标签:总结 第一周 -- Sqoop hive ## 导入 mysql
这周安装了 虚拟机 学习hadoop 相关知识列如
Sqoop的基本概念
Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易。Apache Sqoop正在加紧帮助客户将重要数据从数据库移到Hadoop。随着Hadoop和关系型数据库之间的数据移动渐渐变成一个标准的流程,云管理员们能够利用Sqoop的并行批量数据加载能力来简化这一流程,降低编写自定义数据加载脚本的需求。

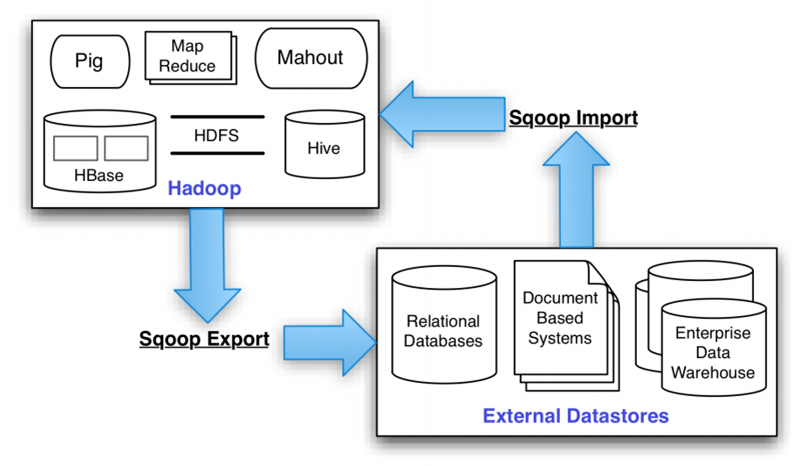
Apache Sqoop(SQL-to-Hadoop) 项目旨在协助 RDBMS 与 Hadoop 之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。因此,可以说Sqoop就是一个桥梁,连接了关系型数据库与Hadoop。
1.2 Sqoop的基本机制
Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。Sqoop的基本工作流程如下图所示:
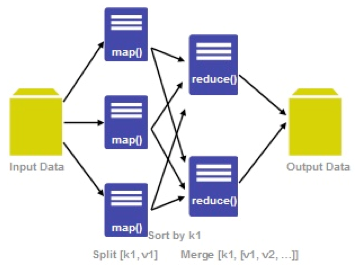
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中(由此也可知,导入导出的事务是以Mapper任务为单位)。同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。 比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
数据导入:MySQL->HDFS
这里假设我们已经在hadoop-master服务器中安装了MySQL数据库服务,并使用默认端口3306。需要注意的是,sqoop的数据库驱动driver默认只支持mysql和oracle,如果使用sqlserver的话,需要把sqlserver的驱动jar包放在sqoop的lib目录下,然后才能使用drive参数。
(1)MySQL数据源:mysql中的hive数据库的TBLS表,这里使用学习笔记17《Hive框架学习》里边Hive的数据库表。
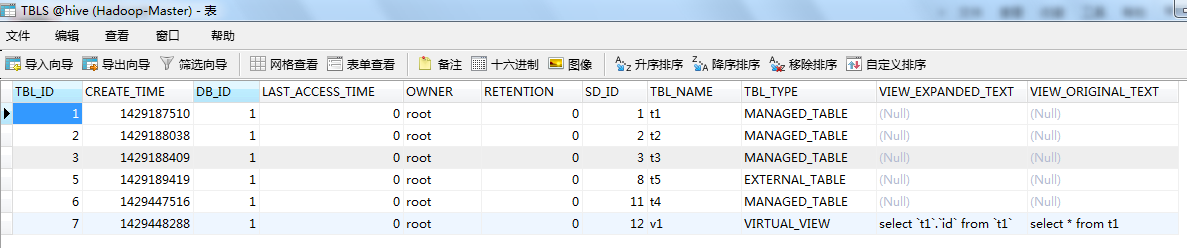
(2)使用import命令将mysql中的数据导入HDFS:
首先看看import命令的基本格式:
sqoop ##sqoop命令
import ##表示导入
--connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
--username root ##连接mysql的用户名
--password admin ##连接mysql的密码
--table mysql1 ##从mysql导出的表名称
--fields-terminated-by '\t' ##指定输出文件中的行的字段分隔符
-m 1 ##复制过程使用1个map作业
--hive-import ##把mysql表数据复制到hive空间中。如果不使用该选项,意味着复制到hdfs中
然后看看如何进行实战:这里将mysql中的TBLS表导入到hdfs中(默认导入目录是/user/<username>)
sqoop import --connect jdbc:mysql://hadoop-master:3306/hive --username root --password admin --table TBLS --fields-terminated-by '\t'
最后看看是否成功导入了HDFS中:可以看到TBLS表存入了多个map任务所生成的文件中
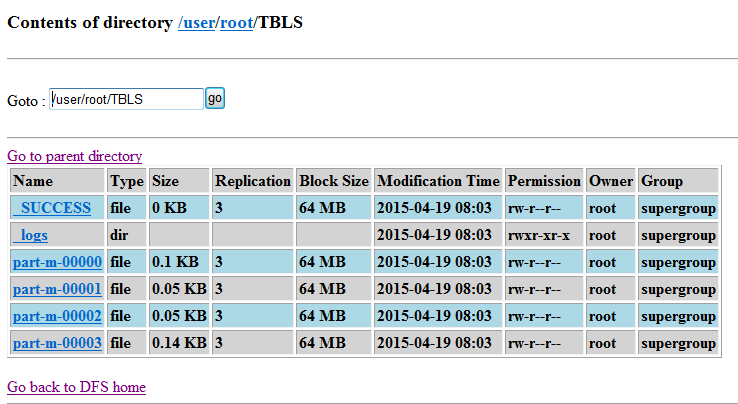

