标签:DeepLab 遮罩 transformer PQ 预测 MaX 像素 全景 decoder

摘要
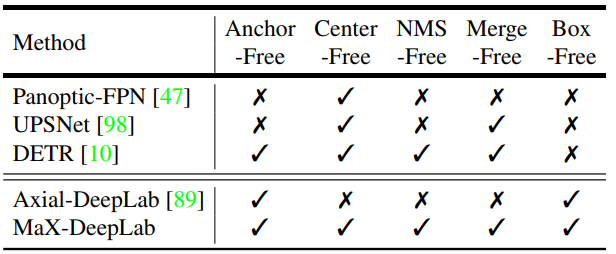
MaX-DeepLab优势:
加了遮罩:基于包围框的方法是预测包围框,不用包围框的是预测遮罩
端到端,无代理子任务:直接通过transformer预测类别标签,用二匹配方法,以PQ-style loss指标训练。
最重要的transformer:引入全局memory路径,再加上原来的像素CNN路径,合成双路径结构,使得各CNN层可以直接通信(?)
实验结果:首次让基于包围框和不用包围框的方法的准确性近乎接近,不用包围框可以使预测更无条件进行
Introduction
全景分割:对每个像素进行预测,预测遮罩归属和类别,每个像素都有唯一的类别thing/stuff,不允许两个物体重合,不仅预测出了类别还能将各物体分离开

语义分割:只能红色的都是人,但是不能区分是几个人,无法分个体处理并且甚至肉眼都看不出是人(比如方框里的那玩意)

实例分割:类似目标检测,只不过输出的是遮罩,只能分离特定类别的物体,也不是对像素标记,而是只找到感兴趣物体的物体轮廓即可

现有的研究
Panoptic-FPN
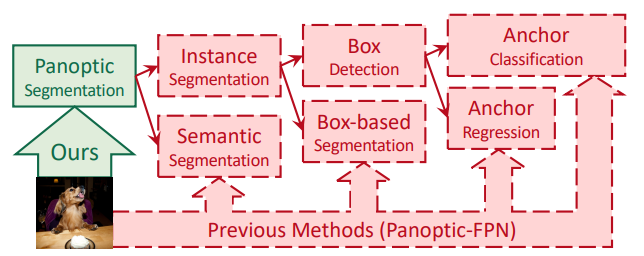
这是基于包围框的处理管线,有anchors, 包围框特例规则等人工设置的模块,虽然这些规则已经研究得挺好了但是对于以下情况还是会有问题。

| Ours | Axial-DeepLab | box-based |
|---|---|---|
| 成功 | 方法基于中心,中心太近的物体会被认为是同一个物体 | 椅子包围框的置信度太低,被过滤 |
优化
使得代理任务数更少:
从处理管线里直接去掉包围框:这更好地满足 实例分割任务是对于遮罩的性质。
一个SOTA的算法Axial-DeepLab是像素级别的预测(相比于包围框来说)(会不会处理量过于大?),它不适于变形了的或中心点重合的物体
本文:
-
借鉴DETR end-to-end的思想用mask transformer直接完成预测遮罩区域和对应语义的任务
-
用PQ-style loss这个自己发明的遮罩重合度和类别正确度的乘积的指标,以及用one-to-one bipartite matching* 评价 predicted mask 与 ground truth
-
不用人工参数
-
是Axial-DeepLab的拓展改进
one-to-one bipartite matching
之前box-free的方法都是label assignment(匹配target和成千上万个anchor,选择正样本)先对目标生成多个预测(one-to many),再对多个预测去重(many-to-one),而类似YOLO对每个目标匹配一个grid的就是one-to-one assignment
bipartite matching(二分图匹配):左边和右边能匹配起来并且两条边不依附于同一个节点
网络结构:
传统:transformer放在CNN顶端
本文:将CNN和transformer结合起来的双路径框架,加了全局的memory,任何卷积层可以与memory直接沟通,促使transformer可以插入任何一层CNN(?)
decoder:
还采用了沙漏式解码器,将多种尺度特征聚合起来,最终以高分辨率输出。
方法
Transformers
在机器翻译中应用。每个transformer中有两个模块,encoder(编码)模块包括一堆小的encoder,decoder(解码)模块有同样数量的小的decoder
![]()
![]()
![]()
第一层encoder是一个word embedding(用低维的一些数字vector表示单词,embedding越近的单词意义越相似,通过神经网络将低维的数字映射了高维的关联关系),以后每层都是前层来的
每一个小的encoder里面都有两部分:self-attention和前馈传播网络
每一个小的decoder还有一个Attention层(?)
![]()
self-attention使得网络可以联系上下文,比如翻译中"it"的指代
Self-attention的执行步骤
-
在每个encoder的输入vector后加3个vector: Query, key, value 它们的维度都固定且小于embedding
-
算得分Query1 dot Key1,Query1 dot Key2(后面的词),得出我们在编码这个单词时,对其他位置的关注度
-
将score进行softmax标准化,使得score∈(0,1]
-
Value * score,得出每个词的focus程度
-
将有关于它的各权重相加
比如对Thinking这个词,并考虑它后面的Machines这个词:

