标签:Transformer nn Vision self num MindSpore 模型 向量 size
Vision Transformer(ViT)简介
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大的促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。
ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。
模型结构
ViT模型的主体结构是基于Transformer模型的Encoder部分(部分结构顺序有调整,如:normalization的位置与标准Transformer不同),其结构图如下:
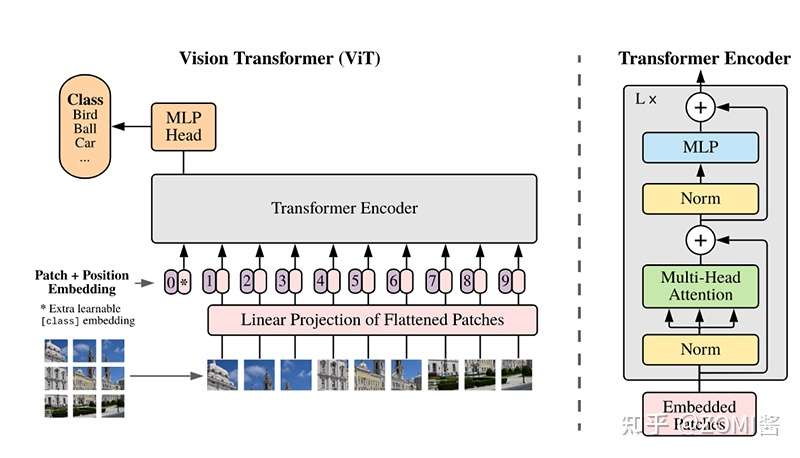
模型特点
ViT模型是应用于图像分类领域。因此,其模型结构相较于传统的Transformer有以下几个特点:
- 数据集的原图像被划分为多个patch后,将二维patch(不考虑channel)转换为一维向量,再加上类别向量与位置向量作为模型输入。
- 模型主体的Block基于Transformer的Encoder部分,但是调整了normaliztion的位置,其中,最主要的结构依然是Multi-head Attention结构。
- 模型在Blocks堆叠后接全连接层接受类别向量输出用于分类。通常情况下,我们将最后的全连接层称为Head,Transformer Encoder部分为backbone。
下面将通过代码实例来详细解释基于ViT实现ImageNet分类任务。
环境准备与数据读取
本案例基于MindSpore-GPU版本,在单GPU卡上完成模型训练和验证。
首先导入相关模块,配置相关超参数并读取数据集,该部分代码在Vision套件中都有API可直接调用,详情可以参考以下链接:https://gitee.com/mindspore/vision 。
可通过:http://image-net.org/ 进行数据集下载。
加载前先定义数据集路径,请确保你的数据集路径如以下结构。
.ImageNet/
├── ILSVRC2012_devkit_t12.tar.gz
├── train/
└── val/
