标签:瓶颈 ACM RTT 拥塞 gain BtlBw 2017 BBR
转载 https://arthurchiao.art/blog/bbr-paper-zh/
[论文] BBR:基于拥塞(而非丢包)的拥塞控制(ACM, 2017)
译者序
本文翻译自 Google 2017 的论文:
Cardwell N, Cheng Y, Gunn CS, Yeganeh SH, Jacobson V. BBR: congestion-based congestion control. Communications of the ACM. 2017 Jan 23;60(2):58-66.
论文副标题:Measuring Bottleneck Bandwidth and Round-trip propagation time(测量瓶颈带宽和往返传输时间)。
BBR 之前,主流的 TCP 拥塞控制算法都是基于丢包(loss-based)设计的, 这一假设最早可追溯到上世纪八九十年代,那时的链路带宽和内存容量分别以 Mbps 和 KB 计,链路质量(以今天的标准来说)也很差。
三十年多后,这两个物理容量都已经增长了至少六个数量级,链路质量也不可同日而语。特别地,在现代基础设施中, 丢包和延迟不一定表示网络发生了拥塞,因此原来的假设已经不再成立。 Google 的网络团队从这一根本问题出发,(在前人工作的基础上) 设计并实现了一个基于拥塞本身而非基于丢包或延迟的拥塞控制新算法,缩写为 BBR。
简单来说,BBR 通过应答包(ACK)中的 RTT 信息和已发送字节数来计算 真实传输速率(delivery rate),然后根据后者来调节客户端接下来的 发送速率(sending rate),通过保持合理的 inflight 数据量来使 传输带宽最大、传输延迟最低。另外,它完全运行在发送端,无需协议、 接收端或网络的改动,因此落地相对容易。
Google 的全球广域网(B4)在 2016 年就已经将全部 TCP 流量从 CUBIC 切换到 BBR, 吞吐提升了 2~25 倍;在做了一些配置调优之后,甚至进一步提升到了 133 倍(文中有详细介绍)。
Linux 实现:
include/uapi/linux/inet_diag.hnet/ipv4/tcp_bbr.c
翻译时适当加入了一些小标题,另外插入了一些内核代码片段(基于内核 5.10),以更方便理解。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
- 译者序
- 1 拥塞和瓶颈(Congestion and Bottlenecks)
- 2 瓶颈的数学表示(Characterizing the Bottleneck)
- 3 使数据流(Packet Flow)与传输路径(Delivery Path)相匹配
- 4 BBR Flow 行为
- 5 部署经验
- 6 问题讨论
- 7 总结
- 致谢
- 附录:详细描述References
从各方面来说,今天的互联网传输数据的速度都不甚理想:
- 大部分移动用户都在忍受数秒乃至数分钟的延迟;
- 机场和大会场馆的共享 WIFI 信号一般都很差;
- 物理和气候学家需要与全球合作者交换 PB 级的数据,最后却发现精心设计的 Gbps 基础设施在跨大洲通信时带宽经常只能达到 Mbps6。
这些问题是由 TCP 的设计导致的 —— 20 世纪 80 年代设计 TCP 拥塞控制(congestion control) 时,认为丢包是发生了“拥塞”13。 在当时的技术条件下我们可以这样认为,但它并非第一原则 (technology limitations, not first principles)。随着网卡从 Mbps 到 Gbps、 内存从 KB 到 GB,丢包和拥塞之间的关系也变得愈发微弱。
