标签:... Name 训练 env agent Reinforcement learning Matlab
在Matlab 上使用 Reinforcement learning
环境搭建
在Matlab中安装Deep Learning Toolbox后安装Reinforcement Learning Toolbox
什么是强化学习
强化学习的最终目标是在未知的环境中训练一个agent,这个agent接受来自环境的observation与reward并对环境输出action,其中的reward用来表示当前动作对任务目标的贡献。
agent由policy和Reinforcement learning algorithm两部分构成.
- policy部分相当于闭环控制系统中的控制器。
- reinforcement learning algorithm部分基于observation, action, reward对policy的参数进行调节。其目标是找到一个最优的policy最大化累计reward。
在Matlab使用reinforcement learning入门
直立小车环境模拟
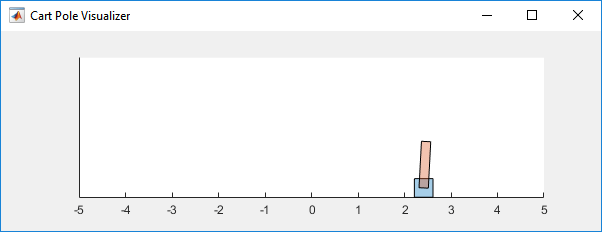
对于环境:
- 直立状态角度为0,垂直向下角度为pi
- 开始状态的初始角度在-0.05~0.05之间
- 从agent到enviroment的力量信号在-10~10N之间
- 观察量为:位置,速度,角度和角速度。
- 如果角度偏差超过12o或者移动距离大于2.4m则终止程序
- 每当处于直立状态时+1分,每当倒下-5分。
创建预设环境
可以使用rlPredefinedEnv调用Matlab预设的环境。环境中包含了reset和step两个函数,这两个函数描述了环境的功能细节。
env = rlPredefinedEnv("CartPole-Discrete");
env =
CartPoleDiscreteAction with properties:
Gravity: 9.8000
MassCart: 1
MassPole: 0.1000
Length: 0.5000
MaxForce: 10
Ts: 0.0200
ThetaThresholdRadians: 0.2094
XThreshold: 2.4000
RewardForNotFalling: 1
PenaltyForFalling: -5
State: [4x1 double]
obsInfo = getObservationInfo(env);
obsInfo =
rlNumericSpec with properties:
LowerLimit: -Inf
UpperLimit: Inf
Name: "CartPole States"
Description: "x, dx, theta, dtheta"
Dimension: [4 1]
DataType: "double"
actInfo = getActionInfo(env);
rng(0);
创建DQN Agent
接着创建PG Agent,首先需要创建Policy的神经网络结构,该网络结构决定了强化学习的表现的上限, 再使用rlStochasticActorRepresentation对该网络进行representation,接着按默认选项创建PGAgent即可。
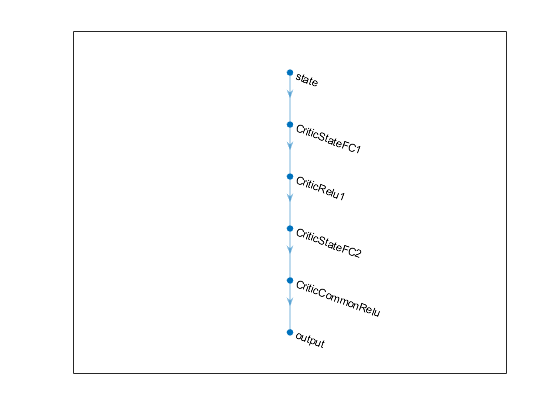
dnn = [
featureInputLayer(obsInfo.Dimension(1),'Normalization','none','Name','state')
fullyConnectedLayer(24,'Name','CriticStateFC1')
reluLayer('Name','CriticRelu1')
fullyConnectedLayer(24, 'Name','CriticStateFC2')
reluLayer('Name','CriticCommonRelu')
fullyConnectedLayer(length(actInfo.Elements),'Name','output')];
该网络的结构
figure
plot(layerGraph(dnn))
使用rlRepresentationOptions设定一些评价器参数
criticOpts = rlRepresentationOptions('LearnRate',0.001,'GradientThreshold',1);
创建一个critic
critic = rlQValueRepresentation(dnn,obsInfo,actInfo,'Observation',{'state'},criticOpts);
使用rlDQNAgentOptions设定一些agent参数,并使用rlPGAgent创造一个agent
agentOpts = rlDQNAgentOptions(...
'UseDoubleDQN',false, ...
'TargetSmoothFactor',1, ...
'TargetUpdateFrequency',4, ...
'ExperienceBufferLength',100000, ...
'DiscountFactor',0.99, ...
