标签:yarn server1 dfs hadoop 3.2 usr 安装
tar -zxvf
改成root权限
chown -R root:root *
修改配置文件
cd /usr/hadoop-3.2.2/etc/hadoop/
(1)修改 core-site.xml
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://stydy1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop-3.2.2/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>he1:2181,he2:2181,he3:2181</value>
</property>
</configuration>
上面指定 zookeeper 地址中的he1,he2,he3 换成你自己机器的主机名(要先配置好主机名与 IP 的映射)或者 ip
(2)修改 hdfs-site.xml
vi hdfs-site.xml
<!--指定hdfs的nameservice为mybigdata,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mybigdata</value>
</property>
<!-- myNameService1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mybigdata</name>
<value>server1,server2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mybigdata.server1</name>
<value>server1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mybigdata.server1</name>
<value>server1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mybigdata.server2</name>
<value>server2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mybigdata.server2</name>
<value>server2:50070</value>
</property>
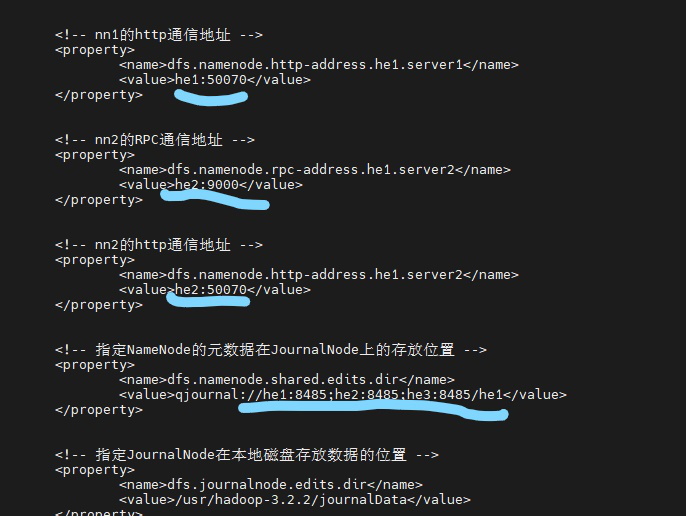
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal:/server1:8485;node1:8485;node2:8485;server2:8485/mybigdata</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/hadoop-3.2.2/journalData</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mybigdata</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,Failover后防止停掉的Namenode启动,造成两个服务,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆,注意换成自己的用户名 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop-3.2.2/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop-3.2.2/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
在这里吧 里面的‘’mybigdata‘’改成你自己喜欢的名字 server1,server2可改可不改,
server1:9000 server1:50070 ‘’server1这些地方要改成你的主机名
<value>qjournal:/server1:8485;node1:8485;node2:8485;server2:8485/mybigdata</value>
这里面‘/server1:8485;node1:8485;node2:8485;server2:84
Yarn高可用
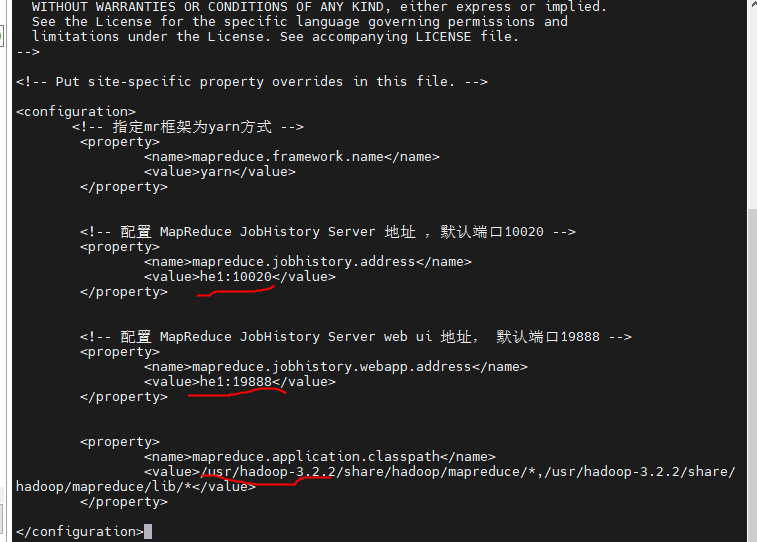