from mindspore import context
from mindvision.classification.dataset import ImageNet
context.set_context(mode=context.GRAPH_MODE, device_target='GPU')
data_url = './ImageNet/'
resize = 224
batch_size = 16
dataset_train = ImageNet(data_url,
split="train",
shuffle=True,
resize=resize,
batch_size=batch_size,
repeat_num=1,
num_parallel_workers=1).run()模型解析
下面将通过代码来细致剖析ViT模型的内部结构。
Transformer基本原理
Transformer模型源于2017年的一篇文章[2]。在这篇文章中提出的基于Attention机制的编码器-解码器型结构在自然语言处理领域获得了巨大的成功。模型结构如下图所示:
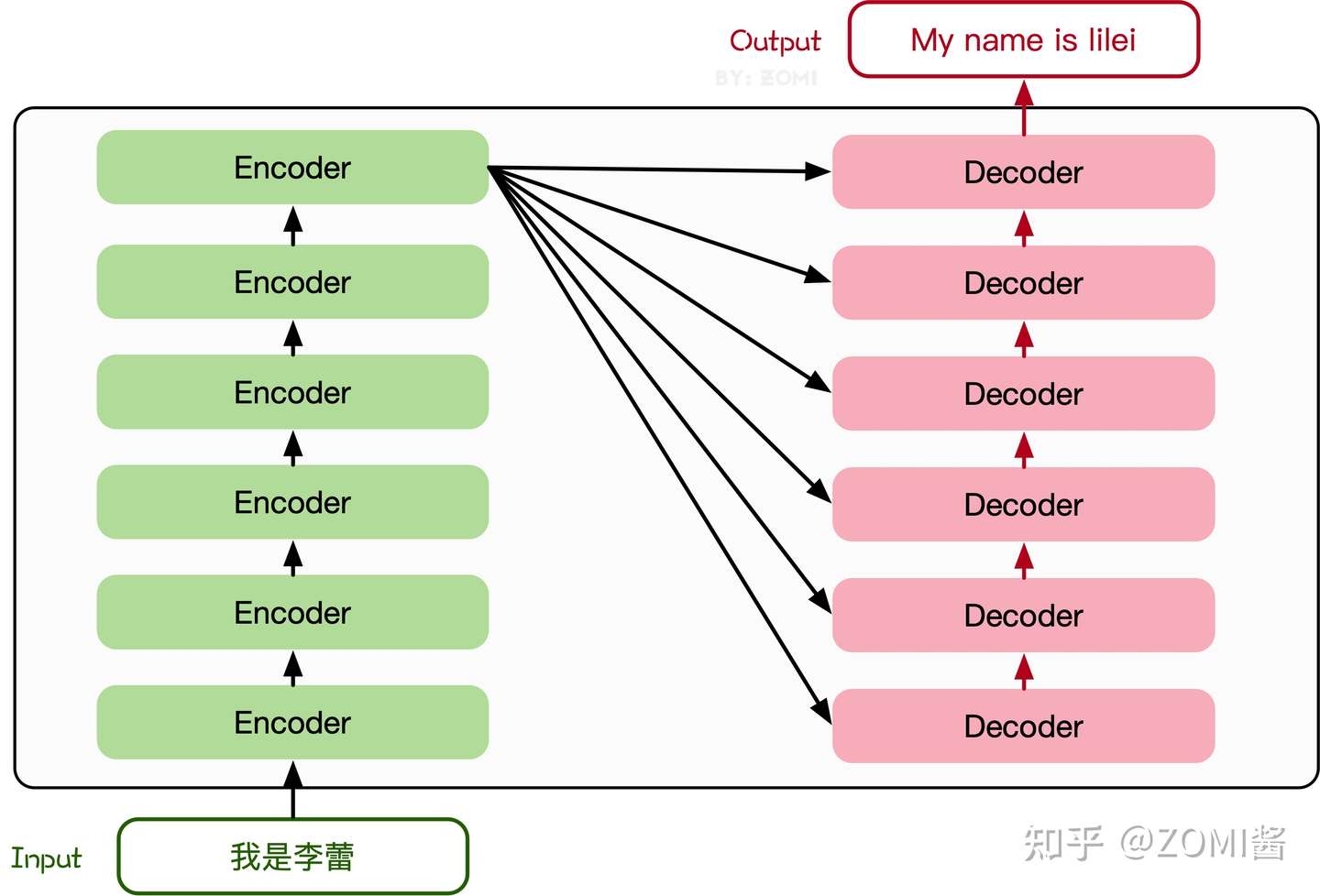
其主要结构为多个Encoder和Decoder模块所组成,其中Encoder和Decoder的详细结构如下图所示:
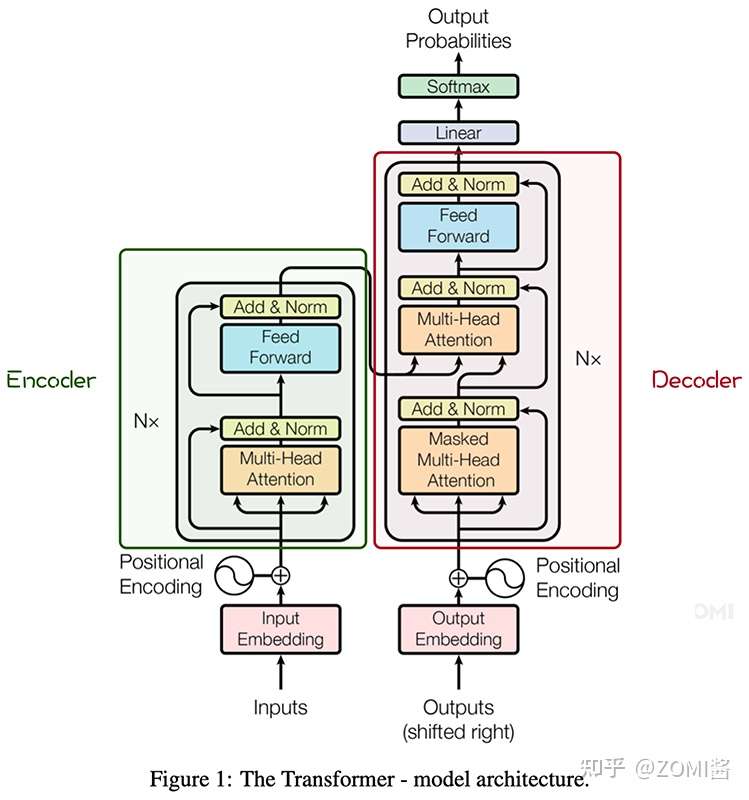
Encoder与Decoder由许多结构组成,如:多头注意力(Multi-Head Attention)层,Feed Forward层,Normaliztion层,甚至残差连接(Residual Connection,图中的“add”)。不过,其中最重要的结构是多头注意力(Multi-Head Attention)结构,该结构基于自注意力(Self-Attention)机制,是多个Self-Attention的并行组成。
所以,理解了Self-Attention就抓住了Transformer的核心。
Attention模块
以下是Self-Attention的解释,其核心内容是为输入向量的每个单词学习一个权重。通过给定一个任务相关的查询向量Query向量,计算Query和各个Key的相似性或者相关性得到注意力分布,即得到每个Key对应Value的权重系数,然后对Value进行加权求和得到最终的Attention数值。
