标签:编码器 OK 检测 样本 网络 GANomaly 监督 损失 Net
原文标题:GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training
原文链接:https://arxiv.org/abs/1805.06725
背景介绍
异常检测是计算机视觉领域一个比较经典的问题,它旨在区分正常样本(下文称为OK样本)和非正常样本(下文称为NG样本)。乍一看,像是普通的二分类问题。其实不然,异常检测有一个内在的属性:样本极其不平衡,即OK样本非常多,NG样本非常少。极端情况,训练阶段见不到任何NG样本,该问题就变成了单分类问题了(本文也将这种只有OK样本而没有NG样本参与训练的情况称为“半监督”,笔者认为是不妥的)。本文提出的GANomaly方法,就是针对这种极端情况的。
由于异常检测问题中NG样本通常比较少,直接学习能区分NG样本的模型是很困难的。既然NG样本不可靠,那大家自然会想到采取相反的思路,学习能区分OK样本的模型就好,只要跟OK长得不像的就认为是NG的。自编码器(Autoencoder)是异常检测中比较经典的一种方法。它的解决思路是采用尽可能多的OK样本去学习一个自编码模型,由于该模型见过足够多的OK样本,因此它能够很好地将OK样本重建出来,而NG样本它是没见过的,因此它没法很好地重建出来。推理阶段,通过输入图片的重建误差,就可以区分出OK和NG样本了。但是,该方法非常容易受噪声影响,需要在自编码器上加各种约束,才能得到一个可用的异常检测模型。
主要思想

如上图所示,不同于一般的基于自编码器的方法,本文采用的是一个编码器(Encoder1)-解码器(Decoder)-编码器(Encoder2)的网络结构,同时学习“原图->重建图”和“原图的编码->重建图的编码”两个映射关系。该方法不仅对生成的图片外观(图片->图片)做了的约束,也对图片内容(图片编码->图片编码)做了约束。另外,该方法还引入了生成对抗网络(GAN)中的对抗训练思想。这里,作者将Encoder1-Decoder-Encoder2当成生成网络G-Net,又定义了一个判别网络D-Net,通过交替训练生成网络和对抗网络,最终学到一个比较好的生成网络。
推理阶段,该方法也不同于一般的基于自编码器的异常检测方法。最后用于推断异常的不是原图和重建图的差异,而是第一部分编码器产生的隐空间特征(原图的编码)和第二部分编码器产生的隐空间特征(重建图的编码)的差异。这种方法更关注图片实质内容的差异,对图片中的微小变化不敏感,因而能解决自编码器中易受噪声影响的问题,鲁棒性更好。
笔者认为本文的主要贡献在于提出了这个Encoder1-Decoder-Encoder2的结构,D-Net只是锦上添花的。因为即便没有D-Net和对抗训练的思想,好好调参数该方法也可以work。
网络结构
本文网络结构包含三个子网络。
第一个子网络是一个常规的碗形的自编码器,它的作用是用于重建输入的OK图像。该自编码器结构的设计参考了DCGAN,具体而言,该自编码器的解码器部分(Decoder)和DCGAN的生成网络几乎是一样的,即从一个n维的向量(bottleneck1)映射到一张3通道的图片,如下图所示。该自编码器的编码器部分(Encoder1)则是编码器的逆过程,即从一张3通道的图片映射到一个n维的向量。
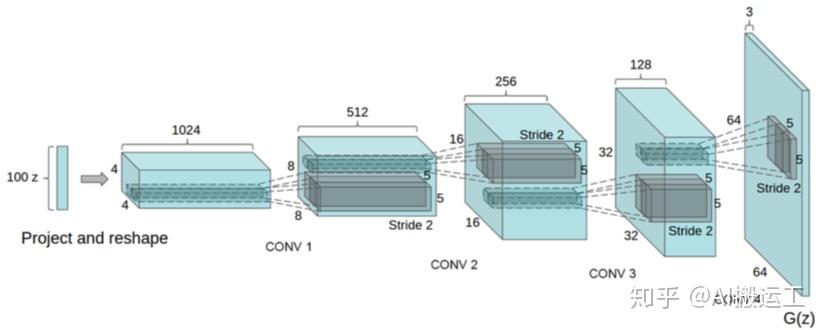
第二个子网络是一个编码网络(Encoder2),它的作用是将第一个子网络重建出来的图片再压缩为一个n维的向量(bottleneck2)。虽然Encoder2采用的结构和Encoder1是一样的,但它们的参数显然是不一样的。这么一个重复的结构看起来没有什么了不起的,但笔者认为该结构是本文思想中最为核心的地方,它摒弃了绝大部分基于自编码器的异常检测方法常用的通过对比原图和重建图的差异来推断异常的方式,采用了一种新的通过对比原图和重建图在高一层抽象空间中的差异来推断异常的方式,而这一层额外的抽象可以使其大大提高抗噪声干扰的能力,学到更加鲁棒的异常检测模型。
