标签:Transformer attribution transformer 模型 attention 解释性 score head 注意力
©原创作者 | FLPPED
论文:
Self-Attention Attribution: Interpreting Information Interactions Inside Transformer (2021 AAAI论文亚军)
地址:
https://arxiv.org/pdf/2004.11207.pdf
01 研究背景
随着transformer模型的提出与不断发展,NLP领域迎来了近乎大一统的时代,绝大多数预训练方法例如BERT等都将transformer结构作为模型的框架基础,在NLP许多领域的SOTA框架中也常常能看到它的身影。
而transformer的成功很大程度上得益于多头注意力机制,这一机制可对输入的上下文信息进行编码,并且使得模型学习到不同输入token之间的依赖关系。
在多头注意力的可解释性研究方面,有些学者侧重于对注意力权重的分析,重点讨论权重大的特征,有些将模型决策的关注点放在输入的token上,还有部分学者认为注意力机制的分布是无法直接解释的。
相比于过去的研究,本文提出了一种自注意力机制的归因算法,可对transformer内部的信息交互进行可解释性的说明。
通过该方法,模型可识别较重要的注意力head,将其他不重要的head进行有效裁剪。还可通过构建归因树(attribution tree)将不同层之间的信息交互进行直观的可视化表示。
最后,文章还以bert作为扩展的实例应用,通过对归因结果分析构建的Adversarial trigger对Bert发动攻击,使得bert的预测能力显著下降。
02 Transformer简介
首先让我们来重新回顾一下Transformer结构。一般Transformer的结构是由encoder和decoder两部分组成,两者各包含N=6的layer,每个layer由两个sub-layer组成,分别为多头自注意力和全连接网络,具体如图1所示。
Transformer模型的成功很大程度上得益于多头注意力机制。假定每个layer的attention heads数量为h,第h个attention head可用下式(1),(2),(3)表示
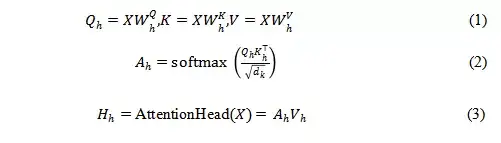
那么每一层多头注意力可表示为:
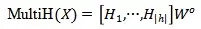
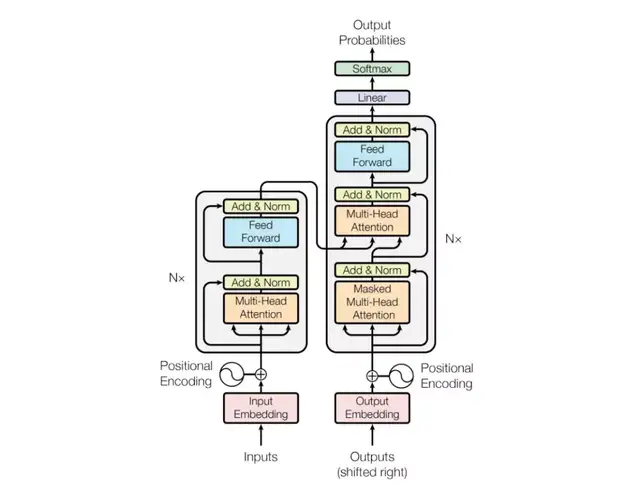
图1 transformer结构示意图
03 self-attention attribution 概念的提出
以往文章在对attention进行解释时,常常关注计算得来的attention score,由图二中的(a)图可以看出,通过(2)式计算的attention score matrix是十分稠密的,无法直接获得transformer内部真实的交互信息,并且两个单词之间的权重较大,也无法直接说明他们对最终的模型预测产生了重要的影响。
为此作者提出了一种自注意力的归因方法。
假设输入的句子为x,
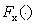
表示transformer模型,
注意力权重矩阵A代表模型的输入,作者希望计算每一对注意力之间的归因分数 (attention attribution: ATTATTR) 来表示其对模型决策的影响大小。
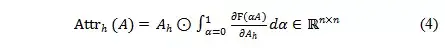
以第h个attention head为例,其归因分数的计算法方法如式(4)所示,值从0到1的积分过程中,每一对attention connection (i,j)对模型的预测影响越大,它的梯度大小就会越显著,因此积分的值也会越大。
在实际的计算中,作者通过(5)式Riemman 估计来对积分过程进行了简化,
