标签:kube kubernetes -- etc 集群 kubeadm K8S 节点
kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。
这个工具能通过两条指令完成一个kubernetes集群的部署:
# 创建一个 Master 节点
kubeadm init
# 将一个 Node 节点加入到当前集群中
kubeadm join <Master节点的IP和端口 >
一、安装要求
在开始之前,部署Kubernetes集群机器需要满足以下几个条件:
- 一台或多台机器,操作系统 CentOS7.x-86_x64
- 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多【注意master需要两核】
- 可以访问外网,需要拉取镜像,如果服务器不能上网,需要提前下载镜像并导入节点
- 禁止swap分区
二、准备环境
| 角色 | IP |
|---|---|
| master | 192.168.177.130 |
| node1 | 192.168.177.131 |
| node2 | 192.168.177.132 |
然后开始在每台机器上执行下面的命令
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
# 永久关闭
sed -i 's/enforcing/disabled/' /etc/selinux/config
# 临时关闭
setenforce 0
# 关闭swap
# 临时
swapoff -a
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 根据规划设置主机名【master节点上操作】
hostnamectl set-hostname k8smaster
# 根据规划设置主机名【node1节点操作】
hostnamectl set-hostname k8snode1
# 根据规划设置主机名【node2节点操作】
hostnamectl set-hostname k8snode2
# 在master添加hosts
cat >> /etc/hosts << EOF
192.168.177.130 k8smaster
192.168.177.131 k8snode1
192.168.177.132 k8snode2
EOF
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 生效
sysctl --system
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
三、安装Docker/kubeadm/kubelet
所有节点安装Docker/kubeadm/kubelet ,Kubernetes默认CRI(容器运行时)为Docker,因此先安装Docker
安装Docker
首先配置一下Docker的阿里yum源
cat >/etc/yum.repos.d/docker.repo<<EOF
[docker-ce-edge]
name=Docker CE Edge - \$basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/\$basearch/edge
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
然后yum方式安装docker
# yum安装
yum -y install docker-ce
# 查看docker版本
docker --version
# 启动docker
systemctl enable docker
systemctl start docker
配置docker的镜像源
cat >> /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
然后重启docker
systemctl restart docker
添加kubernetes软件源
然后我们还需要配置一下yum的k8s软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装kubeadm,kubelet和kubectl
由于版本更新频繁,这里指定版本号部署:
# 安装kubelet、kubeadm、kubectl,同时指定版本
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
# 设置开机启动
systemctl enable kubelet
四、部署Kubernetes Master【master节点】
在 192.168.177.130 执行,也就是master节点
kubeadm init --apiserver-advertise-address=192.168.177.130 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址,【执行上述命令会比较慢,因为后台其实已经在拉取镜像了】,我们 docker images 命令即可查看已经拉取的镜像

当我们出现下面的情况时,表示kubernetes的镜像已经安装成功

使用kubectl工具 【master节点操作】
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
执行完成后,我们使用下面命令,查看我们正在运行的节点
kubectl get nodes

能够看到,目前有一个master节点已经运行了,但是还处于未准备状态
下面我们还需要在Node节点执行其它的命令,将node1和node2加入到我们的master节点上
五、加入Kubernetes Node【Slave节点】
下面我们需要到 node1 和 node2服务器,执行下面的代码向集群添加新节点
执行在kubeadm init输出的kubeadm join命令:
注意,以下的命令是在master初始化完成后,每个人的都不一样!!!需要复制自己生成的
kubeadm join 192.168.177.130:6443 --token 8j6ui9.gyr4i156u30y80xf \
--discovery-token-ca-cert-hash sha256:eda1380256a62d8733f4bddf926f148e57cf9d1a3a58fb45dd6e80768af5a500
默认token有效期为24小时,当过期之后,该token就不可用了。这时就需要重新创建token,操作如下:
kubeadm token create --print-join-command
当我们把两个节点都加入进来后,我们就可以去Master节点 执行下面命令查看情况
kubectl get node

六、部署CNI网络插件
上面的状态还是NotReady,下面我们需要网络插件,来进行联网访问
# 下载网络插件配置
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
默认镜像地址无法访问,sed命令修改为docker hub镜像仓库。
# 添加
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 查看状态 【kube-system是k8s中的最小单元】
kubectl get pods -n kube-system
要是上述方式不太行,可以更换一个网络插件
安装Calico网络插件
curl https://docs.projectcalico.org/manifests/calico.yaml -O
kubectl apply -f calico.yaml运行后的结果
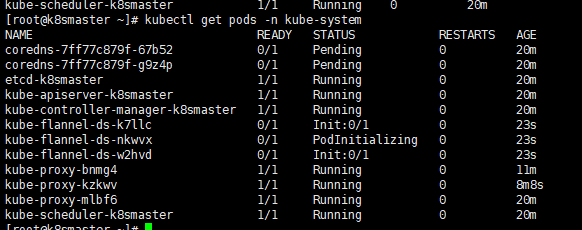
运行完成后,我们查看状态可以发现,已经变成了Ready状态了
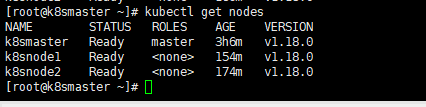
如果上述操作完成后,还存在某个节点处于NotReady状态,可以在Master将该节点删除
# master节点将该节点删除
kubectl delete node k8snode1
# 然后到k8snode1节点进行重置
kubeadm reset
# 重置完后在加入
kubeadm join 192.168.177.130:6443 --token 8j6ui9.gyr4i156u30y80xf --discovery-token-ca-cert-hash sha256:eda1380256a62d8733f4bddf926f148e57cf9d1a3a58fb45dd6e80768af5a500
七、测试kubernetes集群
我们都知道K8S是容器化技术,它可以联网去下载镜像,用容器的方式进行启动
在Kubernetes集群中创建一个pod,验证是否正常运行:
# 下载nginx 【会联网拉取nginx镜像】
kubectl create deployment nginx --image=nginx
# 查看状态
kubectl get pod
如果我们出现Running状态的时候,表示已经成功运行了

