标签:10 Bars +% REASONS ML 模型 回测 FUNDS Pitfall
https://zhuanlan.zhihu.com/p/69231390
标题 THE 10 REASONS MOST MACHINE LEARNING FUNDS FAIL
One Sentence Summary
上古时期做金融都用多元线性回归,ML(机器学习)为金融问题引入了非线性函数,但也带来不少坑,过去20年,老夫(作者)看着多少公司起高楼,又楼塌了。根据我的经验,这些失败背后有10个关键错误。
One Page Summary
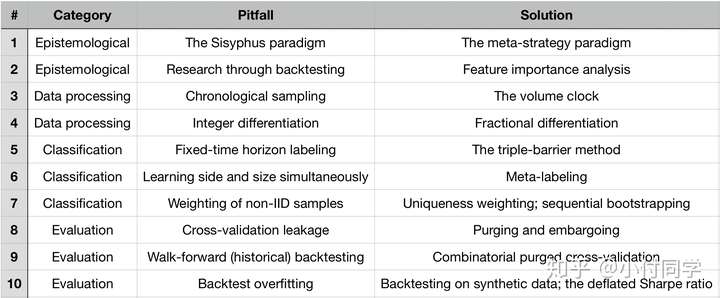
正文
Pitfall #1: 西西弗斯模式(THE SISYPHUS PARADIGM)
Solution #1: 元策略模式(THE META-STRATEGY PARADIGM)
作者首先讨论了自由基金经理(Discretionary portfolio managers~DPM),他们的投资理念比较玄学,不会遵循特定的理论,这样的一群人开会时往往漫无目的、各执一词。DPMs天然地不能组成一个队伍:让50个DPM一起工作,他们的观点会相互影响,结果是老板发了50份工资,只得到一个idea。他们也不是不能成功,关键是要让他们为同一个目标工作,但尽量别交流。
很多公司采用自由基金经理模式做量化 / ML 项目:让50个PhD分别去研究策略,结果要么得到严重过拟合的结果,要么得到烂大街&低夏普率的多因子模型。即使有个别PhD研究出有效的策略,这种模式的投入产出比也极低。这便是所谓让每个员工日复一日搬石头上山的西西弗斯模式(THE SISYPHUS PARADIGM)。
做量化是一项系统工程,包括数据、高性能计算设备、软件开发、特征研究、模拟交易系统……如果交给一个人做,无异于让一个工人造整辆车——这周他是焊接工,下周他是电工,下下周他是油漆工,尝试--->失败--->尝试--->失败,循环往复。
好的做法是将项目清晰地分成子任务,分别设定衡量质量的标准,每个quant在保持全局观的同时专注一个子任务,项目才能得以稳步推进。这是所谓元策略模式(THE META-STRATEGY PARADIGM)。
Pitfall #2: 根据回测结果做研究(RESEARCH THROUGH BACKTESTING)
Solution #2: 特征重要性分析(FEATURE IMPORTANCE ANALYSIS)
金融研究中很普遍的错误是在特定数据上尝试ML模型,不断调参直到得到一个比较好看的回测结果——这显然是过拟合。听说过一个笑话,”如果你的结果不好,说明你调参还不够努力“,学术期刊往往充斥这类虚假的发现,甚至很多是面向测试集调参。
考虑一个ML任务,给定 ,我们可以构建一个分类器,在交叉检验集上评估其泛化误差。假定结果很好,一个自然的问题是:哪些特征对结果的贡献最大?“好的猎人不会对猎狗捕获的猎物照单全收”,回答了这个问题,我们可以增加对提高分类器预测力有帮助的特征,减少几乎是噪声的特征。