今天,TCP 那些基于丢包的拥塞控制(loss-based congestion control) —— 即使是目前其中最好的 CUBIC11 —— 是导致这些问题的主要原因。
- 链路瓶颈处的 buffer 很大时,这类算法会持续占满整个缓冲区,导致 bufferbloat;
- 链路瓶颈处的 buffer 很小时,这类算法又会误将丢包当作拥塞的信号,导致吞吐很低。
解决这些问题需要一种全新的方式,而这首先需要对以下两点有深入理解:
- 拥塞会发生哪里(where)
- 拥塞是如何发生的(how)
1 拥塞和瓶颈(Congestion and Bottlenecks)
1.1 两个物理特性:传输时延(RTprop)和瓶颈带宽(BtlBw)
对于一个(全双工)TCP 连接,在任意时刻,它在每个方向都有且只有一段最慢的链路 (exactly one slowest link)或称瓶颈(bottleneck)。这一点很重要,因为:
-
瓶颈决定了连接的最大数据传输速率。这是不可压缩流(incompressible flow)的一个常规特性。
例如,考虑交通高峰期的一个六车道高速公路,一起交通事故使其中一段变成了单车道, 那么这整条高速公路的吞吐就不会超过那条唯一还在正常通车的车道的吞吐。
-
瓶颈也是持久队列(persistent queues)形成的地方。
对于一条链路,只有当它的离开速率(departure rate)大于到达速率(arrival rate)时,这个队列才会开始收缩。对于一条有多段链路、运行在最大传输速率的连 接(connection),除瓶颈点之外的地方都有更大的离开速率,因此队列会朝着瓶颈 移动(migrate to the bottleneck)。
不管一条连接会经过多少条链路,以及每条链路的速度是多少,从 TCP 的角度来看, 任何一条复杂路径的行为,与 RTT(round-trip time)及瓶颈速率相同的单条链路的行为是一样的。 换句话说,以下两个物理特性决定了传输的性能:
RTprop(round-trip propagation time):往返传输时间BtlBw(bottleneck bandwidth):瓶颈带宽
如果网络路径是一条物理管道,那 RTprop 就是管道的长度,而 BtlBw 则是管道最窄处的直径。
1.2 传输时延/瓶颈带宽与 inflight 数据量的关系
图 1 展示了 inflight 数据量(已发送但还未被确认的数据量)不断增大时, RTT 和传输速率(delivery rate)的变化情况:
直观上,这张图想解释的是:随着正在传输中的数据的不断增多,传输延迟和传输速率将如何变化。 难点在于二者并没有简单的关系可以表示。不仅如此,后文还将看到二者甚至不可同 时测量 —— 就像量子力学中位置和动量不可同时测量。 译注。
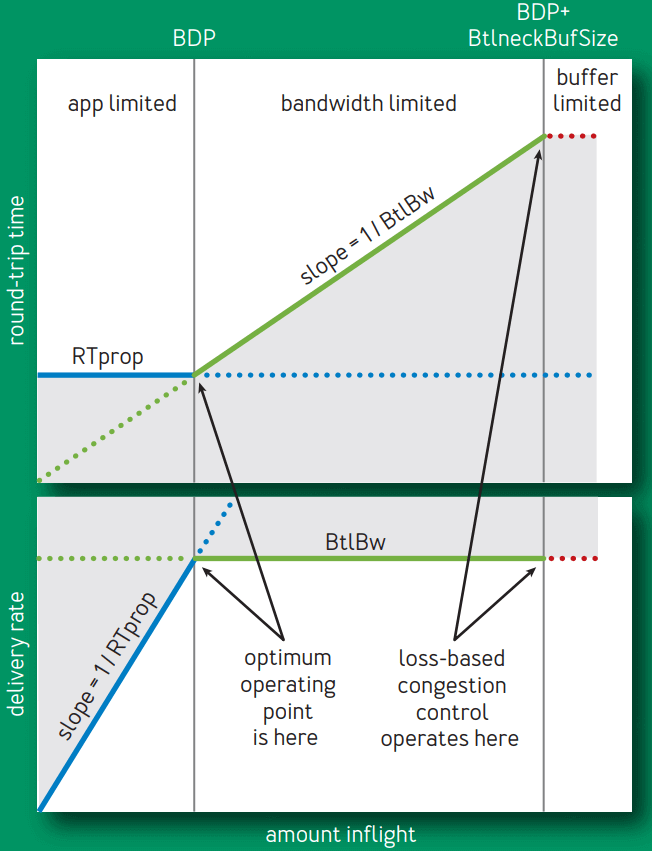
Fig 1. Delivery rate and RTT vs. inflight data
- 蓝线展示 RTprop 限制,
- 绿线展示 BtlBw 限制,
- 红线是瓶颈缓冲区(bottleneck buffer)
横轴表示 inflight 数据量,关键的点有三个,依次为 0 -> BDP -> BDP+BtlneckBuffSize, 后两个点做垂线,将整个空间分为了三个部分:
(0, BDP):这个区间内,应用(客户端)发送的数据并未占满瓶颈带宽(容量),因此称为 应用受限(app limited)区域;(BDP, BDP+BtlneckBuffSize):这个区间内,已经达到链路瓶颈容量,但还未超过 瓶颈容量+缓冲区容量,此时应用能发送的数据量主要受带宽限制, 因此称为带宽受限(bandwidth limited)区域;(BDP+BtlneckBuffSize, infinity):这个区间内,实际发送速率已经超过瓶颈容量+缓冲区容量 ,多出来的数据会被丢弃,缓冲区大小决定了丢包多少,因此称为缓冲区受限(buffer limited)区域。