下面我们就需要将端口暴露出去,让其它外界能够访问
# 暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
# 查看一下对外的端口
kubectl get pod,svc
能够看到,我们已经成功暴露了 80端口 到 30529上

我们到我们的宿主机浏览器上,访问如下地址
http://192.168.177.130:30529/
发现我们的nginx已经成功启动了
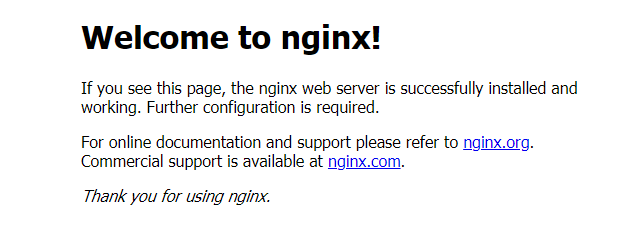
到这里为止,我们就搭建了一个单master的k8s集群


错误汇总
错误一
在执行Kubernetes init方法的时候,出现这个问题
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR NumCPU]: the number of available CPUs 1 is less than the required 2
是因为VMware设置的核数为1,而K8S需要的最低核数应该是2,调整核数重启系统即可
错误二
我们在给node1节点使用 kubernetes join命令的时候,出现以下错误
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Swap]: running with swap on is not supported. Please disable swap
错误原因是我们需要关闭swap
# 关闭swap
# 临时
swapoff -a
# 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab
错误三
在给node1节点使用 kubernetes join命令的时候,出现以下错误
The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused
解决方法,首先需要到 master 节点,创建一个文件
# 创建文件夹
mkdir /etc/systemd/system/kubelet.service.d
# 创建文件
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# 添加如下内容
Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --fail-swap-on=false"
# 重置
kubeadm reset
然后删除刚刚创建的配置目录
rm -rf $HOME/.kube
然后 在master重新初始化
kubeadm init --apiserver-advertise-address=202.193.57.11 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
初始完成后,我们再到 node1节点,执行 kubeadm join命令,加入到master
kubeadm join 202.193.57.11:6443 --token c7a7ou.z00fzlb01d76r37s \
--discovery-token-ca-cert-hash sha256:9c3f3cc3f726c6ff8bdff14e46b1a856e3b8a4cbbe30cab185f6c5ee453aeea5
添加完成后,我们使用下面命令,查看节点是否成功添加
kubectl get nodes
错误四
我们再执行查看节点的时候, kubectl get nodes 会出现问题
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
这是因为我们之前创建的配置文件还存在,也就是这些配置
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
我们需要做的就是把配置文件删除,然后重新执行一下
rm -rf $HOME/.kube
然后再次创建一下即可
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
这个问题主要是因为我们在执行 kubeadm reset 的时候,没有把 $HOME/.kube 给移除掉,再次创建时就会出现问题了
错误五
安装的时候,出现以下错误
Another app is currently holding the yum lock; waiting for it to exit...
是因为yum上锁占用,解决方法
yum -y install docker-ce
错误六
在执行 kubeadm reset 的时候,出现下面的错误
{"level":"warn","ts":"2022-01-22T04:16:31.062-0500","caller":"clientv3/retry_interceptor.go:61","msg":"retrying of unary invoker failed","target":"endpoint://client-bb6ef2cd-d17e-4821-a8b5-96a5f0296d22/172.16.174.140:2379","attempt":0,"error":"rpc error: code = Unknown desc = etcdserver: re-configuration failed due to not enough started members"}解决措施:
执行如下命令
rm -rf /etc/kubernetes/*然后再次执行重置
kubeadm reset最后,再删除 kube 文件夹即可
rm -rf /root/.kube/错误七
在执行kubectl init 时出现下面错误
[root@k8smaster ~]# kubeadm init --apiserver-advertise-address=172.16.174.140 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
W0122 05:12:56.579589 38445 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.18.0
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 18.03.1-ce. Latest validated version: 19.03
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher需要删除 /var/lib/etcd 文件夹即可
rm -rf /var/lib/etcd错误八
在执行kubectl get nodes 的时候,出现下列的错误
error: no configuration has been provided, try setting KUBERNETES_MASTER environment variable这是由于没有配置环境变量引起的,需要编辑文件 /etc/profile,然后末尾追加下面内容
export KUBECONFIG=/etc/kubernetes/admin.conf然后更新环境变量,即可生效
source /etc/profile标签:kube,kubernetes,--,etc,集群,kubeadm,K8S,节点 来源: https://www.cnblogs.com/55zjc/p/15974010.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。