标签:发送 消费 分区 面经 broker kafka --- 消息
消息队列
作用,优点?
- 异步:比如查看文章,点赞收藏评论等操作,提升文章热度,提升个人社区贡献度,提升个人社区积分,刷新社区贡献度排行榜。将其他操作放到消息队列,相应的模块从消息队列中拿到消息后进行业务处理,这样可以异步的完成多个业务操作。
- 削峰:比如求职旺季,秋招春招的节点,很多人频繁浏览各种经验帖子,先直接返回页面,后续的积分,贡献度等计算放到消息队列中,等待消费者慢慢消费。
- 解耦:对于不同的接口,只要消息队列中的消息格式不变,各个接口如何更改都没关系。排查问题是也能直到是具体的哪个部分的问题。
缺点?
- 系统复杂性:引入之后就要考虑消息重复消费、消息丢失、消息的顺序消费等等
- 数据不一致性:对于那一系列操作,要成功都成功,那么就要分布式事务
- 可用性:如果消息队列挂了怎么办呢?
对于消息中间件如何选择?
常见有Kafka、RabbitMQ、RocketMQ 等,还有很多公司都会有自研的没有开源的。
kafka最大优势在于高吞吐量,性能很高。缺点在于可能造成数据丢失,因为它在收到消息的时候,并不是直接写到物理磁盘的,而是先写入到磁盘缓冲区里面的。功能单一,主要支持收发消息。可以进行用户行为日志等。
rabbitmq保证数据不丢失,支持很多高级功能,如死信队列,消息重试等。开发语言是erlang。
rocketmq阿里开发,挺完善的吧。
那么如何选型?
- 如果我们业务只是收发消息这种单一类型的需求,而且可以允许小部分数据丢失的可能性,但是又要求极高的吞吐量和高性能的话,就直接选Kafka就行了,就好比我们公司想要收集和传输用户行为日志以及其他相关日志的处理,就选用的Kafka中间件。
- 如果自己所处公司业务比较平稳,未来几年内不会出现飞速发展,而且没有什么改源码的特殊需求的话,在面对选择MQ的时候就可以选用RabbitMQ。毕竟如今这样的中小公司也就是这么干的。
- 如果自己所处公司发展迅猛,一年经常搞一些特别大的促销秒杀活动,公司技术栈主要是Java语言的话,就直接一步到位选择RocketMQ,这样会省很多事情。
kafka模型结构
暂时先用,我觉得尚硅谷的图更好!
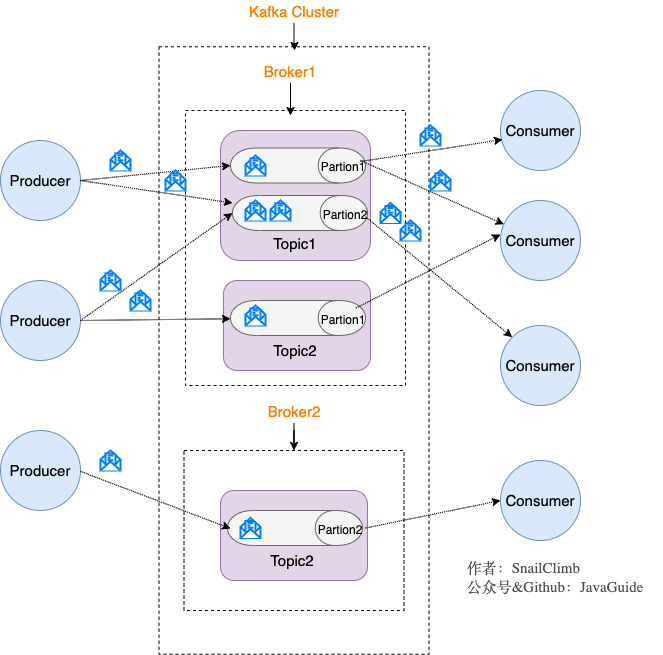
生产者:每个生产者生产消息,消息放在本地内存上,进行批量发送,发送的数据自然要压缩,发送到一个kafka的一个leader分区上
kafka:多个broker,每个broker下多个topic,每个topic下多个分区,每个分区相当于一个队列,分区分为leader和follwer,follower作为备份,那么自然同一个分区的leader分区和follwer分区不能再同一个broker中(如果在一起的话,broker挂掉,那岂不是leader和follwer都挂掉,备份就没意义了)。
消费者:消费者消费leader分区,同组的消费者必须消费不同的分区。
zookeeper再kafka中的作用
kafka再2.8版本将要抛弃zk。为什么抛弃?运维层面,使用kafka还需要维护zk集群,增加复杂度。性能,zk为强一致性,当数据发生变更,通知其他zk节点都更新,并且超过一半写完才行。没了zk,使用内部的quorum来完成zk的工作。
zk再kafka中的作用,管理元数据,如broker,主题,分区等数据。选举等机制。
消息重复消费
