标签:读取 nan 索引 np print inf now numpy
1、numpy读取数据
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)

做一个小demo:
现在这里有一个英国和美国各自youtube1000多个视频的点击,喜欢,不喜欢,评论数量(["views","likes","dislikes","comment_total"])的csv,运用刚刚所学习的只是,我们尝试来对其进行操作
数据来源:https://www.kaggle.com/datasnaek/youtube/data
# 暂无YouTube.csv数据
np.loadtxt(Us_video_data_numbers_path, delimiter=",", dtype=int, uppack=1)
delimiter:指定边界符号是什么,不指定会导致每行数据为一个整体的字符串而报错
dtype:默认情况下对于较大的数据会将其变为科学计数的方式
upack:默认是 Flase(0),默认情况下有多少条数据,就会有多少行;True(1)的情况下,每一列的数据会组成一行,原始数据有多少列,加载出来的数据就会有多少行,相当于转置(学过线代简而易懂)
转置的三种操作如下:
import numpy as np
A = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print(A.T) # 转置操作
print("*"*10)
print(A.transpose()) # 转置操作
print("*"*10)
print(A.swapaxes(1, 0)) # 根据轴方向进行转置操作
[[1 4 7]
[2 5 8]
[3 6 9]]
[[1 4 7]
[2 5 8]
[3 6 9]]
[[1 4 7]
[2 5 8]
[3 6 9]]
2、numpy索引和切片
对于刚刚加载出来的数据,我如果只想选择其中的某一列(行)我们应该怎么做呢?
# 缺少数据集,暂且模拟实现
import numpy as np
USA_file_path = "./YouTuBe_Video_Data/America.csv"
t = np.loadtxt(USA_file_path, delimiter=",", dtype=int)
# 取第n行
print(t[2])
# 取连续的多行
print(t[2:])
# 取不连续的多行
print(t[2, 4, 6, 8, 10])
# 取列
print(t[1, :])
print(t[2:, :])
print(t[[2, 4, 6, 8, 10], :])
# 取连续的多列
print(t[:, 2:])
# 取不连续的多列
print(t[:, [0, 2]])
# 取行和列 如:第3行,第4列的值
print(t[2, 3])
# 取多行多列 如:第3行到第4行 第2列到第4列
# 取的是行和列交叉点的位置
print(t[2:5, 1:4])
# 取多个不相同的点
print(t[[0, 2], [0, 1]]) # 结果为(0,0) (2,1)
3、numpy中数值的修改
简单数值的修改:

那么问题来了:
比如我们想要把t中小于10的数字替换为3
一张图看明白:【可以看出为True的数值处全部改为了3】
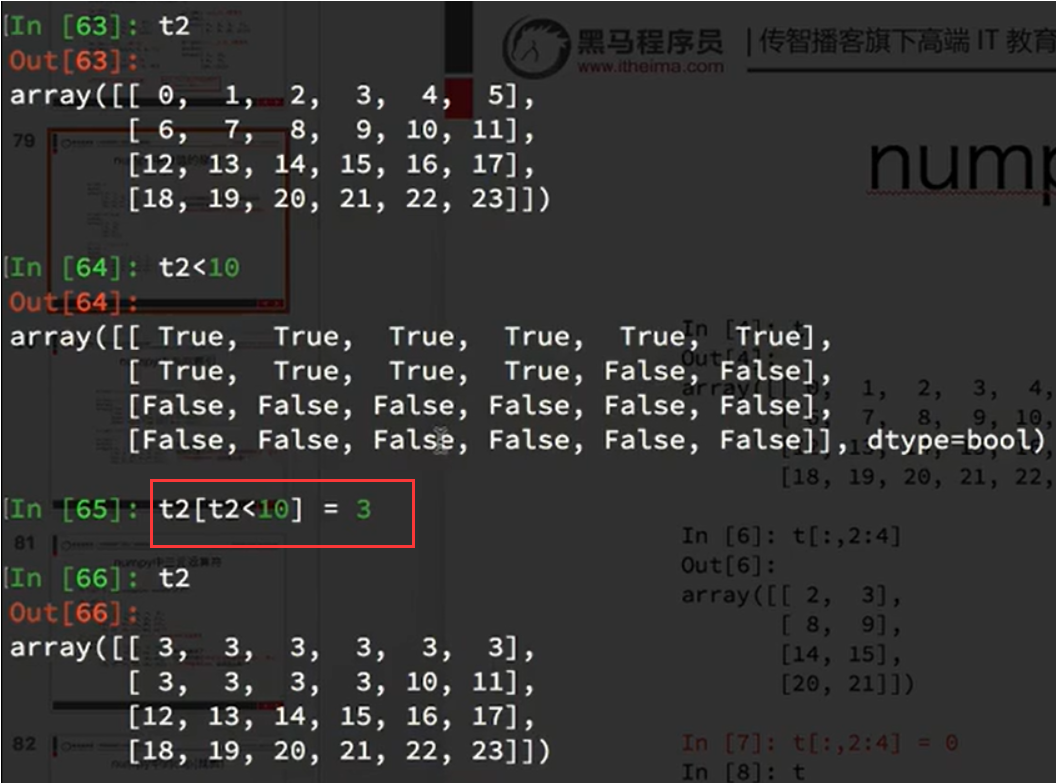
那么问题又来了:
如果我们想把t中小于10的数字替换为0,把大于10的替换为10,应该怎么做??
此处采用了三元运算符的思想

