标签:kubectl 常用 node01 name 对象 nginx 操作 Pod root
常用对象操作:(4)
1. Replication Controller与Replica Set
1.1 使用Replication Controller、Replica Set 管理Pod
前面我们的课程中学习了Pod的一些基本使用方法,而且前面我们都是直接来操作的Pod,假如我们现在有一个Pod正在提供线上的服务,我们来想想一下我们可能会遇到的一些场景:
- 某次运营活动非常成功,网站访问量突然暴增
- 运行当前
Pod的节点发生故障了,Pod不能正常提供服务了
第一种情况,可能比较好应对,一般活动之前我们会大概计算下会有多大的访问量,提前多启动几个Pod,活动结束后再把多余的Pod杀掉,虽然有点麻烦,但是应该还是能够应对这种情况的。
第二种情况,可能某天夜里收到大量报警说服务挂了,然后起来打开电脑在另外的节点上重新启动一个新的Pod,问题也很好的解决了。
如果我们都人工的去解决遇到的这些问题,似乎又回到了以前刀耕火种的时代了是吧,如果有一种工具能够来帮助我们管理Pod就好了,Pod不够了自动帮我新增一个,Pod挂了自动帮我在合适的节点上重新启动一个Pod,这样是不是遇到上面的问题我们都不需要手动去解决了。
幸运的是,
Kubernetes就为我们提供了这样的资源对象:
- Replication Controller:用来部署、升级Pod
- Replica Set:下一代的Replication Controller
- Deployment:可以更加方便的管理Pod和Replica Set
1.2 Replication Controller(RC)
Replication Controller简称RC,RC是Kubernetes系统中的核心概念之一,简单来说,RC可以保证在任意时间运行Pod的副本数量,能够保证Pod总是可用的。如果实际Pod数量比指定的多那就结束掉多余的,如果实际数量比指定的少就新启动一些Pod,当Pod失败、被删除或者挂掉后,RC都会去自动创建新的Pod来保证副本数量,所以即使只有一个Pod,我们也应该使用RC来管理我们的Pod。
我们想想如果现在我们遇到上面的问题的话,可能除了第一个不能做到完全自动化,其余的我们是不是都不用担心了,运行Pod的节点挂了,RC检测到Pod失败了,就会去合适的节点重新启动一个Pod就行,不需要我们手动去新建一个Pod了。如果是第一种情况的话在活动开始之前我们给Pod指定10个副本,结束后将副本数量改成2,这样是不是也远比我们手动去启动、手动去关闭要好得多,而且我们后面还会给大家介绍另外一种资源对象HPA可以根据资源的使用情况来进行自动扩缩容,这样以后遇到这种情况,我们就真的可以安心的去睡觉了。
现在我们来使用RC来管理我们前面使用的Nginx的Pod,YAML文件如下:
[root@node01 ~]# vim rc-demo.yaml
[root@node01 ~]# cat rc-demo.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: rc-demo
labels:
name: rc
spec:
replicas: 3
selector:
name: rc
template:
metadata:
labels:
name: rc
spec:
containers:
- name: nginx-demo
image: nginx
ports:
- containerPort: 80
上面的YAML文件相对于我们之前的Pod的格式:
- kind:
ReplicationController- spec.replicas: 指定
Pod副本数量,默认为1- spec.selector:
RC通过该属性来筛选要控制的Pod- spec.template: 这里就是我们之前的
Pod的定义的模块,但是不需要apiVersion和kind了- spec.template.metadata.labels: 注意这里的
Pod的labels要和spec.selector相同,这样RC就可以来控制当前这个Pod了。
这个YAML文件中的意思就是定义了一个RC资源对象,它的名字叫rc-demo,保证一直会有3个Pod运行,Pod的镜像是nginx镜像。
注意
spec.selector和spec.template.metadata.labels这两个字段必须相同,否则会创建失败的,当然我们也可以不写spec.selector,这样就默认与Pod
模板中的metadata.labels相同了。所以为了避免不必要的错误的话,不写为好。
然后我们来创建上面的RC对象(保存为 rc-demo.yaml):
[root@node01 ~]# kubectl create -f rc-demo.yaml
replicationcontroller "rc-demo" created
查看RC:
[root@node01 ~]# kubectl get rc
NAME DESIRED CURRENT READY AGE
rc-demo 3 3 0 17s
查看具体信息:
[root@node01 ~]# kubectl describe rc rc-demo
Name: rc-demo
Namespace: default
Selector: name=rc
Labels: name=rc
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 0 Running / 3 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: name=rc
Containers:
nginx-demo:
Image: nginx
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 1m replication-controller Created pod: rc-demo-d2kw8
Normal SuccessfulCreate 1m replication-controller Created pod: rc-demo-9cdm8
Normal SuccessfulCreate 1m replication-controller Created pod: rc-demo-rqb6b
然后我们通过RC来修改下Pod的副本数量为2:
[root@node01 ~]# kubectl apply -f rc-demo.yaml
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
replicationcontroller "rc-demo" configured
或者
[root@node01 ~]# kubectl edit rc rc-demo
而且我们还可以用RC来进行滚动升级,比如我们将镜像地址更改为nginx:1.7.9:
$ kubectl rolling-update rc-demo --image=nginx:1.7.9
但是如果我们的Pod中多个容器的话,就需要通过修改YAML文件来进行修改了:
$ kubectl rolling-update rc-demo -f rc-demo.yaml
如果升级完成后出现了新的问题,想要一键回滚到上一个版本的话,使用RC只能用同样的方法把镜像地址替换成之前的,然后重新滚动升级。
1.3 Replication Set(RS)
Replication Set简称RS,随着Kubernetes的高速发展,官方已经推荐我们使用RS和Deployment来代替RC了,实际上RS和RC的功能基本一致,目前唯一的一个区别就是RC只支持基于等式的selector(env=dev或environment!=qa),但RS还支持基于集合的selector(version in (v1.0, v2.0)),这对复杂的运维管理就非常方便了。
kubectl命令行工具中关于RC的大部分命令同样适用于我们的RS资源对象。不过我们也很少会去单独使用RS,它主要被Deployment这个更加高层的资源对象使用,除非用户需要自定义升级功能或根本不需要升级Pod,在一般情况下,我们推荐使用Deployment而不直接使用Replica Set。
最后我们总结下关于
RC/RS的一些特性和作用吧:
- 大部分情况下,我们可以通过定义一个
RC实现的Pod的创建和副本数量的控制RC中包含一个完整的Pod定义模块(不包含apiversion和kind)RC是通过label selector机制来实现对Pod副本的控制的- 通过改变
RC里面的Pod副本数量,可以实现Pod的扩缩容功能- 通过改变
RC里面的Pod模板中镜像版本,可以实现Pod的滚动升级功能(但是不支持一键回滚,需要用相同的方法去修改镜像地址)
2. Deployment
2.1 Deployment的使用
前面的课程中我们学习了Replication Controller和Replica Set两种资源对象,RC和RS的功能基本上是差不多的,唯一的区别就是RS支持集合的selector。我们也学习到了用RC/RS来控制Pod副本的数量,也实现了滚动升级Pod的功能。现在看上去似乎一切都比较完美的运行着,但是我们上节课最后也提到了现在我们推荐使用Deployment这种控制器了,而不是我们之前的RC或者RS,这是为什么呢?
没有对比就没有伤害对吧,我们来对比下二者之间的功能吧,首先RC是Kubernetes的一个核心概念,当我们把应用部署到集群之后,需要保证应用能够持续稳定的运行,RC就是这个保证的关键,主要功能如下:
- 确保
Pod数量:它会确保Kubernetes中有指定数量的Pod在运行,如果少于指定数量的Pod,RC就会创建新的,反之这会删除多余的,保证Pod的副本数量不变。- 确保
Pod健康:当Pod不健康,比如运行出错了,总之无法提供正常服务时,RC也会杀死不健康的Pod,重新创建新的。- 弹性伸缩:在业务高峰或者低峰的时候,可以用过
RC来动态的调整Pod数量来提供资源的利用率,当然我们也提到过如果使用HPA这种资源对象的话可以做到自动伸缩。- 滚动升级:滚动升级是一种平滑的升级方式,通过逐步替换的策略,保证整体系统的稳定性。
Deployment同样也是Kubernetes系统的一个核心概念,主要职责和RC一样的都是保证Pod的数量和健康,二者大部分功能都是完全一致的,我们可以看成是一个升级版的RC控制器,那Deployment又具备那些新特性呢?
RC的全部功能:Deployment具备上面描述的RC的全部功能- 事件和状态查看:可以查看
Deployment的升级详细进度和状态- 回滚:当升级
Pod的时候如果出现问题,可以使用回滚操作回滚到之前的任一版本- 版本记录:每一次对
Deployment的操作,都能够保存下来,这也是保证可以回滚到任一版本的基础- 暂停和启动:对于每一次升级都能够随时暂停和启动
作为对比,我们知道Deployment作为新一代的RC,不仅在功能上更为丰富了,同时我们也说过现在官方也都是推荐使用Deployment来管理Pod的,比如一些官方组件kube-dns、kube-proxy也都是使用的Deployment来管理的,所以当大家在使用的使用也最好使用Deployment来管理Pod。
2.2 创建
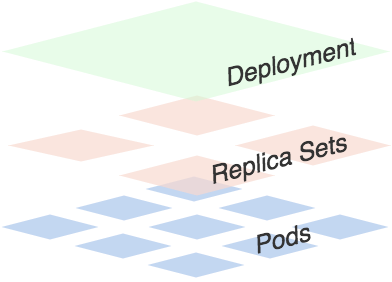
可以看出一个Deployment拥有多个Replica Set,而一个Replica Set拥有一个或多个Pod。一个Deployment控制多个rs主要是为了支持回滚机制,每当Deployment操作时,Kubernetes会重新生成一个Replica Set并保留,以后有需要的话就可以回滚至之前的状态。
下面创建一个Deployment,它创建了一个Replica Set来启动3个nginx pod,yaml文件如下:
[root@node01 ~]# vim nginx-deployment.yaml
[root@node01 ~]# cat nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
labels:
k8s-app: nginx-demo
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
将上面内容保存为: nginx-deployment.yaml,执行命令:
[root@node01 ~]# kubectl create -f nginx-deployment.yaml
deployment.apps "nginx-deploy" created
然后执行一下命令查看刚刚创建的Deployment:
[root@node01 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deploy 3 3 3 0 6s
隔一会再次执行上面命令:
[root@node01 ~]# kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deploy 3 3 3 3 1m
我们可以看到Deployment已经创建了1个Replica Set了,执行下面的命令查看rs和pod:
[root@node01 ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deploy-75675f5897 3 3 3 1m
[root@node01 ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deploy-75675f5897-jrx57 1/1 Running 0 2m app=nginx,pod-template-hash=3123191453
nginx-deploy-75675f5897-r4j2j 1/1 Running 0 2m app=nginx,pod-template-hash=3123191453
nginx-deploy-75675f5897-rpp4m 1/1 Running 0 2m app=nginx,pod-template-hash=3123191453
上面的Deployment的yaml文件中的replicas:3将会保证我们始终有3个POD在运行。
由于Deployment和RC的功能大部分都一样的,我们上节课已经和大家演示了大部分功能了,我们这里重点给大家演示下Deployment的滚动升级和回滚功能。
2.3 滚动升级
现在我们将刚刚保存的yaml文件中的nginx镜像修改为nginx:1.13.3,然后在spec下面添加滚动升级策略:
[root@node01 ~]# tail -7 nginx-deployment.yaml
minReadySeconds: 5
strategy:
# indicate which strategy we want for rolling update
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds:
- Kubernetes在等待设置的时间后才进行升级
- 如果没有设置该值,Kubernetes会假设该容器启动起来后就提供服务了
- 如果没有设置该值,在某些极端情况下可能会造成服务不正常运行
...
maxSurge:- 升级过程中最多可以比原先设置多出的POD数量
- 例如:maxSurage=1,replicas=5,则表示Kubernetes会先启动1一个新的Pod后才删掉一个旧的POD,整个升级过程中最多会有5+1个POD。
...
maxUnavaible:- 升级过程中最多有多少个POD处于无法提供服务的状态
- 当
maxSurge不为0时,该值也不能为0- 例如:maxUnavaible=1,则表示Kubernetes整个升级过程中最多会有1个POD处于无法服务的状态。
然后执行命令:
[root@node01 ~]# kubectl apply -f nginx-deployment.yaml --validate=false
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
deployment.apps "nginx-deploy" configured
然后我们可以使用rollout命令:
查看状态:
[root@node01 ~]# kubectl rollout status deployment/nginx-deploy
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for rollout to finish: 1 old replicas are pending termination...
Waiting for rollout to finish: 1 old replicas are pending termination...