在Self-Attention中:
- 最初的输入向量首先会经过Embedding层映射成Q(Query),K(Key),V(Value)三个向量,由于是并行操作,所以代码中是映射成为dim x 3的向量然后进行分割,换言之,如果你的输入向量为一个向量序列( 1x1 1x1, 2x2 2x2, 3x3 3x3),其中的 1x1 1x1, 2x2 2x2, 3x3 3x3都是一维向量,那么每一个一维向量都会经过Embedding层映射出Q,K,V三个向量,只是Embedding矩阵不同,矩阵参数也是通过学习得到的。这里大家可以认为,Q,K,V三个矩阵是发现向量之间关联信息的一种手段,需要经过学习得到,至于为什么是Q,K,V三个,主要是因为需要两个向量点乘以获得权重,又需要另一个向量来承载权重向加的结果,所以,最少需要3个矩阵,也是论文作者经过实验得出的结论。
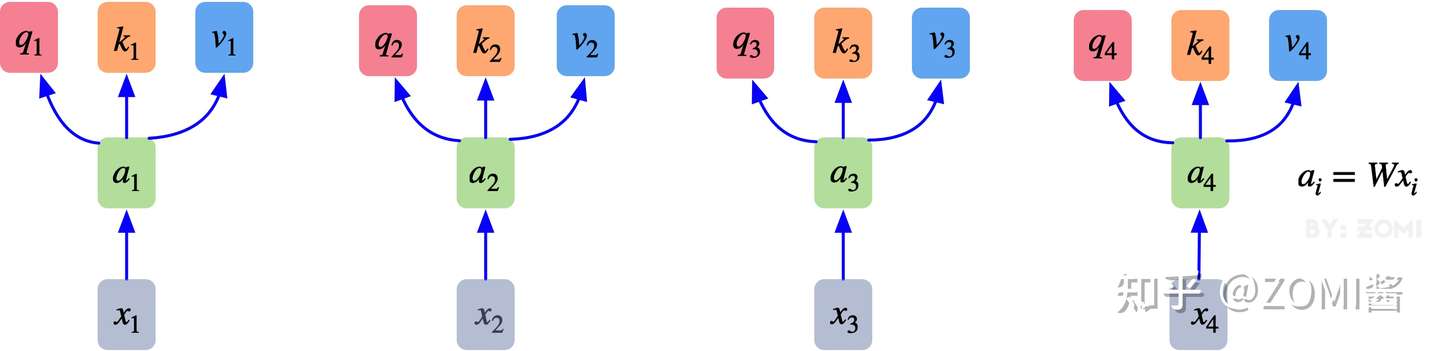
2. 自注意力机制的自注意主要体现在它的Q,K,V都来源于其自身,也就是该过程是在提取输入的不同顺序的向量的联系与特征,最终通过不同顺序向量之间的联系紧密性(Q与K乘积经过softmax的结果)来表现出来。Q,K,V得到后就需要获取向量间权重,需要对Q和K进行点乘并除以维度的平方根 ⎯⎯√d ⎯⎯√d,对所有向量的结果进行Softmax处理,通过公式(2)的操作,我们获得了向量之间的关系权重。
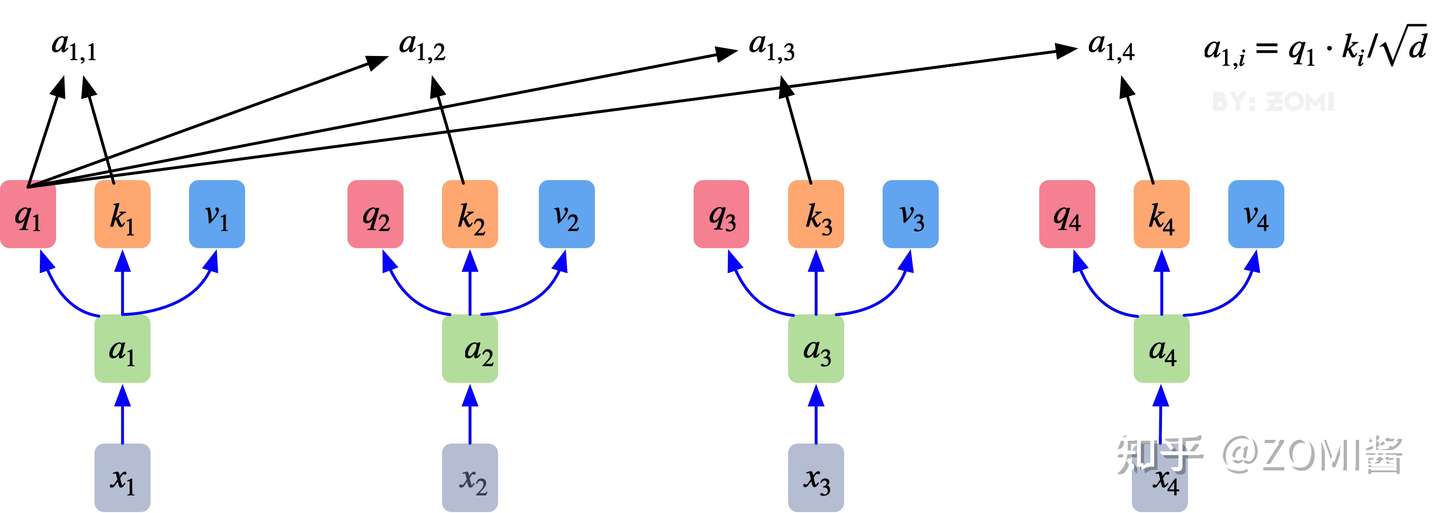

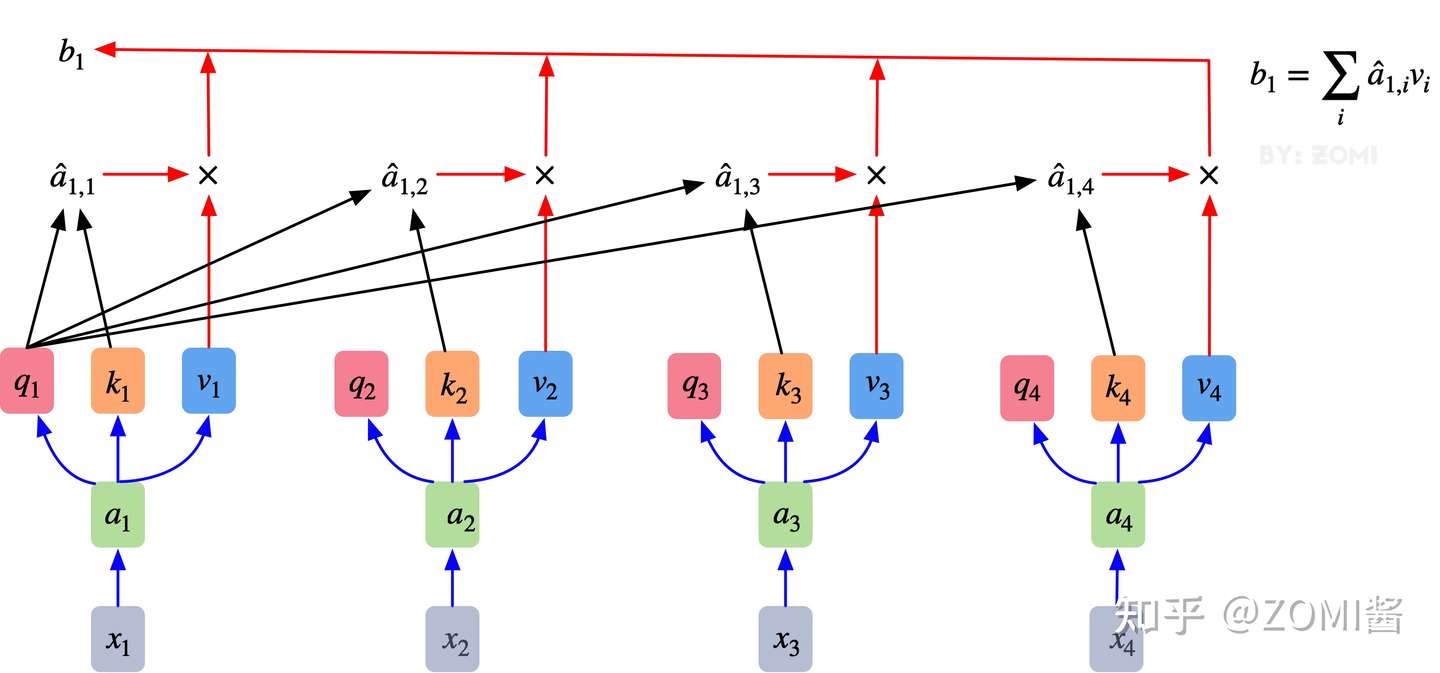
3.其最终输出则是通过V这个映射后的向量与QK经过Softmax结果进行weight sum获得,这个过程可以理解为在全局上进行自注意表示。每一组QKV最后都有一个V输出,这是Self-Attention得到的最终结果,是当前向量在结合了它与其他向量关联权重后得到的结果。
通过下图可以整体把握Self-Attention的全部过程。
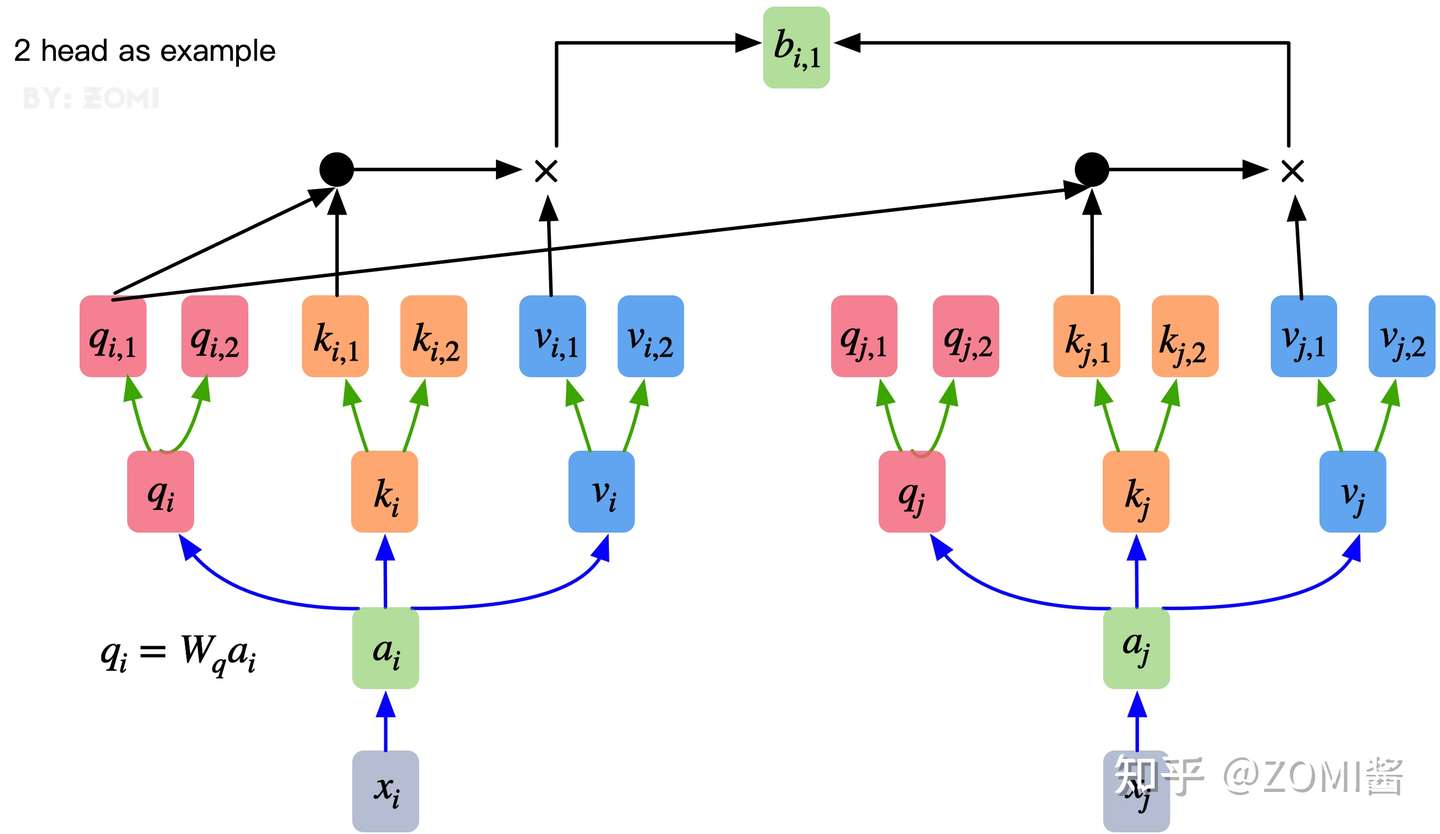
多头注意力机制就是将原本self-Attention处理的向量分割为多个Head进行处理,这一点也可以从代码中体现,这也是attention结构可以进行并行加速的一个方面。