(3)刚刚看到了默认是由多个map来进行处理生成,可以设置指定数量的map任务。又由于sqoop默认不是追加方式写入,还可以设置其为追加方式写入已有文件末尾:
sqoop import --connect jdbc:mysql://hadoop0:3306/hive --username root --password admin --table TBLS --fields-terminated-by '\t' --null-string '**' -m 1 --append
(4)还可以将MySQL中的数据导入Hive中(你设定的hive在hdfs中的存储位置,我这里是/hive/):
首先得删掉刚刚导入到hdfs中的文件数据:
hadoop fs -rmr /user/root/*
然后再通过以下命令导入到hive中:
sqoop import --connect jdbc:mysql://hadoop-master:3306/hive --username root --password admin --table TBLS --fields-terminated-by '\t' -m 1 --append --hive-import
最后看看是否导入到了hive目录(/hive/)中:
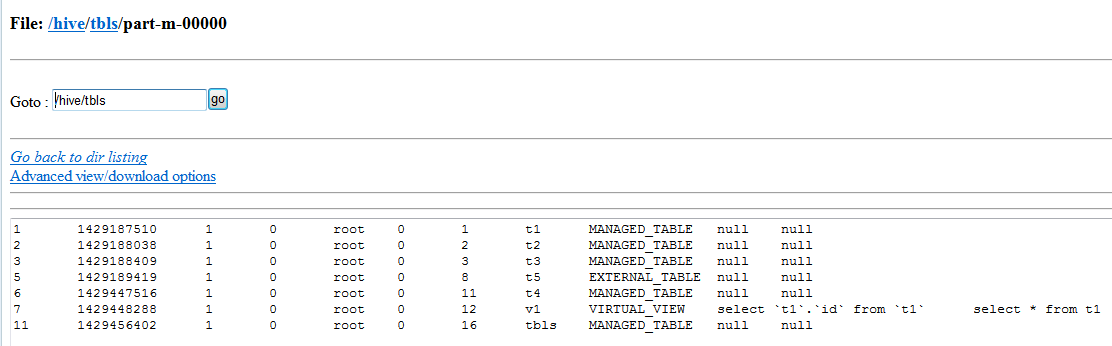
(5)还可以对指定数据源进行增量导入:所谓增量打入,就是导入上一次导入后数据源新增的那部分数据,例如:上次导入的数据是id从1~100的数据,那么这次就只导入100以后新增的数据,而不必整体导入,节省了导入时间。下面的命令以TBL_ID字段作为判断标准采用增量导入,并记录上一次的最后一个记录是6,只导入6以后的数据即可。
sqoop import --connect jdbc:mysql://hadoop0:3306/hive --username root --password admin --table TBLS --fields-terminated-by '\t' --null-string '**' -m 1 --append --hive-import --check-column 'TBL_ID' --incremental append --last-value 6
2.3 数据导出:HDFS->MySQL
(1)既然要导出到MySQL,那么首先得要有一张接收从HDFS导出数据的表。这里为了示范,只创建一个最简单的数据表TEST_IDS,只有一个int类型的ID字段。
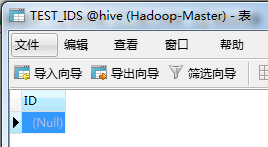
(2)使用export命令进行将数据从HDFS导出到MySQL中,可以看看export命令的基本格式:
sqoop
export ##表示数据从hive复制到mysql中
--connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
--username root ##连接mysql的用户名
--password admin ##连接mysql的密码
--table mysql2 ##mysql中的表,即将被导入的表名称
--export-dir '/user/root/warehouse/mysql1' ##hive中被导出的文件目录
--fields-terminated-by '\t' ##hive中被导出的文件字段的分隔符
注意:导出的数据表必须是事先存在的
(3)准备一个符合数据表规范的文件ids并上传到HDFS中,作为导出到MySQL的数据源:这个ids里边只有10个数字
大多数看的是怎么安装 hadoop 因为实在是安装 后环境搭建不起来
在学习上大约花费了10个小时左右,花在代码上大约5个小时 大部分时间在搞 Hadoop 解决问题 剩下时间都在解决问题
下周准备接着 搞虚拟机成功装上Hadoop 把数据库作业界面美化一下套个模板
在Hadoop安装过程中遇见端口无法访问的问题
编译hadoop 连接eclipse 插件遇见一系列报错
忘记root权限,不然会报错,无法编译成功,昨天其实我应该设置好所有的参数了,就是没有使用root权限,所以没有安装成功 最后root也不管用就是


最后安装上运行也没有运行起来
参考了 以下网站(有用的)
https://www.cnblogs.com/ljy2013/articles/4417933.html
https://www.cnblogs.com/zhangchao0515/p/7099002.html
https://www.cnblogs.com/PurpleDream/p/4014751.html
https://www.cnblogs.com/sissie-coding/p/9449941.html
搜索
复制
标签:总结,第一周,--,Sqoop,hive,##,导入,mysql 来源: https://www.cnblogs.com/stdxxd/p/16438173.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。