以上三者,也可以更直白地称为应用不足、带宽不足、缓冲区不足区域。 译注。
1.3 以上关系的进一步解释
我们来更具体地看一下传输时延(RTprop)和瓶颈带宽(BtlBw)与与 inflight 数据量呈现以上关系:
-
inflight 数据量在
0 -> BDP区间内时,发送的数据还未达到瓶颈容量,此时,- 往返时间不变:对应上半部分图,因为此时还未达到瓶颈带宽,链路不会随数据量增加而带来额外延迟;
- 传输速率线性增大:对应下半部分图;
因此,这个阶段的行为由 RTprop 决定。
-
inflight 数据量刚好等于
BDP时,- 两条限制线相交的点称为 BDP 点,这也是 BDP(bandwidth-delay product,带宽-延迟乘积)这个名称的由来;
- 此时可以算出:
inflight = BtlBw × RTprop;
-
inflight 大于
BDP之后,管道就满了(超过瓶颈带宽)- 超过瓶颈带宽的数据就会形成一个队列(queue),堆积在链路瓶颈处,然后
- RTT 将随着 inflight 数据的增加而线性增加,如上半部分图所示。
-
inflight 继续增大,超过
BDP+BtlneckBuffSize之后,即超过链路瓶颈所支持的最大缓冲区之后,就开始丢包。
灰色区域是不可达的,因为它违反了至少其中一个限制。限制条件的不同导致了三个可行区域 (app-limited, bandwidth-limited, and buffer-limited)各自有不同的行为。
1.4 拥塞和拥塞控制的直观含义
再次给出图 1,
Fig 1. Delivery rate and RTT vs. inflight data
直观上来说, 拥塞(congestion)就是 inflight 数据量持续向右侧偏离 BDP 线的行为, 而拥塞控制(congestion control)就是各种在平均程度上控制这种偏离程度的方案或算法。
1.5 基于丢包的拥塞控制工作机制
基于丢包的拥塞控制工作在 bandwidth-limited 区域的右侧,依靠:
- 很高的延迟,以及
- 频繁的丢包
将连接的传输速率维持在全速瓶颈带宽(full bottleneck bandwidth)。
- 在内存很贵的年代,瓶颈链路的缓冲区只比 BDP 略大,这使得 基于丢包的拥塞控制导致的额外延迟很小;
- 随着内存越来越便宜,缓冲区已经比 ISP 链路的 BDP 要大上几个数量级了, 其结果是,bufferbloat 导致的 RTT 达到了秒级,而不再是毫秒级9。
1.6 更好的工作机制及存在的挑战
Bandwidth-limited 区域的左侧边界是比右侧更好的一个拥塞控制点。
- 1979 年,Leonard Kleinrock16 证明了这个点是最优的, 能最大化传输速率、最小化延迟和丢包,不管是对于单个连接还是整个网络8。
- 不幸的是,大约在同一时间,Jeffrey M. Jaffe14 证明了 不存在能收敛到这个点的分布式算法。这个结果使得研究方向从寻找一个能达到 Kleinrock 最佳工作点(operating point)的分布式算法,转向了对不同拥塞控制方式的研究。
在 Google,我们团队每天都会花数小时来分析从世界各地收集上来的 TCP 包头, 探究各种异常和反常现象背后的意义。
- 第一步通常是寻找基本的路径特性 RTprop 和 BtlBw。