总结来说,多头注意力机制在保持参数总量不变的情况下,将同样的query, key和value映射到原来的高维空间(Q,K,V)的不同子空间(Q_0,K_0,V_0)中进行自注意力的计算,最后再合并不同子空间中的注意力信息。
所以,对于同一个输入向量,多个注意力机制可以同时对其进行处理,即利用并行计算加速处理过程,又在处理的时候更充分的分析和利用了向量特征。下图展示了多头注意力机制,其并行能力的主要体现在下图中的$a_1$和$a_2$是同一个向量进行分割获得的。
以下是vision套件中的Multi-Head Attention代码,结合上文的解释,代码清晰的展现了这一过程。
import mindspore.nn as nn
class Attention(nn.Cell):
def __init__(self,
dim: int,
num_heads: int = 8,
keep_prob: float = 1.0,
attention_keep_prob: float = 1.0):
super(Attention, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = Tensor(head_dim ** -0.5)
self.qkv = nn.Dense(dim, dim * 3)
self.attn_drop = nn.Dropout(attention_keep_prob)
self.out = nn.Dense(dim, dim)
self.out_drop = nn.Dropout(keep_prob)
self.mul = P.Mul()
self.reshape = P.Reshape()
self.transpose = P.Transpose()
self.unstack = P.Unstack(axis=0)
self.attn_matmul_v = P.BatchMatMul()
self.q_matmul_k = P.BatchMatMul(transpose_b=True)
self.softmax = nn.Softmax(axis=-1)
def construct(self, x):
"""Attention construct."""
