标签:False verbose 训练 stacking 模型 分类器 大杀器
一套弱系统能变成一个强系统吗?

当你处在一个复杂的分类问题面前时,金融市场通常会出现这种情况,在搜索解决方案时可能会出现不同的方法。 虽然这些方法可以估计分类,但有时候它们都不比其他分类好。 在这种情况下,合理的选择是将它们全部保留下来,然后通过整合这些部分来创建最终系统。 这种多样化的方法是最方便的做法之一:在几个系统之间划分决定,以避免把所有的鸡蛋放在一个篮子里。
一旦我对这种情况有了大量的估计,我怎样才能将N个子系统的决策结合起来? 作为一个快速的答案,我可以做出平均决定并使用它。 但是,是否有不同的方式充分利用我的子系统? 当然有!
创造性思考!
几个具有共同目标的分类器称为多分类器。 在机器学习中,多分类器是一组不同的分类器,它们进行估算并融合在一起,得到一个结合它们的结果。 许多术语用于指多分类器:多模型,多分类器系统,组合分类器,决策委员会等。它们可以分为两大类:
集成方法:指使用相同的学习技术组合成一组系统来创建新系统。 套袋和提升是最延伸的。
混合方法:采用一组不同的学习者并使用新的学习技术进行组合。 堆叠(或堆叠泛化)是主要的混合多分类器之一。
如何构建一个由 Stacking 驱动的多分类器。
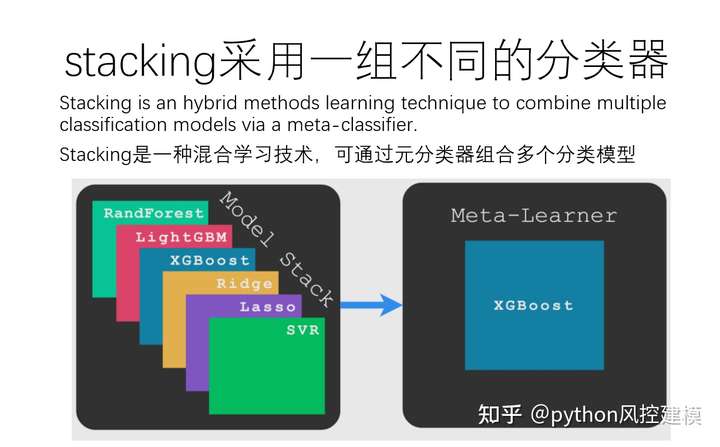
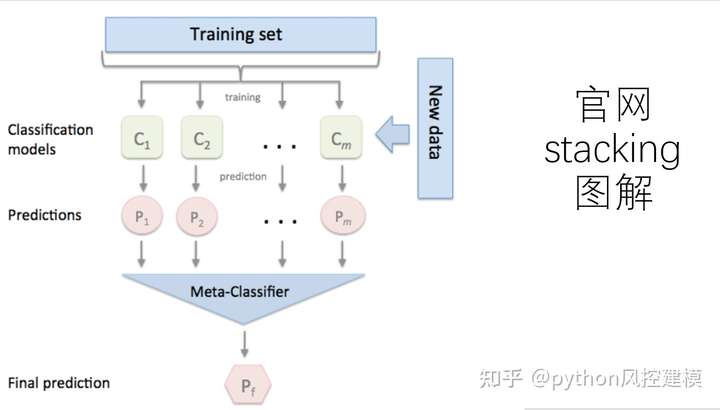
stacking工作流
.