很多人质疑ML是黑箱,因为ML的“学习”无需人类的指导,但这不意味着人不应该看看ML学出了什么东西。理解了ML发现的模式(pattern),才能更好地推动下一步工作:什么特征最重要、这些特征的重要性会随时间改变么、这种改变能否被识别和预测。总之,特征的重要性分析是比回测更好的研究策略。
Pitfall #3: 按时间采样(CHRONOLOGICAL SAMPLING)
Solution #3: 交易量钟(THE VOLUME CLOCK)
作者先对 bar 的概念介绍了一通,这里引用该专栏文章的介绍
木芙蓉:[AFML] 读书笔记 (一)金融数据的特殊结构68 赞同 · 11 评论文章
Bars
为了对非结构化的数据使用机器学习算法,我们需要对原始数据进行解析,从中提取出有价值的信息,最后将提取结果进行规范化的存储。最常见的表示提取后信息的方法就是表格。金融领域中将这样的表格内的一条记录(或一个样本)叫做一个Bar。
1. Time Bars
Time bars 指的是以固定的时间区间对数据进行取样(如每分钟一次)后得到的数据。
尽管Time bars 是实践中最流行使用的处理方式,但这里我们指出它的两个不足:第一,市场交易信息的数量在时间上的分布并不是均匀的。开盘后的一小时内交易通常会比午休前的一小时活跃许多。因此,使用Time bars 会导致交易活跃的时间区间的欠采样,以及交易冷清的时间区间的过采样。第二,根据时间采样的序列通常呈现出较差的统计特征,包括序列相关、异方差等。
2. Tick Bars
Tick bars 是指每隔固定的(如1000次)交易次数提取上述的变量信息。一些研究发现这一取样方法得到的数据更接近独立正态同分布 [Ane and Geman 2000]。
使用Tick Bars 还需注意异常值 (outliers) 的处理。一些交易所会在开盘和收盘时进行集中竞价,在竞价结束后以统一价格进行撮合。
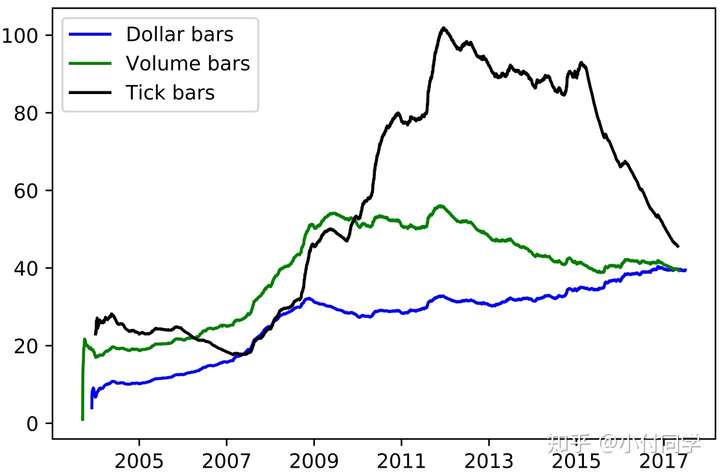
3. Volume Bars & Dollar Bars
Volume Bars 是指每隔固定的成交量提取上述的变量信息。Dollar Bars 则使用了成交额。
使用 Dollar Bars 相对而言是有一定优势的。假设一只股票在一定时间区间内股价翻倍,期初10000元可以购买的股票将会是期末10000元可购买股票手数的两倍。在股价有巨大波动的情况下,Tick Bars以及Volume Bars每天的数量都会随之有较大的波动。除此之外,增发、配股、回购等事件也会导致Tick Bars以及Volume Bars每天数量的波动
使用 Time Bar 会有缺点,相比之下,Volume Clock表现更好。使用固定 bar size 时,每日Dollar/Volume/Tick Bar 的数量如下图所示,可见 Dollar Bars 是更加稳健的方法。
Pitfall #4: 整数差分(INTEGER DIFFERENTIATION)
Solution #4: 非整数差分(FRACTIONAL DIFFERENTIATION)