deployment "nginx-deploy" successfully rolled out
暂停升级
$ kubectl rollout pause deployment <deployment>
继续升级
$ kubectl rollout resume deployment <deployment>
升级结束后,继续查看rs的状态:
[root@node01 ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deploy-594b456c98 3 3 3 1m
nginx-deploy-75675f5897 0 0 0 10m
根据AGE我们可以看到离我们最近的当前状态是:3,和我们的yaml文件是一致的,证明升级成功了。用describe命令可以查看升级的全部信息:
[root@node01 ~]# kubectl describe rs nginx-deploy
Name: nginx-deploy-594b456c98
Namespace: default
Selector: app=nginx,pod-template-hash=1506012754
Labels: app=nginx
pod-template-hash=1506012754
Annotations: deployment.kubernetes.io/desired-replicas=3
deployment.kubernetes.io/max-replicas=4
deployment.kubernetes.io/revision=2
Controlled By: Deployment/nginx-deploy
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
pod-template-hash=1506012754
Containers:
nginx:
Image: nginx:1.13.3
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 15m replicaset-controller Created pod: nginx-deploy-594b456c98-jrkgx
Normal SuccessfulCreate 15m replicaset-controller Created pod: nginx-deploy-594b456c98-gz5zv
Normal SuccessfulCreate 14m replicaset-controller Created pod: nginx-deploy-594b456c98-w6kcc
Name: nginx-deploy-75675f5897
Namespace: default
Selector: app=nginx,pod-template-hash=3123191453
Labels: app=nginx
pod-template-hash=3123191453
Annotations: deployment.kubernetes.io/desired-replicas=3
deployment.kubernetes.io/max-replicas=4
deployment.kubernetes.io/revision=1
Controlled By: Deployment/nginx-deploy
Replicas: 0 current / 0 desired
Pods Status: 0 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
pod-template-hash=3123191453
Containers:
nginx:
Image: nginx:1.7.9
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 24m replicaset-controller Created pod: nginx-deploy-75675f5897-jrx57
Normal SuccessfulCreate 24m replicaset-controller Created pod: nginx-deploy-75675f5897-rpp4m
Normal SuccessfulCreate 24m replicaset-controller Created pod: nginx-deploy-75675f5897-r4j2j
Normal SuccessfulDelete 15m replicaset-controller Deleted pod: nginx-deploy-75675f5897-jrx57
Normal SuccessfulDelete 14m replicaset-controller Deleted pod: nginx-deploy-75675f5897-rpp4m
Normal SuccessfulDelete 14m replicaset-controller Deleted pod: nginx-deploy-75675f5897-r4j2j
2.4 回滚Deployment
我们已经能够滚动平滑的升级我们的Deployment了,但是如果升级后的POD出了问题该怎么办?我们能够想到的最好最快的方式当然是回退到上一次能够提供正常工作的版本,Deployment就为我们提供了回滚机制。
首先,查看Deployment的升级历史:
[root@node01 ~]# kubectl rollout history deployment nginx-deploy
deployments "nginx-deploy"
REVISION CHANGE-CAUSE
1 <none>
2 <none>
从上面的结果可以看出在执行Deployment升级的时候最好带上record参数,便于我们查看历史版本信息。
默认情况下,所有通过kubectl xxxx --record都会被kubernetes记录到etcd进行持久化,这无疑会占用资源,最重要的是,时间久了,当你kubectl get rs时,会有成百上千的垃圾RS返回给你,那时你可能就眼花缭乱了。
上生产时,我们最好通过设置Deployment的.spec.revisionHistoryLimit来限制最大保留的revision number,比如15个版本,回滚的时候一般只会回滚到最近的几个版本就足够了。其实rollout history中记录的revision都和ReplicaSets一一对应。如果手动delete某个ReplicaSet,对应的rollout history就会被删除,也就是还说你无法回滚到这个revison了。
rollout history和ReplicaSet的对应关系,可以在kubectl describe rs $RSNAME返回的revision字段中得到,这里的revision就对应着rollout history返回的revison。
同样我们可以使用下面的命令查看单个revison的信息:
[root@node01 ~]# kubectl rollout history deployment nginx-deploy --revision=2
deployments "nginx-deploy" with revision #2
Pod Template:
Labels: app=nginx
pod-template-hash=1506012754
Containers:
nginx:
Image: nginx:1.13.3
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
假如现在要直接回退到当前版本的前一个版本:
$ kubectl rollout undo deployment nginx-deploy
deployment "nginx-deploy" rolled back
当然也可以用revision回退到指定的版本:
$ kubectl rollout undo deployment nginx-deploy --to-revision=2
deployment "nginx-deploy" rolled back
现在可以用命令查看Deployment现在的状态了。
3. HPA
Pod 自动扩缩容
在前面的课程中,我们提到过通过手工执行kubectl scale命令和在Dashboard上操作可以实现Pod的扩缩容,但是这样毕竟需要每次去手工操作一次,而且指不定什么时候业务请求量就很大了,所以如果不能做到自动化的去扩缩容的话,这也是一个很麻烦的事情。如果Kubernetes系统能够根据Pod当前的负载的变化情况来自动的进行扩缩容就好了,因为这个过程本来就是不固定的,频繁发生的,所以纯手工的方式不是很现实。
幸运的是Kubernetes为我们提供了这样一个资源对象:Horizontal Pod Autoscaling(Pod水平自动伸缩),简称HPA。HAP通过监控分析RC或者Deployment控制的所有Pod的负载变化情况来确定是否需要调整Pod的副本数量,这是HPA最基本的原理。
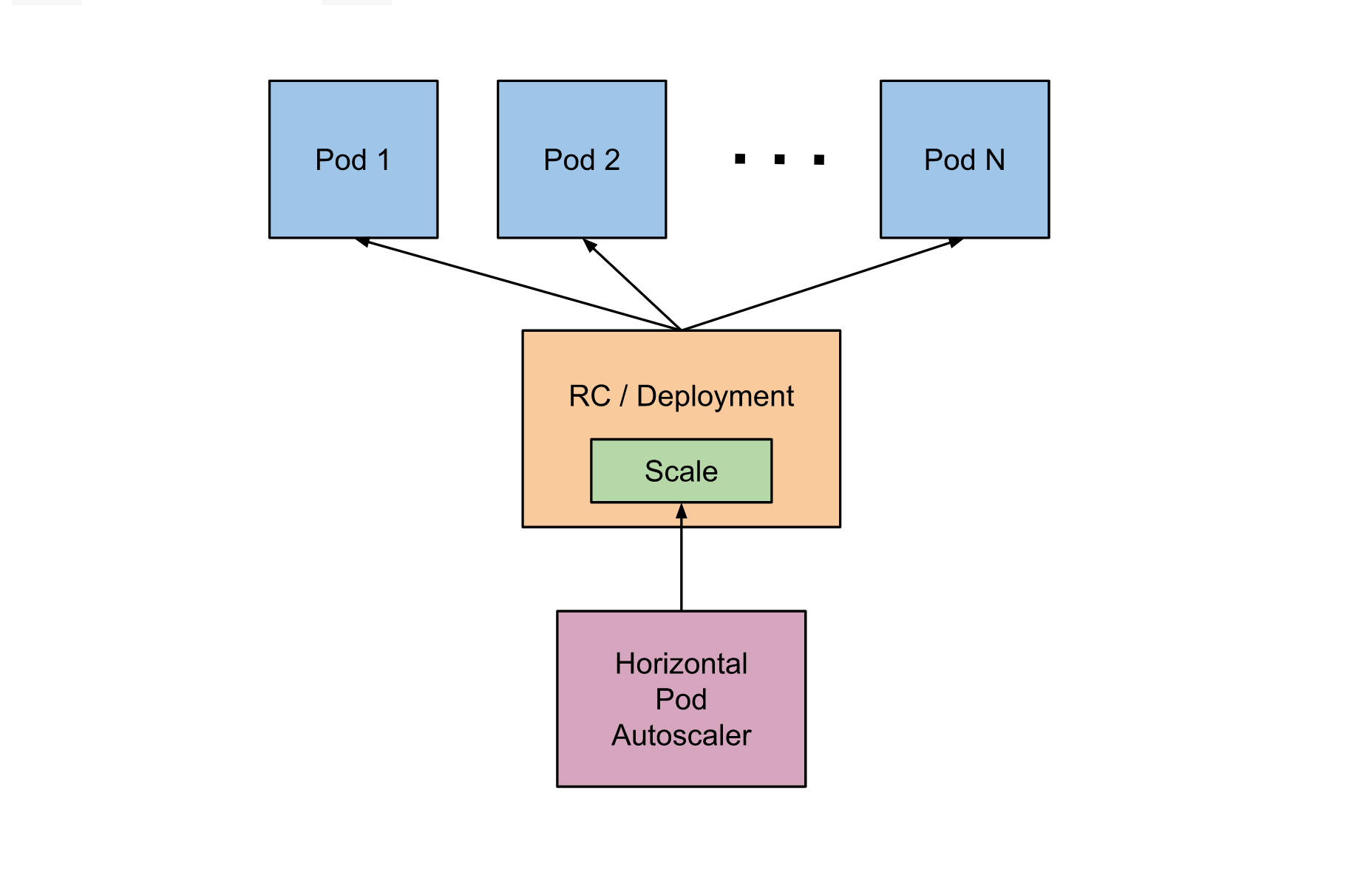
HPA在kubernetes集群中被设计成一个controller,我们可以简单的通过kubectl autoscale命令来创建一个HPA资源对象,HPA Controller默认30s轮询一次(可通过kube-controller-manager的标志--horizontal-pod-autoscaler-sync-period进行设置),查询指定的资源(RC或者Deployment)中Pod的资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
当你创建了HPA后,HPA会从Heapster或者用户自定义的RESTClient端获取每一个一个Pod利用率或原始值的平均值,然后和HPA中定义的指标进行对比,同时计算出需要伸缩的具体值并进行相应的操作。目前,HPA可以从两个地方获取数据:
- Heapster:仅支持
CPU使用率- 自定义监控:我们到后面的监控的课程中再给大家讲解这部分的使用方法
我们这节课来给大家介绍从Heapster获取监控数据来进行自动扩缩容的方法,所以首先我们得安装Heapster,前面我们在kubeadm搭建集群的课程中,实际上我们已经默认把Heapster相关的镜像都已经拉取到节点上了,所以接下来我们只需要部署即可,我们这里使用的是Heapster 1.4.2 版本的,前往Heapster的github页面:
https://github.com/kubernetes/heapster
我们将该目录下面的yaml文件保存到我们的集群上,然后使用kubectl命令行工具创建即可,另外创建完成后,如果需要在Dashboard当中看到监控图表,我们还需要在Dashboard中配置上我们的heapster-host。
同样的,我们来创建一个Deployment管理的Nginx Pod,然后利用HPA来进行自动扩缩容。定义Deployment的YAML文件如下:(hpa-deploy-demo.yaml)
[root@node01 ~]# vim hpa-deploy-demo.yaml
[root@node01 ~]# cat hpa-deploy-demo.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-nginx-deploy
labels:
app: nginx-demo
spec:
revisionHistoryLimit: 15
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
然后创建Deployment:
[root@node01 ~]# kubectl create -f hpa-deploy-demo.yaml
deployment.apps "hpa-nginx-deploy" created
现在我们来创建一个HPA,可以使用kubectl autoscale命令来创建:
[root@node01 ~]# kubectl autoscale deployment hpa-nginx-deploy --cpu-percent=10 --min=1 --max=10
deployment.apps "hpa-nginx-deploy" autoscaled
[root@node01 ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy <unknown>/10% 1 10 1 32s
此命令创建了一个关联资源 hpa-nginx-deploy 的HPA,最小的 pod 副本数为1,最大为10。HPA会根据设定的 cpu使用率(10%)动态的增加或者减少pod数量。
当然出来使用kubectl autoscale命令来创建外,我们依然可以通过创建YAML文件的形式来创建HPA资源对象。如果我们不知道怎么编写的话,可以查看上面命令行创建的HPA的YAML文件:
[root@node01 ~]# kubectl get hpa hpa-nginx-deploy -o yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
annotations:
autoscaling.alpha.kubernetes.io/conditions: '[{"type":"AbleToScale","status":"True","lastTransitionTime":"2021-07-04T14:51:10Z","reason":"SucceededGetScale","message":"the
HPA controller was able to get the target''s current scale"},{"type":"ScalingActive","status":"False","lastTransitionTime":"2021-07-04T14:51:10Z","reason":"FailedGetResourceMetric","message":"the
HPA was unable to compute the replica count: unable to get metrics for resource
cpu: unable to fetch metrics from resource metrics API: the server could not
find the requested resource (get pods.metrics.k8s.io)"}]'
creationTimestamp: 2021-07-04T14:50:40Z
name: hpa-nginx-deploy
namespace: default
resourceVersion: "30703"
selfLink: /apis/autoscaling/v1/namespaces/default/horizontalpodautoscalers/hpa-nginx-deploy
uid: 337d5704-dcd7-11eb-8fc3-000c2927597c
spec:
maxReplicas: 10 #资源最大副本数
minReplicas: 1 #资源最小副本数
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment #需要伸缩的资源类型
name: hpa-nginx-deploy #需要伸缩的资源名称
targetCPUUtilizationPercentage: 10 #触发伸缩的cpu使用率
status:
currentReplicas: 1 #当前的副本数
desiredReplicas: 0 #期望的副本数
好,现在我们根据上面的YAML文件就可以自己来创建一个基于YAML的HPA描述文件了。
现在我们来增大负载进行测试,我们来创建一个busybox,并且循环访问上面创建的服务。
$ kubectl run -i --tty load-generator --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://172.16.255.60:4000; done
下图可以看到,HPA已经开始工作。
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 29% 1 10 27m
同时我们查看相关资源hpa-nginx-deploy的副本数量,副本数量已经从原来的1变成了3。
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 3 3 3 3 4d
同时再次查看HPA,由于副本数量的增加,使用率也保持在了10%左右。
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 9% 1 10 35m
同样的这个时候我们来关掉busybox来减少负载,然后等待一段时间观察下HPA和Deployment对象
$ kubectl get hpa
NAME REFERENCE TARGET CURRENT MINPODS MAXPODS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 10% 0% 1 10 48m
$ kubectl get deployment hpa-nginx-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
hpa-nginx-deploy 1 1 1 1 4d
可以看到副本数量已经由3变为1。
不过当前的HPA只有CPU使用率这一个指标,还不是很灵活的,在后面的课程中我们来根据我们自定义的监控来自动对Pod进行扩缩容。
4. Job/Cronjob
4.1 Job 和 Cronjob 的使用
上节课我们学习了Pod自动伸缩的方法,我们使用到了HPA这个资源对象,我们在后面的课程中还会和大家接触到HPA的。今天我们来给大家介绍另外一类资源对象:Job,我们在日常的工作中经常都会遇到一些需要进行批量数据处理和分析的需求,当然也会有按时间来进行调度的工作,在我们的Kubernetes集群中为我们提供了Job和CronJob两种资源对象来应对我们的这种需求。
Job负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。而CronJob则就是在Job上加上了时间调度。
4.2 Job
我们用Job这个资源对象来创建一个任务,我们定一个Job来执行一个倒计时的任务,定义YAML文件:
[root@node01 ~]# vim job.yaml
[root@node01 ~]# cat job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-demo
spec:
template:
metadata:
name: job-demo
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox
command:
- "bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
注意Job的RestartPolicy仅支持Never和OnFailure两种,不支持Always,我们知道Job就相当于来执行一个批处理任务,执行完就结束了,如果支持Always的话是不是就陷入了死循环了?
