标签:Flink String flink 业务 实时 org apache import com
1. 流程介绍
在上一篇文章中,我们已经把客户端的页面日志,启动日志,曝光日志分别发送到kafka对应的主题中。在本文中,我们将把业务数据也发送到对应的kafka主题中。
通过maxwell采集业务数据变化,相当于是ods数据,把采集的数据发送到kafka的topic(ods_base_db_m)中,然后flink从kafka消费数据,这个过程有维度数据,就放到hbase中,其他事实数据再发送给kafka作为dwd层。flink消费kafka数据可以做一些简单的ETL处理,比如过滤空值,长度限制。
2. 消费kafka数据及ETL操作
项目地址:https://github.com/zhangbaohpu/gmall-flink-parent/tree/master/gmall-realtime
在模块 gmall-realtime 的dwd包下创建类:BaseDbTask.java
具体步骤就看代码了
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.LocalStreamEnvironment;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* 从kafka读取业务数据
* @author: zhangbao
* @date: 2021/8/15 21:10
* @desc:
**/
public class BaseDbTask {
public static void main(String[] args) {
//1.获取flink环境
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/baseDbApp"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//2.从kafka获取topic数据
String topic = "ods_base_db_m";
String group = "base_db_app_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, group);
DataStreamSource<String> jsonStrDs = env.addSource(kafkaSource);
//3.对数据进行json转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = jsonStrDs.map(jsonObj -> JSON.parseObject(jsonObj));
//4.ETL, table不为空,data不为空,data长度不能小于3
SingleOutputStreamOperator<JSONObject> filterDs = jsonObjDs.filter(jsonObject -> jsonObject.getString("table") != null
&& jsonObject.getJSONObject("data") != null
&& jsonObject.getString("data").length() > 3);
filterDs.print("json str --->>");
try {
env.execute("base db task");
} catch (Exception e) {
e.printStackTrace();
}
}
}3. 动态分流
由于MaxWell是把全部数据统一写入一个Topic中, 这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表,有的表既是事实表在某种情况下也是维度表。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL 等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。但是作为 Flink 实时计算任务,如何得知哪些表是维度表,哪些是事实表呢?而这些表又应该采集哪些字段呢?
我们可以将上面的内容放到某一个地方,集中配置。这样的配置不适合写在配置文件中,因为业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现
-
一种是用 Zookeeper 存储,通过 Watch 感知数据变化。
-
另一种是用 mysql 数据库存储,周期性的同步或使用flink-cdc实时同步。
这里选择第二种方案,周期性同步,flink-cdc方式可自行尝试,主要是 mysql 对于配置数据初始化和维护管理,用 sql 都比较方便,虽然周期性操作时效性差一点,但是配置变化并不频繁。
所以就有了如下图:

业务数据保存到Kafka 的主题中,维度数据保存到Hbase 的表中。
4. mysql配置
① 在 gmall-realtime 模块添加依赖
<!--lomback 插件依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
<scope>provided</scope>
</dependency>
<!--commons-beanutils 是 Apache 开源组织提供的用于操作 JAVA BEAN 的工具包。
使用 commons-beanutils,我们可以很方便的对 bean 对象的属性进行操作-->
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
<!--Guava 工程包含了若干被 Google 的 Java 项目广泛依赖的核心库,方便开发-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>② 单独创建数据库gmall2021_realtime
create database gmall2021_realtime;
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`operate_type` varchar(200) NOT NULL COMMENT '操作类型 insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;③ 创建实体类
package com.zhangbao.gmall.realtime.bean;