修改 mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>server1:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>server1:19888</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/usr/hadoop-3.2.2/share/hadoop/mapreduce/*,/usr/hadoop-3.2.2/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
)修改 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
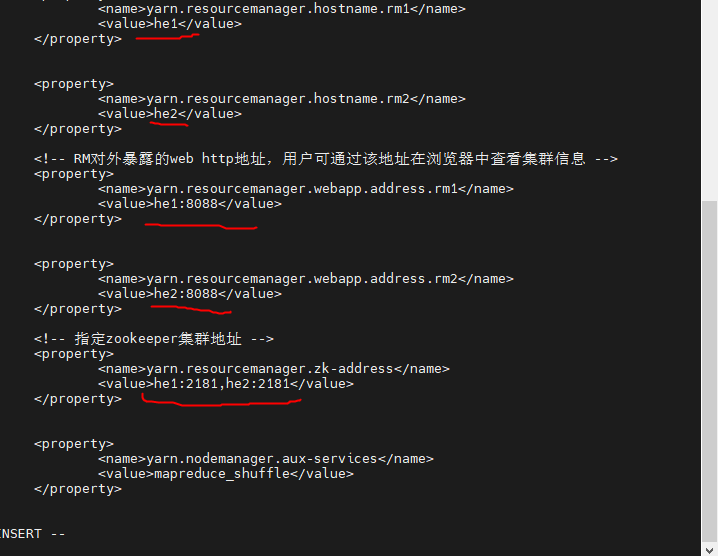
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>server1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>server2</value>
</property>
<!-- RM对外暴露的web http地址,用户可通过该地址在浏览器中查看集群信息 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>server1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>server2:8088</value>
</property>
<!-- 指定zookeeper集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>server1:2181,server2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/hadoop-3.2.2/etc/hadoop:/usr/hadoop-3.2.2/share/hadoop/common/lib/*:/usr/hadoop-3.2.2/share/hadoop/common/*:/usr/hadoop-3.2.2/share/hadoop/hdfs:/usr/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/usr/hadoop-3.2.2/share/hadoop/hdfs/*:/usr/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/usr/hadoop-3.2.2/share/hadoop/mapreduce/*:/usr/hadoop-3.2.2/share/hadoop/yarn:/usr/hadoop-3.2.2/share/hadoop/yarn/lib/*:/usr/hadoop-3.2.2/share/hadoop/yarn/*</value>
</property>
修改workers文件
vi /usr/hadoop-3.2.2/etc/hadoop/workers
启动hadoop有报错没有java_home就修改
指定自己的位置
配置hadoop环境变量
vi /etc/profile
export HADOOP_HOME=/usr/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin
生效
source /etc/profile
启动hadoop
cd /usr/hadoop-3.2.2/sbin/
./hadoop-daemon.sh start journalnode
拷贝命令
scp -r /usr/hadoop-3.2.2/ he2:/usr/
启动集群
cd /usr/hadoop-3.2.2/sbin/
拷贝整个文件夹
scp -r 文件目录/* hostB:存放目录
scp -r hadoop-3.2.2 he2:/usr/
安装jdk步骤
先下载jdk的tar压缩包
然后解压jdk并压缩至指定安装目录,如果不需要指定安装目录直接写tar -zxvf jdk压缩包名即可
tar -zxvf jdk压缩包 -C /这里写指定安装目录
配置环境变量
vi etc/profile
在环境变量中写入自己jdk安装目录,JAVA_HOME后面写自己jdk的安装目录
export JAVA_HOME=/usr/jdk1.8.0_301
export PATH=$PATH:$JAVA_HOME/bin
然后esc shift+: wq保存退出
刷新一下配置信息
source /etc/profile
再看看jdk是否安装成功
java -version
有结果就表示安装成功
查看日志
cd /usr/hadoop-3.2.2/
cd logs/
cat hadoop-root-journalnode-he3.log
标签:yarn,server1,dfs,hadoop,3.2,usr,安装 来源: https://www.cnblogs.com/hejingzi/p/15347180.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。