标签:loss 人脸识别 函数 type self 损失 positive x1 margin
本文主要是针对人脸识别中的各种loss进行总结。
背景
对于分类问题,我们常用的loss function是softmax,表示为: ,当然有softmax肯定也有hardmax:
,softmax和hardmax相比,优势是更容易收敛,更容易达到one-hot。softmax鼓励特征分开,但是并不鼓励分的很开,对于人脸识别来说我们需要类内的距离也足够小,同时保证类间的距离足够大。现有的人脸loss大都基于L2距离和cos距离。
Contrastive Loss
核心思想是随机从训练样本中选择两个样本,如果两者属于同一类,那么使他们的距离尽可能小,否则的话就是使他们的距离尽可能远。Loss function为:
y表示的是否是同一类别。它的缺点很明显,就是需要为每对非同类样本指定margin,而且这个margin是固定的,这就导致embedding空间是固定的,不能发生畸变(distortion)。triplet loss的margin是不固定的。这样的话,对于contrastive loss来说,选择hard example通常会更快地收敛。
https://github.com/delijati/pytorch-siamese/blob/master/contrastive.pygithub.com/delijati/pytorch-siamese/blob/master/contrastive.pyclass ContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
Based on:
"""
def __init__(self, margin=1.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def check_type_forward(self, in_types):
assert len(in_types) == 3
x0_type, x1_type, y_type = in_types
assert x0_type.size() == x1_type.shape
assert x1_type.size()[0] == y_type.shape[0]
assert x1_type.size()[0] > 0
assert x0_type.dim() == 2
assert x1_type.dim() == 2
assert y_type.dim() == 1
def forward(self, x0, x1, y):
self.check_type_forward((x0, x1, y))
# euclidian distance
diff = x0 - x1
dist_sq = torch.sum(torch.pow(diff, 2), 1)
dist = torch.sqrt(dist_sq)
mdist = self.margin - dist
dist = torch.clamp(mdist, min=0.0)
loss = y * dist_sq + (1 - y) * torch.pow(dist, 2)
loss = torch.sum(loss) / 2.0 / x0.size()[0]
return loss
Triplet Loss
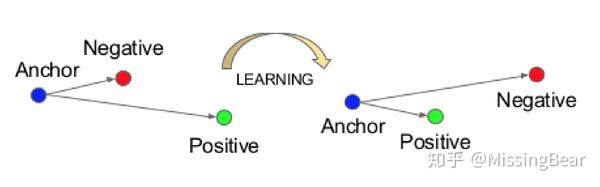
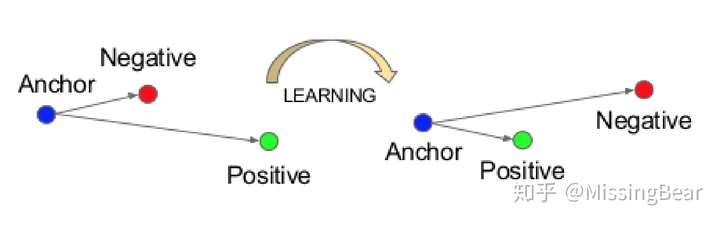
They use Euclidean embedding space to find the similarity or difference between faces. Loss minimizes the distances between similar faces and maximizes one between different faces.
其中f()是embedding function,a是anchor sample,p是positive sample, n是negative sample, 是positive samples和negative samples之间的margin。
从而得到这样的constraint:
,我们只关心违背了constraint的pair,因为这样对训练有用,我们需要选择与anchor最近的negative和最远的positive,同时如何选择pair又是一件非常tricky的事,直接去找最大和最小肯定是不现实的,代价太大!文章提出了两种方法:
- 离线,每n步使用最近的网络再一个subset中选择所需要的样本;
2. 在线,mini-batch中选择
作者选择了第二种。