import lombok.Data;
/**
* @author: zhangbao
* @date: 2021/8/22 13:06
* @desc:
**/
@Data
public class TableProcess {
//动态分流 Sink 常量 改为小写和脚本一致
public static final String SINK_TYPE_HBASE = "hbase";
public static final String SINK_TYPE_KAFKA = "kafka";
public static final String SINK_TYPE_CK = "clickhouse";
//来源表
private String sourceTable;
//操作类型 insert,update,delete
private String operateType;
//输出类型 hbase kafka
private String sinkType;
//输出表(主题)
private String sinkTable;
//输出字段
private String sinkColumns;
//主键字段
private String sinkPk;
//建表扩展
private String sinkExtend;
}④ mysql工具类
package com.zhangbao.gmall.realtime.utils;
import com.google.common.base.CaseFormat;
import com.zhangbao.gmall.realtime.bean.TableProcess;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.commons.lang.reflect.FieldUtils;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
/**
* @author: zhangbao
* @date: 2021/8/22 13:09
* @desc:
**/
public class MysqlUtil {
private static final String DRIVER_NAME = "com.mysql.jdbc.Driver";
private static final String URL = "jdbc:mysql://192.168.88.71:3306/gmall2021_realtime?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8";
private static final String USER_NAME = "root";
private static final String USER_PWD = "123456";
public static void main(String[] args) {
String sql = "select * from table_process";
List<TableProcess> list = getList(sql, TableProcess.class, true);
for (TableProcess tableProcess : list) {
System.out.println(tableProcess.toString());
}
}
public static <T> List<T> getList(String sql,Class<T> clz, boolean under){
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
Class.forName(DRIVER_NAME);
conn = DriverManager.getConnection(URL, USER_NAME, USER_PWD);
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
List<T> resultList = new ArrayList<>();
ResultSetMetaData metaData = rs.getMetaData();
int columnCount = metaData.getColumnCount();
while (rs.next()){
System.out.println(rs.getObject(1));
T obj = clz.newInstance();
for (int i = 1; i <= columnCount; i++) {
String columnName = metaData.getColumnName(i);
String propertyName = "";
if(under){
//指定数据库字段转换为驼峰命名法,guava工具类
propertyName = CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL,columnName);
}
//通过guava工具类设置属性值
BeanUtils.setProperty(obj,propertyName,rs.getObject(i));
}
resultList.add(obj);
}
return resultList;
} catch (Exception throwables) {
throwables.printStackTrace();
new RuntimeException("msql 查询失败!");
} finally {
if(rs!=null){
try {
rs.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(ps!=null){
try {
ps.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
return null;
}
}5. 程序分流
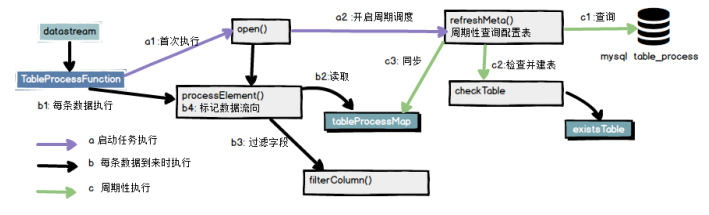
如图定义一个mapFunction函数
-
1.在open方法中初始化配置信息,并周期开启一个任务刷新配置
-
2.在任务中根据配置创建数据表
-
3.分流
主任务流程
