语义分割是图像分割中的基本任务,是指对于图像将每个像素都标注上对应的类别,不区分个体。简单地说,我们需要将视觉输入的数据分为不同的语义可解释性类别。若是区分了个体数量,那么就是实例分割。
本文主要总结一些较为经典的语义分割模型,慢慢更新,主要是对U-Net、FCN、SegNet、PSPNet、DeepLab v1/v2/v3/v3+进行要点概括,论文的具体解读、链接和源码在每个标题之后。
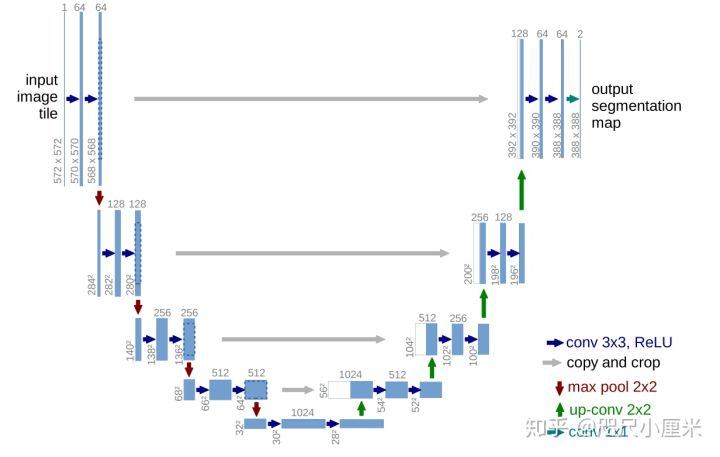
U-Net
-
U-Net发表于2015年,用于医学细胞分割
-
编码器-解码器架构,四次下采样(maxpooling),四次上采样(转置卷积),形成了U型结构
-
U-Net最核心的一个思想是特征图的拼接
-
SGD+Momentum,损失函数为交叉熵
-
数据预处理使用了镜像边缘,可以更好细化边界信息
-
数据增加中有一个弹性形变,符合细胞本身的特性
-
可以应对小样本的数据集进行较快、有效地分割,能够泛化到很多应用场景中去
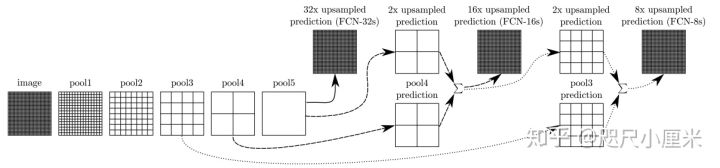
FCN:Fully Convolutional Networks
[论文笔记] FCN:Fully Convolutional Networks - 知乎 (zhihu.com)
- FCN发布于2014年,是语义分割领域全卷积网络的开山之作,U-Net也在其之后
- 其主要思路是将图像分类的网络改良成语义分割的网络,通过将分类器(全连接层)变成上采样层来恢复特征图的尺寸,进行端到端训练
- 分类器变成上采样,这部分思想作者主要的解释是全连接层是一种特殊的卷积
- 选择了AlexNet、GoogLeNet和VGG作为backbone(主干网络),VGG效果最好,但是推理最慢
- 最核心的思想是特征图的融合:假设最后的输出为pool5产生的x,利用转置卷积上采样,放大32倍,得到FCN-32s;将x上采样放大2倍,和pool4产生的特征图直接相加,再上采样放大16倍,得到FCN-16s;将FCN-16s进行上采样放大2倍,与pool3产生的特征图直接相加,在放大8倍,得到FCN-8s。在实验中,FCN-8s的效果最好
- backbone是分类网络,下采样都是maxpooling,上采样使用的是双线性插值初始化的转置卷积
- 在PASCAL VOC 2012上达到了62.2%的mIoU
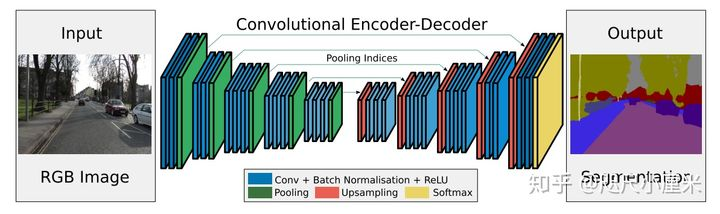
SegNet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
[论文笔记] SegNet: Encoder-Decoder Architecture - 知乎 (zhihu.com)
- SegNet发布于2015年,使用编码器-解码器结构
- 其backbone是2个VGG16,去掉全连接层(13层),对应形成编码器-解码器架构
- 最核心的想法是提出了maxpool的索引来上采样的方法,从而免去了学习上采样的需要,在推理阶段节省了内存