生产者发送一个消息到消息队列,有多个消费者,每个消费者管不同模块,都监听这一个消息,如果某个模块失败,然后请求重新发送消息,那么对于其他成功的模块就有了消息重复消费的问题。
比如这个积分模块失败,要求重新发送消息,导致其他模块比如优惠卷等就会重复消费。
如何解决?接口幂等,就是说多次执行和一次执行效果一样。
比如说积分模块,当我执行加积分时,判断这个订单我处理过没?处理过直接return,没处理过,那么就加积分等操作。
校验可以分为强校验,弱校验:
强校验:自然是涉及金钱的,保证数据一致的。我们有一个流水表(每个业务会有订单号等,总之有一个唯一标识,存放在磁盘数据库),如果业务执行过,那么流水表中有记录。当要执行时,先判断流水表中是否有记录,如果有则直接return,否则执行业务逻辑。
弱校验:对于不那么重要的操作,就把流水放到redis中,设置过期时间,如果一定时间没去处理,那么也无所谓的。比如说发送个庆祝通知,比如说你账户等级到达7级,发送个庆祝消息等。
以上所说都是再网络正常,不宕机等情况下分析。
如果网络波动,或者宕机,等都可能引发数据丢失,或者重复消费。比如kafka某个broker宕机了,没有收到commit,恢复后offset还是原先的,这不就也是重复消费么。消费端手动提交等。
消息顺序消费
比如本来时增,改,删。但是消费时先删,增,改。
- 对于消息的发送,就是生产者一次发送多个消息给消息队列,对于rocketmq是有实现的,保证发送消息的顺序。对于kafka要保证消息发送到一个分区,通过key的hash,发送到一个同一个分区,保证发送顺序。那么消费者消费时,也要保证消费时顺序,那么就只能一个消费者实例,并且单线程去消费消息。(因为多线程下获取所有消息,还是不能保证消息的执行顺序)
- mock示例.md 那么生产者一次发送一个消息,消费者一次消费一个消息,消费完后告诉生产者,让生产者发送下一个消息。(这个跟tcp的差不多。。。)
kafka只能为我们保证分区的消息有序,对于kafka想要顺序消费,那么可以将消息放到同一个分区,如果想要全局有序,那么就只有一个分区,如果想要消费有序,那么就只有一个消费实例,
消息丢失
针对kafka
- broker:kafka为了性能和吞吐量,采取数据异步批量的存储在磁盘。数据先在page cache中,然后再刷盘,存储到磁盘中。那么数据再page cache中时宕机,数据就会丢失。如何保证数据不丢失?通过设置ack,acks 的默认值即为1,代表我们的消息被leader副本接收之后就算被成功发送。我们可以配置
acks = all,代表则所有副本都要接收到该消息之后该消息才算真正成功被发送。 - 生产者:将消息缓存,然后批量发送。或者消息过多,buffer装不下。或者异步发送,消息过多,线程池来不及处理消息。如果因为网络原因发送失败,可以通过重试,并且设置重试间隔来解决。
- 消费者:自动提交是按照一定时间间隔自动执行,这时消费失败,而commit已经发送,导致消息丢失。如果手动提交,比如消费完后,但是还没有提交,这时候挂掉了,这就会导致消息重复消费问题。
分布式事务
2pc(两段式提交)
kafka持久化
kafka为了性能和吞吐量,数据异步批量的存储在磁盘。数据先在page cache中,然后再刷盘,存储到磁盘中,并且持久化到磁盘时顺序访问的,速度还是很快的,节省了磁盘寻道和旋转次数。那么数据再page cache中时宕机,数据就会丢失。存到磁盘的数据是partition以消息日志的方式(落磁盘)存储起来。
kafka为什么快?