元分类器可以在预测的类标签上训练,也可以在预测的类概率训练。
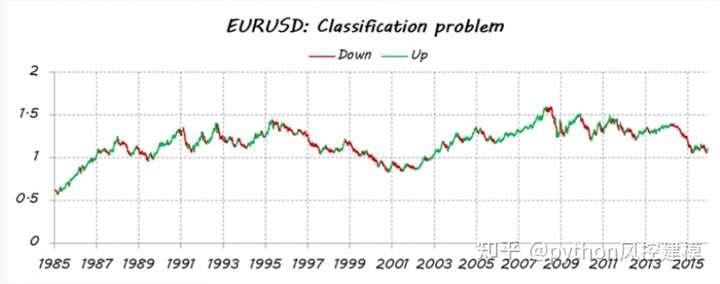
举个stacking预测欧元兑美元趋势例子
想象一下,我想估算一下EURUSD的走势(欧元兑美元趋势)。首先,我把我的问题变成了一个分类问题,所以我把价格数据分成两种类型(或类):向上和向下移动。猜测每天的每一个动作并不是我的本意。我只想检测主要趋势:向上交易多头(类 = 1)和向下交易空头(类 = 0)。
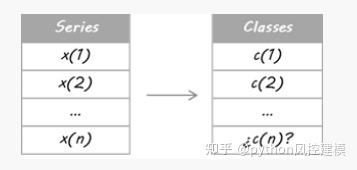
我已经完成了后验分割;我的意思是所有历史数据都被用来决定类别,所以它考虑了一些未来的信息。因此,我目前无法确保 iup 或 down 运动。因此,需要对今天的课程进行估算。
为了这个例子的目的,我设计了三个独立的系统。他们是三个不同的学习者,使用不同的属性集。无论您使用相同的学习器算法还是它们共享某些/所有属性都没有关系;关键是它们必须足够不同以保证多样化。
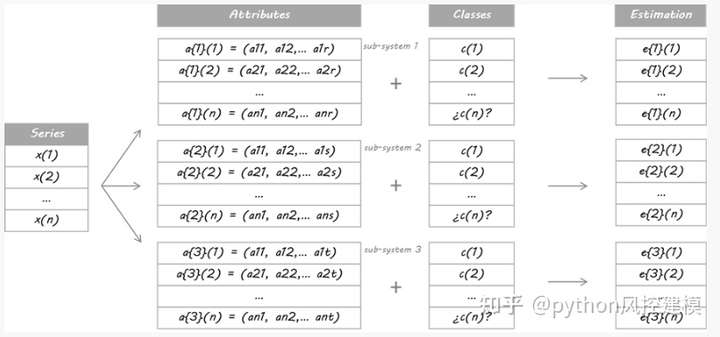
然后,他们根据这些概率进行交易:如果 E 高于 50%,则意味着做多,E 越大。 如果 E 低于 50%,则为空头入场,E 越小。
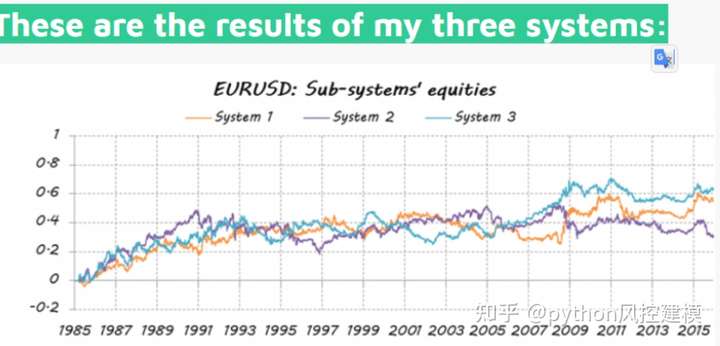
结果不理想,仅仅比随机好
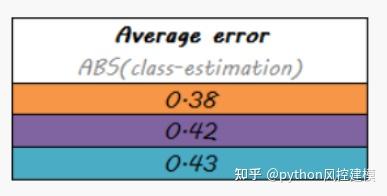
系统误差相关性也较低
一组较弱选手可以组成梦之队吗?