b, n, c = x.shape
# 最初的输入向量首先会经过Embedding层映射成Q(Query),K(Key),V(Value)三个向量
# 由于是并行操作,所以代码中是映射成为dim*3的向量然后进行分割
qkv = self.qkv(x)
#多头注意力机制就是将原本self-Attention处理的向量分割为多个Head进行处理
qkv = self.reshape(qkv, (b, n, 3, self.num_heads, c // self.num_heads))
qkv = self.transpose(qkv, (2, 0, 3, 1, 4))
q, k, v = self.unstack(qkv)
# 自注意力机制的自注意主要体现在它的Q,K,V都来源于其自身
# 也就是该过程是在提取输入的不同顺序的向量的联系与特征
# 最终通过不同顺序向量之间的联系紧密性(Q与K乘积经过softmax的结果)来表现出来
attn = self.q_matmul_k(q, k)
attn = self.mul(attn, self.scale)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# 其最终输出则是通过V这个映射后的向量与QK经过Softmax结果进行weight sum获得
# 这个过程可以理解为在全局上进行自注意表示
out = self.attn_matmul_v(attn, v)
out = self.transpose(out, (0, 2, 1, 3))
out = self.reshape(out, (b, n, c))
out = self.out(out)
out = self.out_drop(out)
return outTransformer Encoder
在了解了Self-Attention结构之后,通过与Feed Forward,Residual Connection等结构的拼接就可以形成Transformer的基础结构,接下来就利用Self-Attention来构建ViT模型中的TransformerEncoder部分,类似于构建了一个Transformer的编码器部分。
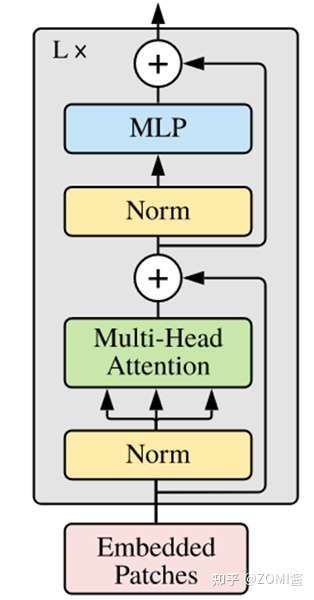
- ViT模型中的基础结构与标准Transformer有所不同,主要在于Normalization的位置是放在Self-Attention和Feed Forward之前,其他结构如Residual Connection,Feed Forward,Normalization都如Transformer中所设计。
- 从transformer结构的图片可以发现,多个子encoder的堆叠就完成了模型编码器的构建,在ViT模型中,依然沿用这个思路,通过配置超参数num_layers,就可以确定堆叠层数。
- Residual Connection,Normalization的结构可以保证模型有很强的扩展性(保证信息经过深层处理不会出现退化的现象,这是Residual Connection的作用),Normalization和dropout的应用可以增强模型泛化能力。
从以下源码中就可以清晰看到Transformer的结构。将TransformerEncoder结构和一个多层感知器(MLP)结合,就构成了ViT模型的backbone部分。
class TransformerEncoder(nn.Cell):
def __init__(self,
dim: int,
num_layers: int,
num_heads: int,
mlp_dim: int,
keep_prob: float = 1.,
attention_keep_prob: float = 1.0,
drop_path_keep_prob: float = 1.0,
activation: nn.Cell = nn.GELU,
norm: nn.Cell = nn.LayerNorm):
super(TransformerEncoder, self).__init__()
layers = []
# 从vit_architecture图可以发现,多个子encoder的堆叠就完成了模型编码器的构建
# 在ViT模型中,依然沿用这个思路,通过配置超参数num_layers,就可以确定堆叠层数
for _ in range(num_layers):
normalization1 = norm((dim,))
normalization2 = norm((dim,))
attention = Attention(dim=dim,
num_heads=num_heads,
keep_prob=keep_prob,
attention_keep_prob=attention_keep_prob)
feedforward = FeedForward(in_features=dim,
hidden_features=mlp_dim,
activation=activation,
keep_prob=keep_prob)
# ViT模型中的基础结构与标准Transformer有所不同
# 主要在于Normalization的位置是放在Self-Attention和Feed Forward之前
# 其他结构如Residual Connection,Feed Forward,Normalization都如Transformer中所设计
layers.append(
nn.SequentialCell([
# Residual Connection,Normalization的结构可以保证模型有很强的扩展性
# 保证信息经过深层处理不会出现退化的现象,这是Residual Connection的作用
# Normalization和dropout的应用可以增强模型泛化能力
ResidualCell(nn.SequentialCell([normalization1,
attention])),
ResidualCell(nn.SequentialCell([normalization2,
feedforward]))
])
)
self.layers = nn.SequentialCell(layers)
def construct(self, x):
"""Transformer construct."""