文章中第一个子网络和第二个子网络共同构成了生成对抗网络中的生成网络(G-Net),听起来有点费解。其实可以换个思路想,第一个子网络就是一个中规中矩的生成网络,第二个子网络只是它的一个约束条件而已。
第三个子网络是一个判别网络(D-Net),它的作用是用于区分原图和重建图(G-Net生成的图片),即要将原图判别为真,将重建图判别为假。它的结构和第一个子网络的解码网络是一样的。D-Net的引入,是为了引入对抗训练思想,旨在学到更好的G-Net。
综上,该文章设计的网络结构事实上比较简单,就是一个Encoder和一个Decoder,只是通过不同的组合,生成了三部分的子网络。接下来将介绍每部分子网络采用的损失函数。
损失函数
本文包含三个子网络,每个子网络对应一个损失函数。由于文章中写的损失函数和作者公布的代码中的损失函数有些出入,笔者认为代码中的损失函数更为合理,因此下文介绍的都是代码中的损失函数。
第一个子网络的损失是自编码器的重建损失,这里借鉴了pix2pix文章中生成网络的损失,采用的是L1损失,而不是L2损失。因为采用L2损失生成的图像通常比采用L1生成的图像要模糊。
第二个子网络的损失是编码网络的损失,这里需要比对的是原图和重建图在高一层抽象空间中的差异,即两个bottleneck(上文中的bottleneck1和bottleneck2)间的差异,采用的是L2损失。
第三个子网络的损失是常规的GAN中判别网络的损失,这里采用的是二分类的交叉熵损失。
正常来说,采用第一个子网络的生成损失和第三个子网络的判别损失就能生成比较不错的图片了,但是这篇文章主要解决的是异常检测问题。异常是图片集的特性,采用像素级的损失(原图和重建图的差异)来推断是不够合理的,因而引入了第二个子网络的编码损失,文章中最后用于推断的也是该损失。
训练
本文采用的训练策略和常规的GAN一样的,即交替地优化D-Net和G-Net。
优化D-Net时,采用的损失为上述第三个子网络的损失,即:
这里的输入 。虽然这里的
需要通过G-Net来生成,但是训练D-Net时,G-Net的参数是固定的。
优化G-Net时,采用的损失比较复杂:
主体损失为重建损失 ,编码损失
为重建损失的一个约束,对抗损失
则是用来和D-Net博弈。需要注意的一点是,这里的对抗损失的输入对象和优化D-Net时的输入对象是不一样的,这里的
,这和常规GAN的训练是一致的。
推断
前面提到,本文采用的推断方式和一般的基于自编码器的异常检测方法是不一样的。这里推断以来的不是重建损失,而是编码损失
。具体而言,网络训练收敛以后,我们可以计算得到所有OK样本中的
值,选取其中最大的作为判别阈值。推断时,给定一张图片,我们可以利用学好的网络,计算其
值,如果它小于判别阈值则判断为OK样本(正常样本),大于则判断为NG样本(异常样本)。
实验
要做基于GANomaly的异常检测实验,需要准备大量的OK样本和少量的NG样本。找不到合适的数据集怎么办?很简单,随便找个开源的分类数据集,将其中一个类别的样本当作异常类别,其他所有类别的样本当作正常样本即可,文章中的实验就是这么干的。具体试验结果如下:
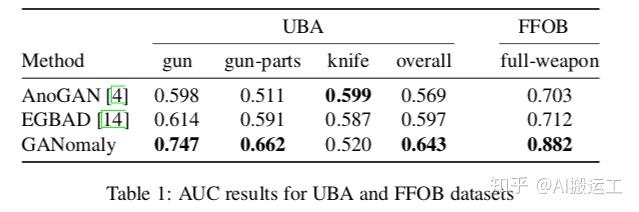
反正在效果上,GANomaly是超过了之前两种代表性的方法。此外,作者还做了性能对比的实验。事实上前面已经介绍了GANomaly的推断方法,就是一个简单的前向传播和一个对比阈值的过程,因此速度非常快。具体结果如下:
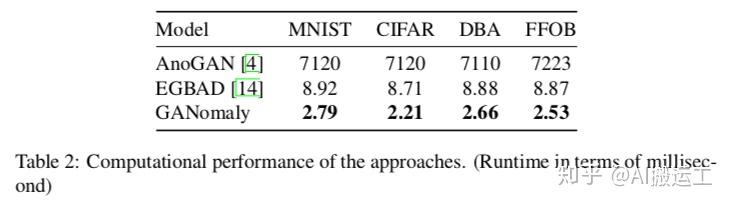
可以看出,计算性能上,GANomaly表现也是非常不错的。
总结
虽然异常检测在数据挖掘领域很早就有人做了,但是计算机视觉领域的相关研究还相对较少。另外,GAN这几年非常火,GAN到底能不能做异常检测,还没有太多人尝试过。本文算是一个比较成功地将GAN用到异常检测的例子。
标签:编码器,OK,检测,样本,网络,GANomaly,监督,损失,Net 来源: https://www.cnblogs.com/ltkekeli1229/p/15583467.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。