一致性的问题。
举个例子,假设某个用户的年龄是 20,请求 A 要更新用户年龄为 21,所以它会删除缓存中的内容。这时,另一个请求 B 要读取这个用户的年龄,它查询缓存发现未命中后,会从数据库中读取到年龄为 20,并且写入到缓存中,然后请求 A 继续更改数据库,将用户的年龄更新为 21。

最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库的数据不一致。
为什么「先更新数据库再删除缓存」不会有数据不一致的问题?
继续用「读 + 写」请求的并发的场景来分析。
假如某个用户数据在缓存中不存在,请求 A 读取数据时从数据库中查询到年龄为 20,在未写入缓存中时另一个请求 B 更新数据。它更新数据库中的年龄为 21,并且清空缓存。这时请求 A 把从数据库中读到的年龄为 20 的数据写入到缓存中。

最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库数据不一致。 从上面的理论上分析,先更新数据库,再删除缓存也是会出现数据不一致性的问题,但是在实际中,这个问题出现的概率并不高。
因为缓存的写入通常要远远快于数据库的写入,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。而一旦请求 A 早于请求 B 删除缓存之前更新了缓存,那么接下来的请求就会因为缓存不命中而从数据库中重新读取数据,所以不会出现这种不一致的情况。
Cache Aside 策略适合读多写少的场景,不适合写多的场景,因为当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
- 另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快过期,对业务的影响也是可以接受。
Read/Write Through(读穿 / 写穿)策略
Read/Write Through(读穿 / 写穿)策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。
Read Through 策略
先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用。
Write Through 策略
当有数据更新的时候,先查询要写入的数据在缓存中是否已经存在:
- 如果缓存中数据已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,然后缓存组件告知应用程序更新完成。
