标签:负载 副本 进阶 分区 broker KAFKA 均衡 kafka leader
大家好,这是一个为了梦想而保持学习的博客。这个专题会记录我对于 KAFKA 的学习和实战经验,希望对大家有所帮助,目录形式依旧为问答的方式,相当于是模拟面试。
一、概述
对于消息中间件来说,负载均衡是非常重要的,不能说我部署了 10 台机器,结果就 2 台忙的要死而其余 8 台都非常空闲,所以通常都需要一些机制来保障集群的负载相对均衡。
注意这里说的是保障而不是保证,因为这些机制可以尽可能的去保障整体负载相对均衡,但是没办法做到绝对的保证负载均衡。
二、服务端负载均衡取决于什么?是如何保障负载均衡的?
我们从前面的文章可以知道,生产 / 消费的真正实体是对应的分区的 leader,所以服务端的负载是否均衡就基本上取决于 leader 分布的是否均匀。
那么服务端是如何尽可能的让 leader 分布均匀的呢?
首先我们需要了解在创建 topic 的时候分区副本是如何分布的,然后再了解是如何从这些副本中选出 leader 的。
我们先来看看 topic 创建时,分区副本的分布过程是什么样子的,我们假设创建一个 TopicA,有 5 分区,3 副本,如下图所示: 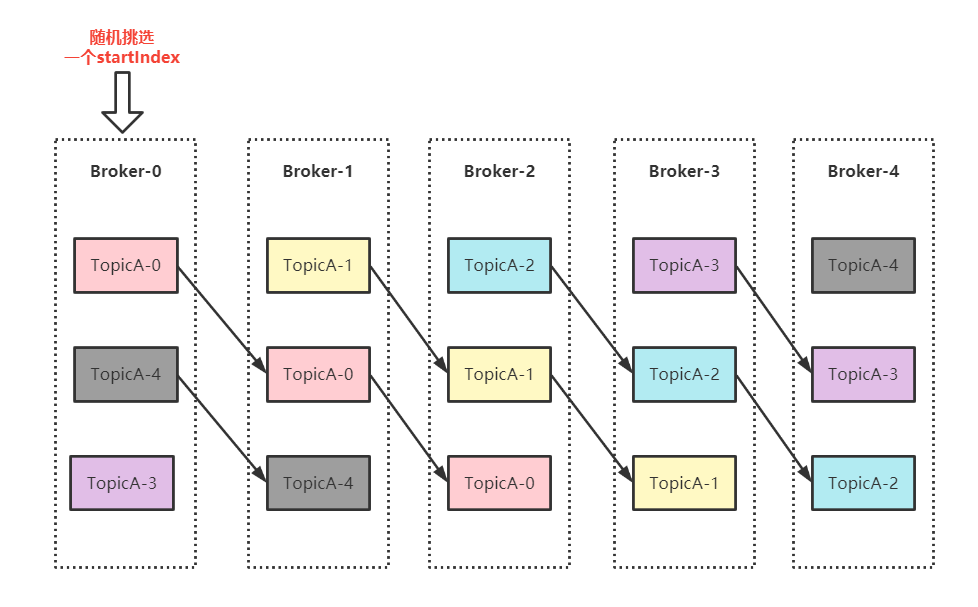
过程概述:
1、随机挑选一个 startIndex,图示中挑选的 startIndex = 0。
2、从 startIndex 开始按照 broker 顺序 生成对应的第一个副本。
3、然后下一轮从 startIndex + 1 开始顺序生成第二个副本,以此类推。
这里可能有同学有疑问,为什么是随机挑选一个 startIndex 呢?我们试想一下要是每次创建分区副本的时候都指定一个特定索引号,例如我们取 startIndex = 0,那么我只创建 1 分区 1 副本的 topic,那么不就意味着所有的 leader 都会在 startIndex 的那台 broker 上?
所以这里的随机挑选也是保障服务端负载均衡的一部分,让分区尽可能的打散到各个 broker 中。
接着上面的图示和案例说,TopicA 这个 5 分区 3 副本的 Topic 基于上面的算法得出了当前分区副本的分布情况,5 个分区副本分布列表如下:
上面的这个分布列表其实就是我们常说的 AR,即所有副本集合;而这其中还有一个概念,叫做优先副本。什么叫优先副本呢,我们以 TopicA-0 的 AR 列表(0,1,2)为例,kafka 会优先选择 broker-0 来成为这个分区的 leader 副本,也就是按照 AR 列表的顺序号优先。最后我们 TopicA 的 leader 副本情况如下,5 个分区的 leader 副本分散到 5 个不同的 broker 上,被尽可能的打散: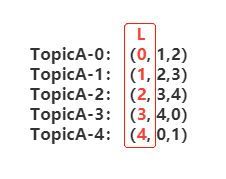
那么到这里,我们就回答了上面的两个问题:
1、创建 topic 的时候分区副本是如何分布的?随机挑选一个 startIndex 之后开始按照 broker 顺序遍历,每一轮结束后 startIndex + 1。
2、如何从这些副本中选出 leader 的?基于优先副本,也就是挑选出 AR 列表中的第一个 brokerId 上的副本成为 leader。
最后我们来回答这个小节的问题,服务端负载均衡的负载均衡是如何保障的呢?