然后来创建该Job,保存为job-demo.yaml:
[root@node01 ~]# kubectl create -f ./job.yaml
job.batch "job-demo" created
然后我们可以查看当前的Job资源对象:
[root@node01 ~]# kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
job-demo 1 1 9m
注意查看我们的Pod的状态,同样我们可以通过kubectl logs来查看当前任务的执行结果。
4.3 CronJob
CronJob其实就是在Job的基础上加上了时间调度,我们可以:在给定的时间点运行一个任务,也可以周期性地在给定时间点运行。这个实际上和我们Linux中的crontab就非常类似了。
一个CronJob对象其实就对应中crontab文件中的一行,它根据配置的时间格式周期性地运行一个Job,格式和crontab也是一样的。
crontab的格式如下:
分 时 日 月 星期 要运行的命令 第1列分钟0~59 第2列小时0~23) 第3列日1~31 第4列月1~12 第5列星期0~7(0和7表示星期天) 第6列要运行的命令
#Kubernetes 默认没有 enable CronJob 功能,需要在 kube-apiserver 中加入这个功能
[root@master ~]# vim /etc/kubernetes/manifests/kube-apiserver.yaml
[root@master ~]# sed -n "42p" /etc/kubernetes/manifests/kube-apiserver.yaml
- --runtime-config=batch/v2alpha1=true
[root@master ~]# systemctl restart kubelet
现在,我们用CronJob来管理我们上面的Job任务,
[root@node01 ~]# vim cronjob-demo.yaml
[root@node01 ~]# cat cronjob-demo.yaml
apiVersion: batch/v2alpha1
kind: CronJob
metadata:
name: cronjob-demo
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: hello
image: busybox
args:
- "bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
我们这里的Kind是CronJob了,要注意的是.spec.schedule字段是必须填写的,用来指定任务运行的周期,格式就和crontab一样,另外一个字段是.spec.jobTemplate, 用来指定需要运行的任务,格式当然和Job是一致的。还有一些值得我们关注的字段.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit,表示历史限制,是可选的字段。它们指定了可以保留多少完成和失败的Job,默认没有限制,所有成功和失败的Job都会被保留。然而,当运行一个Cron Job时,Job可以很快就堆积很多,所以一般推荐设置这两个字段的值。如果设置限制的值为 0,那么相关类型的Job完成后将不会被保留。
接下来我们来创建这个cronjob
[root@node01 ~]# kubectl create -f cronjob-demo.yaml
cronjob.batch "cronjob-demo" created
当然,也可以用kubectl run来创建一个CronJob:
kubectl run hello --schedule="*/1 * * * *" --restart=OnFailure --image=busybox -- /bin/sh -c "date; echo Hello from the Kubernetes cluster"
[root@node01 ~]# kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob-demo */1 * * * * False 0 <none> 17s
[root@node01 ~]# kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
cronjob-demo-1625990160 1 1 44s
job-demo 1 1 23m
[root@node01 ~]# pods=$(kubectl get pods --selector=job-name=cronjob-demo-1625990160 --output=jsonpath={.items..metadata.name} -a)
Flag --show-all has been deprecated, will be removed in an upcoming release
一旦不再需要 Cron Job,简单地可以使用 kubectl 命令删除它:
[root@node01 ~]# kubectl delete cronjob cronjob-demo
cronjob.batch "cronjob-demo" deleted
一旦 Job 被删除,由 Job 创建的 Pod 也会被删除。注意,所有由名称为 “hello” 的 Cron Job 创建的 Job 会以前缀字符串 “hello-” 进行命名。如果想要删除当前 Namespace 中的所有 Job,可以通过命令 kubectl delete jobs --all 立刻删除它们。
5. Service
5.1 Service
我们前面的课程中学习了Pod的基本用法,我们也了解到Pod的生命是有限的,死亡过后不会复活了。我们后面学习到的RC和Deployment可以用来动态的创建和销毁Pod。尽管每个Pod都有自己的IP地址,但是如果Pod重新启动了的话那么他的IP很有可能也就变化了。这就会带来一个问题:比如我们有一些后端的Pod的集合为集群中的其他前端的Pod集合提供API服务,如果我们在前端的Pod中把所有的这些后端的Pod的地址都写死,然后去某种方式去访问其中一个Pod的服务,这样看上去是可以工作的,对吧?但是如果这个Pod挂掉了,然后重新启动起来了,是不是IP地址非常有可能就变了,这个时候前端就极大可能访问不到后端的服务了。
遇到这样的问题该怎么解决呢?在没有使用Kubernetes之前,我相信可能很多同学都遇到过这样的问题,不一定是IP变化的问题,比如我们在部署一个WEB服务的时候,前端一般部署一个Nginx作为服务的入口,然后Nginx后面肯定就是挂载的这个服务的大量后端,很早以前我们可能是去手动更改Nginx配置中的upstream选项,来动态改变提供服务的数量,到后面出现了一些服务发现的工具,比如Consul、ZooKeeper还有我们熟悉的etcd等工具,有了这些工具过后我们就可以只需要把我们的服务注册到这些服务发现中心去就可以,然后让这些工具动态的去更新Nginx的配置就可以了,我们完全不用去手工的操作了,是不是非常方便。
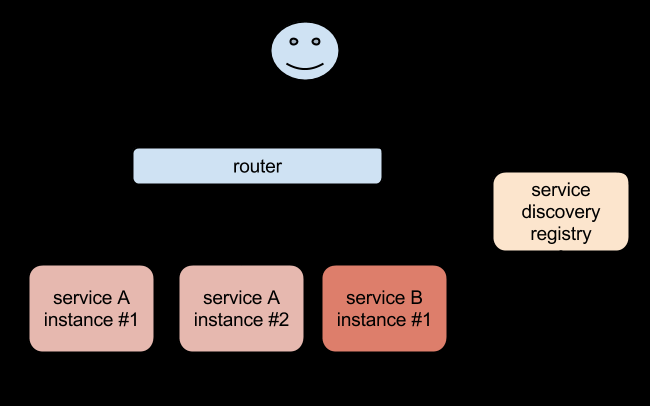
同样的,要解决我们上面遇到的问题是不是实现一个服务发现的工具也可以解决啊?没错的,当我们Pod被销毁或者新建过后,我们可以把这个Pod的地址注册到这个服务发现中心去就可以,但是这样的话我们的前端的Pod结合就不能直接去连接后台的Pod集合了是吧,应该连接到一个能够做服务发现的中间件上面,对吧?
没错,Kubernetes集群就为我们提供了这样的一个对象 - Service,Service是一种抽象的对象,它定义了一组Pod的逻辑集合和一个用于访问它们的策略,其实这个概念和微服务非常类似。一个Serivce下面包含的Pod集合一般是由Label Selector来决定的。
比如我们上面的例子,假如我们后端运行了3个副本,这些副本都是可以替代的,因为前端并不关心它们使用的是哪一个后端服务。尽管由于各种原因后端的Pod集合会发送变化,但是前端却不需要知道这些变化,也不需要自己用一个列表来记录这些后端的服务,Service的这种抽象就可以帮我们达到这种解耦的目的。
5.2 三种IP
在继续往下学习Service之前,我们需要先弄明白Kubernetes系统中的三种IP这个问题,因为经常有同学混乱。
- Node IP:
Node节点的IP地址- Pod IP:
Pod的IP地址- Cluster IP:
Service的IP地址
首先,Node IP是Kubernetes集群中节点的物理网卡IP地址(一般为内网),所有属于这个网络的服务器之间都可以直接通信,所以Kubernetes集群外要想访问Kubernetes集群内部的某个节点或者服务,肯定得通过Node IP进行通信(这个时候一般是通过外网IP了)
然后Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的(我们这里使用的是flannel这种网络插件保证所有节点的Pod IP不会冲突)
最后Cluster IP是一个虚拟的IP,仅仅作用于Kubernetes Service这个对象,由Kubernetes自己来进行管理和分配地址,当然我们也无法ping这个地址,他没有一个真正的实体对象来响应,他只能结合Service Port来组成一个可以通信的服务。
5.3 定义Service
定义Service的方式和我们前面定义的各种资源对象的方式类型,例如,假定我们有一组Pod服务,它们对外暴露了 8080 端口,同时都被打上了app=myapp这样的标签,那么我们就可以像下面这样来定义一个Service对象:
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 8080
name: myapp-http
然后通过的使用kubectl create -f myservice.yaml就可以创建一个名为myservice的Service对象,它会将请求代理到使用 TCP 端口为 8080,具有标签app=myapp的Pod上,这个Service会被系统分配一个我们上面说的Cluster IP,该Service还会持续的监听selector下面的Pod,会把这些Pod信息更新到一个名为myservice的Endpoints对象上去,这个对象就类似于我们上面说的Pod集合了。
需要注意的是,Service能够将一个接收端口映射到任意的targetPort。 默认情况下,targetPort将被设置为与port字段相同的值。 可能更有趣的是,targetPort 可以是一个字符串,引用了 backend Pod 的一个端口的名称。 因实际指派给该端口名称的端口号,在每个 backend Pod 中可能并不相同,所以对于部署和设计 Service ,这种方式会提供更大的灵活性。
另外Service能够支持 TCP 和 UDP 协议,默认是 TCP 协议。
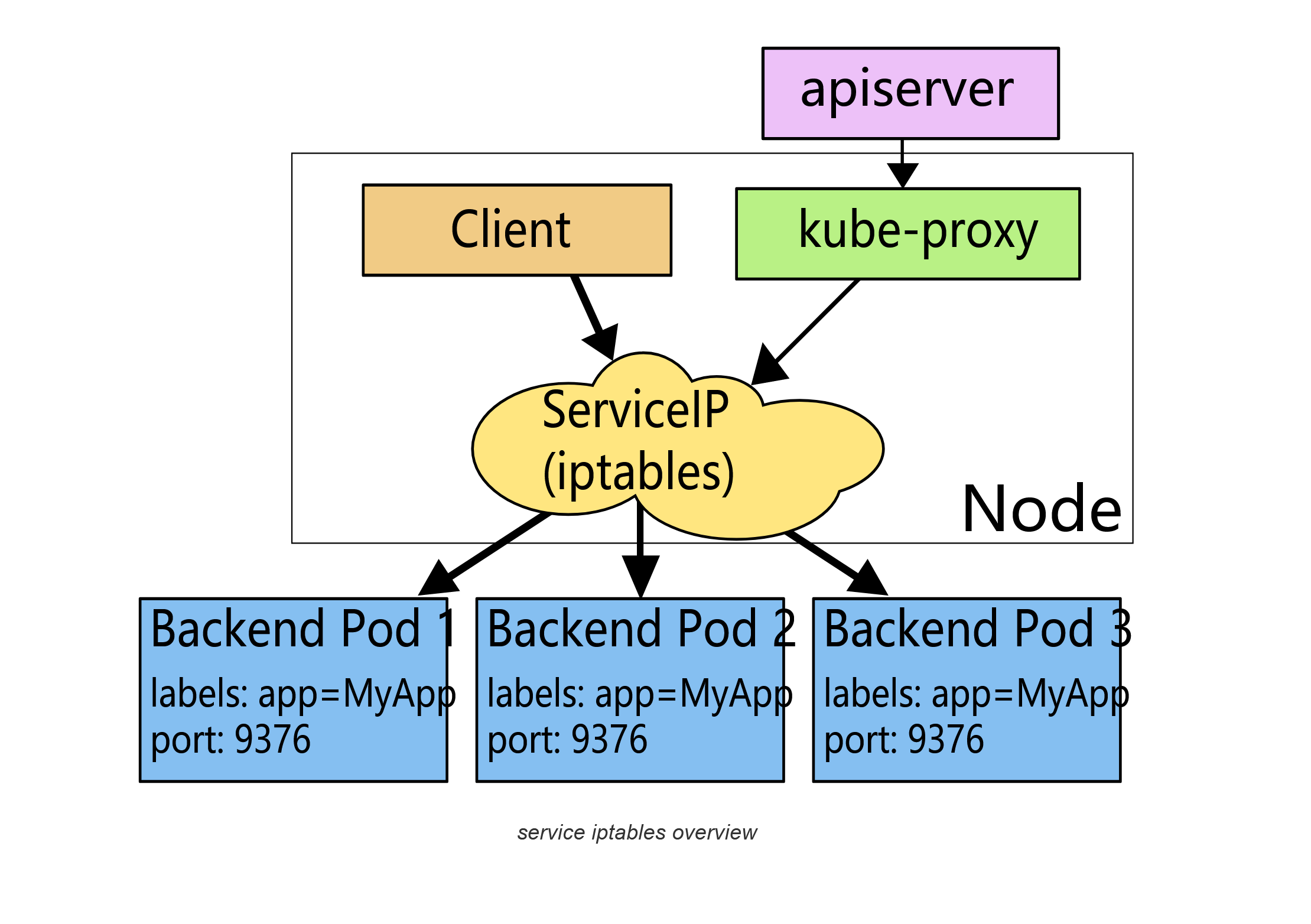
5.4 kube-proxy
前面我们讲到过,在Kubernetes集群中,每个Node会运行一个kube-proxy进程, 负责为Service实现一种 VIP(虚拟 IP,就是我们上面说的clusterIP)的代理形式,现在的Kubernetes中默认是使用的iptables这种模式来代理。这种模式,kube-proxy会监视Kubernetes master对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会添加上 iptables 规则,从而捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某一个个上面。 对于每个 Endpoints 对象,它也会安装 iptables 规则,这个规则会选择一个 backend Pod。
默认的策略是,随机选择一个 backend。 我们也可以实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 "ClientIP" (默认值为 "None")。
另外需要了解的是如果最开始选择的 Pod 没有响应,iptables 代理能够自动地重试另一个 Pod,所以它需要依赖 readiness probes。
5.5 Service 类型
我们在定义Service的时候可以指定一个自己需要的类型的Service,如果不指定的话默认是ClusterIP类型。
我们可以使用的服务类型如下:
- ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的ServiceType。
- NodePort:通过每个 Node 节点上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求 ,可以从集群的外部访问一个 NodePort 服务。
- LoadBalancer:使用云提供商的负载局衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务,这个需要结合具体的云厂商进行操作。
- ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的 kube-dns 才支持。
5.6 NodePort 类型
如果设置 type 的值为 "NodePort",Kubernetes master 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。该端口将通过 Service 的 spec.ports[*].nodePort 字段被指定,如果不指定的话会自动生成一个端口。
需要注意的是,Service 将能够通过 :spec.ports[].nodePort 和 spec.clusterIp:spec.ports[].port 而对外可见。
接下来我们来给大家创建一个NodePort的服务来访问我们前面的Nginx服务:(保存为service-demo.yaml)
[root@node01 ~]# vim service-demo.yaml
[root@node01 ~]# cat service-demo.yaml
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
name: myapp-http
创建该Service:
[root@node01 ~]# kubectl create -f service-demo.yaml
service "myservice" created
然后我们可以查看Service对象信息:
[root@node01 ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 32d
myservice NodePort 10.100.13.170 <none> 80:31941/TCP 3s
我们可以看到myservice的 TYPE 类型已经变成了NodePort ,后面的PORT(S)部分也多了一个 31941 的映射端口。
5.7 ExternalName
ExternalName 是 Service 的特例,它没有 selector,也没有定义任何的端口和 Endpoint。 对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
当查询主机 my-service.prod.svc.cluster.local (后面服务发现的时候我们会再深入讲解)时,集群的 DNS 服务将返回一个值为 my.database.example.com 的 CNAME 记录。 访问这个服务的工作方式与其它的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。 如果后续决定要将数据库迁移到 Kubernetes 集群中,可以启动对应的 Pod,增加合适的 Selector 或 Endpoint,修改 Service 的 type,完全不需要修改调用的代码,这样就完全解耦了。
6. ConfigMap
6.1 ConfigMap
前面的课程中我们学习了Servie的使用,Service是Kubernetes系统中非常重要的一个核心概念,我们还会在后面 的课程中继续学习Service的一些使用方法的。这节课我们来学习另外一个非常重要的资源对象:ConfigMap,我们知道许多应用经常会有从配置文件、命令行参数或者环境变量中读取一些配置信息,这些配置信息我们肯定不会直接写死到应用程序中去的,比如你一个应用连接一个redis服务,下一次想更换一个了的,还得重新去修改代码,重新制作一个镜像,这肯定是不可取的,而ConfigMap就给我们提供了向容器中注入配置信息的能力,不仅可以用来保存单个属性,也可以用来保存整个配置文件,比如我们可以用来配置一个redis服务的访问地址,也可以用来保存整个redis的配置文件。
6.2 创建
ConfigMap 资源对象使用key-value形式的键值对来配置数据,这些数据可以在Pod里面使用,ConfigMap和我们后面要讲到的Secrets比较类似,一个比较大的区别是ConfigMap可以比较方便的处理一些非敏感的数据,比如密码之类的还是需要使用Secrets来进行管理。我们来举个例子说明下ConfigMap的使用方法:
kind: ConfigMap
apiVersion: v1
metadata:
name: cm-demo
namespace: default
data:
data.1: hello
data.2: world
config: |
property.1=value-1
property.2=value-2
property.3=value-3
其中配置数据在data属性下面进行配置,前两个被用来保存单个属性,后面一个被用来保存一个配置文件。
当然同样的我们可以使用kubectl create -f xx.yaml来创建上面的ConfigMap对象,但是如果我们不知道怎么创建ConfigMap的话,不要忘记kubectl是我们最好的老师,可以使用kubectl create configmap -h来查看关于创建ConfigMap的帮助信息,
Examples:
# Create a new configmap named my-config based on folder bar
kubectl create configmap my-config --from-file=path/to/bar
# Create a new configmap named my-config with specified keys instead of file basenames on disk
kubectl create configmap my-config --from-file=key1=/path/to/bar/file1.txt --from-file=key2=/path/to/bar/file2.txt
# Create a new configmap named my-config with key1=config1 and key2=config2
kubectl create configmap my-config --from-literal=key1=config1 --from-literal=key2=config2
我们可以看到可以从一个给定的目录来创建一个ConfigMap对象,比如我们有一个testcm的目录,该目录下面包含一些配置文件,redis和mysql的连接信息,如下:
[root@node01 ~]# mkdir testcm
[root@node01 ~]# vim testcm/redis.conf
[root@node01 ~]# cat testcm/redis.conf
host=127.0.0.1
port=6379
[root@node01 ~]# vim testcm/mysql.conf
[root@node01 ~]# cat testcm/mysql.conf
host=127.0.0.1
port=3306
然后我们可以使用from-file关键字来创建包含这个目录下面所以配置文件的ConfigMap:
[root@node01 ~]# kubectl create configmap cm-demo1 --from-file=testcm
configmap "cm-demo1" created
其中from-file参数指定在该目录下面的所有文件都会被用在ConfigMap里面创建一个键值对,键的名字就是文件名,值就是文件的内容。
创建完成后,同样我们可以使用如下命令来查看ConfigMap列表:
[root@node01 ~]# kubectl get configmap
NAME DATA AGE
cm-demo1 2 5s
可以看到已经创建了一个cm-demo1的ConfigMap对象,然后可以使用describe命令查看详细信息:
[root@node01 ~]# kubectl describe configmap cm-demo1
Name: cm-demo1
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
mysql.conf:
----
host=127.0.0.1
port=3306
redis.conf:
----
host=127.0.0.1
port=6379
Events: <none>
我们可以看到两个key是testcm目录下面的文件名称,对应的value值的话就是文件内容,这里值得注意的是如果文件里面的配置信息很大的话,describe的时候可能不会显示对应的值,要查看键值的话,可以使用如下命令:
