标签:Flink org flink page id CEP apache import 访客
1.访客跳出明细介绍
首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来。那么就要抓住几个特征:
该页面是用户近期访问的第一个页面,这个可以通过该页面是否有上一个页面(last_page_id)来判断,如果这个表示为空,就说明这是这个访客这次访问的第一个页面。
首次访问之后很长一段时间(自己设定),用户没继续再有其他页面的访问。
这第一个特征的识别很简单,保留 last_page_id 为空的就可以了。但是第二个访问的判断,其实有点麻烦,首先这不是用一条数据就能得出结论的,需要组合判断,要用一条存在的数据和不存在的数据进行组合判断。而且要通过一个不存在的数据求得一条存在的数据。更麻烦的他并不是永远不存在,而是在一定时间范围内不存在。那么如何识别有一定失效的组合行为呢?
最简单的办法就是 Flink 自带的 CEP 技术。这个 CEP 非常适合通过多条数据组合来识别某个事件。
用户跳出事件,本质上就是一个条件事件加一个超时事件的组合。
-
流程图
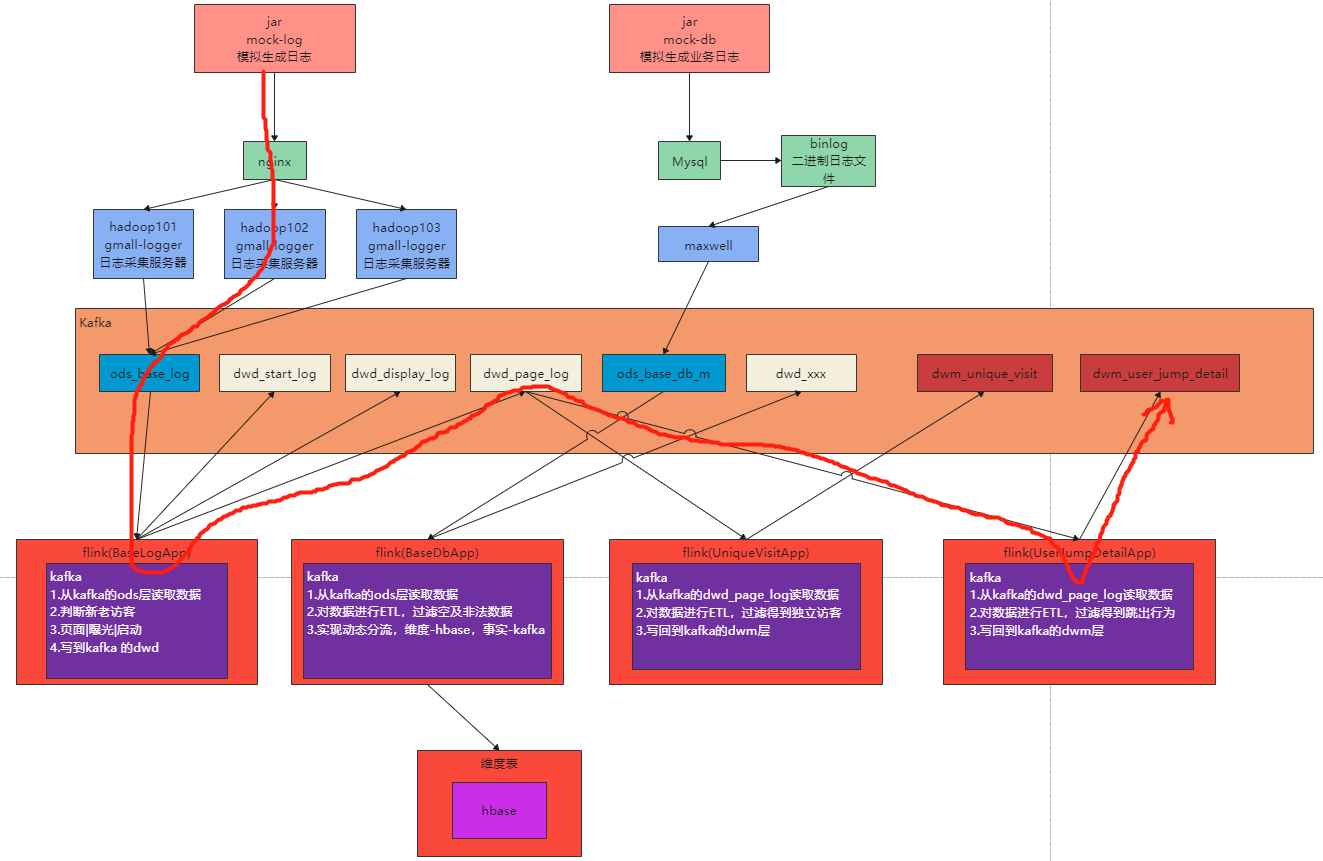
2.代码实现
创建任务类UserJumpDetailApp.java,从kafka读取页面日志
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* @author zhangbao
* @date 2021/10/17 10:38
* @desc
*/
public class UserJumpDetailApp {
public static void main(String[] args) {
//webui模式,需要添加pom依赖
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// StreamExecutionEnvironment env1 = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
// env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60000);
// env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/userJumpDetail"));
// //指定哪个用户读取hdfs文件
// System.setProperty("HADOOP_USER_NAME","zhangbao");
//从kafka读取数据源
String sourceTopic = "dwd_page_log";
String group = "user_jump_detail_app_group";
String sinkTopic = "dwm_user_jump_detail";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, group);
DataStreamSource<String> kafkaDs = env.addSource(kafkaSource);
kafkaDs.print("user jump detail >>>");
try {
env.execute("user jump detail task");
} catch (Exception e) {
e.printStackTrace();
}
}
}3. flink CEP编程
官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.12/dev/libs/cep.html
处理流程
1.从kafka读取日志数据
2.设定时间语义为事件时间并指定事件时间字段ts
3.按照mid分组
4.配置CEP表达式
-
1.第一次访问的页面:last_page_id == null
-
2.第一次访问的页面在10秒内,没有进行其他操作,没有访问其他页面
5.根据表达式筛选流
6.提取命中的数据
-
设定超时时间标识 timeoutTag
-
flatSelect 方法中,实现 PatternFlatTimeoutFunction 中的 timeout 方法。
-
所有 out.collect 的数据都被打上了超时标记
-
本身的 flatSelect 方法因为不需要未超时的数据所以不接受数据。
-
通过 SideOutput 侧输出流输出超时数据
7.将跳出数据写回到kafka
package com.zhangbao.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkGenerator;
import org.apache.flink.api.common.eventtime.WatermarkGeneratorSupplier;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternFlatSelectFunction;
import org.apache.flink.cep.PatternFlatTimeoutFunction;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.List;