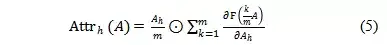
以一个finetune过后的bert模型中的某一个head为例,通过图2可以看出,attention score值较大并不意味着对最终的预测有更大的贡献,例如[SEP] 和其他token之间的attention score很大,但是最终计算的归因分数却很小。
对上下两句之间关系“contradiction”的预测,主要还是归因于第一个句子中的“don’t”和第二句中的“I know”,这一结果也基本符合常识。
可以看出,attribution score更能体现出输入token之间attention的依赖关系对模型预测的贡献。

图2 attention score 和attribution score 示意图
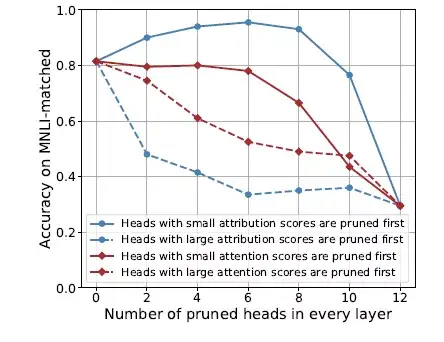
图3 ATTATTR有效性分析
如图3所示,在MNLI(Multi-genre Natural Language Inference) 数据集上,对BERT每一层中attribution scores最高的head进行裁剪,对下游任务预测的准确率影响要大于按照attention scores裁剪,进一步说明attribution score的大小更能反映attention connection 对模型预测能力的影响大小。
从蓝色虚线可以进一步看出仅仅对每一层中top2 的attribution scores进行裁剪就会造成模型预测准确率的巨大下降。
04 研究应用
既然知道每个head中attribution score的“强大威力”, 我们又该如何有效的利用它呢?
在本文的实验部分,作者基于Bert的预训练模型,对下游的四个典型分类任务进行了微调,并基于此说明了attribution 方法的实用价值。
l Attention head 的裁剪
已知attribution score的大小体现了自注意力之间的关系对模型最终决策的影响,作者又对每个attention head定义了其重要性,如(6)式所示,
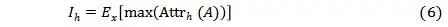
其中x代表了从留出的数据集中采样出的样本, max(Attrh(A)) 代表第h个attention head中最大的attribution value。
将该指标和其他的重要性对比评价指标:准确率差异和Taylor展开方法对比,实验时,将对应指标下重要性较低的head先进行裁剪。
由图4可以看出,按照ATTATTR方法对head进行裁剪的方法对模型预测准确率的损失要明显低于按照准确率差异的方法,并且取得了和Taylor展开方法相当甚至更好的结果。
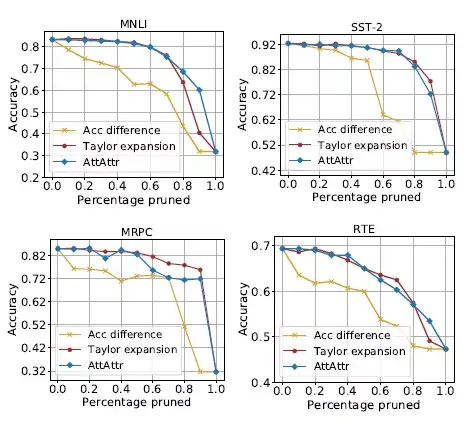
图4 按照不同重要性方法对head裁剪后模型预测准确率的变化情况
Transformer内部信息交互的可视化
基于前面提出的attribution score的方法,文章又提出了一种启发式的算法来构建attribution tree,以进一步揭示transformer内部的信息流动,使人能够更直观地理解输入的单词和最终预测之间的联系。
首先在计算每一层的attribution score的时候,需要将每个head的score做加和。
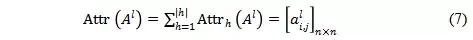
最终构建的attribution tree 需要在最大化attribution score 和使得树中维持边的数量最小之间权衡,因此目标函数可以表示为,
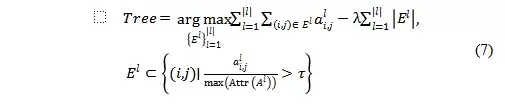
为了避免求解这个联合优化的问题,作者使用了一种自上而下的启发式的算法来生成attribution tree的边,具体算法细节可以参考下图。

图5 Attribution Tree的构建方法
那么通过attribution tree, 又具体得到什么有趣的信息呢?
