标签:文件 文库 打印 选中 pdf 原文 PDF 100 下载
引言
因为学习的原因,在使用电子书籍的时候较多,所以有时候不得不在百度或者学校的图书馆搜一下书籍。当时找的是一本“数值分析”书籍,在百度没有找到,图书馆给我推荐到了一个文库,说可以看电子版的,但是不能下载。每次进入网站看很麻烦呀,而且提供的图片清晰度也不高,所以需要看看可不可以下载。
部分打印
通常的思路是看看网页pdf可不可以直接打印,如果可以直接打印的话,那么我们也就不需要多加步骤了。

图 1
幸运的是,图1这里直接有打印的图标,但会发现,图2除了“当前页面”可选中之外,其他的按钮均为不可选中。因为这些属性是直接可以通过界面即网页源码定义的,所以通过检查元素图3或者F12开发者选项功能图4进行定位,则可以修改标签选中状态。
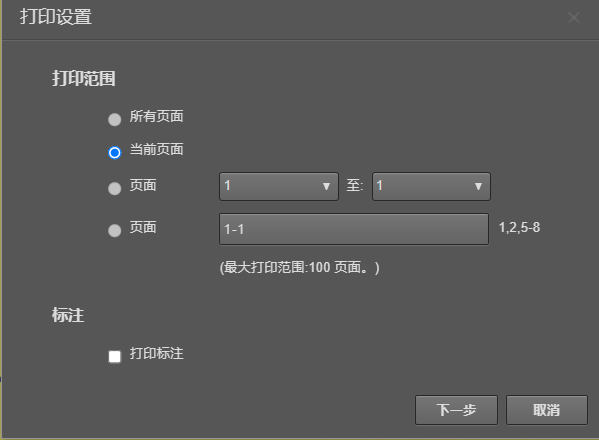
图 2

图 3
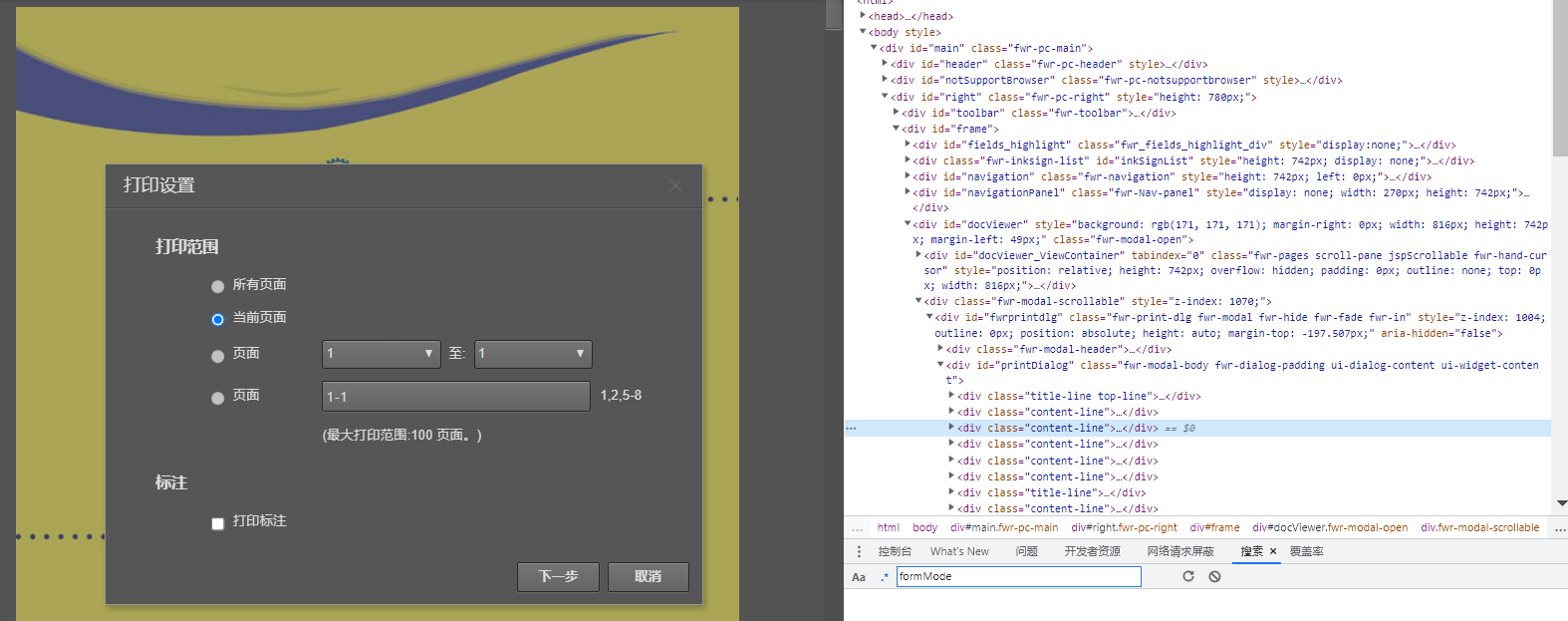
图 4
删除相关元素的disabled="disabled" 属性,则可以进行选中相关标签。但这里有一个问题是每次操作打印后,需要再进行上述操作,这是因为在网页再刷新的时候,js文件会再次进行属性设置,我们没有进行js文件修改,所以我们的操作会被覆盖。
当选中“所有页面”时,如果电子书籍页码大于100页时,会提示我们超过了100页,会终止打印,下面两个“页面”设置如果超过100页也会这样提示,这个问题我们等会再进行处理。这里主要说的是多次部分小于100页的打印。
所以每次按照上述操作,选中“页面”进行小于100页的多批次打印,打印的时间不确定,依照文件大小或者网络速度有关,因为在打印过程中,通过网络监控可以发现,打印的原理是进行图片链接访问,然后以图片的形式打印成pdf。
这种方法会出现以下问题:
1.图片的质量不高,默认的图片质量为100。
2.打印的pdf文件为图片pdf,并不是矢量pdf。
全文打印
当我们选中“所有页面”打印的时候,会提示“当前设置的页面已超出范围”。所以我们就需要找到当我们点击“下一步”按钮时,按钮传递了什么值,为什么会提示(如图5)?
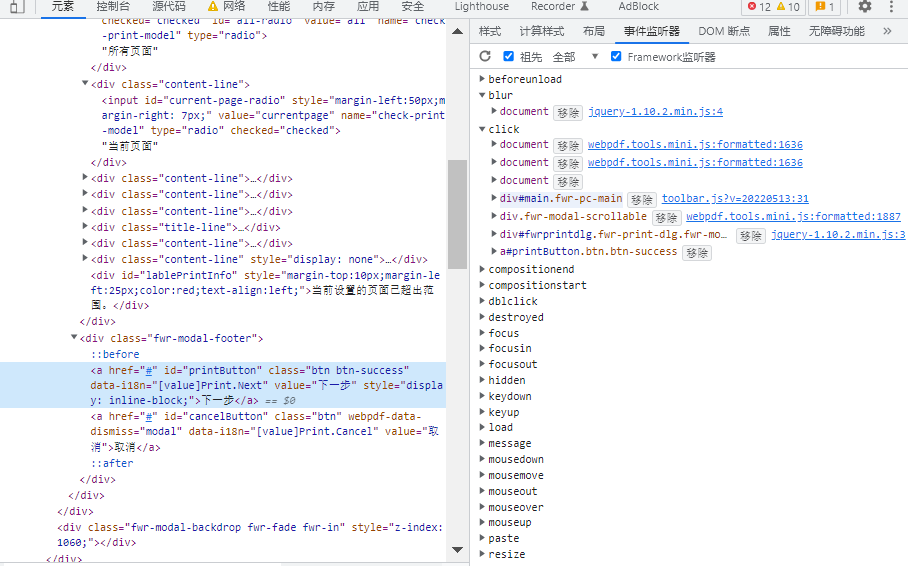
图 5
这里可以发现选中“所有页面”时,传递的value值为all。但是我们对按钮监听事件分析,并没有直接得出跟判断100页有关系的函数。所以转变一个思路,开始没有显示提示,但是超过100页会提示,所以这个显示与100页有关系。选中提示,得到提示的id为“lablePrintInfo”。所以进行搜索得到图6:

图 6
在18752行:
B > 100)return void $("#lablePrintInfo").html(i18n.t("Print.OutOfRangeMessage"));var s = "";
这里可以发现这里有一个判断,如果大于了100,则会提示,所以我们只需要修改这个100页为一个比较大的值,就可以实现全文打印了。(修改js文件方法自行百度)
这里存在一个问题:打印的时间特别长且打印出来的格式容易错乱。
清晰度设置
打印的过程中会发起“https://网站地址/asserts/书籍id/image/页码/分辨率?accessToken=accessToken&formMode=true“通过对‘formMode’搜索:
可以找到:
var e = a.getBaseUrl() + "asserts/" + a.getFileID() + "/image/" + b + "/100?formMode=false&accessToken=accessToken", f = new XMLHttpRequest;
所以将100进行设置,可以提高图片的分辨率。此方法对于超级大型的文件并不适用,这里也不做过多讲解。
全文下载
既然我们可以直接浏览pdf,那么说明在访问这个网站的时候,系统需要传入或者设置pdf文件,pdf文件可以是本地也可以是网络文件。所以我们对网站再次刷新分析整个加载过程。
在进程中发现存在一个post,名叫add。查看post表单:
params:{"params":{"userName":"8","userId":"*","file":"*.pdf"}}type: *
所以我们发现这实际上是将网络pdf文件加载出来的,但是我们直接访问pdf地址是没有权限的。而上面的post得到了一个result。再综合后面的一系列链接,发现result就是一个文件的id。但是我们要想办法使用这个id。
在后面的链接中发现有一个info的get请求,它得到了assertUrl,fileid,fname,userName。这里我的第一个想法就是对得到的数据进行get,或许这样就可以得到pdf文件了。哎,但是无果,我怎么进行get拼接,都访问不成功。这里实在想不通了,我就直接不拼接了,将assertUrl的根网址访问了一下。
居然,发现可以直接访问,可以是访问到了一个在线pdf阅读器,其中的界面与刚才的差不多,但是有许多功能可以直接使用。甚至有直接下载pdf的功能,但是点击“下载pdf”发现会下载失败。
于是又看见有“开启离线阅读模式”功能,点击后会下载pdf文件;对下载文件地址分析:http://******/api/file/*******/getDocumentbuffer
So 可以下载了
标签:文件,文库,打印,选中,pdf,原文,PDF,100,下载 来源: https://www.cnblogs.com/anzhili/p/16386621.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。