return self.layers(x)ViT模型的输入
传统的Transformer结构主要用于处理自然语言领域的词向量(Word Embedding or Word Vector),词向量与传统图像数据的主要区别在于,词向量通常是1维向量进行堆叠,而图片则是二维矩阵的堆叠,多头注意力机制在处理1维词向量的堆叠时会提取词向量之间的联系也就是上下文语义,这使得Transformer在自然语言处理领域非常好用,而2维图片矩阵如何与1维词向量进行转化就成为了Transformer进军图像处理领域的一个小门槛。
在ViT模型中:
- 通过将输入图像在每个channel上划分为1616个patch,这一步是通过卷积操作来完成的,当然也可以人工进行划分,但卷积操作也可以达到目的同时还可以进行一次而外的数据处理;*例如一幅输入224 x 224的图像,首先经过卷积处理得到16 x 16个patch,那么每一个patch的大小就是14 x 14。**
- 再将每一个patch的矩阵拉伸成为一个1维向量,从而获得了近似词向量堆叠的效果。上一步得道的14 x 14的patch就转换为长度为196的向量。
这是图像输入网络经过的第一步处理。具体Patch Embedding的代码如下所示:
class PatchEmbedding(nn.Cell):
MIN_NUM_PATCHES = 4
def __init__(self,
image_size: int = 224,
patch_size: int = 16,
embed_dim: int = 768,
input_channels: int = 3):
super(PatchEmbedding, self).__init__()
self.image_size = image_size
self.patch_size = patch_size
self.num_patches = (image_size // patch_size) ** 2
# 通过将输入图像在每个channel上划分为16*16个patch
self.conv = nn.Conv2d(input_channels, embed_dim, kernel_size=patch_size, stride=patch_size, has_bias=True)
self.reshape = P.Reshape()
self.transpose = P.Transpose()
def construct(self, x):
"""Path Embedding construct."""
x = self.conv(x)
b, c, h, w = x.shape
# 再将每一个patch的矩阵拉伸成为一个1维向量,从而获得了近似词向量堆叠的效果;
x = self.reshape(x, (b, c, h * w))
x = self.transpose(x, (0, 2, 1))
return x由论文中的模型结构可以得知,输入图像在划分为patch之后,会经过pos_embedding 和 class_embedding两个过程。
- class_embedding主要借鉴了BERT模型的用于文本分类时的思想,在每一个word vector之前增加一个类别值,通常是加在向量的第一位,上一步得到的196维的向量加上class_embedding后变为197维。
- 增加的class_embedding是一个可以学习的参数,经过网络的不断训练,最终以输出向量的第一个维度的输出来决定最后的输出类别;由于输入是16 x 16个patch,所以输出进行分类时是取 16 x 16个class_embedding进行分类。
- pos_embedding也是一组可以学习的参数,会被加入到经过处理的patch矩阵中。
- 由于pos_embedding也是可以学习的参数,所以它的加入类似于全链接网络和卷积的bias。这一步就是创造一个长度维197的可训练向量加入到经过class_embedding的向量中。
从论文中可以得到,pos_embedding总共有4中方案。但是经过作者的论证,只有加上pos_embedding和不加pos_embedding有明显影响,至于pos_embedding是1维还是2维对分类结果影响不大,所以,在我们的代码中,也是采用了1维的pos_embedding,由于class_embedding是加在pos_embedding之前,所以pos_embedding的维度会比patch拉伸后的维度加1。
总的而言,ViT模型还是利用了Transformer模型在处理上下文语义时的优势,将图像转换为一种“变种词向量”然后进行处理,而这样转换的意义在于,多个patch之间本身具有空间联系,这类似于一种“空间语义”,从而获得了比较好的处理效果。
整体构建ViT
以下代码构建了一个完整的ViT模型。
from typing import Optional
class ViT(nn.Cell):
def __init__(self,
image_size: int = 224,
input_channels: int = 3,
patch_size: int = 16,
embed_dim: int = 768,
num_layers: int = 12,
num_heads: int = 12,
mlp_dim: int = 3072,
keep_prob: float = 1.0,
attention_keep_prob: float = 1.0,
drop_path_keep_prob: float = 1.0,
activation: nn.Cell = nn.GELU,
norm: Optional[nn.Cell] = nn.LayerNorm,
pool: str = 'cls') -> None:
super(ViT, self).__init__()
self.patch_embedding = PatchEmbedding(image_size=image_size,
patch_size=patch_size,
embed_dim=embed_dim,
input_channels=input_channels)
num_patches = self.patch_embedding.num_patches
# 此处增加class_embedding和pos_embedding,如果不是进行分类任务
# 可以只增加pos_embedding,通过pool参数进行控制
self.cls_token = init(init_type=Normal(sigma=1.0),
shape=(1, 1, embed_dim),
dtype=ms.float32,
name='cls',
requires_grad=True)
# pos_embedding也是一组可以学习的参数,会被加入到经过处理的patch矩阵中
self.pos_embedding = init(init_type=Normal(sigma=1.0),
shape=(1, num_patches + 1, embed_dim),
dtype=ms.float32,
name='pos_embedding',
requires_grad=True)
# axis=1定义了会在向量的开头加入class_embedding
self.concat = P.Concat(axis=1)
self.pool = pool
self.pos_dropout = nn.Dropout(keep_prob)
self.norm = norm((embed_dim,))
self.tile = P.Tile()
self.transformer = TransformerEncoder(dim=embed_dim,
num_layers=num_layers,
num_heads=num_heads,
mlp_dim=mlp_dim,
keep_prob=keep_prob,
attention_keep_prob=attention_keep_prob,
drop_path_keep_prob=drop_path_keep_prob,
activation=activation,
norm=norm)
def construct(self, x):
"""ViT construct."""