-
顺序写:Kafka 采用
顺序写文件的方式来提高磁盘写入性能。顺序写文件,基本减少了磁盘寻道和旋转的次数。磁头再也不用在磁道上乱舞了,而是一路向前飞速前行。 -
零拷贝:数据从broker磁盘通过网络传输的consumer,传统的IO流程:
- 第一次:读取磁盘文件到操作系统内核缓冲区;
- 第二次:将内核缓冲区的数据,copy 到应用程序的 buffer;
- 第三步:将应用程序 buffer 中的数据,copy 到 socket 网络发送缓冲区;
- 第四次:将 socket buffer 的数据,copy 到网卡,由网卡进行网络传输。
零拷贝:
-
page cache:生产者写入数据到broker,首先将数据存放到page cache中,consumer消费消息时,先从page cache中找,找到了则通过零拷贝传输到broker的socket buffer,再通过网络传输。如果再page cache中找不到,那再去磁盘中找。
-
压缩:压缩数据,支持多种压缩算法
-
分区并发:虽然分区可以提高并发,但是并不是分区越多越好:
-
越多的分区需要打开更多的文件句柄
-
客户端 / 服务器端需要使用的内存就越多:客户端 producer 有个参数 batch.size,默认是 16KB。它会为每个分区缓存消息,一旦满了就打包将消息批量发出。如果分区数越多,这部分缓存所需的内存占用也会更多。(意思是一个分区那就16kb,两个分区那就32kb,200个分区那就是200*16kb,分区越多,缓存消息越大)
-
降低高可用性:分区越多,每个broker上的分区也就越多
-
推还是拉?
我们讨论推拉模式,都是讨论消费者和broker。
对于提供者和broker默认是推。
如果是推?
broker接受到消息就推送给消费者
- 好处:
- 实时性高: Broker 接受完消息之后可以立马推送给 Consumer。
- 对于消费者使用来说更简单,简单啊就等着,反正有消息来了就会推过来。
- 缺点:
- 当生产者往 Broker 发送消息的速率大于消费者消费消息的速率时,随着时间的增长消费者那边可能就“爆仓”了,那么broker需要知道消费者的消费速率,需要平衡推送速率,而对于每个消费者的消费速率还可能变化,那么broker就要更新推送速度。总之很麻烦。
- 总结:推模式难以根据消费者的状态控制推送速率,适用于消息量不大、消费能力强要求实时性高的情况下。
如果是拉?
- 好处:
- 消费者可以根据自身的情况来发起拉取消息的请求
- 拉模式下 Broker 就相对轻松了,它只管存生产者发来的消息,至于消费的时候自然由消费者主动发起
- 拉模式可以更合适的进行消息的批量发送
- 缺点:
- 消息延迟:比如设置每2秒,拉一次。
- 消息忙请求,忙请求就是比如消息隔了几个小时才有,那么在几个小时之内消费者的请求都是无效的,在做无用功。
那么kafka是拉模式。
如何拉?
长轮询
消费者等待消息,当有消息的时候 Broker 会直接返回消息,如果没有消息都会采取延迟处理的策略,并且为了保证消息的及时性,在对应队列或者分区有新消息到来的时候都会提醒消息来了,及时返回消息。
一句话说就是消费者和 Broker 相互配合,拉取消息请求不满足条件的时候 hold 住,避免了多次频繁的拉取动作,当消息一到就提醒返回。
标签:发送,消费,分区,面经,broker,kafka,---,消息 来源: https://www.cnblogs.com/keboom/p/15876122.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。