标签:11 实战 视频 Hive t1 tez gulivideo category orc
第11章 Hive实战
11.1 需求描述
统计硅谷影音视频网站的常规指标,各种TopN指标:
-- 统计视频观看数Top10
-- 统计视频类别热度Top10
-- 统计出视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
-- 统计视频观看数Top50所关联视频的所属类别Rank
-- 统计每个类别中的视频热度Top10,以Music为例
-- 统计每个类别视频观看数Top10
-- 统计上传视频最多的用户Top10以及他们上传的视频观看次数在前20的视频
11.2 数据结构
1)视频表
视频表
| 字段 | 备注 | 详细描述 |
|---|---|---|
| videoId | 视频唯一id(String) | 11位字符串 |
| uploader | 视频上传者(String) | 上传视频的用户名String |
| age | 视频年龄(int) | 视频在平台上的整数天 |
| category | 视频类别(Array |
上传视频指定的视频分类 |
| length | 视频长度(Int) | 整形数字标识的视频长度 |
| views | 观看次数(Int) | 视频被浏览的次数 |
| rate | 视频评分(Double) | 满分5分 |
| Ratings | 流量(Int) | 视频的流量,整型数字 |
| conments | 评论数(Int) | 一个视频的整数评论数 |
| relatedId | 相关视频id(Array |
相关视频的id,最多20个 |
2)用户表
用户表
| 字段 | 备注 | 字段类型 |
|---|---|---|
| uploader | 上传者用户名 | string |
| videos | 上传视频数 | int |
| friends | 朋友数量 | int |
11.3 准备工作
11.3.1 ETL
通过观察原始数据形式,可以发现,视频可以有多个所属分类,每个所属分类用&符号分割,且分割的两边有空格字符,同时相关视频也是可以有多个元素,多个相关视频又用“\t”进行分割。为了分析数据时方便对存在多个子元素的数据进行操作,我们首先进行数据重组清洗操作。即:将所有的类别用“&”分割,同时去掉两边空格,多个相关视频id也使用“&”进行分割。
1)ETL之封装工具类
public class ETLUtil {
/**
* 数据清洗方法
*/
public static String etlData(String srcData){
StringBuffer resultData = new StringBuffer();
//1. 先将数据通过\t 切割
String[] datas = srcData.split("\t");
//2. 判断长度是否小于9
if(datas.length <9){
return null ;
}
//3. 将数据中的视频类别的空格去掉
datas[3]=datas[3].replaceAll(" ","");
//4. 将数据中的关联视频id通过&拼接
for (int i = 0; i < datas.length; i++) {
if(i < 9){
//4.1 没有关联视频的情况
if(i == datas.length-1){
resultData.append(datas[i]);
}else{
resultData.append(datas[i]).append("\t");
}
}else{
//4.2 有关联视频的情况
if(i == datas.length-1){
resultData.append(datas[i]);
}else{
resultData.append(datas[i]).append("&");
}
}
}
return resultData.toString();
}
}
2)ETL之Mapper
/**
* 清洗谷粒影音的原始数据
* 清洗规则
* 1. 将数据长度小于9的清洗掉
* 2. 将数据中的视频类别中间的空格去掉 People & Blogs
* 3. 将数据中的关联视频id通过&符号拼接
*/
public class EtlMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
private Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//清洗
String resultData = ETLUtil.etlData(line);
if(resultData != null) {
//写出
k.set(resultData);
context.write(k,NullWritable.get());
}
}
}
3)ETL之Driver
package com.wolffy.gulivideo.etl;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class EtlDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(EtlDriver.class);
job.setMapperClass(EtlMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}
4)将ETL程序打包为etl.jar 并上传到Linux的 /opt/module/hive/datas 目录下
5)上传原始数据到HDFS
[wolffy@hadoop102 datas] pwd
/opt/module/hive/datas
[wolffy@hadoop102 datas] hadoop fs -mkdir -p /gulivideo/video
[wolffy@hadoop102 datas] hadoop fs -mkdir -p /gulivideo/user
[wolffy@hadoop102 datas] hadoop fs -put gulivideo/user/user.txt /gulivideo/user