所以,transformer由encoder和decoder组成,encoder包括数个小encoder,decoder也是,每个小encoder由self-attention和前馈网络组成,self-attention计算包括6个步骤,同时为让attention可以关注更多位置,引入multi-head即多检测头机制,使该层有多个Query/key/value矩阵
算法基本方程
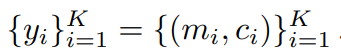 mi是物体ground truth遮罩,各不重合,ci是该遮罩的分类号
mi是物体ground truth遮罩,各不重合,ci是该遮罩的分类号
 是预测的遮罩,mi近似不相交,pi是c这个分类的概率
是预测的遮罩,mi近似不相交,pi是c这个分类的概率
 对每个遮罩求类别
对每个遮罩求类别
 是(h,w)这个像素的第i个预测mask,下标i称为其ID,之后还要过滤掉confidence太低的
是(h,w)这个像素的第i个预测mask,下标i称为其ID,之后还要过滤掉confidence太低的
PQ-Style Loss
PQ(全景质量)=识别质量(RecognitionQ)*分割质量(SegmentationQ)
先定义PQ-style的分类的ground truth和预测值间的相似矩阵
然后优化使得预测的遮罩结果逼近真实的遮罩结果
遮罩相似矩阵
相似矩阵:,那么A和B是相似矩阵
遮罩相似矩阵定义为: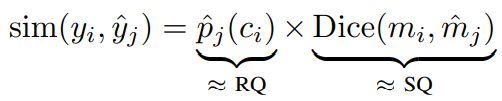 ,前面的yi=
,前面的yi=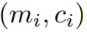 ,^yi=
,^yi=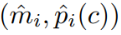
Dice(应对语义分割中正负样本强烈不平衡的场景,评估两个样本相似性)系数评估预测样本和真实样本
遮罩相似矩阵下界0是预测的分类不对 或者 遮罩与正确遮罩无交集,上界1是分类正确 且 遮罩完全吻合
遮罩匹配
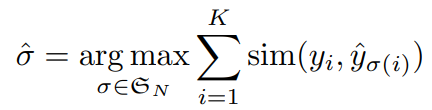
用匈牙利算法进行预测遮罩和真实遮罩的二部图匹配,找到对应真实值的那K个预测遮罩叫正样本,并得出正样本的正确排列,那N-K个负样本就当作空集(无物体)
DETR的一对一匹配是为了移除重复和重叠,本文没有遇到这样的困难,并且利用PQ(panoptic quality)矩阵成功(因为上面的匹配输出的是唯一对应排列)使每个预测遮罩只能对应一个真实遮罩来促进训练
PQ-style loss
用上面的方程来优化模型的参数θ(这是哪个参数?)
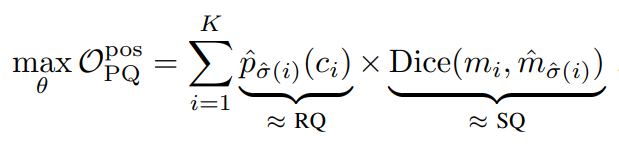
为了让它更适合梯度下降训练,我们加了交叉熵项Log: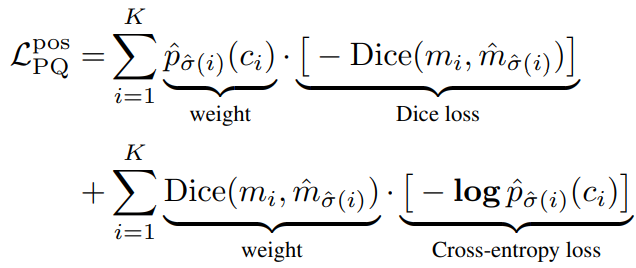
然后也给了负样本一些权重,来训练空集的识别: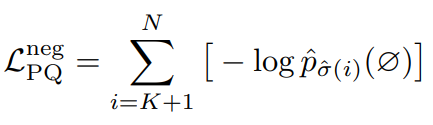 ,于是最后PQ-Style Loss就是:
,于是最后PQ-Style Loss就是: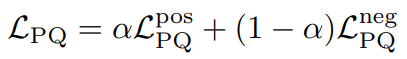 用这个loss来训练
用这个loss来训练
网络结构
包括一个双路径transformer,一个将多尺度结合起来的沙漏式解码器和检测头
双路径Transformer