[root@node01 ~]# kubectl get configmap cm-demo1 -o yaml
apiVersion: v1
data:
mysql.conf: |
host=127.0.0.1
port=3306
redis.conf: |
host=127.0.0.1
port=6379
kind: ConfigMap
metadata:
creationTimestamp: 2021-07-18T12:36:38Z
name: cm-demo1
namespace: default
resourceVersion: "9281"
selfLink: /api/v1/namespaces/default/configmaps/cm-demo1
uid: cbf961bc-e7c4-11eb-8fc3-000c2927597c
除了通过文件目录进行创建,我们也可以使用指定的文件进行创建ConfigMap,同样的,以上面的配置文件为例,我们创建一个redis的配置的一个单独ConfigMap对象:
[root@node01 ~]# kubectl create configmap cm-demo2 --from-file=testcm/redis.conf
configmap "cm-demo2" created
[root@node01 ~]# kubectl get configmap cm-demo2 -o yaml
apiVersion: v1
data:
redis.conf: |
host=127.0.0.1
port=6379
kind: ConfigMap
metadata:
creationTimestamp: 2021-07-18T12:40:41Z
name: cm-demo2
namespace: default
resourceVersion: "9575"
selfLink: /api/v1/namespaces/default/configmaps/cm-demo2
uid: 5cd4cd56-e7c5-11eb-8fc3-000c2927597c
我们可以看到一个关联redis.conf文件配置信息的ConfigMap对象创建成功了,另外值得注意的是--from-file这个参数可以使用多次,比如我们这里使用两次分别指定redis.conf和mysql.conf文件,就和直接指定整个目录是一样的效果了。
另外,通过帮助文档我们可以看到我们还可以直接使用字符串进行创建,通过--from-literal参数传递配置信息,同样的,这个参数可以使用多次,格式如下:
[root@node01 ~]# kubectl create configmap cm-demo3 --from-literal=db.host=localhost --from-literal=db.port=3306
configmap "cm-demo3" created
[root@node01 ~]# kubectl get configmap cm-demo3 -o yaml
apiVersion: v1
data:
db.host: localhost
db.port: "3306"
kind: ConfigMap
metadata:
creationTimestamp: 2021-07-18T12:41:44Z
name: cm-demo3
namespace: default
resourceVersion: "9651"
selfLink: /api/v1/namespaces/default/configmaps/cm-demo3
uid: 8226fcbd-e7c5-11eb-8fc3-000c2927597c
6.3 使用
ConfigMap创建成功了,那么我们应该怎么在Pod中来使用呢?我们说ConfigMap这些配置数据可以通过很多种方式在Pod里使用,主要有以下几种方式:
- 设置环境变量的值
- 在容器里设置命令行参数
- 在数据卷里面创建config文件
首先,我们使用ConfigMap来填充我们的环境变量:
[root@node01 ~]# vim testcm1.yaml
[root@node01 ~]# cat testcm1.yaml
apiVersion: v1
kind: Pod
metadata:
name: testcm1-pod
spec:
containers:
- name: testcm1
image: busybox
command: [ "/bin/sh", "-c", "env" ]
env:
- name: DB_HOST
valueFrom:
configMapKeyRef:
name: cm-demo3
key: db.host
- name: DB_PORT
valueFrom:
configMapKeyRef:
name: cm-demo3
key: db.port
envFrom:
- configMapRef:
name: cm-demo1
创建这个Pod
[root@node01 ~]# kubectl create -f ./testcm1.yaml
pod "testcm1-pod" created
这个Pod运行后会输出如下几行:
[root@node01 ~]# kubectl logs testcm1-pod
KUBERNETES_SERVICE_PORT=443
KUBERNETES_PORT=tcp://10.96.0.1:443
HOSTNAME=testcm1-pod
DB_PORT=3306
SHLVL=1
HOME=/root
mysql.conf=host=127.0.0.1
port=3306
redis.conf=host=127.0.0.1
port=6379
KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
KUBERNETES_PORT_443_TCP_PORT=443
KUBERNETES_PORT_443_TCP_PROTO=tcp
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443
KUBERNETES_SERVICE_HOST=10.96.0.1
PWD=/
DB_HOST=localhost
......
我们可以看到DB_HOST和DB_PORT都已经正常输出了,另外的环境变量是因为我们这里直接把cm-demo1给注入进来了,所以把他们的整个键值给输出出来了,这也是符合预期的。
另外我们可以使用ConfigMap来设置命令行参数,ConfigMap也可以被用来设置容器中的命令或者参数值,如下Pod:
[root@node01 ~]# vim testcm2.yaml
[root@node01 ~]# cat testcm2.yaml
apiVersion: v1
kind: Pod
metadata:
name: testcm2-pod
spec:
containers:
- name: testcm2
image: busybox
command: [ "/bin/sh", "-c", "echo $(DB_HOST) $(DB_PORT)" ]
env:
- name: DB_HOST
valueFrom:
configMapKeyRef:
name: cm-demo3
key: db.host
- name: DB_PORT
valueFrom:
configMapKeyRef:
name: cm-demo3
key: db.port
创建这个Pod
[root@node01 ~]# kubectl create -f ./testcm2.yaml
pod "testcm2-pod" created
运行这个Pod后会输出如下信息:
[root@node01 ~]# kubectl logs testcm2-pod
localhost 3306
另外一种是非常常见的使用ConfigMap的方式:通过数据卷使用,在数据卷里面使用ConfigMap,就是将文件填入数据卷,在这个文件中,键就是文件名,键值就是文件内容:
[root@node01 ~]# vim testcm3.yaml
[root@node01 ~]# cat testcm3.yaml
apiVersion: v1
kind: Pod
metadata:
name: testcm3-pod
spec:
containers:
- name: testcm3
image: busybox
command: [ "/bin/sh", "-c", "cat /etc/config/redis.conf" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: cm-demo2
创建这个Pod
[root@node01 ~]# kubectl create -f ./testcm3.yaml
pod "testcm3-pod" created
运行这个Pod的,查看日志:
[root@node01 ~]# kubectl logs testcm3-pod
host=127.0.0.1
port=6379
当然我们也可以在ConfigMap值被映射的数据卷里去控制路径,如下Pod定义:
[root@node01 ~]# vim testcm4.yaml
[root@node01 ~]# cat testcm4.yaml
apiVersion: v1
kind: Pod
metadata:
name: testcm4-pod
spec:
containers:
- name: testcm4
image: busybox
command: [ "/bin/sh","-c","cat /etc/config/path/to/msyql.conf" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: cm-demo1
items:
- key: mysql.conf
path: path/to/msyql.conf
创建这个Pod
[root@node01 ~]# kubectl create -f ./testcm4.yaml
pod "testcm4-pod" created
运行这个Pod的,查看日志:
[root@node01 ~]# kubectl logs testcm4-pod
host=127.0.0.1
port=3306
另外需要注意的是,当ConfigMap以数据卷的形式挂载进Pod的时,这时更新ConfigMap(或删掉重建ConfigMap),Pod内挂载的配置信息会热更新。这时可以增加一些监测配置文件变更的脚本,然后reload对应服务。
7. Secret
7.1 Secret
上节课我们学习了ConfigMap的时候,我们说ConfigMap这个资源对象是Kubernetes当中非常重要的一个对象,一般情况下ConfigMap是用来存储一些非安全的配置信息,如果涉及到一些安全相关的数据的话用ConfigMap就非常不妥了,因为ConfigMap是名为存储的,我们说这个时候我们就需要用到另外一个资源对象了:Secret,Secret用来保存敏感信息,例如密码、OAuth 令牌和 ssh key等等,将这些信息放在Secret中比放在Pod的定义中或者docker镜像中来说更加安全和灵活。
Secret有三种类型:
- Opaque:base64 编码格式的 Secret,用来存储密码、密钥等;但数据也可以通过base64 –decode解码得到原始数据,所有加密性很弱。
- kubernetes.io/dockerconfigjson:用来存储私有docker registry的认证信息。
- kubernetes.io/service-account-token:用于被
serviceaccount引用,serviceaccout 创建时Kubernetes会默认创建对应的secret。Pod如果使用了serviceaccount,对应的secret会自动挂载到Pod目录/run/secrets/kubernetes.io/serviceaccount中。
7.2 Opaque Secret
Opaque 类型的数据是一个 map 类型,要求value是base64编码格式,比如我们来创建一个用户名为 admin,密码为 admin321 的 Secret 对象,首先我们先把这用户名和密码做 base64 编码,
[root@node01 ~]# echo -n "admin" | base64
YWRtaW4=
[root@node01 ~]# echo -n "admin321" | base64
YWRtaW4zMjE=
然后我们就可以利用上面编码过后的数据来编写一个YAML文件:(secret-demo.yaml)
[root@node01 ~]# vim secret-demo.yaml
[root@node01 ~]# cat secret-demo.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: YWRtaW4zMjE=
然后同样的我们就可以使用kubectl命令来创建了:
[root@node01 ~]# kubectl create -f secret-demo.yaml
secret "mysecret" created
利用get secret命令查看:
[root@node01 ~]# kubectl get secret
NAME TYPE DATA AGE
default-token-ztfk2 kubernetes.io/service-account-token 3 47d
mysecret Opaque 2 7s
其中
default-token-cty7pdefault-token-n9w2d为创建集群时默认创建的 secret,被serviceacount/default 引用。
使用describe命令,查看详情:
[root@node01 ~]# kubectl describe secret mysecret
Name: mysecret
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
username: 5 bytes
password: 8 bytes
我们可以看到利用describe命令查看到的Data没有直接显示出来,如果想看到Data里面的详细信息,同样我们可以输出成YAML文件进行查看:
[root@node01 ~]# kubectl get secret mysecret -o yaml
apiVersion: v1
data:
password: YWRtaW4zMjE=
username: YWRtaW4=
kind: Secret
metadata:
creationTimestamp: 2021-08-01T08:52:14Z
name: mysecret
namespace: default
resourceVersion: "117383"
selfLink: /api/v1/namespaces/default/secrets/mysecret
uid: c4a0ccbd-f2a5-11eb-8fc3-000c2927597c
type: Opaque
创建好Secret对象后,有两种方式来使用它:
- 以环境变量的形式
- 以Volume的形式挂载
7.3 环境变量
首先我们来测试下环境变量的方式,同样的,我们来使用一个简单的busybox镜像来测试下:(secret1-pod.yaml)
[root@node01 ~]# vim secret1-pod.yaml
[root@node01 ~]# cat secret1-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: secret1-pod
spec:
containers:
- name: secret1
image: busybox
command: [ "/bin/sh", "-c", "env" ]
env:
- name: USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
主要上面环境变量中定义的secretKeyRef关键字,和我们上节课的configMapKeyRef是不是比较类似,一个是从Secret对象中获取,一个是从ConfigMap对象中获取,创建上面的Pod:
[root@node01 ~]# kubectl create -f secret1-pod.yaml
pod "secret1-pod" created
然后我们查看Pod的日志输出:
[root@node01 ~]# kubectl logs secret1-pod
...
USERNAME=admin
...
PASSWORD=admin321
可以看到有 USERNAME 和 PASSWORD 两个环境变量输出出来。
7.4 Volume 挂载
同样的我们用一个Pod来验证下Volume挂载,创建一个Pod文件:(secret2-pod.yaml)
[root@node01 ~]# vim secret2-pod.yaml
[root@node01 ~]# cat secret2-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: secret2-pod
spec:
containers:
- name: secret2
image: busybox
command: ["/bin/sh", "-c", "ls /etc/secrets"]
volumeMounts:
- name: secrets
mountPath: /etc/secrets
volumes:
- name: secrets
secret:
secretName: mysecret
创建Pod:
[root@node01 ~]# kubectl create -f secret2-pod.yaml
pod "secret2-pod" created
然后我们查看输出日志:
[root@node01 ~]# kubectl logs secret2-pod
password
username
可以看到secret把两个key挂载成了两个对应的文件。当然如果想要挂载到指定的文件上面,是不是也可以使用上一节课的方法:在secretName下面添加items指定 key 和 path,这个大家可以参考上节课ConfigMap中的方法去测试下。
7.5 kubernetes.io/dockerconfigjson
除了上面的Opaque这种类型外,我们还可以来创建用户docker registry认证的Secret,直接使用kubectl create命令创建即可,如下:
[root@node01 ~]# kubectl create secret docker-registry myregistry --docker-server=DOCKER_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
secret "myregistry" created
然后查看Secret列表:
[root@node01 ~]# kubectl get secret
NAME TYPE DATA AGE
default-token-ztfk2 kubernetes.io/service-account-token 3 47d
myregistry kubernetes.io/dockerconfigjson 1 3s
mysecret Opaque 2 23m
注意看上面的TYPE类型,myregistry是不是对应的kubernetes.io/dockerconfigjson,同样的可以使用describe命令来查看详细信息:
[root@node01 ~]# kubectl describe secret myregistry
Name: myregistry
Namespace: default
Labels: <none>
Annotations: <none>
Type: kubernetes.io/dockerconfigjson
Data
====
.dockerconfigjson: 152 bytes
同样的可以看到Data区域没有直接展示出来,如果想查看的话可以使用-o yaml来输出展示出来:
[root@node01 ~]# kubectl get secret myregistry -o yaml
apiVersion: v1
data:
.dockerconfigjson: eyJhdXRocyI6eyJET0NLRVJfU0VSVkVSIjp7InVzZXJuYW1lIjoiRE9DS0VSX1VTRVIiLCJwYXNzd29yZCI6IkRPQ0tFUl9QQVNTV09SRCIsImVtYWlsIjoiRE9DS0VSX0VNQUlMIiwiYXV0aCI6IlJFOURTMFZTWDFWVFJWSTZSRTlEUzBWU1gxQkJVMU5YVDFKRSJ9fX0=
kind: Secret
metadata:
creationTimestamp: 2021-08-01T10:41:11Z
name: myregistry
namespace: default
resourceVersion: "5552"
selfLink: /api/v1/namespaces/default/secrets/myregistry
uid: fcd87d58-f2b4-11eb-8fc3-000c2927597c
type: kubernetes.io/dockerconfigjson
可以把上面的data.dockerconfigjson下面的数据做一个base64解码,看看里面的数据是怎样的呢?