x = self.patch_embedding(x)
# class_embedding主要借鉴了BERT模型的用于文本分类时的思想
# 在每一个word vector之前增加一个类别值,通常是加在向量的第一位
cls_tokens = self.tile(self.cls_token, (x.shape[0], 1, 1))
x = self.concat((cls_tokens, x))
x += self.pos_embedding
x = self.pos_dropout(x)
x = self.transformer(x)
x = self.norm(x)
# 增加的class_embedding是一个可以学习的参数,经过网络的不断训练
# 最终以输出向量的第一个维度的输出来决定最后的输出类别;
x = x[:, 0]
return x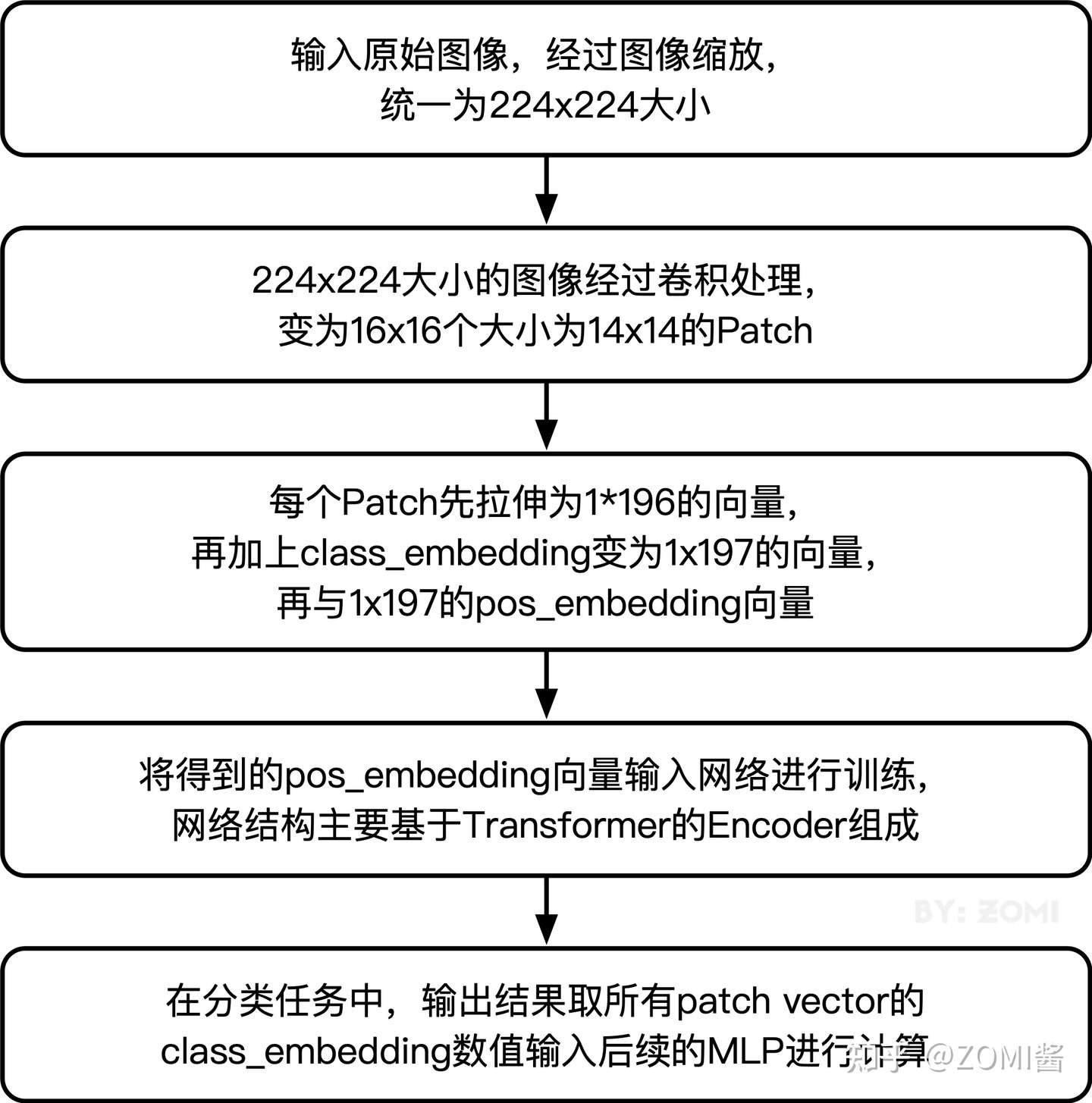
模型训练与推理
模型训练
模型开始训练前,需要设定损失函数,优化器,回调函数等,直接调用mindvision提供的接口可以方便完成实例化。
import mindspore.nn as nn
from mindspore.train import Model
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig
from mindvision.classification.models import vit_b_16
from mindvision.engine.callback import LossMonitor
from mindvision.engine.loss import CrossEntropySmooth
# 定义超参数
epoch_size = 10
momentum = 0.9
step_size = dataset_train.get_dataset_size()
num_classes = 1000
# 构建模型
network = vit_b_16(num_classes=num_classes, image_size=resize, pretrained=True)
# 定义递减的学习率
lr = nn.cosine_decay_lr(min_lr=float(0),
max_lr=0.003,
total_step=epoch_size * step_size,
step_per_epoch=step_size,
decay_epoch=90)
# 定义优化器
network_opt = nn.Adam(network.trainable_params(), lr, momentum)
# 定义损失函数
network_loss = CrossEntropySmooth(sparse=True,
reduction="mean",
smooth_factor=0.1,
classes_num=num_classes)
# 设定checkpoint
ckpt_config = CheckpointConfig(save_checkpoint_steps=step_size, keep_checkpoint_max=100)
ckpt_callback = ModelCheckpoint(prefix='vit_b_16', directory='./ViT', config=ckpt_config)
# 初始化模型
model = Model(network, loss_fn=network_loss, optimizer=network_opt, metrics={"acc"})
# 训练
model.train(epoch_size,
dataset_train,
callbacks=[ckpt_callback, LossMonitor(lr)],
dataset_sink_mode=False)结果:
Epoch:[ 0/ 10], step:[ 1/80072], loss:[1.963/1.963], time:8171.241 ms, lr:0.00300
Epoch:[ 0/ 10], step:[ 2/80072], loss:[7.809/4.886], time:769.321 ms, lr:0.00300
Epoch:[ 0/ 10], step:[ 3/80072], loss:[8.851/6.208], time:779.355 ms, lr:0.00300
....