解码器
本文不是用的轻量级解码器,而是用了L层层叠的解码器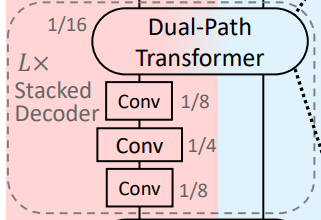
这个解码器进行的处理是将特征进行尺寸调整后,加和
Bilinear Resizing 指用双线性插值将图片缩放,调整尺寸

本文的解码器只是做了简单的各尺度加和,每一层解码器后面加了一个transformer再进入下一个分辨率,并且这里的每个分辨率不和YOLO一样直接参与预测,只是聚合一下各尺度的特征供接下来处理
检测头
对于N个遮罩,通过2个全连接层和1个SoftMax标准化后,我们得出了分类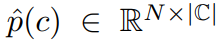
另外一路经过两个全连接层的得到了特征 ,然后从解码器出来的在经过两个卷积层(步长为4)后得到了正则化的特征
,然后从解码器出来的在经过两个卷积层(步长为4)后得到了正则化的特征 ,预测的遮罩^m就是f和g相乘:
,预测的遮罩^m就是f和g相乘:
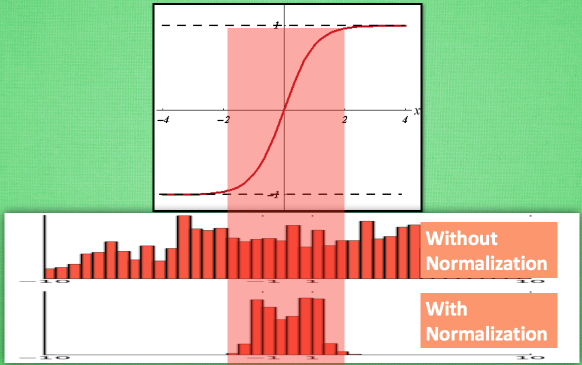
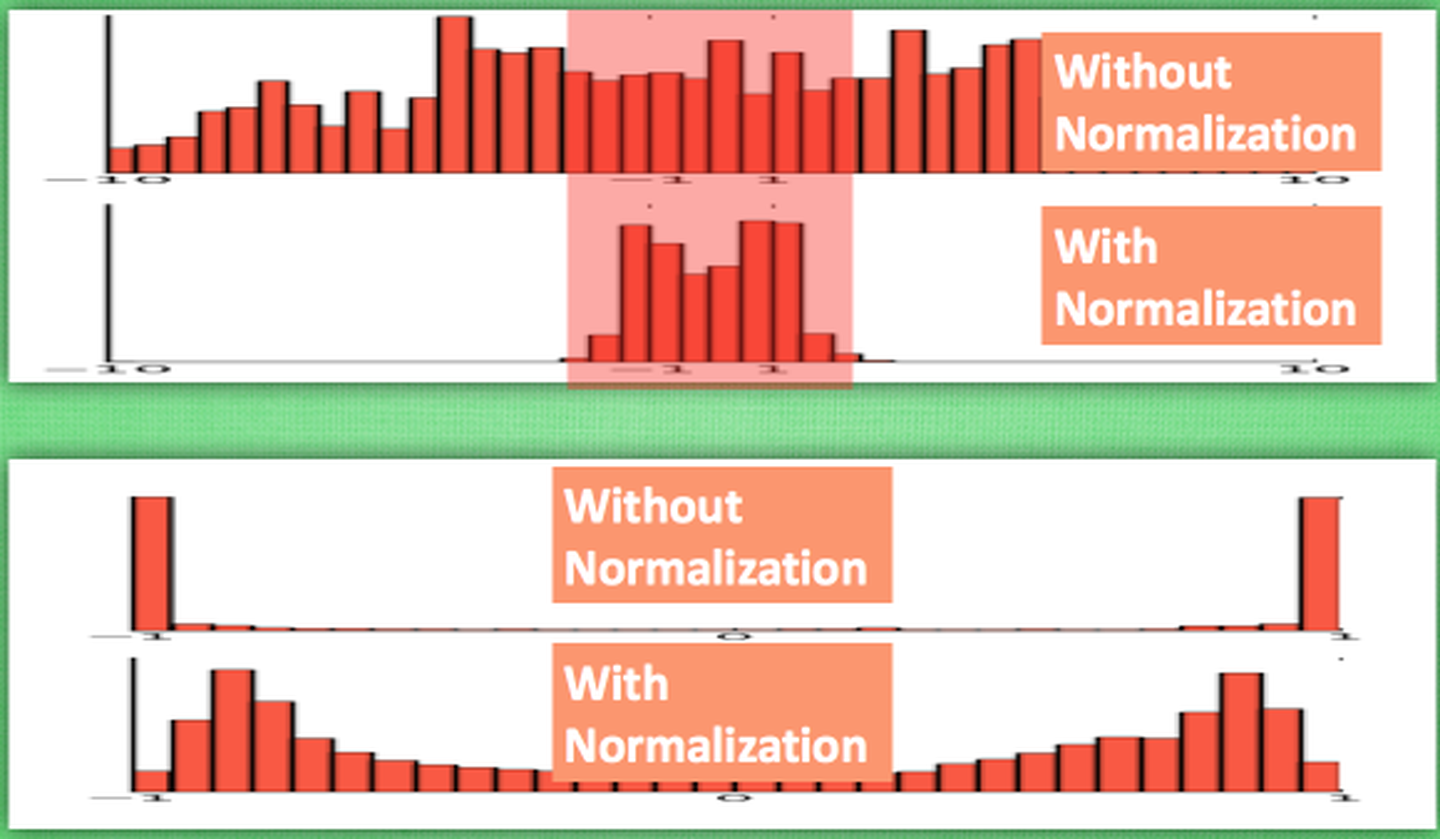
在处理时,应用了batch norm([知乎-Batch Normalization]是为防止训练饱和,在隐藏层中也进行边训练边正则化,如下图)来改善初始化值,并且对原始的图像进行遮罩双线性上采样(用双线性是为了不让放大模糊)
最后结合上述的m和p就是结果
辅助Loss
辅助Loss可以帮助网络训练
Instance discrimination