[root@node01 ~]# echo eyJhdXRocyI6eyJET0NLRVJfU0VSVkVSIjp7InVzZXJuYW1lIjoiRE9DS0VSX1VTRVIiLCJwYXNzd29yZCI6IkRPQ0tFUl9QQVNTV09SRCIsImVtYWlsIjoiRE9DS0VSX0VNQUlMIiwiYXV0aCI6IlJFOURTMFZTWDFWVFJWSTZSRTlEUzBWU1gxQkJVMU5YVDFKRSJ9fX0= | base64 -d
{"auths":{"DOCKER_SERVER":{"username":"DOCKER_USER","password":"DOCKER_PASSWORD","email":"DOCKER_EMAIL","auth":"RE9DS0VSX1VTRVI6RE9DS0VSX1BBU1NXT1JE"}}}
如果我们需要拉取私有仓库中的docker镜像的话就需要使用到上面的myregistry这个Secret:
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: foo
image: 192.168.1.100:5000/test:v1
imagePullSecrets:
- name: myregistrykey
我们需要拉取私有仓库镜像192.168.1.100:5000/test:v1,我们就需要针对该私有仓库来创建一个如上的Secret,然后在Pod的 YAML 文件中指定imagePullSecrets,我们会在后面的私有仓库搭建的课程中跟大家详细说明的。
7.6 kubernetes.io/service-account-token
另外一种Secret类型就是kubernetes.io/service-account-token,用于被serviceaccount引用。serviceaccout 创建时 Kubernetes 会默认创建对应的 secret。Pod 如果使用了 serviceaccount,对应的secret会自动挂载到Pod的/run/secrets/kubernetes.io/serviceaccount目录中。
这里我们使用一个nginx镜像来验证一下,大家想一想为什么不是呀busybox镜像来验证?当然也是可以的,但是我们就不能在command里面来验证了,因为token是需要Pod运行起来过后才会被挂载上去的,直接在command命令中去查看肯定是还没有 token 文件的。
[root@node01 ~]# kubectl run secret-pod3 --image nginx:1.7.9
deployment.apps "secret-pod3" created
[root@node01 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
secret-pod3-78c8c76db8-d2kw8 1/1 Running 0 14s
[root@node01 ~]# kubectl exec secret-pod3-78c8c76db8-d2kw8 ls /run/secrets/kubernetes.io/serviceaccount
ca.crt
namespace
token
[root@node01 ~]# kubectl exec secret-pod3-78c8c76db8-d2kw8 cat /run/secrets/kubernetes.io/serviceaccount/token
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImRlZmF1bHQtdG9rZW4tenRmazIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGVmYXVsdCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjA3YTVmYzY3LWNkM2UtMTFlYi04ZmMzLTAwMGMyOTI3NTk3YyIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpkZWZhdWx0OmRlZmF1bHQifQ.GGz7ZsyDQUnYKJyoOddCoMXq4NROD9eG0AFANJgosk8_5H6za2x3TL1UPyWXRZ_tpDpS2Kr8mU3qEr85H03hCQGeS_NSXxXtnTeTcC5vJo3SYDZhb-CNhuARr0_PhjfV4HvB_guOB2rckTfLVFINl-xz6LYpQGgs6CK6KFq1WaD1YHiRjCHSAhBfgyTOqsHXVE3mT73xjtT5x4E3w2mdbzeBMsOq9EXpquVWrsacUjaPGb_Xf-SW6ZCHvyxI75efoY5dJX7Djvq0-9XUa0WIXmlfpi7t02u3XCja4tGqCr7VCCH4d_9O6BwxIzSt1Za59v3FeMl4GWI712_81xA1Ow
7.7 Secret 与 ConfigMap 对比
最后我们来对比下Secret和ConfigMap这两种资源对象的异同点:
相同点:
- key/value的形式
- 属于某个特定的namespace
- 可以导出到环境变量
- 可以通过目录/文件形式挂载
- 通过 volume 挂载的配置信息均可热更新
不同点:
- Secret 可以被 ServerAccount 关联
- Secret 可以存储 docker register 的鉴权信息,用在 ImagePullSecret 参数中,用于拉取私有仓库的镜像
- Secret 支持 Base64 加密
- Secret 分为 kubernetes.io/service-account-token、kubernetes.io/dockerconfigjson、Opaque 三种类型,而 Configmap 不区分类型
8. RBAC
8.1 RBAC
前面两节课我们学习了Kubernetes中的两个用于配置信息的重要资源对象:ConfigMap和Secret,其实到这里我们基本上学习的内容已经覆盖到Kubernetes中一些重要的资源对象了,来部署一个应用程序是完全没有问题的了。在我们演示一个完整的示例之前,我们还需要给大家讲解一个重要的概念:RBAC - 基于角色的访问控制。
RBAC使用rbac.authorization.k8s.io API Group 来实现授权决策,允许管理员通过 Kubernetes API 动态配置策略,要启用RBAC,需要在 apiserver 中添加参数--authorization-mode=RBAC,如果使用的kubeadm安装的集群,1.6 版本以上的都默认开启了RBAC,可以通过查看 Master 节点上 apiserver 的静态Pod定义文件:
[root@master ~]# sed -n '37p' /etc/kubernetes/manifests/kube-apiserver.yaml
- --authorization-mode=Node,RBAC
如果是二进制的方式搭建的集群,添加这个参数过后,记得要重启 apiserver 服务。
8.2 RBAC API 对象
Kubernetes有一个很基本的特性就是它的所有资源对象都是模型化的 API 对象,允许执行 CRUD(Create、Read、Update、Delete)操作(也就是我们常说的增、删、改、查操作),比如下面的这下资源:
- Pods
- ConfigMaps
- Deployments
- Nodes
- Secrets
- Namespaces
上面这些资源对象的可能存在的操作有:
- create
- get
- delete
- list
- update
- edit
- watch
- exec
在更上层,这些资源和 API Group 进行关联,比如Pods属于 Core API Group,而Deployements属于 apps API Group,要在Kubernetes中进行RBAC的管理,除了上面的这些资源和操作以外,我们还需要另外的一些对象:
- Rule:规则,规则是一组属于不同 API Group 资源上的一组操作的集合
- Role 和 ClusterRole:角色和集群角色,这两个对象都包含上面的 Rules 元素,二者的区别在于,在 Role 中,定义的规则只适用于单个命名空间,也就是和 namespace 关联的,而 ClusterRole 是集群范围内的,因此定义的规则不受命名空间的约束。另外 Role 和 ClusterRole 在
Kubernetes中都被定义为集群内部的 API 资源,和我们前面学习过的 Pod、ConfigMap 这些类似,都是我们集群的资源对象,所以同样的可以使用我们前面的kubectl相关的命令来进行操作- Subject:主题,对应在集群中尝试操作的对象,集群中定义了3种类型的主题资源:
- [ ] User Account:用户,这是有外部独立服务进行管理的,管理员进行私钥的分配,用户可以使用 KeyStone或者 Goolge 帐号,甚至一个用户名和密码的文件列表也可以。对于用户的管理集群内部没有一个关联的资源对象,所以用户不能通过集群内部的 API 来进行管理
- [ ] Group:组,这是用来关联多个账户的,集群中有一些默认创建的组,比如cluster-admin
- [ ] Service Account:服务帐号,通过
KubernetesAPI 来管理的一些用户帐号,和 namespace 进行关联的,适用于集群内部运行的应用程序,需要通过 API 来完成权限认证,所以在集群内部进行权限操作,我们都需要使用到 ServiceAccount,这也是我们这节课的重点
- RoleBinding 和 ClusterRoleBinding:角色绑定和集群角色绑定,简单来说就是把声明的 Subject 和我们的 Role 进行绑定的过程(给某个用户绑定上操作的权限),二者的区别也是作用范围的区别:RoleBinding 只会影响到当前 namespace 下面的资源操作权限,而 ClusterRoleBinding 会影响到所有的 namespace。
接下来我们来通过几个示例来演示下RBAC的配置方法。
8.3 创建一个只能访问某个 namespace 的用户
我们来创建一个 User Account,只能访问 kube-system 这个命名空间:
- username: haimaxy
- group: youdianzhishi
8.3.1 第1步:创建用户凭证
我们前面已经提到过,Kubernetes没有 User Account 的 API 对象,不过要创建一个用户帐号的话也是挺简单的,利用管理员分配给你的一个私钥就可以创建了,这个我们可以参考官方文档中的方法,这里我们来使用OpenSSL证书来创建一个 User,当然我们也可以使用更简单的cfssl工具来创建:
(1)给用户 haimaxy 创建一个私钥,命名成:haimaxy.key:
[root@node01 ~]# openssl genrsa -out haimaxy.key 2048
Generating RSA private key, 2048 bit long modulus
....................................+++
..............................+++
e is 65537 (0x10001)
(2)使用我们刚刚创建的私钥创建一个证书签名请求文件:haimaxy.csr,要注意需要确保在-subj参数中指定用户名和组(CN表示用户名,O表示组):
[root@node01 ~]# openssl req -new -key haimaxy.key -out haimaxy.csr -subj "/CN=haimaxy/O=youdianzhis"
(3)然后找到我们的Kubernetes集群的CA,我们使用的是kubeadm安装的集群,CA相关证书位于/etc/kubernetes/pki/目录下面,如果你是二进制方式搭建的,你应该在最开始搭建集群的时候就已经指定好了CA的目录,我们会利用该目录下面的ca.crt和ca.key两个文件来批准上面的证书请求
(4)生成最终的证书文件,我们这里设置证书的有效期为500天:
[root@node01 ~]# openssl x509 -req -in haimaxy.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out haimaxy.crt -days 500
Signature ok
subject=/CN=haimaxy/O=youdianzhis
Getting CA Private Key
(5)现在查看我们当前文件夹下面是否生成了一个证书文件:
[root@node01 ~]# ls haimaxy.*
haimaxy.crt haimaxy.csr haimaxy.key
(6) 现在我们可以使用刚刚创建的证书文件和私钥文件在集群中创建新的凭证和上下文(Context):
[root@node01 ~]# kubectl config set-credentials haimaxy --client-certificate=haimaxy.crt --client-key=haimaxy.key
User "haimaxy" set.
我们可以看到一个用户haimaxy创建了,然后为这个用户设置新的 Context:
[root@node01 ~]# kubectl config set-context haimaxy-context --cluster=kubernetes --namespace=kube-system --user=haimaxy
Context "haimaxy-context" created.
到这里,我们的用户haimaxy就已经创建成功了,现在我们使用当前的这个配置文件来操作kubectl命令的时候,应该会出现错误,因为我们还没有为该用户定义任何操作的权限呢:
[root@node01 ~]# kubectl get pods --context=haimaxy-context
Error from server (Forbidden): pods is forbidden: User "haimaxy" cannot list pods in the namespace "kube-system"
8.3.2 第2步:创建角色
用户创建完成后,接下来就需要给该用户添加操作权限,我们来定义一个YAML文件,创建一个允许用户操作 Deployment、Pod、ReplicaSets 的角色,如下定义:(haimaxy-role.yaml)
[root@node01 ~]# vim haimaxy-role.yaml
[root@node01 ~]# cat haimaxy-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: haimaxy-role
namespace: kube-system
rules:
- apiGroups: ["", "extensions", "apps"]
resources: ["deployments", "replicasets", "pods"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"] #也可以使用['*']
其中Pod属于 core 这个 API Group,在YAML中用空字符就可以,而Deployment属于 apps 这个 API Group,ReplicaSets属于extensions这个 API Group(我怎么知道的?点这里查文档),所以 rules 下面的 apiGroups 就综合了这几个资源的 API Group:["", "extensions", "apps"],其中verbs就是我们上面提到的可以对这些资源对象执行的操作,我们这里需要所有的操作方法,所以我们也可以使用['*']来代替。
然后创建这个Role:
[root@node01 ~]# kubectl create -f haimaxy-role.yaml
role.rbac.authorization.k8s.io "haimaxy-role" created
注意这里我们没有使用上面的
haimaxy-context这个上下文了,因为木有权限啦
8.3.3 第3步:创建角色权限绑定
Role 创建完成了,但是很明显现在我们这个 Role 和我们的用户 haimaxy 还没有任何关系,对吧?这里我就需要创建一个RoleBinding对象,在 kube-system 这个命名空间下面将上面的 haimaxy-role 角色和用户 haimaxy 进行绑定:(haimaxy-rolebinding.yaml)
[root@node01 ~]# vim haimaxy-rolebinding.yaml
[root@node01 ~]# cat haimaxy-rolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: haimaxy-rolebinding
namespace: kube-system
subjects:
- kind: User
name: haimaxy
apiGroup: ""
roleRef:
kind: Role
name: haimaxy-role
apiGroup: ""
上面的YAML文件中我们看到了subjects关键字,这里就是我们上面提到的用来尝试操作集群的对象,这里对应上面的 User 帐号 haimaxy,使用kubectl创建上面的资源对象:
[root@node01 ~]# kubectl create -f haimaxy-rolebinding.yaml
rolebinding.rbac.authorization.k8s.io "haimaxy-rolebinding" created
8.3.4 第4步. 测试
现在我们应该可以上面的haimaxy-context上下文来操作集群了:
[root@node01 ~]# kubectl get pods --context=haimaxy-context
NAME READY STATUS RESTARTS AGE
etcd-master 1/1 Running 0 47d
kube-apiserver-master 1/1 Running 0 47d
kube-controller-manager-master 1/1 Running 0 47d
kube-dns-86f4d74b45-d4xsl 3/3 Running 0 47d
kube-flannel-ds-amd64-nmr2k 1/1 Running 0 47d
kube-flannel-ds-amd64-rzvfc 1/1 Running 0 47d
kube-proxy-6zbdw 1/1 Running 0 47d
kube-proxy-zg7v2 1/1 Running 0 47d
kube-scheduler-master 1/1 Running 0 47d
kubernetes-dashboard-669f9bbd46-tf6bz 1/1 Running 0 47d
我们可以看到我们使用kubectl的使用并没有指定 namespace 了,这是因为我们已经为该用户分配了权限了,如果我们在后面加上一个-n default试看看呢?