通过 Topic 创建时的算法,保障分区副本尽可能的打散到各个 broker,然后通过优先副本选举选出 AR 中的第一个副本成为 leader,让 leader 副本分散到各个 broker 中,以保障整体的负载均衡。
另外补充一下,随着时间的推移,集群状态的变化,或多或少会发生一些 leader 的切换和迁移,可能会导致某些 broker 上的 leader 会多一些从而导致负载不均衡,kafka 针对这个问题提供了分区自动重平衡的功能,对应 broker 端的参数是 auto.leader.rebalance.enable,默认为 true 即开启。
开启之后呢,Controller 会启动一个定时任务,每隔一段时间(5 分钟)会去轮询所有的 broker,计算每个 broker 节点的分区不平衡率,看是否超过了设置的阈值(默认 10%)如果达到则自动进行分区迁移,将 leader 副本迁移回原先的优先副本所在的 broker。分区不平衡率 = 当前broker的非优先副本leader个数 / 当前broker的分区总数
需要注意的是,这个自动迁移的过程可能会引起负面的性能问题,从而影响到现有的业务,所以需要根据业务情况来判断是否要开启这个功能;另外 kafka 有提供专门的脚本去手动执行该迁移操作:kafka-preferred-replica-election.sh 有兴趣的同学可以查一下具体的用法在此就不再赘述。
三、生产端是如何保障负载均衡的?
生产端保障负载均衡就很简单啦,就思考一下,生产消息的时候需要发往哪个 leader 副本呢?如何才能尽可能的保障每个副本发送的数据都差不多呢?我们来看下 kafkaProducer 的默认分区器实现源码:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
可以看到,当 key 不存在时,计算要发往哪个分区的算法,其实就是轮询算法,非常简单明了和有效。
不过这里有一点值得提一下的就是,当 key 不存在时,会从当前存活的分区里面去轮询;而当 key 存在时,无论那个计算出来的分区存不存活都会往指定分区发送,这是一个比较重要的区别。
四、消费端是如何保障负载均衡的?
对于消费者而言,负载均衡的定义不是说如何均匀的拉取数据,而是总量数据一定的情况下,如何分发给组内的各个 broker。
这里定义比较绕,举个栗子,现在 Topic 有 100w 数据,我消费组内有 4 个消费者;消费端的负载均衡就是想办法保障每个消费者能拉取到 25w 条数据。
明白定义之后,我们就来思考问题,消费端怎么才能做到负载均衡呢?
从前面我们知道,其实消费端消费的实体也是某个分区的 leader 副本,所以我们只需要把分区副本均匀的分配给当前组内的消费者是不是就可以保障负载大致是均衡的呢?
是的,kafka 的消费端程序,如果走消费组机制,就会提供一个分区分配的策略,对应的配置项为:partition.assignment.strategy 默认值为 RangeAssignor。
每当 rebalance 的时候在 SYNC 阶段都会由 consumer 中的 leader 根据这个选出的策略进行分区分配计算,尽可能的让分区分配均匀,从而保障消费端的负载均衡。(对 rebalance 过程不熟悉的同学可以看下我之前的文章:十二)
具体的官方提供策略有哪些呢?我们可以从源码中得知共三种: 
具体这三种的分区分配算法过程我在这里就不写了,我们只需要明白有这几种策略可以去让消费者的分区分配尽可能的均衡,从而保障消费端的负载均衡。
有兴趣的同学可以阅读朱忠华大佬的《深入理解 Kafka》,这里面有详细的讲解。
另外就是,这个分区分配策略是可以自定义扩展的,继承抽象父类 AbstractPartitionAssignor 即可,然后重写指定函数即可,大家可以参照某一种官方实现去自定义实现。
五、什么情况下会出现负载不均衡?
最后,我们总结一下,什么情况下会出现负载不均衡?
服务端:
1、创建 Topic 时手动指定分区分配,可能导致 leader 分布不均。
2、集群状态变化导致 leader 迁移,kafka 自带 leader 重平衡机制可自动迁移 leader。
3、集群节点扩容,新增的节点如果不迁移分区或重建 Topic 不会有 leader 因此不会有流量打过去,从而导致负载不均衡,这也是 kafka 目前现存的比较大的痛点之一。
4、设置了 broker.rack,分区副本算法会为了可用性尽可能避免副本创建在同一机架的机器上,从而可能导致负载不均衡。具体算法和上面算法相差不多,不过是 broker 列表会根据设置的机架信息先排序一次。
生产端:
1、指定业务 key,会让对应 key 的消息都发送到指定分区,可能导致负载不均衡。
2、业务使用上,某些 Topic 的流量远大于其他 Topic 也可能导致负载不均衡。
消费端:
1、分区分配策略,有些策略可能会导致某些场景下分区分配出现不均匀的情况导致负载不均衡。
2、业务使用上,某些 Topic 的流量远大于其他 Topic 也可能导致负载不均衡。
如何解决负载不均衡呢?很可惜,计算机领域没有银弹,负载均衡问题也是一个非常大的命题,所以我们这一篇文章只能大概梳理一下 kafka 中的服务端 / 生产端 / 消费端是怎么尽可能保障负载均衡的,在我们了解了这些机制之后,再根据自己的业务场景去使用 / 运维 kafka 的时候才能尽可能的去避免出现负载不均衡的问题。
标签:负载,副本,进阶,分区,broker,KAFKA,均衡,kafka,leader 来源: https://www.cnblogs.com/keepal/p/16341762.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。