Instance discrimination常见于无监督学习中,露头于"What makes instance discrimination good for transfer learning?" 它的 MoCo 超越了有监督网络,通过物件级别的对比学习来得到有意义的表征,该表征可以用于反映实例之间的明显相似性。正如有监督分类学习可以获得具备 不同类别之间的明显相似性的表征。相似地,通过将class数量扩展为instance数量,我们最终可以用无监督方法得到表示instance之间明显相似性的表征。因而,instance discrimination本身成立的假设是建立在:每一个样例均与其他样例存在显著不同,可以将每一样例当作单独类别看待的基础上。
本文将每个像素作为每个instance,处理
对于每个遮罩,定义
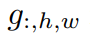 上的特征embedding
上的特征embedding 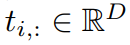
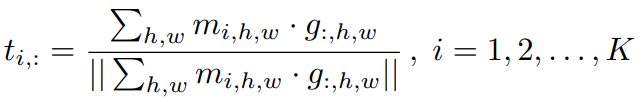
这K个实例embedding 对应着K个真实遮罩。然后这 个pixel的
个pixel的 每个对应一个instance discrimination任务,每个像素对应哪个遮罩embedding会被对应好(?)
每个对应一个instance discrimination任务,每个像素对应哪个遮罩embedding会被对应好(?)
Contrastive Loss:像素会被表示成vector,相同类别的vec距离近,不同类别的距离远,该loss想让和这个样本同类的正样本趋近于1,负样本趋近于0(?)