'MiniBatchSize',256);
agent = rlDQNAgent(critic,agentOpts);
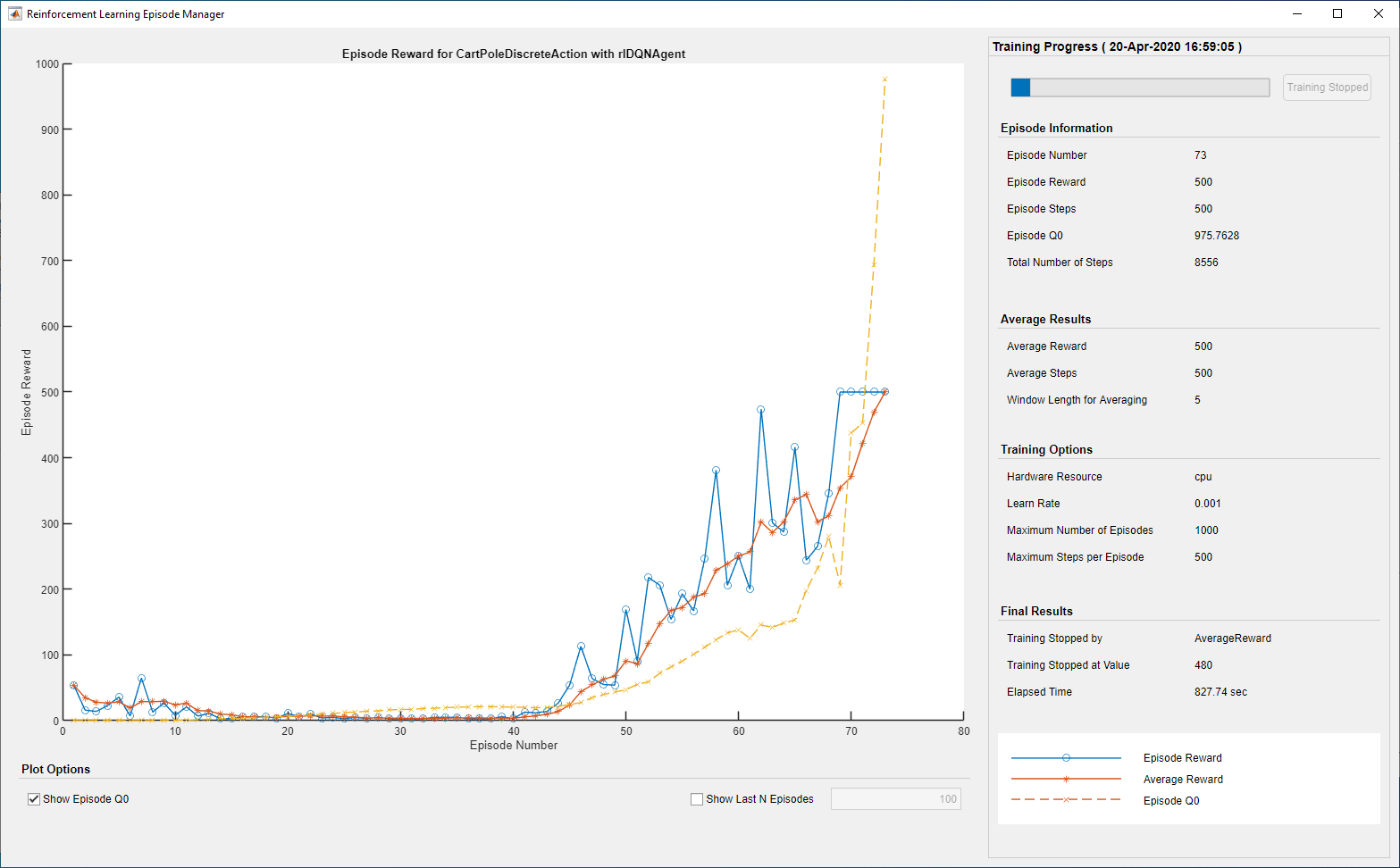
训练Agent
为了训练agent,首先需要设定一些参数,我们在这里使用下列的参数:
- 运行一次最多包含 1000 个片段的训练,每个片段最多持续 500 个时间步长。
- 在Episode Manager dialog box中显示训练过程,禁用命令行显示
- 当agent平均得分大于480的时候停止训练
trainOpts = rlTrainingOptions(...
'MaxEpisodes',1000, ...
'MaxStepsPerEpisode',500, ...
'Verbose',false, ...
'Plots','training-progress',...
'StopTrainingCriteria','AverageReward',...
'StopTrainingValue',480);
在训练或者仿真时可以用plot观看。
plot(env)
通过使用train来训练。
doTraining = false;
if doTraining
% Train the agent.
trainingStats = train(agent,env,trainOpts);
else
% Load the pretrained agent for the example.
load('MATLABCartpoleDQNMulti.mat','agent')
end
DQN agent仿真
为了验证训练出的agent的性能,将agent在环境中进行仿真。使用rlSimulationOptions和sim函数
simOptions = rlSimulationOptions('MaxSteps',500);
experience = sim(env,agent,simOptions);
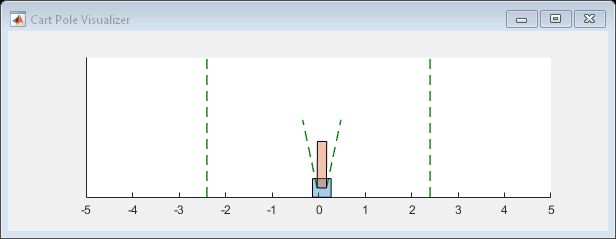
totalReward = sum(experience.Reward)
totalReward = 500
标签:...,Name,训练,env,agent,Reinforcement,learning,Matlab 来源: https://www.cnblogs.com/lyrorz/p/15675722.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。