[root@node01 ~]# kubectl --context=haimaxy-context get pods --namespace=default
Error from server (Forbidden): pods is forbidden: User "haimaxy" cannot list pods in the namespace "default"
是符合我们预期的吧?因为该用户并没有 default 这个命名空间的操作权限
8.4 创建一个只能访问某个 namespace 的ServiceAccount
上面我们创建了一个只能访问某个命名空间下面的普通用户,我们前面也提到过 subjects 下面还有一直类型的主题资源:ServiceAccount,现在我们来创建一个集群内部的用户只能操作 kube-system 这个命名空间下面的 pods 和 deployments,首先来创建一个 ServiceAccount 对象:
[root@node01 ~]# kubectl create sa haimaxy-sa -n kube-system
serviceaccount "haimaxy-sa" created
当然我们也可以定义成YAML文件的形式来创建。
然后新建一个 Role 对象:(haimaxy-sa-role.yaml)
[root@node01 ~]# vim haimaxy-sa-role.yaml
[root@node01 ~]# cat haimaxy-sa-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: haimaxy-sa-role
namespace: kube-system
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
可以看到我们这里定义的角色没有创建、删除、更新 Pod 的权限,待会我们可以重点测试一下,创建该 Role 对象:
[root@node01 ~]# kubectl create -f haimaxy-sa-role.yaml
role.rbac.authorization.k8s.io "haimaxy-sa-role" created
然后创建一个 RoleBinding 对象,将上面的 haimaxy-sa 和角色 haimaxy-sa-role 进行绑定:(haimaxy-sa-rolebinding.yaml)
[root@node01 ~]# vim haimaxy-sa-rolebinding.yaml
[root@node01 ~]# cat haimaxy-sa-rolebinding.yaml
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: haimaxy-sa-rolebinding
namespace: kube-system
subjects:
- kind: ServiceAccount
name: haimaxy-sa
namespace: kube-system
roleRef:
kind: Role
name: haimaxy-sa-role
apiGroup: rbac.authorization.k8s.io
添加这个资源对象:
[root@node01 ~]# kubectl create -f haimaxy-sa-rolebinding.yaml
rolebinding.rbac.authorization.k8s.io "haimaxy-sa-rolebinding" created
然后我们怎么去验证这个 ServiceAccount 呢?我们前面的课程中是不是提到过一个 ServiceAccount 会生成一个 Secret 对象和它进行映射,这个 Secret 里面包含一个 token,我们可以利用这个 token 去登录 Dashboard,然后我们就可以在 Dashboard 中来验证我们的功能是否符合预期了:
[root@node01 ~]# kubectl get secret -n kube-system |grep haimaxy-sa
haimaxy-sa-token-8vnpr kubernetes.io/service-account-token 3 8m
[root@node01 ~]# kubectl get secret haimaxy-sa-token-8vnpr -o jsonpath={.data.token} -n kube-system |base64 -d
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJoYWltYXh5LXNhLXRva2VuLTh2bnByIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImhhaW1heHktc2EiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIxMWQ0NjM4NS1mMmJhLTExZWItOGZjMy0wMDBjMjkyNzU5N2MiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06aGFpbWF4eS1zYSJ9.RIi5fOebs08JqJ1WFApYIuYMjLu_y-9a0k66aJ9jgCrEn6iWL45d-a857NOaPHeu1wkBrE39xblapNIAscQJ0HONgHANgY2TGYHCky5y5ee2VNamp45ft_rcufgMVhEWKmSjBF0sn70OJj2zEnrRTbR3kdKXPfkbs9wEQcYxAf3JmiQBhu_py6995hudzJ-SQtXiFplpLOBWLc_hgT4a037n4wbd4awRsE6SIFcZ48nHIQXC2nu3JF9X25SJOzTYkWSTA7fzAI1kfbqfDh11Mp6yRyY5IFjYZTJbCfoaSMUTEMcTILqkjkNDe7eqkdwPOVfvQgVjK78tLfGPlDnVRQ
使用这里的 token 去 Dashboard 页面进行登录: https://192.168.200.10:30422/
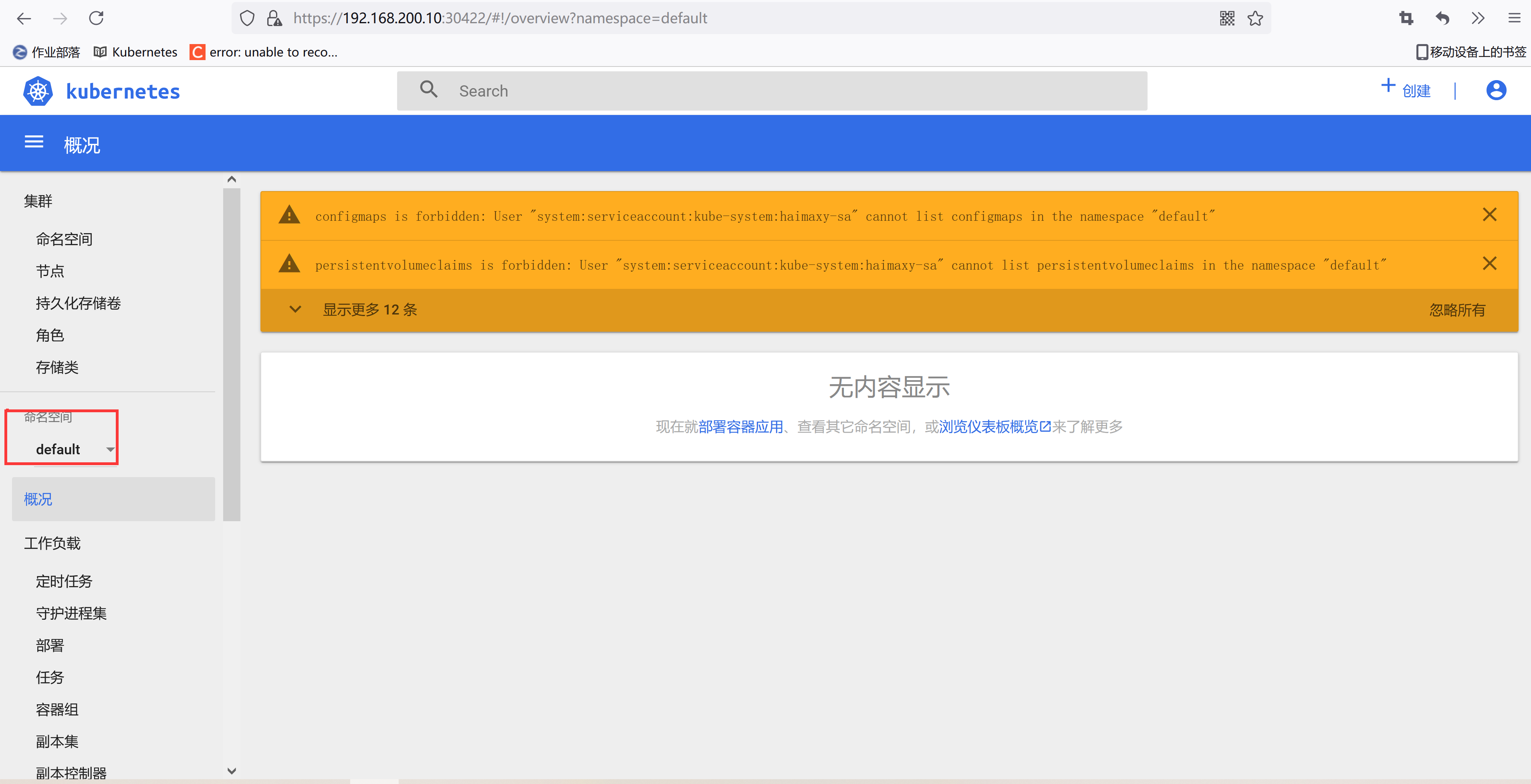
我们可以看到上面的提示信息,这是因为我们登录进来后默认跳转到 default 命名空间,我们切换到 kube-system 命名空间下面就可以了:
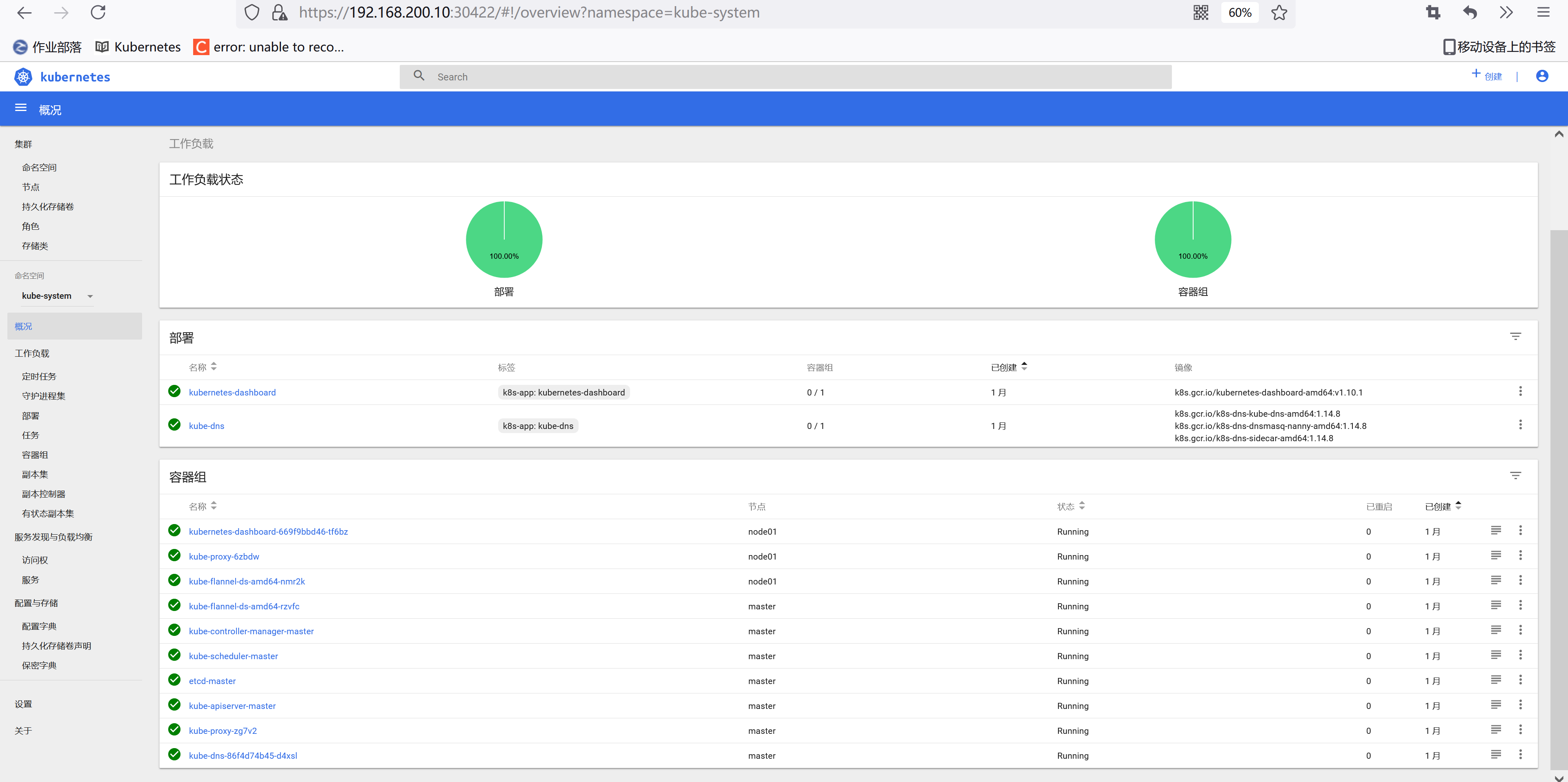
我们可以看到可以访问pod列表了,但是也会有一些其他额外的提示:events is forbidden: User “system:serviceaccount:kube-system:haimaxy-sa” cannot list events in the namespace “kube-system”,这是因为当前登录用只被授权了访问 pod 和 deployment 的权限,同样的,访问下deployment看看可以了吗?
