标签:DistributedDataParallel args 训练 torch rank Pytorch GPU local 分布式
用单机单卡训练模型的时代已经过去,单机多卡已经成为主流配置。如何最大化发挥多卡的作用呢?本文介绍Pytorch中的DistributedDataParallel方法。
1. DataParallel
其实Pytorch早就有数据并行的工具DataParallel,它是通过单进程多线程的方式实现数据并行的。
简单来说,DataParallel有一个参数服务器的概念,参数服务器所在线程会接受其他线程传回来的梯度与参数,整合后进行参数更新,再将更新后的参数发回给其他线程,这里有一个单对多的双向传输。因为Python语言有GIL限制,所以这种方式并不高效,比方说实际上4卡可能只有2~3倍的提速。
2. DistributedDataParallel
Pytorch目前提供了更加高效的实现,也就是DistributedDataParallel。从命名上比DataParallel多了一个分布式的概念。首先 DistributedDataParallel是能够实现多机多卡训练的,但考虑到大部分的用户并没有多机多卡的环境,本篇博文主要介绍单机多卡的用法。
从原理上来说,DistributedDataParallel采用了多进程,避免了python多线程的效率低问题。一般来说,每个GPU都运行在一个单独的进程内,每个进程会独立计算梯度。
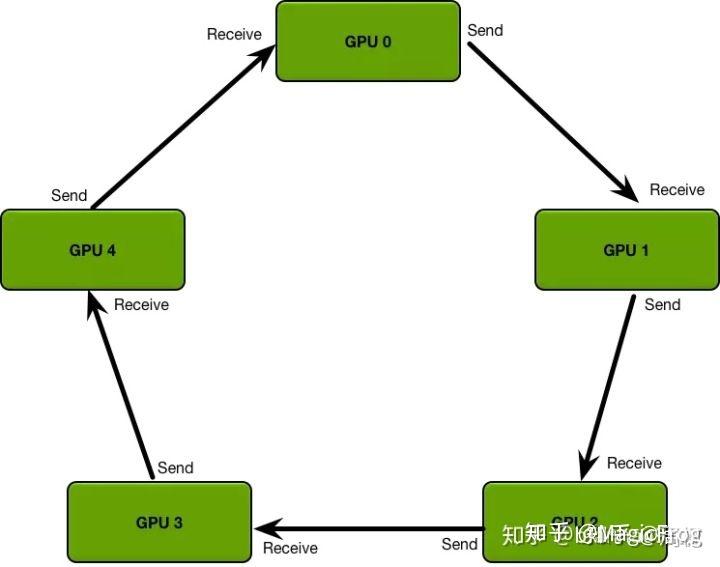
同时DistributedDataParallel抛弃了参数服务器中一对多的传输与同步问题,而是采用了环形的梯度传递,这里引用知乎上的图例。这种环形同步使得每个GPU只需要和自己上下游的GPU进行进程间的梯度传递,避免了参数服务器一对多时可能出现的信息阻塞。
3. DistributedDataParallel示例
下面给出一个非常精简的单机多卡示例,分为六步实现单机多卡训练。
第一步,首先导入相关的包。
import argparse
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
第二步,加一个参数,local_rank。这比较好理解,相当于就是告知当前的程序跑在那一块GPU上,也就是下面的第三行代码。local_rank是通过pytorch的一个启动脚本传过来的,后面将说明这个脚本是啥。最后一句是指定通信方式,这个选nccl就行。
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1, type=int)
args = parser.parse_args()
torch.cuda.set_device(args.local_rank)
dist.init_process_group(backend='nccl')
第三步,包装Dataloader。这里需要的是将sampler改为DistributedSampler,然后赋给DataLoader里面的sampler。
为什么需要这样做呢?因为每个GPU,或者说每个进程都会从DataLoader里面取数据,指定DistributedSampler能够让每个GPU取到不重叠的数据。
读者可能会比较好奇,在下面指定了batch_size为24,这是说每个GPU都会被分到24个数据,还是所有GPU平分这24条数据呢?答案是,每个GPU在每个iter时都会得到24条数据,如果你是4卡,一个iter中总共会处理24*4=96条数据。
train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)
trainloader = torch.utils.data.DataLoader(my_trainset,batch_size=24,num_workers=4,sampler=train_sampler)
第四步,使用DDP包装模型。device_id仍然是args.local_rank。
model = DDP(model, device_ids=[args.local_rank])
第五步,将输入数据放到指定GPU。后面的前后向传播和以前相同。
for imgs,labels in trainloader:
imgs=imgs.to(args.local_rank)
labels=labels.to(args.local_rank)
optimizer.zero_grad()
output=net(imgs)
loss_data=loss(output,labels)
loss_data.backward()
optimizer.step()
第六步,启动训练。torch.distributed.launch就是启动脚本,nproc_per_node是GPU数。
python -m torch.distributed.launch --nproc_per_node 2 main.py
通过以上六步,我们就让模型跑在了单机多卡上。是不是也没有那么麻烦,但确实要比DataParallel复杂一些,考虑到加速效果,不妨试一试。
4. DistributedDataParallel注意点
DistributedDataParallel是多进程方式执行的,那么有些操作就需要小心了。如果你在代码中写了一行print,并使用4卡训练,那么你将会在控制台看到四行print。我们只希望看到一行,那该怎么做呢?
像下面一样加一个判断即可,这里的get_rank()得到的是进程的标识,所以输出操作只会在进程0中执行。
if dist.get_rank() == 0:
print("hah")
你会经常需要dist.get_rank()的。因为有很多操作都只需要在一个进程里执行,比如保存模型,如果不加以上判断,四个进程都会写模型,可能出现写入错误;另外load预训练模型权重时,也应该加入判断,只load一次;还有像输出loss等一些场景。
【参考】https://zhuanlan.zhihu.com/p/178402798
标签:DistributedDataParallel,args,训练,torch,rank,Pytorch,GPU,local,分布式 来源: https://www.cnblogs.com/Thinker-pcw/p/16479677.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。