金融中价格序列平稳性不好,即金融资产价格的期望和方差随时间波动较大,而有监督学习通常要求数据基本满足平稳过程。ML项目中一般会将价格序列处理为涨跌幅(return),即 ,或者
(一阶差分)。做整数阶差分可能使得数据点丢失之前序列所蕴含的信息(Memory),举个例子:A股大多是散户,他们会更青睐低价股,所以绝对价格是很重要的信息。
我们需要在数据平稳性和保留数据信息之间做取舍,非整数/分数差分就是一个较好的解决方案,其定义如下:
给定时间序列 ,阶数
,则
时刻的
阶差分
其中
作者用ADF检验(单位根检验)来检查其能否在95%置信度下拒绝非平稳假设,同时计算 与
相关系数。发现对于 E-mini S&P 500 log-prices,
时满足平稳性假设,同时
与
相关系数达到 0.995;而
即一阶差分时,满足平稳性假设但相关系数仅为0.05。在不同
下ADF检验结果与相关系数绘制如下,
时满足平稳性假设,而
越小相关系数越大。
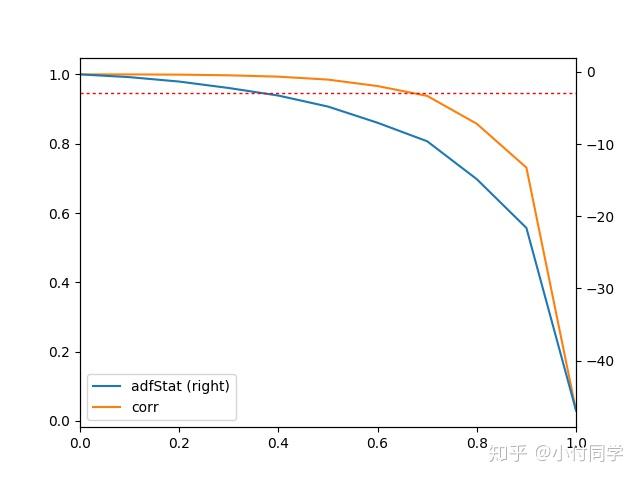
这一部分最初看的有点懵,看过好基友 LXX 同学的笔记才大体明白,上面的分析部分基于 LXX 同学的笔记,感谢~
Pitfall #5: 固定时间范围标签(FIXED-TIME HORIZON LABELING)
Solution #5: 三边界方法(THE TRIPLE-BARRIER METHOD)
大部分ML的论文几乎都用以下固定时间范围标签方法:
,其中
,阀值
为常数
该方法有若干不足:
- 如 Pitfall #4 所述,time bars 的统计性质并不好
- 用常数阈值
而不顾波动性是不明智的,假设某股票刚开盘时
,而中午时
,若选定
,则中午时
均为0,尽管
是可预测的而且在统计上显著。
- 原文如下,没看懂。。。(我猜是说这种方法可能被强制平仓,求指教 hhh)
Third, it is simply unrealistic to build a strategy that profits from positions that would have been stopped-out by the fund, exchange (margin call) or investor.
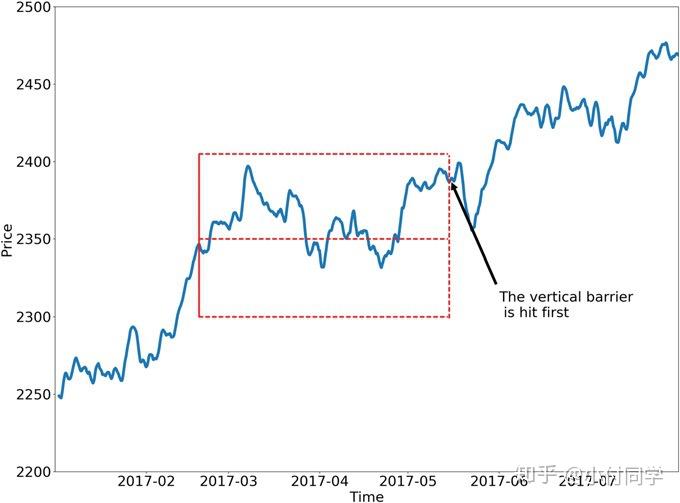
三边界方法(THE TRIPLE-BARRIER METHOD)考虑到平仓的触发条件,是更好的处理方式,其包括上下水平边界和右边的垂直边界。水平边界需要综合考虑盈利和止损,其边界宽度是价格波动性的函数(波动大边界宽,波动小边界窄);垂直边界考虑到建仓后 bar 的流量,如果不采用 time bars,垂直边界的宽度就不是固定的(翻译太艰难了,附上原文)
The third barrier is defined in terms of number of bars elapsed since the position was taken (an activity- based, not fixed-time expiration limit).