import java.util.Map;
/**
* @author zhangbao
* @date 2021/10/17 10:38
* @desc
*/
public class UserJumpDetailApp {
public static void main(String[] args) {
//webui模式,需要添加pom依赖
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// StreamExecutionEnvironment env1 = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
// env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60000);
// env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/userJumpDetail"));
// //指定哪个用户读取hdfs文件
// System.setProperty("HADOOP_USER_NAME","zhangbao");
//从kafka读取数据源
String sourceTopic = "dwd_page_log";
String group = "user_jump_detail_app_group";
String sinkTopic = "dwm_user_jump_detail";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, group);
DataStreamSource<String> jsonStrDs = env.addSource(kafkaSource);
/*//测试数据
DataStream<String> jsonStrDs = env
.fromElements(
"{\"common\":{\"mid\":\"101\"},\"page\":{\"page_id\":\"home\"},\"ts\":10000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"home\"},\"ts\":12000}",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"home\"},\"ts\":15000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"detail\"},\"ts\":30000} "
);
dataStream.print("in json:");*/
//对读取到的数据进行结构转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = jsonStrDs.map(jsonStr -> JSON.parseObject(jsonStr));
// jsonStrDs.print("user jump detail >>>");
//从flink1.12开始,时间语义默认是事件时间,不需要额外指定,如果是之前的版本,则要按以下方式指定事件时间语义
//env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//指定事件时间字段
SingleOutputStreamOperator<JSONObject> jsonObjWithTSDs = jsonObjDs.assignTimestampsAndWatermarks(
WatermarkStrategy.<JSONObject>forMonotonousTimestamps().withTimestampAssigner(
new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject jsonObject, long l) {
return jsonObject.getLong("ts");
}
}
));
//按照mid分组
KeyedStream<JSONObject, String> ketByDs = jsonObjWithTSDs.keyBy(
jsonObject -> jsonObject.getJSONObject("common").getString("mid")
);
/**
* flink CEP表达式
* 跳出规则,满足两个条件:
* 1.第一次访问的页面:last_page_id == null
* 2.第一次访问的页面在10秒内,没有进行其他操作,没有访问其他页面
*/
Pattern<JSONObject, JSONObject> pattern = Pattern.<JSONObject>begin("first")
.where( // 1.第一次访问的页面:last_page_id == null
new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id");
System.out.println("first page >>> "+lastPageId);