构建多分类器的目的是获得比任何单个分类器都能获得的更好的预测性能。让我们看看是否是这种情况。
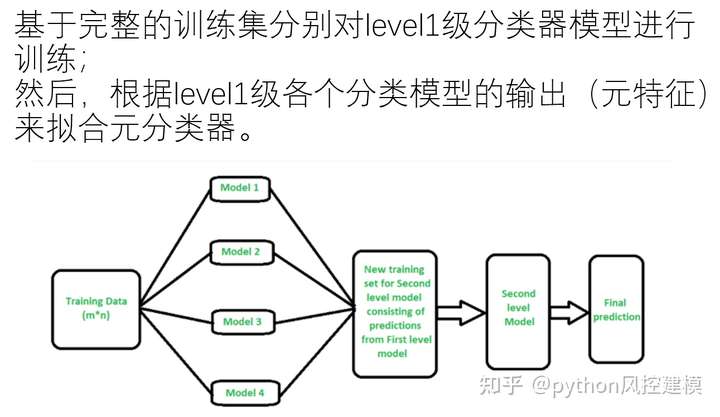
我将在本例中使用的方法基于Stacking算法。 Stacking的思想是,称为级别0模型的主分类器的输出将被用作称为元模型的另一分类器的属性以近似相同的分类问题。元模型留下来找出合并机制。它将负责连接0级模型的回复和真实分类。
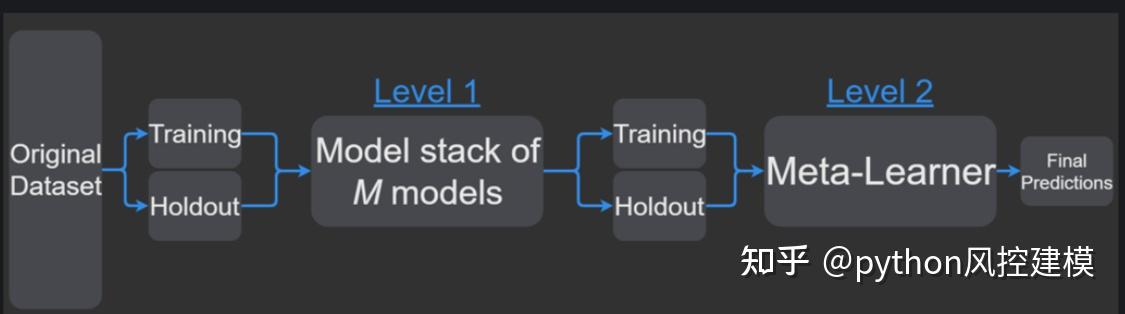
严格的过程包括将训练集分成不相交的集合。然后训练每个级别0的学习者关于整个数据,排除一组,并将其应用于排除组。通过对每组重复,为每个学习者获得每个数据的估计。这些估计值将成为训练元模型或1级模型的属性。由于我的数据是一个时间序列,因此我决定使用第1天到第d-1天的集合来构建第d天的估计。
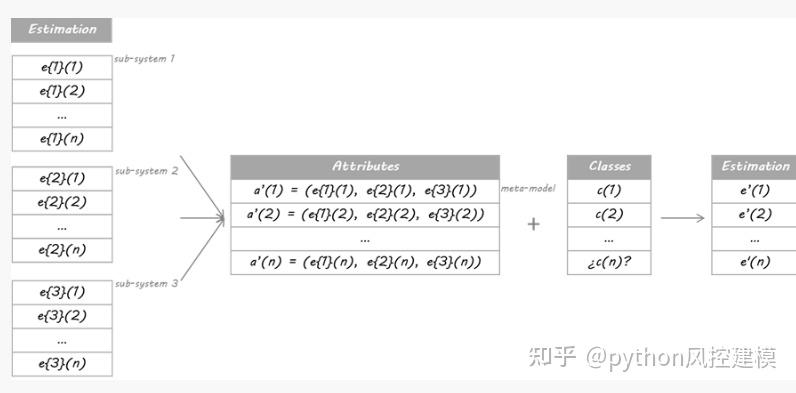
这与哪种模式配合使用?
元模型可以是分类树,随机森林,支持向量机......任何分类学习者都是有效的。 对于这个例子,我选择了使用最近邻居算法。 这意味着元模型将估计新数据的类别,以发现过去数据中0级分类的类似配置,然后将分配这些类似情况的类别。
让我们看看我的梦之队的成绩是多么的好......