如果未来价格走势先触及上边界,可以取 ;先触及下边界,则取
(如下图);先触及右边界,可以取
,或者根据盈利正负,取
。
Pitfall #6: 同时学出方向和规模(LEARNING SIDE AND SIZE SIMULTANEOUSLY)
Solution #6: 元标签(META-LABELING)
金融中用ML的另一常见错误是同时学习仓位的方向和规模(据我所知很多论文仅对买/卖方向做决策,每笔交易的金额/股数是固定的)。具体而言,方向决策(买/卖)是最基本的决策,规模决策(size decision)是风险管理决策,即我们的风险承受能力有多大,以及对于方向决策有多大信心。我们没必要用一个模型处理两种决策,更好的做法是分别构建两个模型:第一个模型来做方向决策,第二个模型来预测第一个模型预测的准确度。
很多ML模型表现出高精确度(precision)和低召回率(recall),即 很高,而
很低。这意味着这些模型过于保守,大量交易机会被错过。
F1-score 综合考虑了精确度和召回率,是更好的衡量指标,元标签(META-LABELING)有助于构建高 F1-score 模型。首先(用专家知识)构建一个高召回率的基础模型,即对交易机会宁可错杀一千,不可放过一个。随后构建一个ML模型,用于决定我们是否应该执行基础模型给出的决策。元标签+ML有以下4个优势:
- 大家批评ML是黑箱,而元标签+ML则是在白箱(基础模型)的基础上构建的,具有更好的可解释性;
- 元标签+ML减少了过拟合的可能性,即ML模型仅对交易规模决策不对交易方向决策,避免一个ML模型对全部决策进行控制;
- 元标签+ML的处理方式允许更复杂的策略架构,例如:当基础模型判断应该多头,用ML模型来决定多头规模;当基础模型判断应该空头,用另一个ML模型来决定空头规模;
- 赢小输大会得不偿失,所以单独构建ML模型对规模决策是有必要的。
achieving high accuracy on small bets and low accuracy on large bets will ruin you
Pitfall #7: (WEIGHTING OF NON-IID SAMPLES)
Solution #7: (UNIQUENESS WEIGHTING AND SEQUENTIAL BOOTSTRAPPING)
实验室希望研究血液胆固醇含量受什么因素影响,从人群中随机实验者采集的血液样品服从独立同分布(IID),假如有人把每瓶血液都溅出一点到临近试管中,即试管10的血样包含试管1-9的部分血样,试管11的血样包含试管2-10的部分血样,现在要确定什么因素会影响血液胆固醇含量会非常困难。金融ML也面临同样的问题:
(1) labels are decided by outcomes;
(2) outcomes are decided over multiple observations;
(3) because labels overlap in time, we cannot be certain about what observed features caused an effect.