τ 是temperature(?),m项仅当像素(h,w)属于真实遮罩mi时为1,并且跑一遍所有的像素,这会促使同个物体的特征是相似的,而不同的物体是差别很大的,这就是contrastive loss处理的结果,也是实例分割的目的
遮罩ID的交叉熵
这会得出每个像素(h,w)下的“正确”遮罩ID号,优化的过程中将使用交叉熵Loss
语义分割检测头
当Stacked decoder的L=0时,在backbone的顶端加入语义检测头,否则把语义检测头放在步长为4的decoder的后面,因为通过实验得知这样会让遮罩的特征g和语义的特征分离得很好
实验
参数
32 TPU 训练 100k 样本(分成54 epochs)
batch size=64
poly式的learning rate = 1e-3
推理的图像尺寸=641×641
遮罩的置信度=0.7 过滤遮罩ID的置信度<0.4的像素的类别,设置为空
输出尺寸:N=128 D=128(128个通道)
PQ-Style Loss
weight=3.0
α=0.75
辅助Loss
instance discrimination
τ=0.3
weight=1.0
遮罩ID的交叉熵
weight=0.3
语义分割检测头
weight=1.0
Main results
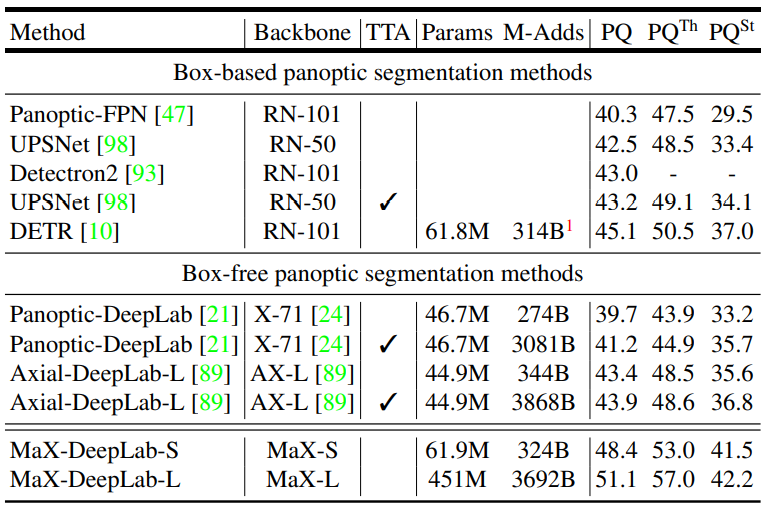
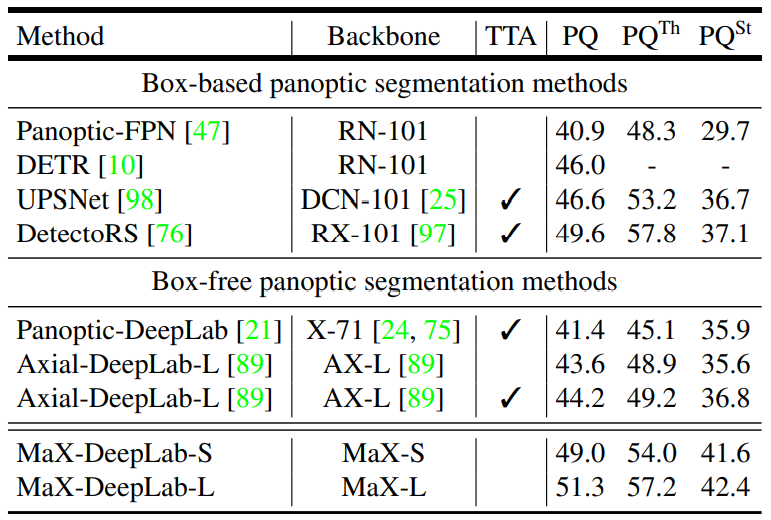
小模型MaX-DeepLab-S和大模型MaX-DeepLab-L 跑 COCO val(训练过程的测试集),test-dev(开发过程中训练过程后的测试集)
MaX-DeepLab-S使用ResNet50骨架,在最后两阶段用了Axial-attention 块,预训练后将最后一个阶段替换为双路径transformer L=0decoder
MaX-DeepLab-L使用Wide-ResNet-41骨架,L=2decoder,替换所有步长=16的残差块为axial-attention双路径块
Ablation Study
将Wide-ResNet-41的16步长的块都加入双路径transformer,使得其拥有四种尺度的注意力
为了更快地训练,我们不用decoder,并且将Pixel-to-pixel近似用卷积块代替
尺寸
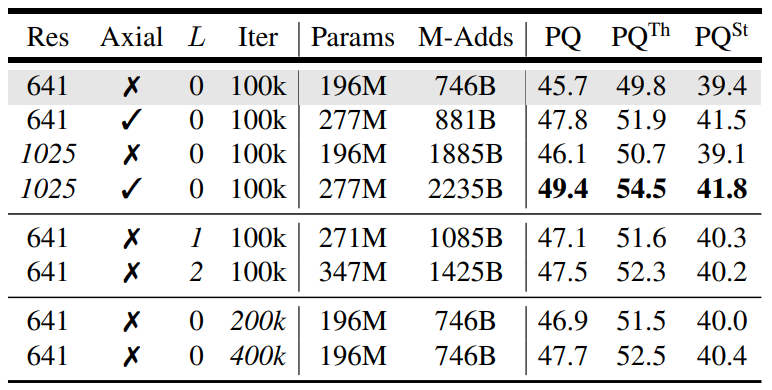