https://github.com/adambielski/siamese-triplet/blob/master/losses.pygithub.com/adambielski/siamese-triplet/blob/master/losses.py
class TripletLoss(nn.Module):
"""
Triplet loss
Takes embeddings of an anchor sample, a positive sample and a negative sample
"""
def __init__(self, margin):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative, size_average=True):
distance_positive = (anchor - positive).pow(2).sum(1) # .pow(.5)
distance_negative = (anchor - negative).pow(2).sum(1) # .pow(.5)
losses = F.relu(distance_positive - distance_negative + self.margin)
return losses.mean() if size_average else losses.sum()Center Loss
最小化类内的variations,同时保证类间的特征分开:
,其中c类中心,随网络一起更新。
下面就是更新的一些推导:
L-Softmax Loss
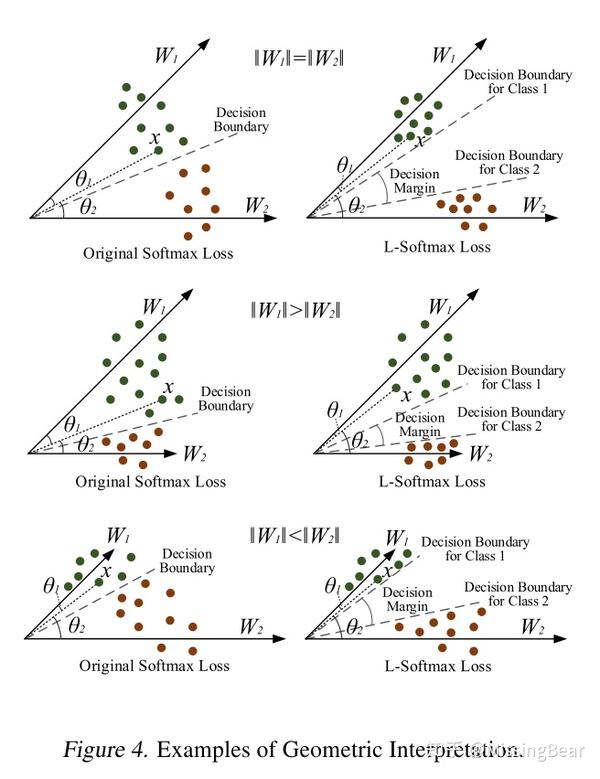
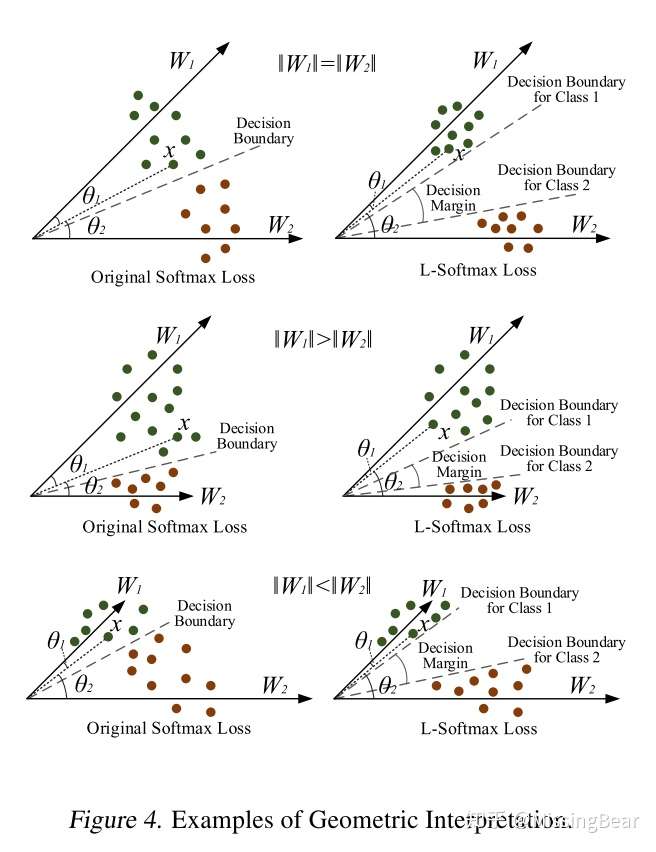
样本和参数的分离性可以分解成amplitude和angular
所以对于softmax的cross entropy loss可以写成:
对于初始的二分类softmax来说,我们需要保证:
,即
考虑到 函数在
是单调递减的,为了提高分类的难度,将其改写成:
m越大,对于相同的 和x来说,
的选择空间越小,分类也越严格,使得学到的类间特征会更加接近W,减小类内的距离,与此同时中间的间隔也会更大,这样可以增加类间的距离。本质上是通过限制decision margin来提高分离性!
最终得到:


A-Softmax Loss
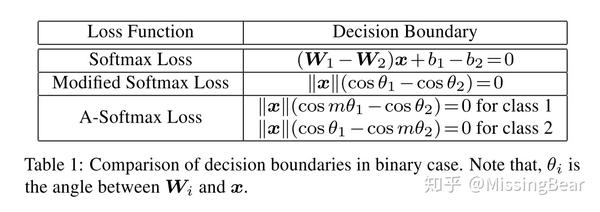
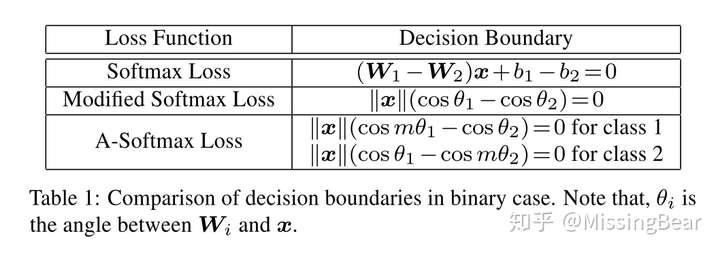
和L-Softmax类似,不过A-Softmax将参数W的归一化,使得W的l2 norm为1,这样的话分类只和特征向量和W的角度有关了!通过限制角度的选择空间来加大训练难度,提高分离性。
把每一类都加大难度!
然后再优化一下:
其中
参考文献
- Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 815-823.MLA
- Wen Y, Zhang K, Li Z, et al. A discriminative feature learning approach for deep face recognition[C]//European Conference on Computer Vision. Springer, Cham, 2016: 499-515.MLA
- Hadsell R, Chopra S, LeCun Y. Dimensionality reduction by learning an invariant mapping[C]//null. IEEE, 2006: 1735-1742.
- Liu W, Wen Y, Yu Z, et al. Sphereface: Deep hypersphere embedding for face recognition[C]//The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017, 1: 1.
- Liu W, Wen Y, Yu Z, et al. Large-Margin Softmax Loss for Convolutional Neural Networks[C]//ICML. 2016: 507-516.
本文转载:https://zhuanlan.zhihu.com/p/42793251
标签:loss,人脸识别,函数,type,self,损失,positive,x1,margin 来源: https://www.cnblogs.com/chentiao/p/16367781.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。