package com.zhangbao.gmall.realtime.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.app.func.TableProcessFunction;
import com.zhangbao.gmall.realtime.bean.TableProcess;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.LocalStreamEnvironment;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.OutputTag;
/**
* 从kafka读取业务数据
* @author: zhangbao
* @date: 2021/8/15 21:10
* @desc:
**/
public class BaseDbTask {
public static void main(String[] args) {
//1.获取flink环境
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/baseDbApp"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//2.从kafka获取topic数据
String topic = "ods_base_db_m";
String group = "base_db_app_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, group);
DataStreamSource<String> jsonStrDs = env.addSource(kafkaSource);
//3.对数据进行json转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = jsonStrDs.map(jsonObj -> JSON.parseObject(jsonObj));
//4.ETL, table不为空,data不为空,data长度不能小于3
SingleOutputStreamOperator<JSONObject> filterDs = jsonObjDs.filter(jsonObject -> jsonObject.getString("table") != null
&& jsonObject.getJSONObject("data") != null
&& jsonObject.getString("data").length() > 3);
//5.动态分流,事实表写会kafka,维度表写入hbase
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>(TableProcess.SINK_TYPE_HBASE){};
//创建自定义mapFunction函数
SingleOutputStreamOperator<JSONObject> kafkaTag = filterDs.process(new TableProcessFunction(hbaseTag));
DataStream<JSONObject> hbaseDs = kafkaTag.getSideOutput(hbaseTag);
filterDs.print("json str --->>");
try {
env.execute("base db task");
} catch (Exception e) {
e.printStackTrace();
}
}
}创建TableProcessFunction自定义任务
这里包括上面说的四个步骤
-
初始化并周期读取配置数据
-
执行每条数据
-
过滤字段
-
标记数据流向,根据配置写入对应去向,维度数据就写入hbase,事实数据就写入kafka
package com.zhangbao.gmall.realtime.app.func;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.bean.TableProcess;
import com.zhangbao.gmall.realtime.common.GmallConfig;
import com.zhangbao.gmall.realtime.utils.MysqlUtil;
import lombok.extern.log4j.Log4j2;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.*;
/**
* @author: zhangbao
* @date: 2021/8/26 23:24
* @desc:
**/
@Log4j2(topic = "gmall-logger")
public class TableProcessFunction extends ProcessFunction<JSONObject,JSONObject> {
//定义输出流标记
private OutputTag<JSONObject> outputTag;
//定义配置信息
private Map<String , TableProcess> tableProcessMap = new HashMap<>();
//在内存中存放已经创建的表
Set<String> existsTable = new HashSet<>();
//phoenix连接对象
Connection con = null;
public TableProcessFunction(OutputTag<JSONObject> outputTag) {
this.outputTag = outputTag;
}
//只执行一次
@Override
public void open(Configuration parameters) throws Exception {
//初始化配置信息
log.info("查询配置表信息");
//创建phoenix连接
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
con = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
refreshDate();
//启动一个定时器,每隔一段时间重新获取配置信息
//delay:延迟5000执行,每隔5000执行一次
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