各个网络的尺寸如表所示。加入Axial-attention有最大的提升,将输入分辨率提升至1025×1025后同样采用100kIter后PQ提升至49.4%,加入L=1的decoder后PQ有较大的提升,L=2就没有那么明显了,Iter数量更多更利于聚合,但是没有DETR里面那种明显
双路径Transformer
本文用Memory-to-pixel来把transformer连接到CNN上,接下来的情况见表:
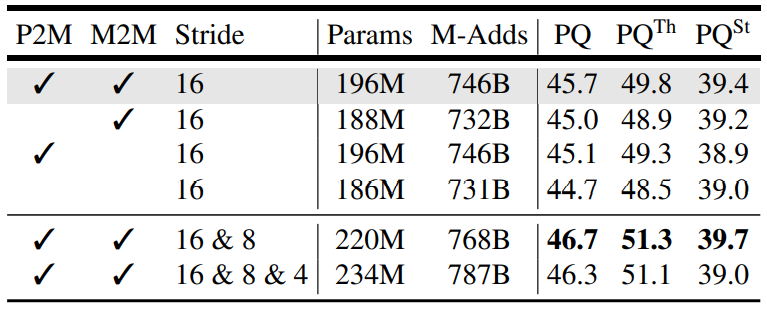
把P2M去掉会带来损失,但是把M2M去掉会更鲁棒,我们认为是因为非重合遮罩方程促使的。其实DETR是通过M2M的self-attention来去重的。
把步长为8的块也加入transformer会带来1%的提升,但是加入步长为4的块就没有提升了
辅助Loss
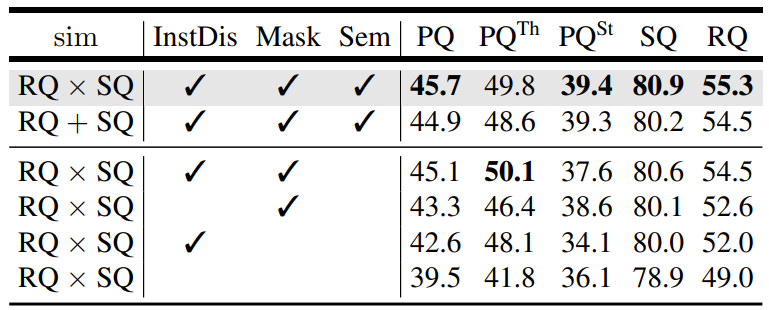
通过从匈牙利算法基本的RQ+SQ开始,逐渐改进,可以看到其逐步的提升
分析
训练曲线

模型通过1/10于DETR的iterations快速收敛到了46%PQ附近,由(b),(c)可知,匹配的分类效果优于匹配的遮罩效果,同时(d),(e)进行了逐像素的instance discrimination效果和Mask-ID预测的效果,绝大多数的像素都预测得很好,只有10%一直预测不好,最终也是它们导致的PQ error
好看的
为了更好了解transformer遮罩特征f,标准化的decoder输出g,它们怎样得到预测值^m的,我们用RGB3个通道训练,得到只有这三种基本颜色的遮罩结果,如图:

差别越大的物体颜色差别越大
阅读总结
全景分割是一个非常有意思的领域,之前没有接触过NLP的transformer,研究复杂神经网络的经历较少,对各种Loss学习得也不足,对数学公式的推导和理解也较欠缺,这样看来虽然对神经网络很感兴趣,但是相较于研究生阶段高端深入的研究学习来说,目前的知识可能还处在新手村,还有很长的路要走,需要继续和现在一样查英文解释,以一敌百拓展学习,多举一反三多读文献来进步,希望能早日在我浙做出好的成果!
标签:DeepLab,遮罩,transformer,PQ,预测,MaX,像素,全景,decoder 来源: https://www.cnblogs.com/IamIron-Man/p/15516553.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。