- 作者说道这个idea是来自于无监督特征学习。在解码器中重新使用编码器池化时的索引下标有这么几个优点:1. 能改善边缘的情况;2. 减少了模型的参数;3. 这种能容易就能整合到任何的编码器-解码器结构中,只需要稍稍改动
- 文章采用的数据集是CamVid road scene segmentation 和 SUN RGB-D indoor scene segmentation。之所以不用主流的Pascal VOC12,是因为作者认为VOC12的背景太不相同了,所以可能分割起来比较容易
- 总得来说,SegNet的性能比较一般,不如同时期的DeepLab v1,但是因为它只存储特征映射的maxpool索引,所以最推理阶段内存占用少,更为高效
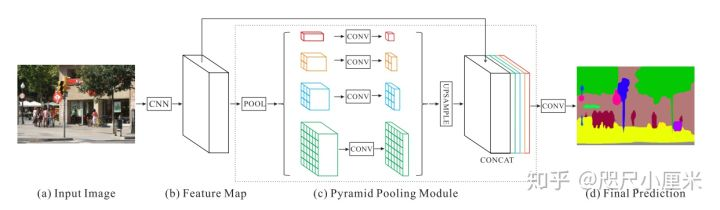
PSPNet:Pyramid Scene Parsing Network
[论文笔记] PSPNet:Pyramid Scene Parsing Network - 知乎 (zhihu.com)
- PSPNet发布于2017年,CVPR 2017
- 核心idea是提出了金字塔池化模块,模型带有空洞卷积
- 金字塔池化(Pyramid pooling)融合了四个比例的特征,结合多尺寸信息:SPP(AVE效果优于MAX)。最粗糙的 \(1x1\)是全局尺度的池化,剩下的层次会将图像分为不同子区域,形成不同区域的信息表示。金字塔池模块中不同level的输出包含比例不同的feature map(比如输入的维度都是 \(2048\) ,有四个层次的金字塔,那么输出的维度则为 \(2048/4=512\) )。为了保持全局特征的权重,若如果金字塔的数量为 ,则N在每个金字塔级别之后使用
1x1卷积层将上下文表示的维度减小到原先的1/N。然后直接对feature map进行双线性插值,恢复到输入的长宽上。最后,将不同level的特征拼接起来作为金字塔池化的全局特征。文中给出的金字塔池化模块是一个四级模块,其大小分别为1x1 2x2 3x3 6x6。 - 其backbone为修改Resnet-101 为 ResNet-103,而且有辅助 loss,上采样是双线性插值
- 性能上PASCAL VOC 2012:85.4%(pre-trained on COCO),82.6%;Cityscape:80.2% (both coarse and fine set)。
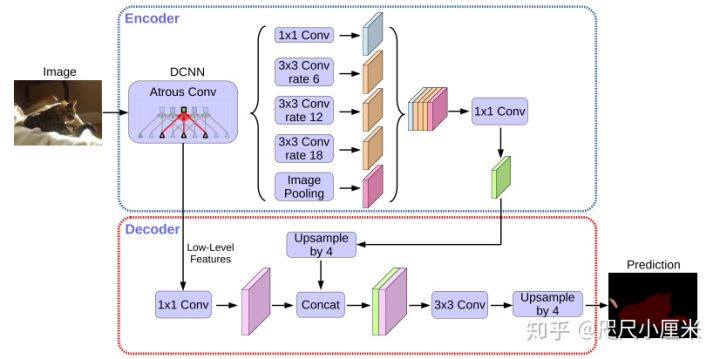
DeepLab v3+
- CVPR 2018
- 和v3的区别是多了一个解码器模块,backbone用了Aligned Xception(其中有深度可分解卷积)
- PASCAL VOC 2012达到了87.8%的mIOU,在JFT预训练的DeepLab v3+在PASCAL VOC 2012上至今领先,达到了89.0%,但是JFT-300M是谷歌的内部数据集,不开源
[论文笔记] DeepLab v3+ - 知乎 (zhihu.com)
标签:采样,分割,卷积,论文,语义,解码器,池化,FCN 来源: https://www.cnblogs.com/cjjcn/p/16271388.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。