标签:__ 01 name 学习 导入 模块 print import
目录昨日内容回顾
异常处理
如何理解异常
程序在运行的过程中出现了异常使得整个程序结束了,也称bug
异常的分类
nameError、typeError、indexError等
异常的类型
语法错误,不允许出现错误,出现就立马改正
逻辑错误,可以出现,出现后改正
如何理解错误
line所在行是提示是哪一行出现了问题,可以点击链接直接跳到所在行,如果有多行错误,可以从下向上看
最后一行冒号左侧是提示是什么类型的错误,冒号右侧是提示具体的错误是什么
异常的语法结构
try:
可能会出错的代码(被try监控)
except 错误类型1 as e: # e就是具体错误的原因
对应错误类型1的解决措施
except 错误类型2 as e: # e就是具体错误的原因
对应错误类型2的解决措施
except 错误类型3 as e: # e就是具体错误的原因
对应错误类型3的解决措施
except 错误类型4 as e: # e就是具体错误的原因
对应错误类型4的解决措施
万能异常结构
try:
123 + 'hello'
except Exception as e: # 万能异常方式1
print(e)
except BaseException as e: # 万能异常方式2
print(e)
其他关键字
try:
name = 123
except Exception as e:
print('你出错了 你个小垃圾')
else:
print('try监测的代码没有出错的情况下正常运行结束 则会执行else子代码')
finally:
print('try监测的代码无论有没有出错 最后都会执行finally子代码')
主动报错
name = input('username>>>:').strip()
if name == 'jason':
# raise NameError('jason来了 快跑!!!')
raise Exception('反正就是不能过')
else:
print('不是jason 那没事了')
'''可以用来处理一些紧急情况'''
断言
name = 'jason'
# 通过一系列的手段获取来的数据
assert isinstance(name, list)
# 断言数据属于什么类型 如果不对则直接报错 对则正常执行下面的代码
print('针对name数据使用列表相关的操作')
应用场景
主要处理一些不可控的情况,try的子代码越少越好,异常处理的代码尽量少用
生成器对象
本质:
其实就是迭代器对象,迭代器对象是解释器提供给我们的,而生成器是我们自己定义出来的。
作用
一种不依赖引取值的通用方式,可以节省数据类型的内存占有空间,优化代码
关键字
当函数体代码中有yield关键字的时候,函数名第一次加括号调用不会执行函数体代码,而是由普通的函数变成了迭代器对象,然后用双下next去取值,在运行双下next的时候遇到yield会停下,下一次会从上一次停下的位置开始,遇到yield继续停下
结合send使用,可以给yield里面传值,会自动调用双下next方法
生成器表达式
元组没有生成式表达式,可以把生成器表达式看作
l1 = (i**2 for i in range(10) if i > 3)
print(l1)
# <generator object <genexpr> at 0x0000022003D2BA50>
今日学习内容
迭代取值与索引取值的差异
# 迭代取值
l1 = [11, 22, 33, 44, 55]
print(l1[0])
print(l1[1])
print(l1[0])
'''
优势:可以随意反复的获取任意数据值
劣势:针对无序的容器类型无法取值
'''
# 索引取值
l1 = [11, 22, 33, 44, 55]
res = l1.__iter__()
print(res.__next__())
print(res.__next__())
print(res.__next__())
'''
优势:提供了一种通用的取值方式
劣势:取值一旦开始只能往前不能回退
'''
模块
1.什么是模块
模块就是一系列功能的结合体 可以直接使用
使用模块就相当于拥有了这个结合体所有的功能
2.为什么要用模块?
