标签:XML xml 元素 Element 简述 import DTD
XML
XML简介
- xml:
eXtensible Markup Language,可扩展标记语言,是一种标记语言。 - xml是一种非常灵活的语言,没有固定的标签,所有的标签都可以自定义。
- 通常,xml可被用于信息的记录和传递。(xml就是一个普通的文本文件,跟我们平常用的
txt很像,具有很方便的传递性)。因此,xml经常被用于充当配置文件。 - XML编辑器:
- 记事本
- Dreamweaver
- XML.Spy
- xml默认打开方式:浏览器。(浏览器可以识别XML)
格式良好的XML
--————————————————————————————————————————来自菜鸟
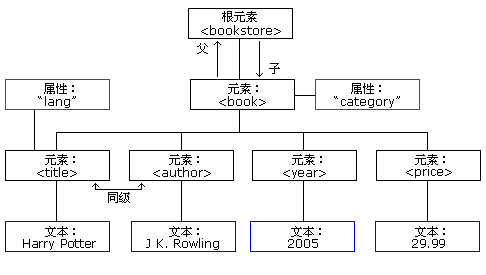
XML 文档形成一种树结构
XML 文档必须包含根元素。该元素是所有其他元素的父元素。
XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。
所有的元素都可以有子元素:
<root> <child> <subchild> ..... </subchild> </child> </root>父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞(兄弟或姐妹)。
所有的元素都可以有文本内容和属性(类似 HTML 中)。
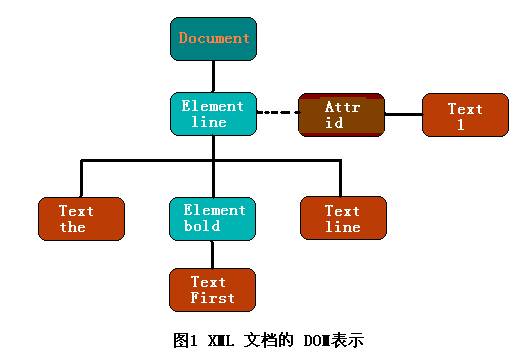
XML将数据组织成为一棵树,DOM 通过解析 XML 文档,为 XML 文档在逻辑上建立一个树模型,树的节点是一个个的对象。这样通过操作这棵树和这些对象就可以完成对 XML 文档的操作,为处理文档的所有方面提供了一个完美的概念性框架。
如下XML文档:
<line id="1"> the <bold>First</bold>line</line>
由于DOM“一切都是节点(everything-is-a-node)”,XML树的每个 Document、Element、Text 、Attr和Comment都是 DOM Node。
由上面例子可知, DOM 实质上是一些节点的集合。由于文档中可能包含有不同类型的信息,所以定义了几种不同类型的节点,如:Document、Element、Text、Attr 、CDATASection、ProcessingInstruction、Notation 、EntityReference、Entity、DocumentType、DocumentFragment等。
- 声明信息,用于描述XML的版本和编码方式
<?xml version="1.0" encoding="UTF-8"?>//XML 声明-定义XML版本和编码方式
<??> 版本号 编码方式
- xml有且仅有一个根元素(根元素可以理解成顶级元素)(元素:由开始标签,元素内容和结束标签组成)
- 所以不能有两个同级元素作为最高级元素
- xml是大小写敏感的
<a></a> 对 <----> <a></A> 错
- 标签元素是成对的,而且要正确嵌套。
<a>
<aa>
</aa>
</a>
- 属性值要使用双引号
<a id="abcaca">
<aa>
</aa>
</a>
- 注释的写法
<!-- 这里是注释 -->
- 例子
<?xml version="1.0" encoding="UTF-8"?>
<!-- 这里是注释 -->
<books> <!-- 最高级元素,根元素 不能有跟最高级元素同级别的元素,规定根元素只能有一个-->
<book id="b01">
<name>java高级编程</name>
<author>张三</author>
<price>50.5</price>
</book>
<book id="b02">
<name>java高级编程</name>
<author>李四</author>
<price>30.5</price>
</book>
<!-- 理论上可以写中文 但是尽量不写 -->
<书>
<作者>shc</作者>
</书>
</books>
- 练习
<?xml version="1.0" encoding="UTF-8"?>
<scores>
<student id="1">
<name>王同</name>
<subject>Java</subject>
<score>98</score>
</student>
<student id="2">
<name>梧桐</name>
<subject>SQL</subject>
<score>56</score>
</student>
</scores>
DTD
DTD简介
- DTD:Document Type Definition,文档定义类型。
- DTD用于约束XML的文档格式,保证xml是一个有效的xml
- DTD可以分为两种:内部DTD,外部DTD。
使用DTD
内部DTD的定义
<!DOCTYPE 根元素 [元素声明]>
- 元素声明语法
<!ELEMENT 元素名 (子元素[,子元素...])>
-
数量词
- +:表示出现1次或多次,至少一次
- ?: 表示出现0次或1次
- *:表示出现任意次
-
属性(attlist)声明语法:
- 属性类型:CDATA,表示字符数据(character data)
- 默认值:
#REQUIRED,表示必须出现#IMPLIED,表示不是必须的
<!ATDLIST 元素名称 属性名称 属性类型 默认值>
- 带DTD的完整XML代码
<?xml version="1.0" encoding="UTF-8"?>
<!-- 声明内部DTD -->
<!DOCTYPE scores [
<!ELEMENT scores (student+) >
<!ELEMENT student (name,score)> 注意student和()之间必须有空格
<!ATTLIST student id CDATA #REQUIRED> 声明这个属性必须存在
<!ELEMENT name (#PCDATA)>
<!ELEMENT score (#PCDATA)> score标签之间不能再有标签
]>
<!-- PCDATA是指两个标签之间的文档 -->
注意根元素下各个子元素的顺序也必须跟声明的一致
<scores>
<student id="1">
<name>shc</name>
<score>25</score>
</student>
</scores>
外部DTD的定义
- 创建一个独立的DTD文件:scoress.dtd
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT scoress (student+)>
<!ELEMENT student (name,score,subject)>
<!ATTLIST student id CDATA #REQUIRED>
<!ELEMENT name (#PCDATA)>
<!ELEMENT score (#PCDATA)>
<!ELEMENT subject (#PCDATA)>
- 在xml中引入外部DTD文件:scoress.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- 引入外部DTD文件 -->
<!DOCTYPE scoress SYSTEM "scoress.dtd">
<scoress>
<student id="1">
<name>ss</name>
<score>25</score>
<subject>english</subject>
</student>
<student id="3">
<name>mm</name>
<score>25</score>
<subject>math</subject>
</student>
</scoress>
XML的解析
在对xml文件进行解析时,包括创建xml,对xml文件进行增删改查等操作
常见的xml解析技术
DOM解析
- 是官方提供的解析方式,基于XML树解析,消耗资源大,适用于多次访问XML
SAX解析
- 是民间的解析方式,基于事件的解析,消耗资源小,适用于数据量较大的XML
JDOM解析
- 第三方提供,开源免费的解析方式,比DOM解析快