refreshDate();
}
},5000,5000);
}
//每进来一个元素,执行一次
@Override
public void processElement(JSONObject jsonObj, Context context, Collector<JSONObject> collector) throws Exception {
//获取表的修改记录
String table = jsonObj.getString("table");
String type = jsonObj.getString("type");
JSONObject data = jsonObj.getJSONObject("data");
if(type.equals("bootstrap-insert")){
//maxwell更新历史数据时,type类型是bootstrap-insert
type = "insert";
jsonObj.put("type",type);
}
if(tableProcessMap != null && tableProcessMap.size()>0){
String key = table + ":" + type;
TableProcess tableProcess = tableProcessMap.get(key);
if(tableProcess!=null){
//数据发送到何处,如果是维度表,就发送到hbase,如果是事实表,就发送到kafka
String sinkType = tableProcess.getSinkType();
jsonObj.put("sink_type",sinkType);
String sinkColumns = tableProcess.getSinkColumns();
//过滤掉不要的数据列,sinkColumns是需要的列
filterColumns(data,sinkColumns);
}else {
log.info("no key {} for mysql",key);
}
if(tableProcess!=null && tableProcess.getSinkType().equals(TableProcess.SINK_TYPE_HBASE)){
//根据sinkType判断,如果是维度表就分流,发送到hbase
context.output(outputTag,jsonObj);
}else if(tableProcess!=null && tableProcess.getSinkType().equals(TableProcess.SINK_TYPE_KAFKA)){
//根据sinkType判断,如果是事实表就发送主流,发送到kafka
collector.collect(jsonObj);
}
}
}
//过滤掉不要的数据列,sinkColumns是需要的列
private void filterColumns(JSONObject data, String sinkColumns) {
String[] cols = sinkColumns.split(",");
//转成list集合,用于判断是否包含需要的列
List<String> columnList = Arrays.asList(cols);
Set<Map.Entry<String, Object>> entries = data.entrySet();
Iterator<Map.Entry<String, Object>> iterator = entries.iterator();
while (iterator.hasNext()){
Map.Entry<String, Object> next = iterator.next();
String key = next.getKey();
//如果不包含就删除不需要的列
if(!columnList.contains(key)){
iterator.remove();
}
}
}
//读取配置信息,并创建表
private void refreshDate() {
List<TableProcess> processList = MysqlUtil.getList("select * from table_process", TableProcess.class, true);
for (TableProcess tableProcess : processList) {
String sourceTable = tableProcess.getSourceTable();
String operateType = tableProcess.getOperateType();
String sinkType = tableProcess.getSinkType();
String sinkTable = tableProcess.getSinkTable();
String sinkColumns = tableProcess.getSinkColumns();
String sinkPk = tableProcess.getSinkPk();
String sinkExtend = tableProcess.getSinkExtend();
String key = sourceTable+":"+operateType;
tableProcessMap.put(key,tableProcess);
//在phoenix创建表
if(TableProcess.SINK_TYPE_HBASE.equals(sinkType) && operateType.equals("insert")){
boolean noExist = existsTable.add(sinkTable);//true则表示没有创建表
if(noExist){
createTable(sinkTable,sinkColumns,sinkPk,sinkExtend);
}
}
}
}
//在phoenix中创建表
private void createTable(String table, String columns, String pk, String ext) {
if(StringUtils.isBlank(pk)){
pk = "id";
}
if(StringUtils.isBlank(ext)){
ext = "";
}