作者提出一种基于权重的采样方法,但不是非常直观,暂且不分析,留个 TO DO 日后填。各位看官可以看看后记中推荐的两篇,其他人对此有相应的分析。
Pitfall #8: 交叉检验集泄露信息(CROSS-VALIDATION LEAKAGE)
Solution #8: 清理和禁止(PURGING AND EMBARGOING)
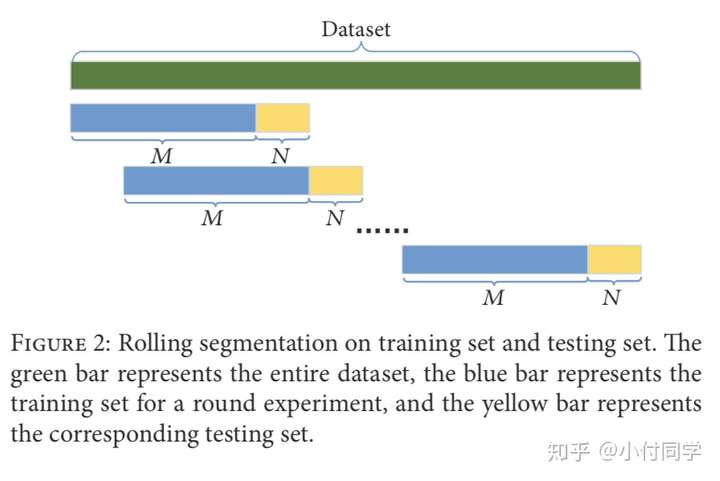
作者论证了 k-折交叉检验(k-fold CV)方法在金融中失败的原因以及处理方法,然而我看过的若干论文中对金融数据的处理几乎都是依照时间顺序将数据划分为 train、CV、test 集,或者用 rolling 方法(如下图),而没有用 k-折交叉检验方法。
Anyway,作者的思想是值得借鉴的——金融中需要警惕在训练集 / CV 集中引入未来信息。举个栗子,由于金融数据时序的自相关性, 、
;如果将
划为训练集,将
划为CV集,必然会将训练集的信息泄露(leakage)到CV集。好的做法应该是在训练集和CV集之间设定一个间隔:若
是训练集最后一个数据,则CV集第一个数据可以为
。
Pitfall #9: 前向回测(WALK-FORWARD / HISTORICAL BACKTESTING)
Solution #9: CPCV(COMBINATORIAL PURGED CROSS-VALIDATION)
文献常用的回测方法是前向回测(Walk-forward Backtesting):根据当前时刻以前的数据做决策。这种方式容易解读同时也很直观,但存在几点不足:
- 前向回测只测试了单个场景,容易过拟合;
- 前向回测的结果未必能代表未来的表现。
这里作者提出了一种更加丧心病狂的切分方法:将所有数据分为 份(注意避免信息泄露),从中任意取
份作为测试集,剩下
份作为训练集,总共有
种取法。这种方法最大的优势是允许我们得到某策略在不同时期的夏普率分布,而不是计算一个夏普率值。
这一部分有些懵,训练/测试集怎么可以这样划分。。。可能是我金融知识还不够吧,另外作者提到 walk-backward backtest ——从2017年回测到2007年,简直不知所云。
Pitfall #10: 回测过拟合(BACKTEST OVERFITTING)
Solution #10: 保守夏普率(THE DEFLATED SHARPE RATIO)
假设 独立通过分布且
,可证明
。若
代表一系列回测结果的夏普率,则只要回测次数足够多,或者每次回测结果方差足够大,从中都能选出任意高的结果,尽管有可能
。
这提醒我们要考虑到回测次数造成的过拟合,一种解决方案是保守夏普率(THE DEFLATED SHARPE RATIO,DSR),该方法数学背景较复杂,这里不详细介绍;其思想是给定一系列对夏普率 的估计值
,通过统计检验的方法估计能否推翻零假设
。
后记
有部分文章对此分析过,不过不知道为什么大家都分析7个原因,我是10个hhh(作者发布了两个版本的论文),各位看官可以对比参考~
标签:10,Bars,+%,REASONS,ML,模型,回测,FUNDS,Pitfall 来源: https://www.cnblogs.com/dhcn/p/15571042.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。