那么问题双来了:
如果我们想把t中小于10的数字替换为0,把大于18的替换为18,应该怎么做??
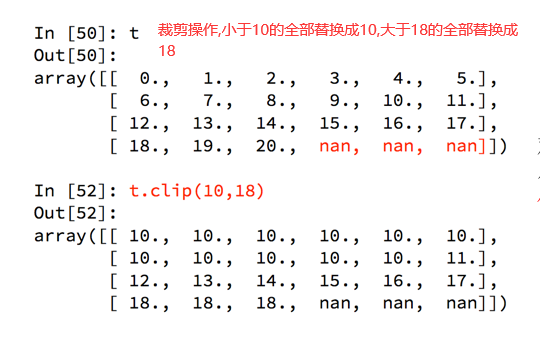
4、numpy中的nan和inf
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
-
当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
-
当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity, inf表示正无穷,-inf表示负无穷
什么时候回出现inf包括(-inf,+inf)
- 比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf
那么如何指定一个nan或者inf呢?(注意他们的type类型)

5、numpy中的nan的注意点

那么问题来了,在一组数据中单纯的把nan替换为0,合适么?会带来什么样的影响?
比如,全部替换为0后,替换之前的平均值如果大于0,替换之后的均值肯定会变小,所以更一般的方式是把缺失的数值替换为均值(中值)或者是直接删除有缺失值的一行
那么问题来了:
-
如何计算一组数据的中值或者是均值
-
如何删除有缺失数据的那一行(列)[在pandas中介绍]
6、numpy中常用统计函数
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None) 即最大值和最小值只差
标准差:t.std(axis=None)

默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上的结果
7、ndarry缺失值填充均值
t中存在nan值,如何操作把其中的nan填充为每一列的均值
import numpy as np
nan = np.nan
t = np.array([[0, 1, 2, 3, 4, 5],
[ 6, 7, nan, 9, 10, 11],
[12, 13, 14, nan, 16, 17],
[ 18, 19, 20, 21, 22, 23]])
def fill_nan_by_column_mean(t):
for i in range(t.shape[1]):
nan_num = np.count_nonzero(t[:, i][t[:, i] != t[:, i]]) # 计算非nan的个数
if nan_num > 0: # 存在nan值
now_col = t[:, i]
now_col_not_nan = now_col[np.isnan(now_col) == False].sum() # 求和
now_col_mean = now_col_not_nan / (t.shape[0] - nan_num) # 和/个数
now_col[np.isnan(now_col)] = now_col_mean # 赋值给now_col
t[:, i] = now_col # 赋值给t,即更新t的当前列
着实麻烦!后期学习pandas进行处理
标签:读取,nan,索引,np,print,inf,now,numpy 来源: https://www.cnblogs.com/wangzheming35/p/15353411.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。