[wolffy@hadoop102 datas] hadoop fs -put gulivideo/video/*.txt /gulivideo/video
6)ETL数据
[wolffy@hadoop102 datas] hadoop jar etl.jar com.wolffy.hive.etl.EtlDriver /gulivideo/video /gulivideo/video/output
11.3.2 准备表
1)需要准备的表
创建原始数据表:gulivideo_ori,gulivideo_user_ori,
创建最终表:gulivideo_orc,gulivideo_user_orc
2)创建原始数据表:
(1)gulivideo_ori
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as textfile;
(2)创建原始数据表: gulivideo_user_ori
ccreate table gulivideo_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as textfile;
1) 创建orc存储格式带snappy压缩的表:
(1)gulivideo_orc
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
stored as orc
tblproperties("orc.compress"="SNAPPY");
(2)gulivideo_user_orc
create table gulivideo_user_orc(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by "\t"
stored as orc
tblproperties("orc.compress"="SNAPPY");
(3)向ori表插入数据
load data inpath "/gulivideo/video/output" into table gulivideo_ori;
load data inpath "/gulivideo/user" into table gulivideo_user_ori;
(4)向orc表插入数据
insert into table gulivideo_orc select * from gulivideo_ori;
insert into table gulivideo_user_orc select * from gulivideo_user_ori;
11.3.3 安装Tez引擎(了解)
Tez是一个Hive的运行引擎,性能优于MR。为什么优于MR呢?看下。
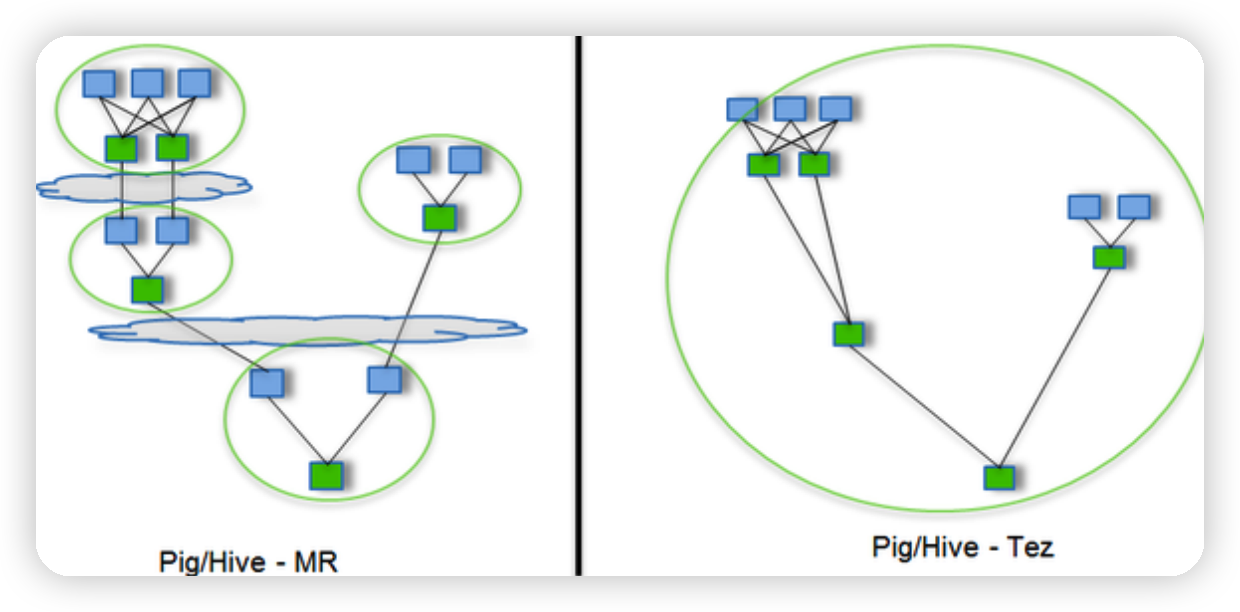
用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到HDFS。
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
1)将tez安装包拷贝到集群,并解压tar包
[wolffy@hadoop102 software]$ mkdir /opt/module/tez
[wolffy@hadoop102 software]$ tar -zxvf /opt/software/tez-0.10.1-SNAPSHOT-minimal.tar.gz -C /opt/module/tez
2)上传tez依赖到HDFS
[wolffy@hadoop102 software]$ hadoop fs -mkdir /tez
[wolffy@hadoop102 software]$ hadoop fs -put /opt/software/tez-0.10.1-SNAPSHOT.tar.gz /tez
3)新建tez-site.xml
[wolffy@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/tez-site.xml
添加如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1-SNAPSHOT.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.4</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
</configuration>
4)修改Hadoop环境变量
[wolffy@hadoop102 software]$ vim $HADOOP_HOME/etc/hadoop/shellprofile.d/tez.sh
添加Tez的Jar包相关信息
hadoop_add_profile tez
function _tez_hadoop_classpath
{
hadoop_add_classpath "$HADOOP_HOME/etc/hadoop" after
hadoop_add_classpath "/opt/module/tez/*" after
hadoop_add_classpath "/opt/module/tez/lib/*" after
}
5)修改Hive的计算引擎
[wolffy@hadoop102 software]$ vim $HIVE_HOME/conf/hive-site.xml
添加
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>
6)解决日志Jar包冲突
[wolffy@hadoop102 software]$ rm /opt/module/tez/lib/slf4j-log4j12-1.7.10.jar
11.4 业务分析
11.4.1 统计视频观看数Top10
思路:使用order by按照views字段做一个全局排序即可,同时我们设置只显示前10条。
最终代码:
SELECT
videoId,
views
FROM
gulivideo_orc
ORDER BY
views DESC
LIMIT 10;
11.4.2 统计视频类别热度Top10
思路:
(1)即统计每个类别有多少个视频,显示出包含视频最多的前10个类别。
(2)我们需要按照类别group by聚合,然后count组内的videoId个数即可。