- 能从跟踪信息中拿到这些数据这一事实,说明 Jaffe 的结论可能并没有看上去那么悲观。 Jaffe 的结果在本质上具有测量模糊性(fundamental measurement ambiguities),例 如,测量到的 RTT 增加是由于路径长度变化导致的,还是瓶颈带宽变小导致的,还是另 一个连接的流量积压、延迟增加导致的。
- 虽然无法让任何单个测量参数变得很精确,但一个连接随着时间变化的行为 还是能清晰地反映出某些东西,也预示着用于解决这种模糊性的测量策略是可行的。
1.7 BBR:基于对两个参数(RTprop、BtlBw)的测量实现拥塞控制
组合这些测量指标(measurements),再引入一个健壮的伺服系统 (基于控制系统领域的近期进展) 12,我们便得到一个能针对对真实拥塞 —— 而非丢包或延迟 —— 做出反应的 分布式拥塞控制协议,能以很大概率收敛到 Kleinrock 的最优工作点。
我们的三年努力也正是从这里开始:试图基于对如下刻画一条路径的两个参数的测量, 来实现一种拥塞控制机制,
- 瓶颈带宽(Bottleneck Bandwidth)
- 往返传输时间(Round-trip propagation time)
2 瓶颈的数学表示(Characterizing the Bottleneck)
2.1 最小化缓冲区积压(或最高吞吐+最低延迟)需满足的条件
当一个连接满足以下两个条件时,它将运行在最高吞吐和最低延迟状态:
-
速率平衡(rate balance):瓶颈链路的数据包到达速率刚好等于瓶颈带宽
BtlBw,这个条件保证了链路瓶颈已达到 100% 利用率。
-
管道填满(full pipe):传输中的总数据(inflight)等于 BDP(
= BtlBw × RTprop)。这个条件保证了有恰好足够的数据,既不会产生瓶颈饥饿(bottleneck starvation), 又不会产生管道溢出(overfill the pipe)。
需要注意,
-
仅凭 rate balance 一个条件并不能确保没有积压。
例如,某个连接在一个 BDP=5 的链路上,开始时它发送了 10 个包组成的 Initial Window,之后就一直稳定运行在瓶颈速率上。那么,在这个链路此后的行为就是:
- 稳定运行在瓶颈速率上
- 稳定有 5 个包的积压(排队)
-
类似地,仅凭 full pipe 一个条件也无法确保没有积压。
例如,如果某个连接以
BDP/2的突发方式发送一个 BDP 的数据, 那仍然能达到瓶颈利用率,但却会产生平均 BDP/4 的瓶颈积压。
在链路瓶颈以及整条路径上最小化积压的唯一方式是同时满足以上两个条件。
2.2 无偏估计(unbiased estimator)
下文会提到“无偏估计”这个统计学术语,这里先科普下:
In statistics, the bias (or bias function) of an estimator is the difference between this estimator’s expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased.
Wikipedia: Bias of an estimator
译注。
2.3 传输时延(RTProp)的表示与估计
BtlBw 和 RTprop 在一个连接的生命周期中是不断变化的,因此必须持续对它们做出估计(estimation)。
TCP 目前跟踪了 RTT(从发送一段数据到这段数据被确认接收的时间) ,因为检测是否有丢包要用到这个参数。在任意时刻 t,
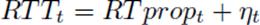
其中
标签:瓶颈,ACM,RTT,拥塞,gain,BtlBw,2017,BBR 来源: https://www.cnblogs.com/haoee/p/16209818.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。