if (lastPageId == null || lastPageId.length() == 0) {
return true;
}
return false;
}
}
).next("next")
.where( //2.第一次访问的页面在10秒内,没有进行其他操作,没有访问其他页面
new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
String pageId = jsonObject.getJSONObject("page").getString("page_id");
System.out.println("next page >>> "+pageId);
if(pageId != null && pageId.length()>0){
return true;
}
return false;
}
}
//时间限制模式,10S
).within(Time.milliseconds(10000));
//将cep表达式运用到流中,筛选数据
PatternStream<JSONObject> patternStream = CEP.pattern(ketByDs, pattern);
//从筛选的数据中再提取数据超时数据,放到侧输出流中
OutputTag<String> timeOutTag = new OutputTag<String>("timeOut"){};
SingleOutputStreamOperator<Object> outputStreamDS = patternStream.flatSelect(
timeOutTag,
//获取超时数据
new PatternFlatTimeoutFunction<JSONObject, String>() {
@Override
public void timeout(Map<String, List<JSONObject>> map, long l, Collector<String> collector) throws Exception {
List<JSONObject> first = map.get("first");
for (JSONObject jsonObject : first) {
System.out.println("time out date >>> "+jsonObject.toJSONString());
//所有 out.collect 的数据都被打上了超时标记
collector.collect(jsonObject.toJSONString());
}
}
},
//获取未超时数据
new PatternFlatSelectFunction<JSONObject, Object>() {
@Override
public void flatSelect(Map<String, List<JSONObject>> map, Collector<Object> collector) throws Exception {
//不超时的数据不提取,所以这里不做操作
}
}
);
//获取侧输出流的超时数据
DataStream<String> timeOutDs = outputStreamDS.getSideOutput(timeOutTag);
timeOutDs.print("jump >>> ");
//将跳出数据写回到kafka
timeOutDs.addSink(MyKafkaUtil.getKafkaSink(sinkTopic));
try {
env.execute("user jump detail task");
} catch (Exception e) {
e.printStackTrace();
}
}
}
测试数据
将从kafka读取数据的方式切换成固定数据内容,如下:
//测试数据
DataStream<String> jsonStrDs = env
.fromElements(
"{\"common\":{\"mid\":\"101\"},\"page\":{\"page_id\":\"home\"},\"ts\":10000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"home\"},\"ts\":12000}",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"home\"},\"ts\":15000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"detail\"},\"ts\":30000} "
);
dataStream.print("in json:");然后从dwm_user_jump_detail主题消费数据
./kafka-console-consumer.sh --bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic dwm_user_jump_detail
标签:Flink,org,flink,page,id,CEP,apache,import,访客 来源: https://www.cnblogs.com/zhangbaohpu/p/15987524.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。