DOM4J解析
- 4->four->for
- 解析xml的入口,是需要先拿到一个Document对象
- 范例:读取scoress.xml
- 建包,建普通java类
package com.shc.xml;
import java.io.File;
import java.util.Iterator;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/*
* 从XML中读取信息
* 使用dom4j解析XML
* ①获取Document对象
* ②通过Document对象获取根元素,然后就是对根元素下的属性和对象及进行迭代
*/
public class TestXml {
public static void main(String[] args) throws DocumentException {
//1. 创建SAXReader对象,用于读取xml文件
SAXReader reader = new SAXReader();
//2. 读取XML文件,得到Document对象
Document doc = reader.read(new File("src/scoress.xml"));
// System.out.println(doc);//打印路径?
//3. 获取根元素
Element root = doc.getRootElement();
System.out.println(root.getName());
System.out.println("**********************");
//4. 获取根元素下所有子元素 通过迭代器遍历 要写泛型
//elementIterator 返回的是Object类型的对象 实际上是元素
//那么我们的泛型如果写Element就会警告,但是是对的
//如何消除警告: 泛型写'?' 这样就以Object来接收每个对象
//但是这样之后在使用时,就需要先把对象强为Element
Iterator<?> elementIterator = root.elementIterator();
while(elementIterator.hasNext()) {
//取出元素 通过根元素score的迭代得到所有student
Element e = (Element) elementIterator.next();
System.out.println(e.getName());
//获取每个student的ID属性
// e.attributeIterator();//追忆一个元素 不必使用迭代器
Attribute id = e.attribute("id");// 通过属性名字获取属性内容
System.out.println(id.getName()+"="+id.getValue());
//获取student的子元素
Element name = e.element("name");
Element subject = e.element("subject");
Element score = e.element("score");
System.out.println(name.getName()+"="+name.getStringValue());
System.out.println(subject.getName()+"="+subject.getText());//因为我闷在两个标签之间写的实际上就是文本,所可以用getText()
System.out.println("******************");
}
}
}
scoress
**********************
student
id=1
name=ss
subject=english
******************
student
id=3
name=mm
subject=math
******************
DOM4J创建XML
package com.shc.xml;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class CreateXml {
private static Writer writer = null;
public static void main(String[] args) throws IOException {
//[1] 通过DocumenHelper生成一个Document对象
Document doc = DocumentHelper.createDocument();//方法返回document对象
//[2] 添加并得到根元素
Element root = doc.addElement("books");//方法返回根元素对象
//[3] 为根元素添加子元素
Element book = root.addElement("book");//方法返回添加到根元素下的元素对象
//[4] 为book添加元素属性
book.addAttribute("id", "b01");//方法返回被添加属性的元素
//这些方法返回的都是元素 是为了方便链式编程 链式编程缺电:可读性差 优点:高大上
// doc.addElement("books").addElement("book").addAttribute("id","b01");
//[5] 为book添加子元素
Element name = book.addElement("name");
Element author = book.addElement("author");
Element price = book.addElement("price");
//[6]为子元素添加文本
name.addText("Thinking in Java");
author.addText("小伟");
price.addText("88");
// //[7] 将doc输出到xml文件中即可用
// try {
// writer = new FileWriter(new File("src/book.xml"));
// doc.write(writer);
// } catch (IOException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// } finally {
// //[8] 关闭资源
// try {
// writer.close();
// } catch (IOException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// }
// }
//[7] 格式良好的输出
OutputFormat format = OutputFormat.createPrettyPrint();
XMLWriter writer = new XMLWriter(new FileWriter(new File("src/book2.xml")),format);
writer.write(doc);
//[8] 关闭资源
writer.close();
}
}
<?xml version="1.0" encoding="UTF-8"?>
<books><book id="b01"><name>Thinking in Java</name><author>小伟</author><price>88</price></book></books>
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="b01">
<name>Thinking in Java</name>
<author>小伟</author>
<price>88</price>
</book>
</books>
常识
- 创建XML文件步骤
- File -- Java Project --- src ---new File/XMLf File --- xxx.xml
标签:XML,xml,元素,Element,简述,import,DTD 来源: https://www.cnblogs.com/4-Prestar/p/14777993.html
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。