- 如果缓存中数据不存在,直接更新数据库,然后返回;
下面是 Read Through/Write Through 策略的示意图:
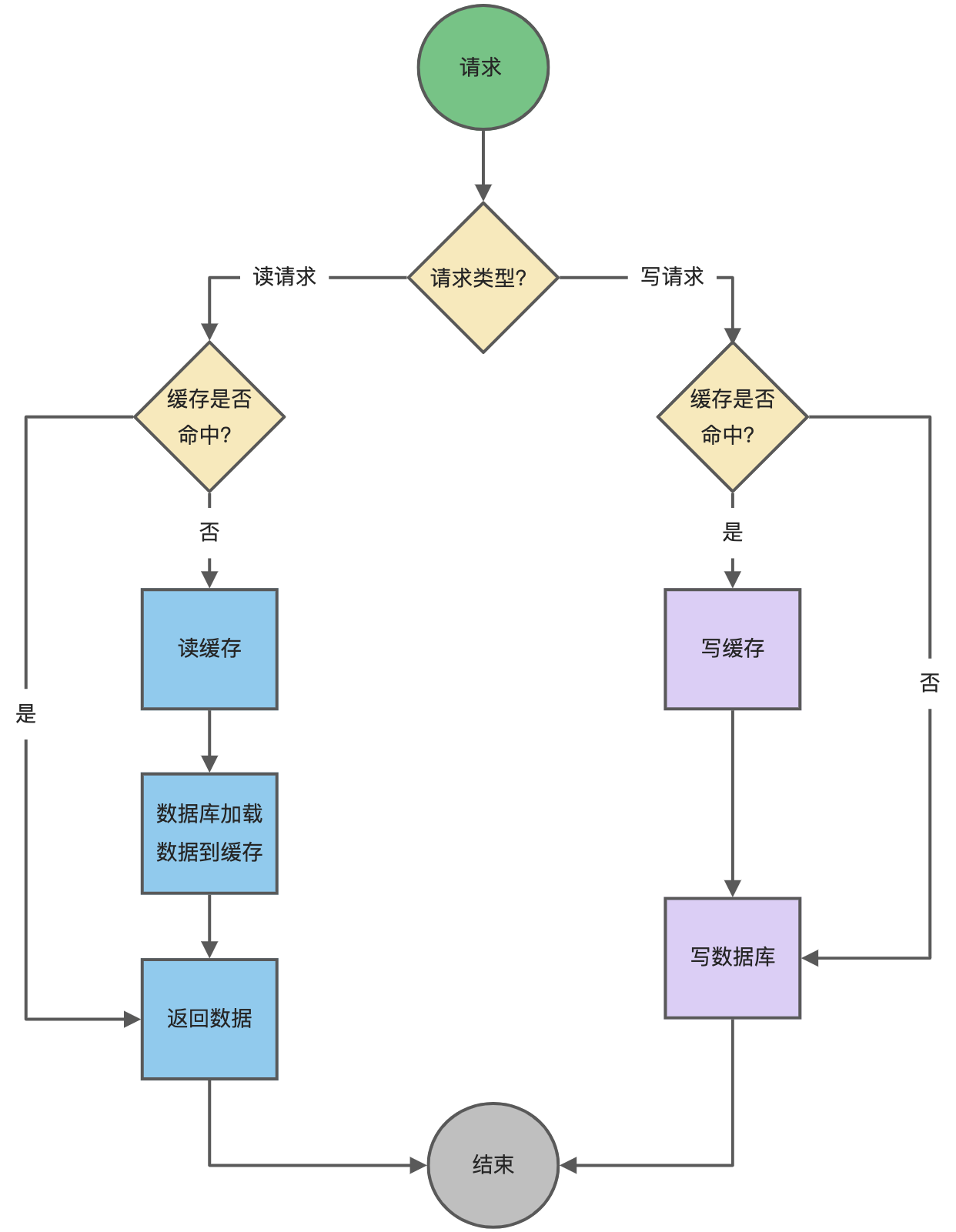
Read Through/Write Through 策略的特点是由缓存节点而非应用程序来和数据库打交道,在我们开发过程中相比 Cache Aside 策略要少见一些,原因是我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库和自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略。
Write Back(写回)策略
Write Back(写回)策略在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行。
实际上,Write Back(写回)策略也不能应用到我们常用的数据库和缓存的场景中,因为 Redis 并没有异步更新数据库的功能。
Write Back 是计算机体系结构中的设计,比如 CPU 的缓存、操作系统中文件系统的缓存都采用了 Write Back(写回)策略。
Write Back 策略特别适合写多的场景,因为发生写操作的时候, 只需要更新缓存,就立马返回了。比如,写文件的时候,实际上是写入到文件系统的缓存就返回了,并不会写磁盘。
但是带来的问题是,数据不是强一致性的,而且会有数据丢失的风险,因为缓存一般使用内存,而内存是非持久化的,所以一旦缓存机器掉电,就会造成原本缓存中的脏数据丢失。所以你会发现系统在掉电之后,之前写入的文件会有部分丢失,就是因为 Page Cache 还没有来得及刷盘造成的。
这里贴一张 CPU 缓存与内存使用 Write Back 策略的流程图:
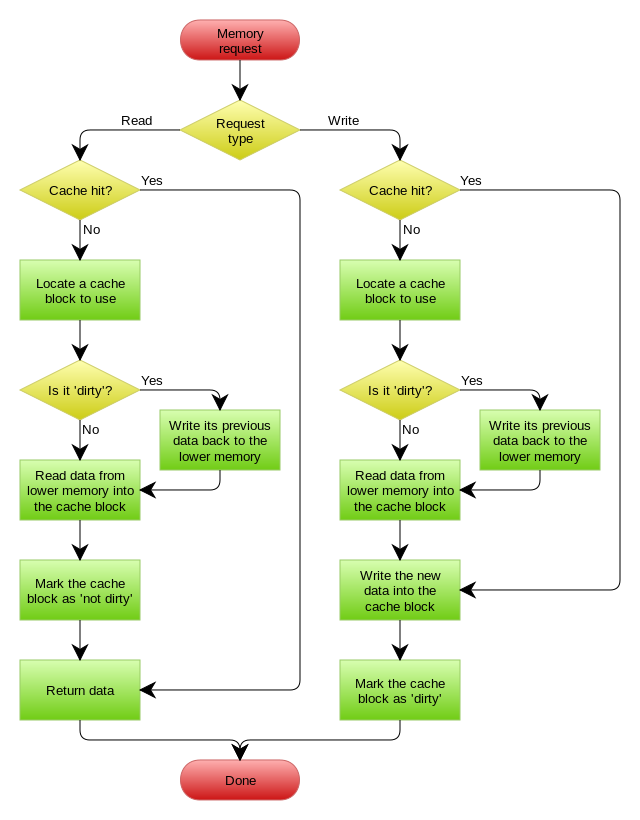
有没有觉得这个流程很熟悉?因为我在写 CPU 缓存文章的时候提到过。
系列《图解Redis》文章
面试篇:
数据类型篇:
持久化篇:
功能篇:
高可用篇:
缓存篇:
标签:面试官,缓存,策略,数据库,更新,Write,数据 来源: https://www.cnblogs.com/xiaolincoding/p/16493675.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。