StringBuilder sql = new StringBuilder("create table if not exists " + GmallConfig.HBASE_SCHEMA + "." + table +"(");
String[] split = columns.split(",");
for (int i = 0; i < split.length; i++) {
String field = split[i];
if(pk.equals(field)){
sql.append(field + " varchar primary key ");
}else {
sql.append("info." + field +" varchar ");
}
if(i < split.length-1){
sql.append(",");
}
}
sql.append(")").append(ext);
//创建phoenix表
PreparedStatement ps = null;
try {
log.info("创建phoenix表sql - >{}",sql.toString());
ps = con.prepareStatement(sql.toString());
ps.execute();
} catch (SQLException throwables) {
throwables.printStackTrace();
}finally {
if(ps!=null){
try {
ps.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
throw new RuntimeException("创建phoenix表失败");
}
}
}
if(tableProcessMap == null || tableProcessMap.size()==0){
throw new RuntimeException("没有从配置表中读取配置信息");
}
}
}6. 重启策略
flink程序在运行时,有错误会抛出异常,程序就停止了,但当开始checkpoint检查点时,flink重启策略就是开启的,如果程序出现异常了,程序就会一直重启,并且重启次数是Integer.maxValue,这个过程也看不到错误信息,是很不友好的。
flink可以设置重启策略,所以在我们开启checkpoint检查点时,设置不需要重启就可以看到错误信息了:
env.setRestartStrategy(RestartStrategies.noRestart());
下面我们测试一下。
package com.zhangbao.gmall.realtime.app.dwd;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.app.func.TableProcessFunction;
import com.zhangbao.gmall.realtime.bean.TableProcess;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.executiongraph.restart.RestartStrategy;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.LocalStreamEnvironment;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.OutputTag;
/**
* 从kafka读取业务数据
* @author: zhangbao
* @date: 2021/8/15 21:10
* @desc:
**/
public class Test {
public static void main(String[] args) {
//1.获取flink环境
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/baseDbApp"));
//指定哪个用户读取hdfs文件
System.setProperty("HADOOP_USER_NAME","zhangbao");
//flink重启策略,
// 如果开启上面的checkpoint,重启策略就是自动重启,程序有问题不会有报错,
// 如果没有开启checkpoint,就不会自动重启,所以这里设置不需要重启,就可以查看错误信息
env.setRestartStrategy(RestartStrategies.noRestart());
//2.从kafka获取topic数据
String topic = "ods_base_db_m";
String group = "test_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, group);
DataStreamSource<String> jsonStrDs = env.addSource(kafkaSource);
jsonStrDs.print("转换前-->");
//3.对数据进行json转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = jsonStrDs.map(jsonObj ->{
System.out.println(4/0);
JSONObject jsonObject = JSON.parseObject(jsonObj);
return jsonObject;
});
jsonObjDs.print("转换后-->");
try {
env.execute("base db task");
} catch (Exception e) {
e.printStackTrace();
}
}
}在程序对数据进行转换过程中,我们加了 System.out.println(4/0); 这样一行代码,肯定会抛出异常的。
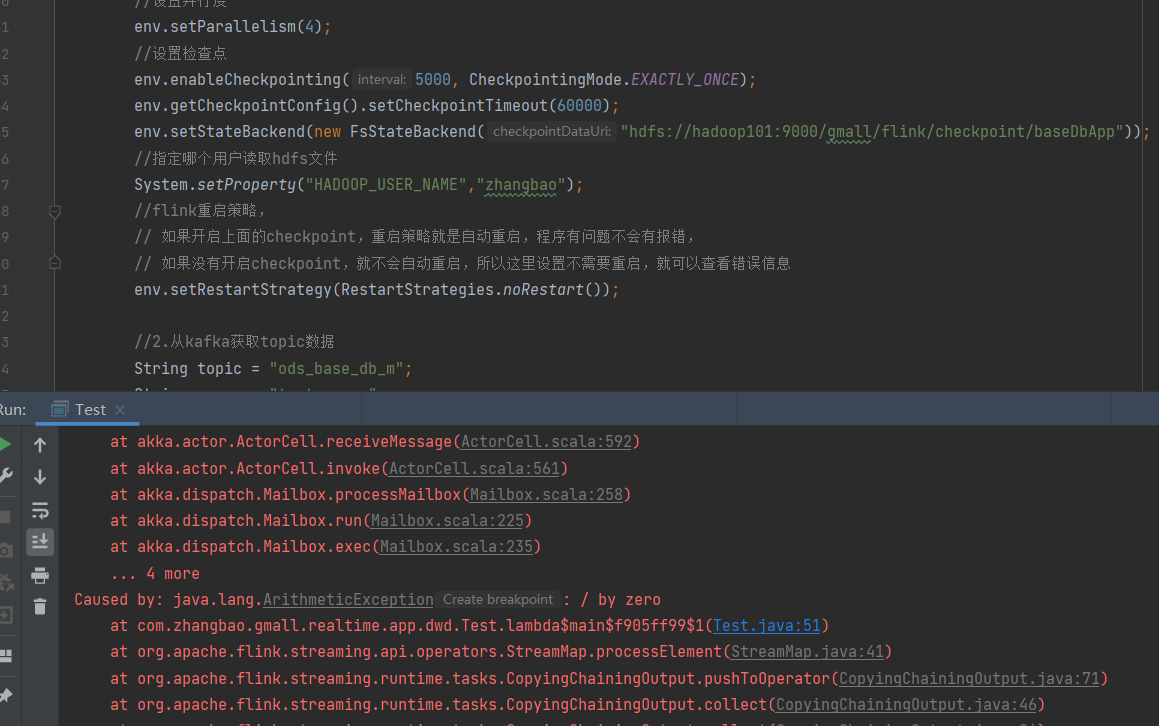
在设置不需要重启后,就可以看到错误信息了,当你把设置不需要重启一行代码注释掉,就会发现程序是一直在运行中的,并且没有任何错误信息。
在实际应用中,根据需要可以自行设置。
标签:Flink,String,flink,业务,实时,org,apache,import,com 来源: https://www.cnblogs.com/zhangbaohpu/p/15913866.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。