©原创作者 | 杨健
论文标题:
K-BERT: Enabling Language Representation with Knowledge Graph
收录会议:
AAAI
论文链接:
https://ojs.aaai.org/index.php/AAAI/article/view/5681
项目地址:
https://github.com/autoliuweijie/K-BERT
01 背景论述
笔者在前面的论文解读中提到过ERNIE使用基于自注意力机制来克服异构向量的融合,而KEPLER更进一步,将实体的描述文本作为训练语料,利用文本编码器生成实体的初始化语料,避免了异构语义向量的生成。
那么除了这一方式以外,是否还存在别的方式在注入异构知识的过程中解决异构向量的问题呢?
既然造成异构向量的原因在于使用不同的表示学习方式对不同结构的对象进行表示学习,那么一个直接的思路就是将不同结构的对象转换成同一结构,从而使用同一种表示学习方式对其编码。
本文所解读的K-BERT模型正是通过将知识图谱中的三元组转换为文本序列实现了结构的统一,在此基础上使用预训练语言模型编码文本和知识。
具体而言,K-BERT首先将图谱中的三元组视为单向的文本序列,通过对齐输入序列中的相同的实体名作为桥梁,实现文本序列和三元组序列之间的链接,形成如下图所示的句子树结构:

尽管这种方式生成了统一的数据结构,然而在使用已有的预训练语言模型对它编码时却会遇到引入知识噪音的问题。
也即由于预训练语言模型中的自注意机制,会使得模型中的无关词关注到三元组中的实体,从而影响其正确的语义。
比如文本序列中的visiting会受到apple和CEO等无关词的影响。
02 解决方案
K-BERT使用BERT模型作为基础模型,为下游任务构造含有知识的句子树作为输入序列,并通过下游任务的目标函数微调模型。
K-BERT模型主要包括知识层(knowledge layer)、表示层(embedding layer)、可见层(seeing layer)和编码器(mask-Transformer encoder)四个组成模块。
其中知识层负责知识的注入以及句子树的生成;表示层负责将句子树这一输入序列投影成表示向量;可见层通过使用可见矩阵记录向量的可见范围,解决知识噪音的问题;编码层则负责基于注入的三元组知识所提供的信息编码表示向量。
模型结构如图1所示:

图1. K-BERT模型结构
给定输入序列,知识层首先挑选出序列中的命名实体,并将其作为头实体,从知识图谱中检索出实体所在的三元组,然后将三元组中的关系和尾实体链接到命名实体后面,形成深度为1的句子树。
获得句子树后,K-BERT使用和BERT相同的方式生成文本初始表示向量,段落(segment)表示向量,与BERT所不同的是,由于引入了三元组,K-BERT使用软位置编码方式生成位置向量。
以图1中的句子为例,“CEO”和“is”都处于Cook后面,因此他们拥有相同的绝对位置向量,然而这会使得编码器在计算自注意力时,认为“CEO”和“is”关联密切,从而受到误导。
表示向量的生成示例如下图所示:

为了解决这一问题,模型在可见层部分额外设计了一个可见矩阵,控制每一个文本向量的可见范围。
同样以图1中的句子为例,句子树总长度为12,对于第一个单词Tim而言,文本序列中的所有单词都可见,而句子中的分支,也即三元组的关系和尾实体不可见。
针对可见单词,将矩阵中对应位置赋值为0,对于不可见的单词则赋值为负无穷。依次对序列中的每一个单词进行相同的处理,从而生成12*12的矩阵。
矩阵示意图如下图所示:

其中红色标记的点代表纵向上某个单词对横向上某个单词可见,白色标记的点则代表不可见。
矩阵取值规则如下面公式所示:

矩阵Mij将在自注意力层中和权重矩阵(query矩阵Q和key矩阵K的乘积)求和,从而使得无关单词之间的权重为负无穷,经过Softmax计算后关注度为0,而相关词之间的权重由于和0值求和,关注度不受影响,从而克服无关词带来的语义影响。
计算公式如下图所示:
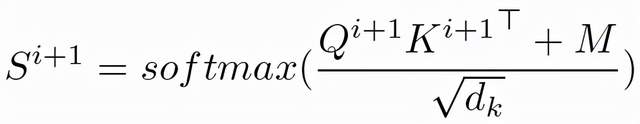
03 实验分析
实验主要包括针对开放和特定领域的中文自然语言理解实验,以及消融实验。
3.1 开放领域自然语言理解实验
面对开放领域,作者分别使用HowNet和CN-DBpedia两个知识图谱微调模型,分别在情感分类、自然语言推理、句子对语义相似性判断、问答和实体识别任务上测试经过训练后的模型的有效性。
其测试结果如图2和图3所示:
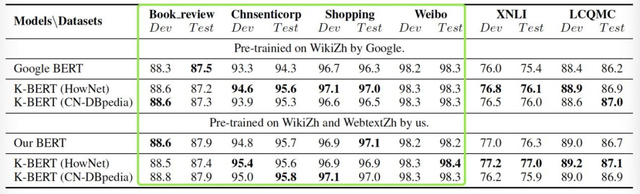
图2. K-BERT在情感识别任务、自然语言推理和句子对语义相似性判断任务上的正确率
结果表明知识图谱对于情感分类任务没有较大的影响(正确率见绿框中显示),这是因为任务中判断句子的情感类别更依赖于句中的情感词,而非外部的知识库。
但对于这一点,笔者认为外部知识库也同样有着很大的重要,比如当某人引用“西出阳关无故人,劝君更尽一杯酒”这类古诗时,仅仅依赖于情感词就无法判断个人此时的情感倾向。

图3. K-BERT在问答和实体识别任务上的F1值
其次在语义相似性任务上,图3的结果表明使用HowNet微调比使用CN-DBpedia取得的正确率更高,在问答和实体识别任务上则相反。
这是因为HowNet是一个语义粒度更小的知识图谱,它是通过将单词分解为最小语义单元的方式组织知识图谱,图谱中实体之间的关系表达的是“组成”这一关系,因而更适用于对单词语义要求更高的语言理解型任务。而对于要求实体间更为多样关系的任务,百科知识图谱更更为适用。
此外,在金融和医疗领域的问答和实体识别任务上测试的结果表明,相比BERT,通过使用知识图谱能够有效提高模型的性能,使用领域知识图谱则有进一步的提高。
3.2 消融实验
该实验部分检测了软位置编码和可视矩阵的有效性。结果表明,当不使用软位置编码或可视矩阵时,模型会受到知识噪音的影响,造成模型的性能下降,而使用它们能够提高模型的鲁棒性,从而更有效的利用外部知识。
04 点滴思考
模型通过构造句子树这一统一结构融合了知识图谱中的三元组,具有下面几个优点,一是模型不需要重新预训练,而仅需通过微调注入知识,保持了预训练语言模型的参数不变,并且训练效率更高。
这对于应对会动态变化的真实世界而言非常重要,由于外部知识库会不断更新,重新预训练一方面会增加训练成本,另一方面也容易造成参数遗忘。
对于参数遗忘的问题,一个较为成熟的解决方式是在原有模型的基础上引入适配器,使用适配器记录额外的参数,而保持原有模型参数在训练的时候不变[1]。二是和KEPLER一样,在知识注入的同时避免了异构向量的生成。
然而K-BERT将三元组视作一个独立的单元,忽略了三元组间的关联。此外,K-BERT在微调阶段注入知识也使得知识注入的程度有限。为此,[2-3]尝试引入知识图谱中的子图作为基本的知识单元,从而引入实体在图谱中的上下文信息。
参考文献
[1] K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters
http://arxiv.org/abs/2002.01808
[2] CoLAKE- Contextualized Language and Knowledge Embedding
https://arxiv.org/abs/2010.00309
[3] Integrating Graph Contextualized Knowledge into Pre-trained Language Models
https://arxiv.org/abs/1912.00147
标签:BERT,训练,图谱,模型,知识,三元组,语料,向量 来源: https://www.cnblogs.com/NLPlunwenjiedu/p/15963966.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。