极大地提升开发效率
3.模块的来源
3.1.内置模块
无需下载 解释器自带 直接导入使用即可
3.2.自定义模块
自己写的代码 分装成模块 自己用或者发布到网上
3.3.第三方模块
别人写的发布到网上 可以下载使用的模块
4.模块的四种表现形式
4.1.使用python代码编写的py文件
4.2.多个py文件组成的文件夹(按照模块功能的不同划分不同的文件夹)
4.3.已被编译为共享库或DLL的c或C++扩展
4.4.使用C编写并链接到python解释器的内置模块
模块的俩种导入方式
1.模块文件注意事项:
以后真正的项目中 所有的py文件名称都是英文;
学习模块的时候 模块文件的名称就得用英文;
py文件被当做模块导入的时候不需要考虑后缀
2.导入方式
方式一:import....句式
eg:import md
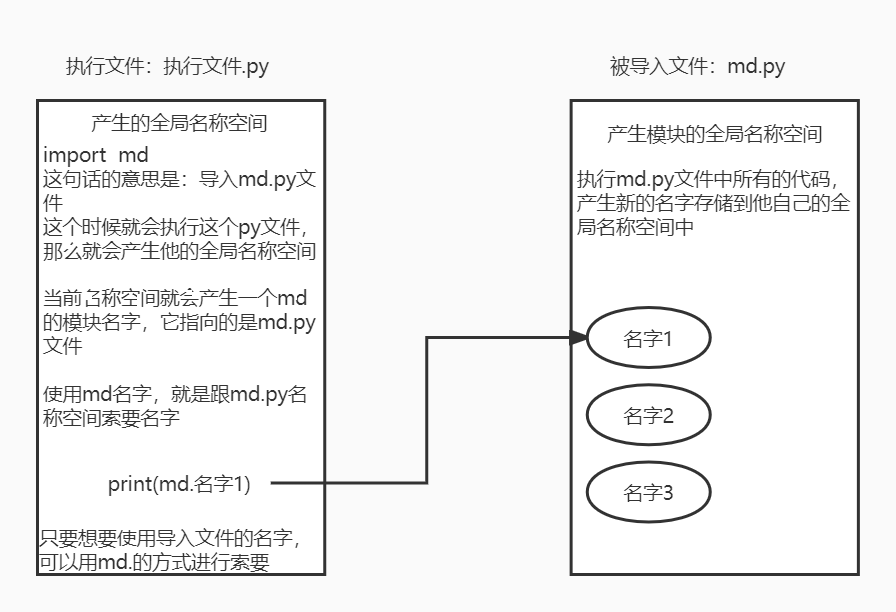
过程流程:
1.会产生执行文件的名称空间
2.产生被导入文件的名称空间并运行该文件内所有的代码 存储名字
3.在执行文件中会获取一个模块的名字 通过该名字点的方式就可以使用到被导入文件名称空间中的名字
小知识:
同一个程序反复导入相同的模块 导入语句只会执行一次
import md 有效
import md 无效
import md 无效
方式二:from....import....句式
from md import money (指名道姓的导入)