Epoch:[ 9/ 10], step:[80070/80072], loss:[1.112/6.657], time:780.714 ms, lr:0.00240
Epoch:[ 9/ 10], step:[80071/80072], loss:[1.111/6.708], time:781.860 ms, lr:0.00240
Epoch:[ 9/ 10], step:[80072/80072], loss:[1.102/6.777], time:782.859 ms, lr:0.00240模型验证
模型验证过程主要应用了nn,Model,context,ImageNet,CrossEntropySmooth和vit_b_16等接口。
通过改变ImageNet接口的split参数即可调用验证集。
与训练过程相似,首先调用vit_b_16接口定义网络结构,加载预训练模型参数。随后设置损失函数,评价指标等,编译模型后进行验证。
dataset_analyse = ImageNet(data_url,
split="val",
num_parallel_workers=1,
resize=resize,
batch_size=batch_size)
dataset_eval = dataset_analyse.run()
network = vit_b_16(num_classes=num_classes, image_size=resize, pretrained=True)
network_loss = CrossEntropySmooth(sparse=True,
reduction="mean",
smooth_factor=0.1,
classes_num=num_classes)
# 定义评价指标
eval_metrics = {'Top_1_Accuracy': nn.Top1CategoricalAccuracy(),
'Top_5_Accuracy': nn.Top5CategoricalAccuracy()}
model = Model(network, network_loss, metrics=eval_metrics)
# 评估模型
result = model.eval(dataset_eval)
print(result)结果:
{'Top_1_Accuracy': 0.73524, 'Top_5_Accuracy': 0.91756}模型推理
在进行模型推理之前,首先要定义一个对推理图片进行数据预处理的方法。该方法可以对我们的推理图片进行resize和normalize处理,这样才能与我们训练时的输入数据匹配。
import mindspore.dataset.vision.c_transforms as transforms
# 数据预处理操作
def infer_transform(dataset, columns_list, resize):
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
trans = [transforms.Decode(),
transforms.Resize([resize, resize]),
transforms.Normalize(mean=mean, std=std),
transforms.HWC2CHW()]
dataset = dataset.map(operations=trans,
input_columns=columns_list[0],
num_parallel_workers=1)
dataset = dataset.batch(1)
return dataset接下来,我们将调用模型的predict方法进行模型推理,需要注意的是,推理图片需要自备,同时给予准确的路径利用read_dataset接口读推理图片路径,利用GeneratorDataset来生成测试集。
在推理过程中,ImageNet接口主要负责对原数据集标签和模型输出进行配对。通过index2label就可以获取对应标签,再通过show_result接口将结果写在对应图片上。
import numpy as np
import mindspore.dataset as ds
from mindspore import Tensor
from mindvision.dataset.generator import DatasetGenerator
from mindvision.dataset.download import read_dataset
from mindvision.classification.utils.image import show_result
# 读取推理图片
image_list, image_label = read_dataset('./infer')
columns_list = ('image', 'label')
dataset_infer = ds.GeneratorDataset(DatasetGenerator(image_list, image_label),
column_names=list(columns_list),
num_parallel_workers=1)
dataset_infer = infer_transform(dataset_infer, columns_list, resize)
# 读取数据进行推理
for i, image in enumerate(dataset_infer.create_dict_iterator(output_numpy=True)):
image = image["image"]
image = Tensor(image)
prob = model.predict(image)
label = np.argmax(prob.asnumpy(), axis=1)
predict = dataset_analyse.index2label[int(label)]
output = {int(label): predict}
print(output)
show_result(img=image_list[i], result=output, out_file=image_list[i])结果:
{236: 'Doberman'}推理过程完成后,在推理文件夹下可以找到图片的推理结果,如下图所示:

总结
本案例完成了一个ViT模型在ImageNet数据上进行训练,验证和推理的过程,其中,对关键的ViT模型结构和原理作了讲解。通过学习本案例,理解源码可以帮助学员掌握Multi-Head Attention,TransformerEncoder,pos_embedding等关键概念,如果要详细理解ViT的模型原理,建议基于源码更深层次的详细阅读,可以参考vision套件:
https://gitee.com/mindspore/vision/tree/master/examples/classification/vit 。
引用
[1] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).
[2] Vaswani, Ashish, et al. "Attention is all you need."Advances in Neural Information Processing Systems. (2017).
标签:Transformer,nn,Vision,self,num,MindSpore,模型,向量,size 来源: https://www.cnblogs.com/ZOMI/p/16266358.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。