同样的,你可以根据自己的需求来对访问用户的权限进行限制,可以自己通过 Role 定义更加细粒度的权限,也可以使用系统内置的一些权限……
8.5 创建一个可以访问所有 namespace 的ServiceAccount
刚刚我们创建的haimaxy-sa这个 ServiceAccount 和一个 Role 角色进行绑定的,如果我们现在创建一个新的 ServiceAccount,需要他操作的权限作用于所有的 namespace,这个时候我们就需要使用到 ClusterRole 和 ClusterRoleBinding 这两种资源对象了。同样,首先新建一个 ServiceAcount 对象:(haimaxy-sa2.yaml)
[root@node01 ~]# vim haimaxy-sa2.yaml
[root@node01 ~]# cat haimaxy-sa2.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: haimaxy-sa2
namespace: kube-system
创建:
[root@node01 ~]# kubectl create -f haimaxy-sa2.yaml
serviceaccount "haimaxy-sa2" created
然后创建一个 ClusterRoleBinding 对象(haimaxy-clusterolebinding.yaml):
[root@node01 ~]# vim haimaxy-clusterolebinding.yaml
[root@node01 ~]# cat haimaxy-clusterolebinding.yaml
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: haimaxy-sa2-clusterrolebinding
subjects:
- kind: ServiceAccount
name: haimaxy-sa2
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
从上面我们可以看到我们没有为这个资源对象声明 namespace,因为这是一个 ClusterRoleBinding 资源对象,是作用于整个集群的,我们也没有单独新建一个 ClusterRole 对象,而是使用的 cluster-admin 这个对象,这是Kubernetes集群内置的 ClusterRole 对象,我们可以使用kubectl get clusterrole 和kubectl get clusterrolebinding查看系统内置的一些集群角色和集群角色绑定,这里我们使用的 cluster-admin 这个集群角色是拥有最高权限的集群角色,所以一般需要谨慎使用该集群角色。
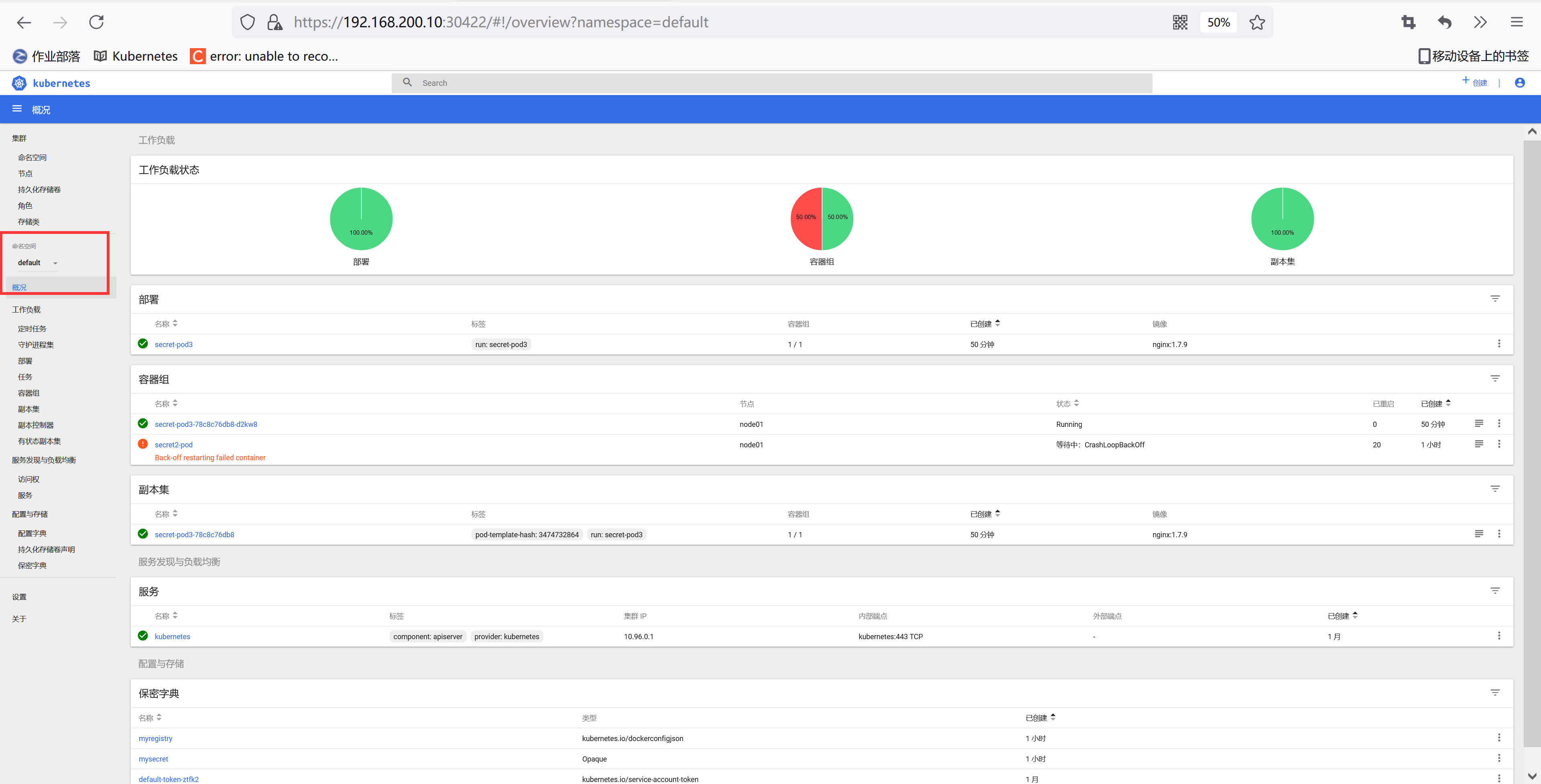
创建上面集群角色绑定资源对象,创建完成后同样使用 ServiceAccount 对应的 token 去登录 Dashboard 验证下:
[root@node01 ~]# kubectl create -f haimaxy-clusterolebinding.yaml
clusterrolebinding.rbac.authorization.k8s.io "haimaxy-sa2-clusterrolebinding" created
[root@node01 ~]# kubectl get secret -n kube-system |grep haimaxy-sa2
haimaxy-sa2-token-n5qwz kubernetes.io/service-account-token 3 2m
[root@node01 ~]# kubectl get secret haimaxy-sa2-token-n5qwz -o jsonpath={.data.token} -n kube-system |base64 -d
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJoYWltYXh5LXNhMi10b2tlbi1uNXF3eiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJoYWltYXh5LXNhMiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImRjZjc2ZmIxLWYyYmMtMTFlYi04ZmMzLTAwMGMyOTI3NTk3YyIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTpoYWltYXh5LXNhMiJ9.PLFRB2KX92eG-RP5KFzKSiH9b3uVFtvGWicGzehY7BR2Gz-mBy1-4Z0rp8VMTWe0nl6FzyNyIx8iTLfUH3_eJUXQOZq_THlvk7blA_DnrAgXNKVEBWRKQlRuc458Rg2kvmylB_d8gT2_8_Nggw0lNxeOjPPws3pkHTrRTKrt64mvNMsgOczXLWSclplsqDM0TYtC5JflgKN2hXq0IHMlfFk9-wIOf9BWvGZKopBOBmvT8sBsOndrN0RjhuvFEnsp3OxzklKGSiUh_vV_6hS1jhmMmezlHjuC6dkKq342ulC4k-PXhPfZ1CDmFE2zpp2MUzj9Wu3TK1chgSWc0677LA
我们在最开始接触到RBAC认证的时候,可能不太熟悉,特别是不知道应该怎么去编写rules规则,大家可以去分析系统自带的 clusterrole、clusterrolebinding 这些资源对象的编写方法,怎么分析?还是利用 kubectl 的 get、describe、 -o yaml 这些操作,所以kubectl最基本的用户一定要掌握好。
RBAC只是Kubernetes中安全认证的一种方式,当然也是现在最重要的一种方式,后面我们再和大家一起聊一聊Kubernetes中安全设计。
9. 部署 Wordpress 示例
9.1 部署 Wordpress 示例
前面的课程中我们基本上了解了Kubernetes当中常见的一些对象资源,这节课我们就来利用前面学习的知识点来部署一个实际的应用 - 将Wordpress应用部署到我们的集群当中,我们前面是不是已经用docker-compose的方式部署过了,我们可以了解到要部署一个Wordpress应用主要涉及到两个镜像:wordpress和mysql,wordpress是应用的核心程序,mysql是用于数据存储的。
现在我们来看看如何来部署我们的这个wordpress应用
9.2 一个Pod
我们知道一个Pod中可以包含多个容器,那么很明显我们这里是不是就可以将wordpress部署成一个独立的Pod?我们将我们的应用都部署到blog这个命名空间下面,所以先创建一个命名空间:
[root@node01 ~]# kubectl create namespace blog
namespace "blog" created
然后来编写YAML文件:(wordpress-pod.yaml)
[root@node01 ~]# vim wordpress-pod.yaml
[root@node01 ~]# cat wordpress-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: wordpress
namespace: blog
spec:
containers:
- name: wordpress
image: wordpress
ports:
- containerPort: 80
name: wdport
env:
- name: WORDPRESS_DB_HOST
value: localhost:3306
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
- name: mysql
image: mysql:5.7
imagePullPolicy: IfNotPresent
args: # 新版本镜像有更新,需要使用下面的认证插件环境变量配置才会生效
- --default_authentication_plugin=mysql_native_password
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- containerPort: 3306
name: dbport
env:
- name: MYSQL_ROOT_PASSWORD
value: rootPassW0rd
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
volumeMounts:
- name: db
mountPath: /var/lib/mysql
volumes:
- name: db
hostPath:
path: /var/lib/mysql
要注意这里针对mysql这个容器我们做了一个数据卷的挂载,这是为了能够将mysql的数据能够持久化到节点上,这样下次mysql容器重启过后数据不至于丢失。然后创建上面的Pod:
[root@node01 ~]# kubectl create -f wordpress-pod.yaml
pod "wordpress" created
接下来就是等待拉取镜像,启动容器,同样我们可以使用describe指令查看详细信息:
[root@node01 ~]# kubectl describe pod wordpress -n blog
大家可以看看我们现在这种单一Pod的方式有什么缺点?假如我们现在需要部署3个Wordpress的副本,该怎么办?是不是我们只需要在上面的YAML文件中加上replicas: 3这个属性就可以了啊?但是有个什么问题呢?是不是不仅仅是Wordpress这个容器会被部署成3份,连我们的MySQL数据库也会被部署成3份了呢?MySQL数据库单纯的部署成3份他们能联合起来使用吗?不能,如果真的这么简单的话就不需要各种数据库集群解决方案了,所以我们这里部署3个Pod实例,实际上他们互相之间是独立的,因为数据不想通,明白吧?所以该怎么办?拆分呗,把wordpress和mysql这两个容器部署成独立的Pod是不是就可以了。
另外一个问题是我们的wordpress容器需要去连接mysql数据库吧,现在我们这里放在一起能保证mysql先启动起来吗?貌似没有特别的办法,前面学习的InitContainer也是针对Pod来的,所以无论如何,我们都需要将他们进行拆分。
9.3 两个Pod
现在来把上面的一个Pod拆分成两个Pod,我们前面也反复强调过要使用Deployment来管理我们的Pod,上面只是为了单纯给大家说明怎么来把前面的Docker环境下的wordpress转换成Kubernetes环境下面的Pod,有了上面的Pod模板,我们现在来转换成Deployment很容易了吧。
9.3.1 第一步,创建一个MySQL的Deployment对象:(wordpress-db.yaml)
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deploy
namespace: blog
labels:
app: mysql
spec:
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
imagePullPolicy: IfNotPresent
args:
- --default_authentication_plugin=mysql_native_password
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- containerPort: 3306
name: dbport
env:
- name: MYSQL_ROOT_PASSWORD
value: rootPassW0rd
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
volumeMounts:
- name: db
mountPath: /var/lib/mysql
volumes:
- name: db
hostPath:
path: /var/lib/mysql
如果我们只创建上面的Deployment这个对象,那么我们应该怎样让后面的Wordpress来访问呢?貌似没办法是吧,之前在一个Pod里面还可以使用localhost来进行访问,现在分开了该怎样访问呢?还记得前面的Service吗?没错,使用Service就可以了,所以我们在上面的wordpress-db.yaml文件中添加上Service的信息:
---
apiVersion: v1
kind: Service
metadata:
name: mysql
namespace: blog
spec:
selector:
app: mysql
ports:
- name: mysqlport
protocol: TCP
port: 3306
targetPort: dbport
然后创建上面的wordpress-db.yaml文件:
[root@node01 ~]# kubectl create -f wordpress-db.yaml
deployment.apps "mysql-deploy" created
service "mysql" created
然后我们查看Service的详细情况:
[root@node01 ~]# kubectl describe svc mysql -n blog
Name: mysql
Namespace: blog
Labels: <none>
Annotations: <none>
Selector: app=mysql
Type: ClusterIP
IP: 10.100.13.170
Port: mysqlport 3306/TCP
TargetPort: dbport/TCP
Endpoints: 10.244.1.4:3306
Session Affinity: None
Events: <none>
可以看到Endpoints部分匹配到了一个Pod,生成了一个clusterIP:10.100.13.170,现在我们是不是就可以通过这个clusterIP加上定义的3306端口就可以正常访问我们这个mysql服务了。
9.3.2 第二步. 创建Wordpress服务,将上面的wordpress的Pod转换成Deployment对象:(wordpress.yaml)
[root@node01 ~]# vim wordpress.yaml
[root@node01 ~]# cat wordpress.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress-deploy
namespace: blog
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
template:
metadata:
labels:
app: wordpress
spec:
containers:
- name: wordpress
image: wordpress
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: wdport
env:
- name: WORDPRESS_DB_HOST
value: 10.100.13.170:3306
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
注意这里的环境变量WORDPRESS_DB_HOST的值将之前的localhost地址更改成了上面mysql服务的clusterIP地址了,然后创建上面的Deployment对象:
[root@node01 ~]# kubectl create -f wordpress.yaml
deployment.apps "wordpress-deploy" created
创建完成后,我们可以看看我们创建的Pod的状态:
[root@node01 ~]# kubectl get pods -n blog
NAME READY STATUS RESTARTS AGE
mysql-deploy-787bdb744b-d2kw8 1/1 Running 0 6m
wordpress-deploy-65586fc686-rqb6b 1/1 Running 0 2m
可以看到都已经是Running状态了,然后我们需要怎么来验证呢?是不是去访问下我们的wordpress服务就可以了,要访问,我们就需要建立一个能让外网用户访问的Service,前面我们学到过是不是NodePort类型的Service就可以?所以在上面的wordpress.yaml文件中添加上Service的信息:
---
apiVersion: v1
kind: Service
metadata:
name: wordpress
namespace: blog
spec:
type: NodePort
selector:
app: wordpress
ports:
- name: wordpressport
protocol: TCP
port: 80
targetPort: wdport
注意要添加属性type: NodePort,然后重新更新wordpress.yaml文件:
[root@node01 ~]# kubectl apply -f wordpress.yaml
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
deployment.apps "wordpress-deploy" configured
service "wordpress" created
创建完成后,查看下svc:
[root@node01 ~]# kubectl get svc -n blog
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP 10.100.13.170 <none> 3306/TCP 10m
wordpress NodePort 10.109.79.65 <none> 80:31941/TCP 13s
可以看到wordpress服务产生了一个31941的端口,现在我们是不是就可以通过任意节点的NodeIP加上31941端口,就可以访问我们的wordpress应用了,在浏览器中打开,如果看到wordpress跳转到了安装页面,证明我们的嗯安装是没有任何问题的了,如果没有出现预期的效果,那么就需要去查看下Pod的日志来查看问题了:
然后根据页面提示,填上对应的信息,点击“安装”即可,最终安装成功后,我们就可以看到熟悉的首页界面了:GDg^CJGkq4D1)faxDe
9.4 提高稳定性
现在wordpress应用已经部署成功了,那么就万事大吉了吗?如果我们的网站访问量突然变大了怎么办,如果我们要更新我们的镜像该怎么办?如果我们的mysql服务挂掉了怎么办?
所以要保证我们的网站能够非常稳定的提供服务,我们做得还不够,我们可以通过做些什么事情来提高网站的稳定性呢?