from md import money, read1
read1()
eg:from md import money, read1
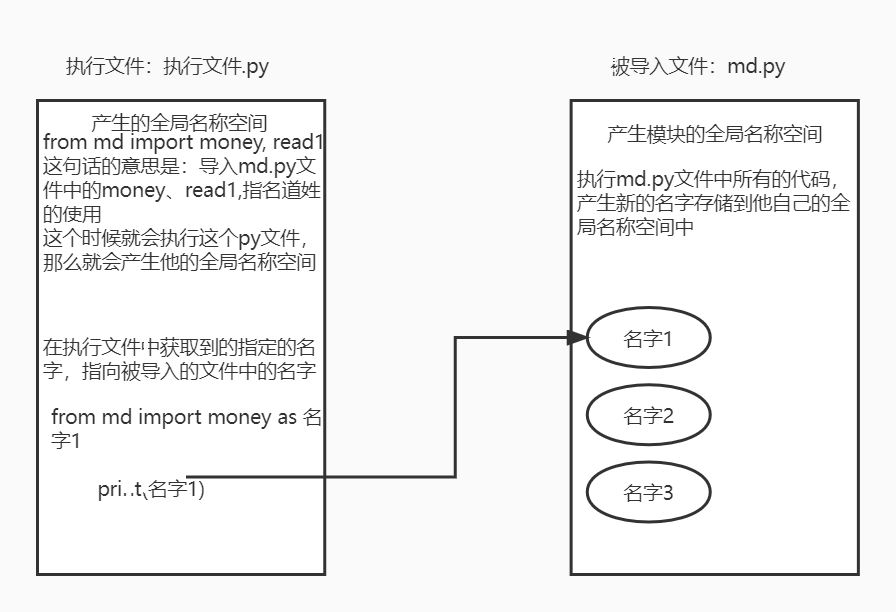
过程流程:
1.创建执行文件的名称空间
2.创建被导入文件的名称空间
3.执行被导入文件中的代码 将产生的名字存储到被导入文件的名称空间中
4.在执行文件中获取到指定的名字 指向被导入文件的名称空间
3.两种导入句式的优缺点
import md
优点:通过md点的方式可以使用到模块内所有的名字 并且不会冲突
缺点:md什么都可以点 有时候并不想让所有的名字都能被使用
from md import money, read1
优点:指名道姓的使用指定的名字 并且不需要加模块名前缀
缺点:名字及其容易产生冲突(绑定关系被修改)
导入模块句式的其他用法
1.起别名
情况1:多个模块文件名相同(多个人写)
from md import money as md_my
from md1 import money as md1_my
print(md_my)
print(md1_my)
情况2:原有的模块文件名复杂
import mdddddddddd as md
2.导入多个名字
import time, sys, os
上述导入方式建议多个模块功能相似才能适应 不相似尽量分开导入
import time
import os
import sys
from md import money, read1, read2