文章以MNLI数据集中的一对语句为例进行了解释,如下图6所示,该任务的目标是判断两句话之间的关系是矛盾、中立还是相似。
从树的底部可以看到,信息之间的交互仅局限于本句中,是相对local的。
然后随着信息的聚合汇总,两个句子分别聚焦在“supplement”和“extra”两个单词上,从“extra”中可以明显看到“add something extra”信息和“supplement”是强相关且相似的,最终所有信息汇聚到[CLS] token上,做出“entailment”的预测。
可以看出,attribution tree 将整个信息流动的过程清晰的可视化了,增强了transformer模型的可解释性,使人能够更方便的去理解任务以及找到模型可能的改进方向。
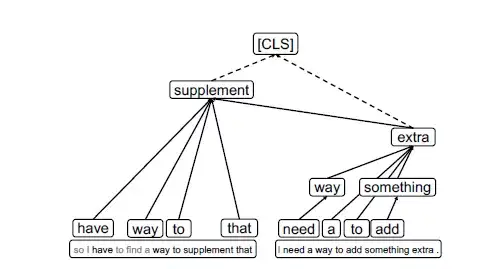
图6 MNLI数据集中的某一例子
对BERT模型的非目标攻击
通过对transformer内部信息流动观察,可以进一步发现模型的预测受attribution score较大的一些attention connection的影响较大,而很容易忽视其他大部分的输入信息。
因此文章这里采用over-confident 的模式作为adversarial triggers 来攻击bert模型。
具体实验时,文章首先通过不同层中最大的attribution scores 来提取attention 之间的依赖关系,然后将提取出来的这些依赖关系的对应模式当做adversarial triggers添加到想要攻击的样本中,从而改变原始样本的预测结果。
如下图7所示,整个攻击过程首先将最上方这个预测为contradict的句子对中对结果贡献最大的两个模式“floods-ice”和“Iowa-Florida”抽提出来, 将他们作为trigger加入到下面两个测试的样本中去,可以看到模型的预测结果从原来准确的“entailment”和“neutral”错误的预测成了“contradict”,是不是非常神奇!

图7使用ATTATTR来提取trigger进行攻击
由此也可以看出,bert模型在预测时会过度依赖一些特定的trigger模式来做预测,这样一旦添加一些其他容易混淆的trigger时,就很容易受到攻击从而造成预测显著失真。
05 总结
相比于其他文章将关注点放在注意力权重上的分析和讨论,这篇文章从attribution score这个全新的角度分析了注意力依赖之间的关系以及它对模型预测结果的影响。
此外在应用方面,作者从head 裁剪、transformer内部信息流的可视化以及通过构建adversarial triggers来攻击bert等方面给出了非常有趣且实用的示例,可以看到以transformer为基础架构的预训练模型的预测还十分依赖学到的某种特殊关系对,未来在充分了解attention内部的真实依赖关系的前提下,还需要针对下游任务引入一些新的约束和指导,以便更好地利用输入的信息,提升模型预测的鲁棒性。
参考文献
[1] Hao Y, Dong L, Wei F, et al. Self-Attention Attribution: Interpreting Information Interactions Inside Transformer[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(14): 12963-12971.
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。
标签:Transformer,attribution,transformer,模型,attention,解释性,score,head,注意力 来源: https://www.cnblogs.com/NLPlunwenjiedu/p/15867500.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。