第一. 增加健康检测,我们前面说过liveness probe和rediness probe是提高应用稳定性非常重要的方法:
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 3
periodSeconds: 3
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 10
增加上面两个探针,每10s检测一次应用是否可读,每3s检测一次应用是否存活
第二. 增加 HPA,让我们的应用能够自动应对流量高峰期:
$ kubectl autoscale deployment wordpress-deploy --cpu-percent=10 --min=1 --max=10 -n blog
deployment "wordpress-deploy" autoscaled
我们用kubectl autoscale命令为我们的wordpress-deploy创建一个HPA对象,最小的 pod 副本数为1,最大为10,HPA会根据设定的 cpu使用率(10%)动态的增加或者减少pod数量。当然最好我们也为Pod声明一些资源限制:
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
更新Deployment后,我们可以可以来测试下上面的HPA是否会生效:
$ kubectl run -i --tty load-generator --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://10.244.1.62:80; done
观察Deployment的副本数是否有变化
$ kubectl get deployment wordpress-deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
wordpress-deploy 3 3 3 3 4d
第三. 增加滚动更新策略,这样可以保证我们在更新应用的时候服务不会被中断:
replicas: 2
revisionHistoryLimit: 10
minReadySeconds: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
第四. 我们知道如果mysql服务被重新创建了的话,它的clusterIP非常有可能就变化了,所以上面我们环境变量中的WORDPRESS_DB_HOST的值就会有问题,就会导致访问不了数据库服务了,这个地方我们可以直接使用Service的名称来代替host,这样即使clusterIP变化了,也不会有任何影响,这个我们会在后面的服务发现的章节和大家深入讲解的:
env:
- name: WORDPRESS_DB_HOST
value: mysql:3306
第五. 我们在部署wordpress服务的时候,mysql服务以前启动起来了吗?如果没有启动起来是不是我们也没办法连接数据库了啊?该怎么办,是不是在启动wordpress应用之前应该去检查一下mysql服务,如果服务正常的话我们就开始部署应用了,这是不是就是InitContainer的用法:
initContainers:
- name: init-db
image: busybox
command: ['sh', '-c', 'until nslookup mysql; do echo waiting for mysql service; sleep 2; done;']
直到mysql服务创建完成后,initContainer才结束,结束完成后我们才开始下面的部署。
最后,我们把部署的应用整合到一个YAML文件中来:(wordpress-all.yaml)
[root@node01 ~]# vim wordpress-all.yaml
[root@node01 ~]# cat wordpress-all.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
namespace: blog
labels:
app: mysql
spec:
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
args:
- --default_authentication_plugin=mysql_native_password
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
ports:
- containerPort: 3306
name: dbport
env:
- name: MYSQL_ROOT_PASSWORD
value: rootPassW0rd
- name: MYSQL_DATABASE
value: wordpress
- name: MYSQL_USER
value: wordpress
- name: MYSQL_PASSWORD
value: wordpress
volumeMounts:
- name: db
mountPath: /var/lib/mysql
volumes:
- name: db
hostPath:
path: /var/lib/mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql
namespace: blog
spec:
selector:
app: mysql
ports:
- name: mysqlport
protocol: TCP
port: 3306
targetPort: dbport
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
namespace: blog
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
minReadySeconds: 5
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
labels:
app: wordpress
spec:
initContainers:
- name: init-db
image: busybox
command: ['sh', '-c', 'until nslookup mysql; do echo waiting for mysql service; sleep 2; done;']
containers:
- name: wordpress
image: wordpress
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: wdport
env:
- name: WORDPRESS_DB_HOST
value: mysql:3306
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
value: wordpress
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 10
resources:
limits:
cpu: 200m
memory: 256Mi
requests:
cpu: 100m
memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:
name: wordpress
namespace: blog
spec:
selector:
app: wordpress
type: NodePort
ports:
- name: wordpressport
protocol: TCP
port: 80
nodePort: 31941
targetPort: wdport
我们这里主要是针对的wordpress来做的提高稳定性的方法,如何对mysql提高一些稳定性呢?大家下去可以试一试,我们接下来会和大家讲解mysql这类有状态的应用在Kubernetes当中的使用方法。
最后,我们来把前面我们部署的相关服务全部删掉,重新通过上面的YAML文件来创建:
[root@node01 ~]# kubectl create -f wordpress-all.yaml
deployment.apps "mysql" created
service "mysql" created
deployment.apps "wordpress" created
service "wordpress" created
看看最后能不能得到我们的最终成果呢?
10. DaemonSet和StatefulSet
10.1 DaemonSet 与 StatefulSet 的使用
前面我们的课程中学习了大部分资源对象的使用方法,上节课我们通过一个WordPress的示例把我们前面的内容做了一个总结。今天我们来给大家讲解另外一个Pod控制器的使用方法,我们前面主要讲解的是Deployment这种对象资源的使用,接下来我们要讲解的是在特定场合下使用的控制器:DaemonSet与StatefulSet。
10.2 DaemonSet 的使用
通过该控制器的名称我们可以看出它的用法:Daemon,就是用来部署守护进程的,DaemonSet用于在每个Kubernetes节点中将守护进程的副本作为后台进程运行,说白了就是在每个节点部署一个Pod副本,当节点加入到Kubernetes集群中,Pod会被调度到该节点上运行,当节点从集群只能够被移除后,该节点上的这个Pod也会被移除,当然,如果我们删除DaemonSet,所有和这个对象相关的Pods都会被删除。
在哪种情况下我们会需要用到这种业务场景呢?其实这种场景还是比较普通的,比如:
- 集群存储守护程序,如glusterd、ceph要部署在每个节点上以提供持久性存储;
- 节点监视守护进程,如Prometheus监控集群,可以在每个节点上运行一个node-exporter进程来收集监控节点的信息;
- 日志收集守护程序,如fluentd或logstash,在每个节点上运行以收集容器的日志
这里需要特别说明的一个就是关于DaemonSet运行的Pod的调度问题,正常情况下,Pod运行在哪个节点上是由Kubernetes的调度器策略来决定的,然而,由DaemonSet控制器创建的Pod实际上提前已经确定了在哪个节点上了(Pod创建时指定了.spec.nodeName),所以:
- DaemonSet并不关心一个节点的unshedulable字段,这个我们会在后面的调度章节和大家讲解的。
- DaemonSet可以创建Pod,即使调度器还没有启动,这点非常重要。
下面我们直接使用一个示例来演示下,在每个节点上部署一个Nginx Pod:(nginx-ds.yaml)
[root@node01 ~]# vim nginx-ds.yaml
[root@node01 ~]# cat nginx-ds.yaml
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: nginx-ds
labels:
k8s-app: nginx
spec:
selector:
matchLabels:
k8s-app: nginx
template:
metadata:
labels:
k8s-app: nginx
spec:
containers:
- image: nginx:1.7.9
name: nginx
ports:
- name: http
containerPort: 80
然后直接创建即可:
[root@node01 ~]# kubectl create -f nginx-ds.yaml
daemonset.apps "nginx-ds" created
然后我们可以观察下Pod是否被分布到了每个节点上:
[root@node01 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-ds-d2kw8 1/1 Running 0 19s 10.244.1.3 node01
10.3 StatefulSet 的使用
在学习StatefulSet这种控制器之前,我们就得先弄明白一个概念:什么是有状态服务?什么是无状态服务?
- 无状态服务(Stateless Service):该服务运行的实例不会在本地存储需要持久化的数据,并且多个实例对于同一个请求响应的结果是完全一致的,比如前面我们讲解的
WordPress实例,我们是不是可以同时启动多个实例,但是我们访问任意一个实例得到的结果都是一样的吧?因为他唯一需要持久化的数据是存储在MySQL数据库中的,所以我们可以说WordPress这个应用是无状态服务,但是MySQL数据库就不是了,因为他需要把数据持久化到本地。- 有状态服务(Stateful Service):就和上面的概念是对立的了,该服务运行的实例需要在本地存储持久化数据,比如上面的
MySQL数据库,你现在运行在节点A,那么他的数据就存储在节点A上面的,如果这个时候你把该服务迁移到节点B去的话,那么就没有之前的数据了,因为他需要去对应的数据目录里面恢复数据,而此时没有任何数据。
现在大家对有状态和无状态有一定的认识了吧,比如我们常见的 WEB 应用,是通过session来保持用户的登录状态的,如果我们将session持久化到节点上,那么该应用就是一个有状态的服务了,因为我现在登录进来你把我的session持久化到节点A上了,下次我登录的时候可能会将请求路由到节点B上去了,但是节点B上根本就没有我当前的session数据,就会被认为是未登录状态了,这样就导致我前后两次请求得到的结果不一致了。所以一般为了横向扩展,我们都会把这类 WEB 应用改成无状态的服务,怎么改?将session数据存入一个公共的地方,比如redis里面,是不是就可以了,对于一些客户端请求API的情况,我们就不使用session来保持用户状态,改成用token也是可以的。
无状态服务利用我们前面的Deployment或者RC都可以很好的控制,对应有状态服务,需要考虑的细节就要多很多了,容器化应用程序最困难的任务之一,就是设计有状态分布式组件的部署体系结构。由于无状态组件可能没有预定义的启动顺序、集群要求、点对点 TCP 连接、唯一的网络标识符、正常的启动和终止要求等,因此可以很容易地进行容器化。诸如数据库,大数据分析系统,分布式 key/value 存储和 message brokers 可能有复杂的分布式体系结构,都可能会用到上述功能。为此,Kubernetes引入了StatefulSet资源来支持这种复杂的需求。
StatefulSet类似于ReplicaSet,但是它可以处理Pod的启动顺序,为保留每个Pod的状态设置唯一标识,同时具有以下功能:
- 稳定的、唯一的网络标识符
- 稳定的、持久化的存储
- 有序的、优雅的部署和缩放
- 有序的、优雅的删除和终止
- 有序的、自动滚动更新
10.4 创建StatefulSet
接下来我们来给大家演示下StatefulSet对象的使用方法,在开始之前,我们先准备两个1G的存储卷(PV),在后面的课程中我们也会和大家详细讲解 PV 和 PVC 的使用方法的,这里我们先不深究:(pv001.yaml)
[root@node01 ~]# vim pv001.yaml
[root@node01 ~]# cat pv001.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv001
labels:
release: stable
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
hostPath:
path: /tmp/data
另外一个只需要把 name 改成 pv002即可
[root@node01 ~]# vim pv002.yaml
[root@node01 ~]# cat pv002.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv002
labels:
release: stable
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
hostPath:
path: /tmp/data
然后创建:
[root@node01 ~]# kubectl create -f pv001.yaml && kubectl create -f pv002.yaml
persistentvolume "pv001" created
persistentvolume "pv002" created
[root@node01 ~]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv001 1Gi RWO Recycle Available 7s
pv002 1Gi RWO Recycle Available 7s
可以看到成功创建了两个 PV对象,状态是:Available。
然后我们使用StatefulSet来创建一个 Nginx 的 Pod,对于这种类型的资源,我们一般是通过创建一个Headless Service类型的服务来暴露服务,将clusterIP设置为None就是一个无头的服务:(statefulset-demo.yaml)
[root@node01 ~]# vim statefulset-demo.yaml
[root@node01 ~]# cat statefulset-demo.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
role: stateful
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
role: stateful
template:
metadata:
labels:
app: nginx
role: stateful
spec:
containers:
- name: nginx
image: cnych/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
注意上面的 YAML 文件中和volumeMounts进行关联的是一个新的属性:volumeClaimTemplates,该属性会自动声明一个 pvc 对象和 pv 进行管理:
然后这里我们开启两个终端窗口。在第一个终端中,使用 kubectl get 来查看 StatefulSet 的 Pods 的创建情况。
[root@node01 ~]# kubectl get pods -w -l role=stateful
在另一个终端中,使用 kubectl create 来创建定义在 statefulset-demo.yaml 中的 Headless Service 和 StatefulSet。
[root@node01 ~]# kubectl create -f statefulset-demo.yaml
service "nginx" created
statefulset.apps "web" created
10.5 检查 Pod 的顺序索引
对于一个拥有 N 个副本的 StatefulSet,Pod 被部署时是按照 {0..N-1}的序号顺序创建的。在第一个终端中我们可以看到如下的一些信息:
[root@node01 ~]# kubectl get pods -w -l role=stateful
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 1s
web-0 0/1 ContainerCreating 0 1s
web-0 1/1 Running 0 3s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 1s
web-1 0/1 ContainerCreating 0 1s
web-1 1/1 Running 0 4s
请注意在 web-0 Pod 处于 Running 和 Ready 状态后 web-1 Pod 才会被启动。
如同 StatefulSets 概念中所提到的, StatefulSet 中的 Pod 拥有一个具有稳定的、独一无二的身份标志。这个标志基于 StatefulSet 控制器分配给每个 Pod 的唯一顺序索引。 Pod 的名称的形式为<statefulset name>-<ordinal index>。web StatefulSet 拥有两个副本,所以它创建了两个 Pod:web-0 和 web-1。
上面的命令创建了两个 Pod,每个都运行了一个 NGINX web 服务器。获取 nginx Service 和 web StatefulSet 来验证是否成功的创建了它们。
[root@node01 ~]# kubectl get service nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP 10.100.13.170 <none> 80/TCP 2m
[root@node01 ~]# kubectl get statefulset web
NAME DESIRED CURRENT AGE
web 2 2 2m
[root@node01 ~]# kubectl get pod -l app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
web-0 1/1 Running 0 5m 10.244.1.4 node01
web-1 1/1 Running 0 5m 10.244.1.5 node01
10.6 使用稳定的网络身份标识
每个 Pod 都拥有一个基于其顺序索引的稳定的主机名。使用 kubectl exec 在每个 Pod 中执行 hostname 。
[root@node01 ~]# for i in 0 1; do kubectl exec web-$i -- sh -c 'hostname'; done
web-0
web-1
然后我们使用 kubectl run 运行一个提供 nslookup 命令的容器。通过对 Pod 的主机名执行 nslookup,你可以检查他们在集群内部的 DNS 地址。
$ kubectl run -i --tty --image busybox dns-test --restart=Never --rm /bin/sh
nslookup web-0.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.6
nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.6
headless service 的 CNAME 指向 SRV 记录(记录每个 Running 和 Ready 状态的 Pod)。SRV 记录指向一个包含 Pod IP 地址的记录表项。
然后我们再来看下删除 StatefulSet 下面的 Pod:
在一个终端中查看 StatefulSet 的 Pod:
$ kubectl get pod -w -l role=stateful
在另一个终端中使用 kubectl delete 删除 StatefulSet 中所有的 Pod。
$ kubectl delete pod -l role=stateful
pod "web-0" deleted
pod "web-1" deleted
等待 StatefulSet 重启它们,并且两个 Pod 都变成 Running 和 Ready 状态。
$ kubectl get pod -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 2s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 34s
然后再次使用 kubectl exec 和 kubectl run 查看 Pod 的主机名和集群内部的 DNS 表项。
$ for i in 0 1; do kubectl exec web-$i -- sh -c 'hostname'; done
web-0
web-1
$ kubectl run -i --tty --image busybox dns-test --restart=Never --rm /bin/sh
nslookup web-0.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.7
nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.8
我们可以看到Pod 的序号、主机名、SRV 条目和记录名称没有改变,但和 Pod 相关联的 IP 地址可能会发生改变。所以说这就是为什么不要在其他应用中使用 StatefulSet 中的 Pod 的 IP 地址进行连接,这点很重要。一般情况下我们直接通过 SRV 记录连接就行:web-0.nginx、web-1.nginx,因为他们是稳定的,并且当你的 Pod 的状态变为 Running 和 Ready 时,你的应用就能够发现它们的地址。
同样我们可以查看 PV、PVC的最终绑定情况:
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv001 1Gi RWO Recycle Bound default/www-web-0 1h
pv002 1Gi RWO Recycle Bound default/www-web-1 1h
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound pv001 1Gi RWO 22m
www-web-1 Bound pv002 1Gi RWO 22m
当然 StatefulSet 还拥有其他特性,在实际的项目中,我们还是很少回去直接通过 StatefulSet 来部署我们的有状态服务的,除非你自己能够完全能够 hold 住,对于一些特定的服务,我们可能会使用更加高级的 Operator 来部署,比如 etcd-operator、prometheus-operator 等等,这些应用都能够很好的来管理有状态的服务,而不是单纯的使用一个 StatefulSet 来部署一个 Pod就行,因为对于有状态的应用最重要的还是数据恢复、故障转移等等。
标签:kubectl,常用,node01,name,对象,nginx,操作,Pod,root 来源: https://www.cnblogs.com/ywb123/p/15674230.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。