上述导入方式是推荐使用的 因为多个名字出自于一个模块文件
3.全导入
需求:需要使用模块名称空间中很多名字,而且规定只能使用from...import句式
使用这个方法:
from md import *
* 表示所有
ps:针对*号的导入还可以控制名字的数量
在模块文件中可以使用__all__ = [字符串的名字]控制*能够获取的名字
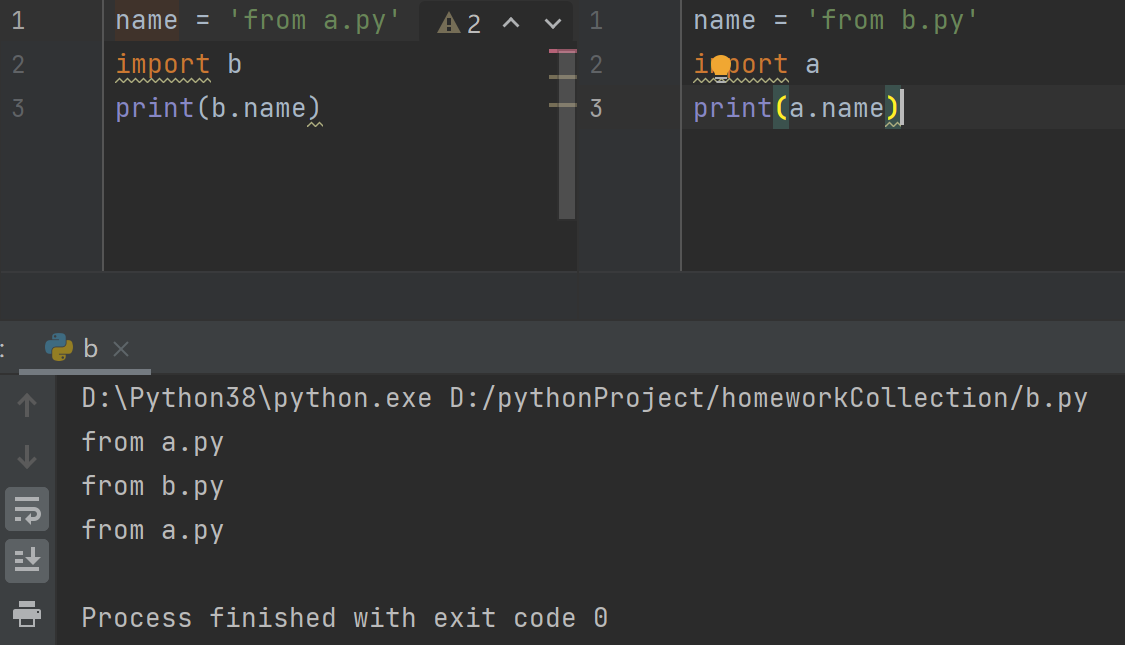
循环导入问题
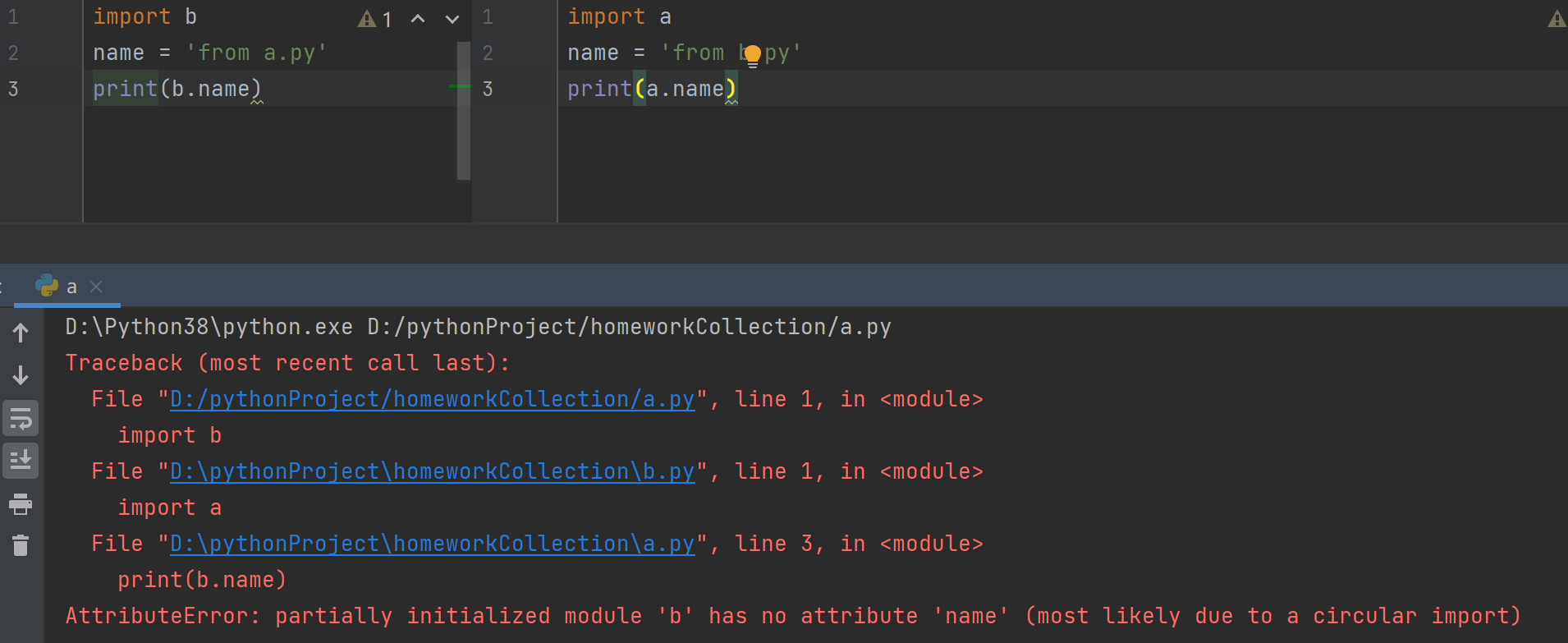
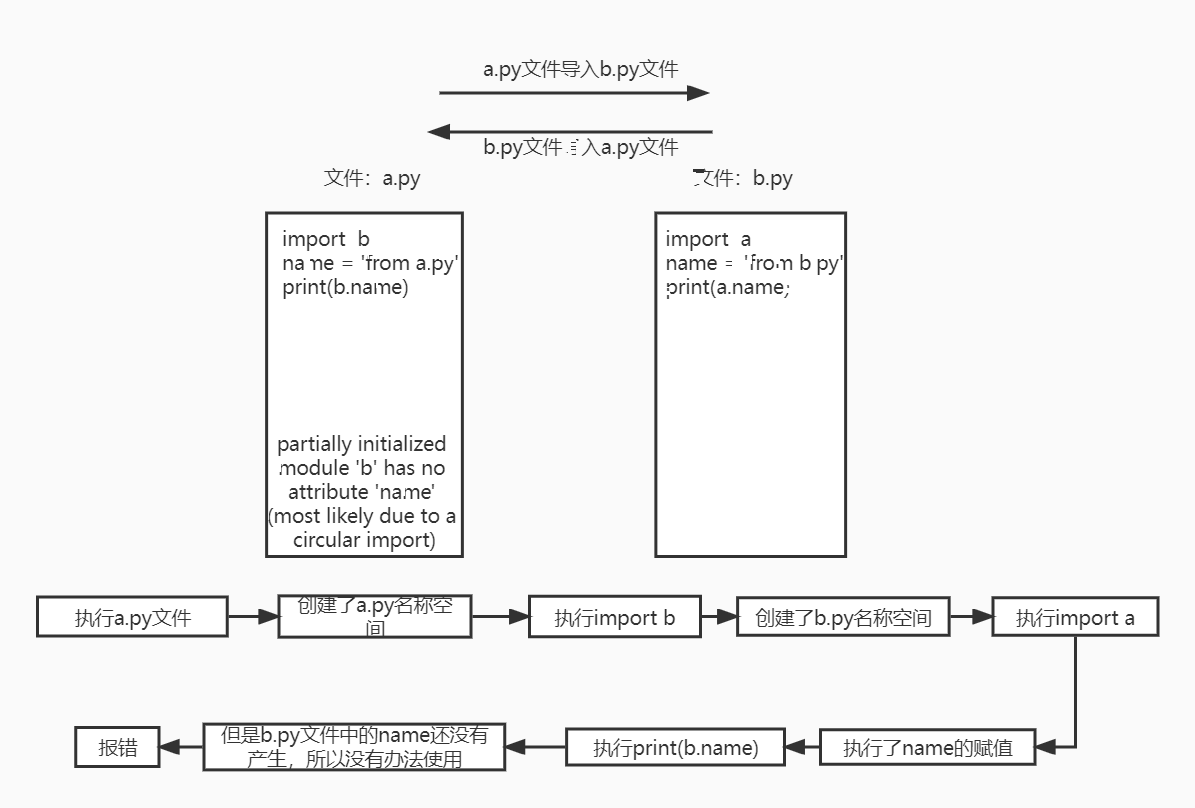
1.怎么理解循环导入
循环导入就是俩个py文件相互导入使用
2.容易出现的报错现象
使用彼此的名字可能是在没有准备好的情况下就使用了
3.避免循环导入
循环导入要尽量避免出现,如果真的无法避免的话,那就在所有名字使用之前提前准备好
name = 'from a.py'
import b
print(b.name)
name = 'from b.py'
import a
print(a.name)
判断文件类型
1.简要
以后程序运行起来可能涉及到的不止一个文件,而针对不同文件是分不同类型的
2.关于__name__
所有的py文件中都自带一个__name__内置名
当py文件是执行文件的时候 name__的结果是__main