(3)因为当前表结构为:一个视频对应一个或多个类别。所以如果要group by类别,需要先将类别进行列转行(展开),然后再进行count即可。
(4)最后按照热度排序,显示前10条。
最终代码:
SELECT
t1.category_name ,
COUNT(t1.videoId) hot
FROM
(
SELECT
videoId,
category_name
FROM
gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
) t1
GROUP BY
t1.category_name
ORDER BY
hot
DESC
LIMIT 10
11.4.3 统计出视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
思路:
(1)先找到观看数最高的20个视频所属条目的所有信息,降序排列
(2)把这20条信息中的category分裂出来(列转行)
(3)最后查询视频分类名称和该分类下有多少个Top20的视频
最终代码:
SELECT
t2.category_name,
COUNT(t2.videoId) video_sum
FROM
(
SELECT
t1.videoId,
category_name
FROM
(
SELECT
videoId,
views ,
category
FROM
gulivideo_orc
ORDER BY
views
DESC
LIMIT 20
) t1
lateral VIEW explode(t1.category) t1_tmp AS category_name
) t2
GROUP BY t2.category_name
11.4.4 统计视频观看数Top50所关联视频的所属类别排序
代码:
SELECT
t6.category_name,
t6.video_sum,
rank() over(ORDER BY t6.video_sum DESC ) rk
FROM
(
SELECT
t5.category_name,
COUNT(t5.relatedid_id) video_sum
FROM
(
SELECT
t4.relatedid_id,
category_name
FROM
(
SELECT
t2.relatedid_id ,
t3.category
FROM
(
SELECT
relatedid_id
FROM
(
SELECT
videoId,
views,
relatedid
FROM
gulivideo_orc
ORDER BY
views
DESC
LIMIT 50
)t1
lateral VIEW explode(t1.relatedid) t1_tmp AS relatedid_id
)t2
JOIN
gulivideo_orc t3
ON
t2.relatedid_id = t3.videoId
) t4
lateral VIEW explode(t4.category) t4_tmp AS category_name
) t5
GROUP BY
t5.category_name
ORDER BY
video_sum
DESC
) t6
11.4.5 统计每个类别中的视频热度Top10,以Music为例
思路:
(1)要想统计Music类别中的视频热度Top10,需要先找到Music类别,那么就需要将category展开,所以可以创建一张表用于存放categoryId展开的数据。
(2)向category展开的表中插入数据。
(3)统计对应类别(Music)中的视频热度。
统计Music类别的Top10(也可以统计其他)
SELECT
t1.videoId,
t1.views,
t1.category_name
FROM
(
SELECT
videoId,
views,
category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
WHERE
t1.category_name = "Music"
ORDER BY
t1.views
DESC
LIMIT 10
11.4.6 统计每个类别视频观看数Top10
最终代码:
SELECT
t2.videoId,
t2.views,
t2.category_name,
t2.rk
FROM
(
SELECT
t1.videoId,
t1.views,
t1.category_name,
rank() over(PARTITION BY t1.category_name ORDER BY t1.views DESC ) rk
FROM
(
SELECT
videoId,
views,
category_name
FROM gulivideo_orc
lateral VIEW explode(category) gulivideo_orc_tmp AS category_name
)t1
)t2
WHERE t2.rk <=10
11.4.7 统计上传视频最多的用户Top10以及他们上传的视频观看次数在前20的视频
思路:
(1)求出上传视频最多的10个用户
(2)关联gulivideo_orc表,求出这10个用户上传的所有的视频,按照观看数取前20
最终代码:
SELECT
t2.videoId,
t2.views,
t2.uploader
FROM
(
SELECT
uploader,
videos
FROM gulivideo_user_orc
ORDER BY
videos
DESC
LIMIT 10
) t1
JOIN gulivideo_orc t2
ON t1.uploader = t2.uploader
ORDER BY
t2.views
DESC
LIMIT 20
IT学习网站
大数据高薪训练营 完结
链接:https://pan.baidu.com/s/1ssRD-BYOiiMw30EV_BLMWQ
提取码:dghu
失效加V:x923713
QQ交流群 欢迎加入

标签:11,实战,视频,Hive,t1,tez,gulivideo,category,orc 来源: https://www.cnblogs.com/niuniu2022/p/16354086.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。