当py文件是被导入文件的时候 __name__的结果是模块名(文件名)
3.__name__的用途
主要用于开发模块的作者测试自己的代码使用
if`__`name`__` == `__`main`__`:
"开发者写入的代码" # 自己更改代码的时候不影响别人使用代码
当文件是执行文件的时候才会执行if的子代码
上述判断一般只出现整个程序的启动文件中
ps:在pycharm中可以直接编写main按tab键自动补全
模块查找顺序
1.查找顺序
内存---->内置---->sys.path(程序系统环境变量)
2.验证
# 1.导入一个文件 然后在导入过程中删除该文件 发现还可以使用
import md
import time
time.sleep(15)
print(md.money)
# 2.创建一个跟内置模块名相同的文件名
import time
print(time.time())
from time import name
print(name)
# ps:创建模块文件的时候尽量不要与内置模块名冲突
# 3.导入模块的时候一定要知道谁是执行文件
import sys
print(sys.path)
'''
所有的路径都是参照执行文件来的
内存和内置里都没有的时候,就会来这里找
['D:\\pythonProject\\homeworkCollection',
'D:\\pythonProject\\homeworkCollection',
'D:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_display',
'D:\\Python38\\python38.zip', 'D:\\Python38\\DLLs',
'D:\\Python38\\lib', 'D:\\Python38', 'D:\\Python38\\lib\\site-packages',
'D:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
'''
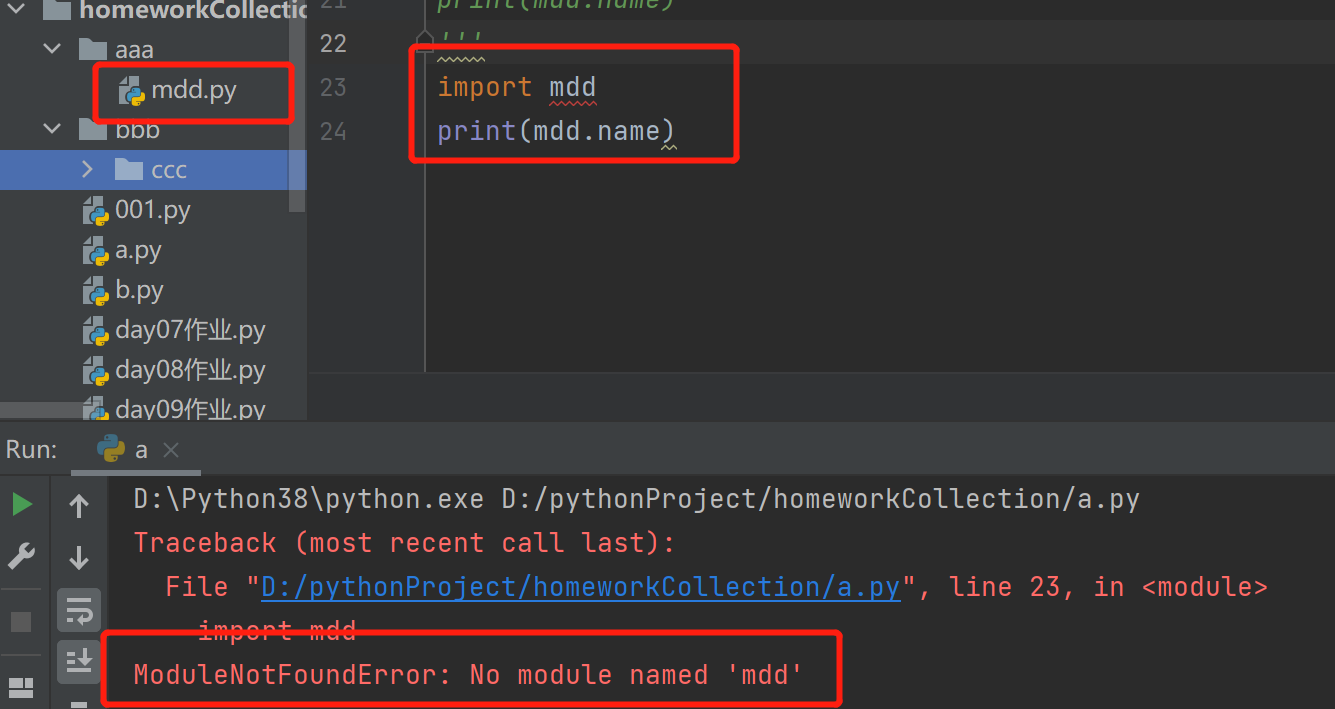
# 解决方案
import sys
# 将mdd的路劲添加到sys中
sys.path.append(r'D:\pythonProject\homeworkCollection\aaa')
import mdd
print(mdd.name)
3.通用的方式
sys.path.append(目标文件所在的路径)
4.利用from...import句式
起始位置一定是执行文件所在的路径 from xxx import mdd
ps:路劲的问题全部以执行文件为主
标签:__,01,name,学习,导入,模块,print,import 来源: https://www.cnblogs.com/zxr1002/p/16475179.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。