stacking模型的平均误差值是最低的
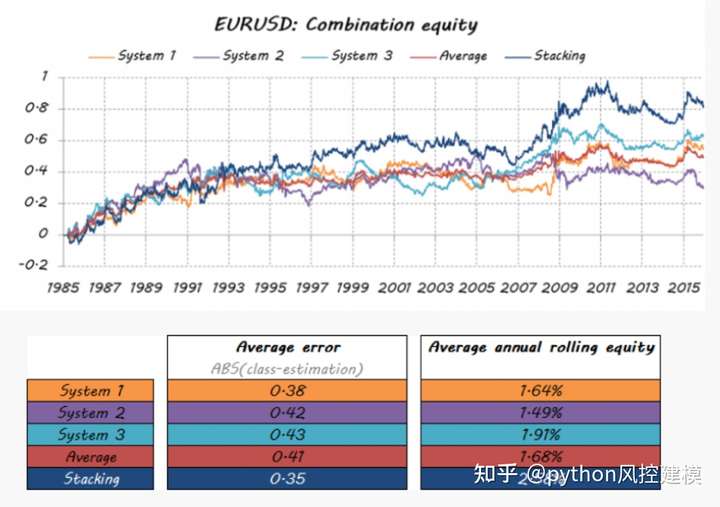
结论
这只是大量可用多分类器的一个例子。 他们不仅可以帮助您通过现代和独创的技术将您的部分解决方案融入到独特的答案中,而且可以创建一个真正的梦幻团队。 单个组件被融合到一个系统中的方式也有一个重要的改进余地。
所以,下次你需要结合时,花更多的时间来研究可能性。 通过习惯的力量避免传统的平均水平,并探索更复杂的方法。 他们可能会为你带来额外的表现
模型融合在kaggle竞赛应用
模型融合是一种非常强大的技术,可以提高各种 ML 任务的准确性。在本文中,我将分享我在 Kaggle 比赛中的集成方法。
对于第一部分,我们着眼于从提交文件创建集成。第二部分将着眼于通过堆叠泛化/混合创建集成。
我回答为什么集成会减少泛化错误。最后,我展示了不同的集成方法,以及它们的结果和代码,供您自己尝试。Kaggle Ensembling Guide我回答为什么集成会减少泛化错误。最后,我展示了不同的集成方法,以及它们的结果和代码,供您自己尝试。
stacked 产生方法是一种截然不同的组合多个模型的方法,它讲的是组合学习器的概念,但是使用的相对于bagging和boosting较少,它不像bagging和boosting,而是组合不同的模型,具体的过程如下:
1.划分训练数据集为两个不相交的集合。
2. 在第一个集合上训练多个学习器。
3. 在第二个集合上测试这几个学习器
4. 把第三步得到的预测结果作为输入,把正确的回应作为输出,训练一个高层学习器,
这里需要注意的是1-3步的效果与cross-validation,我们不是用赢家通吃,而是使用非线性组合学习器的方法
将训练好的所有基模型对整个训练集进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
下面我们介绍一款功能强大的stacking利器,mlxtend库,它可以很快地完成对sklearn模型地stacking。
StackingClassifier 使用API及参数解析:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
参数:
classifiers : 基分类器,数组形式,[cl1, cl2, cl3]. 每个基分类器的属性被存储在类属性 self.clfs_.
meta_classifier : 目标分类器,即将前面分类器合起来的分类器
use_probas : bool (default: False) ,如果设置为True, 那么目标分类器的输入就是前面分类输出的类别概率值而不是类别标签
average_probas : bool (default: False),用来设置上一个参数当使用概率值输出的时候是否使用平均值。
verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。
属性:
clfs_ : 每个基分类器的属性,list, shape 为 [n_classifiers]。
meta_clf_ : 最终目标分类器的属性
方法:
fit(X, y)
fit_transform(X, y=None, fit_params)
get_params(deep=True),如果是使用sklearn的GridSearch方法,那么返回分类器的各项参数。
predict(X)
predict_proba(X)
score(X, y, sample_weight=None), 对于给定数据集和给定label,返回评价accuracy
set_params(params),设置分类器的参数,params的设置方法和sklearn的格式一样
python融合模型部分实战代码
from sklearn.datasets import load_iris
from mlxtend.classifier import StackingClassifier
from mlxtend.feature_selection import ColumnSelector
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
iris = load_iris()
X = iris.data
y = iris.target
pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)),
LogisticRegression())
pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)),
LogisticRegression())
sclf = StackingClassifier(classifiers=[pipe1, pipe2],
meta_classifier=LogisticRegression())
sclf.fit(X, y) 欢迎各位同学学习《python机器学习-乳腺癌细胞挖掘》课程,包含完整stacking融合模型知识:

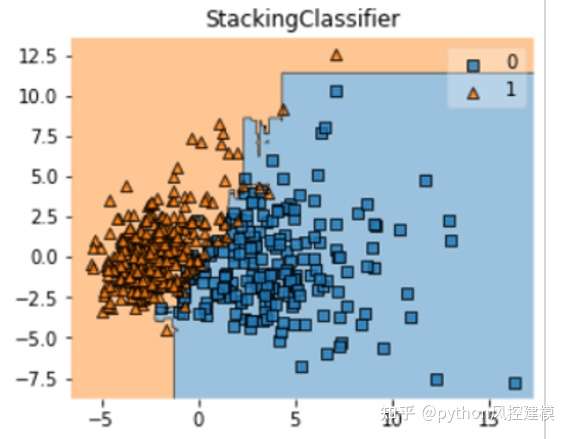
课程涉及融合模型python脚本截图

课程有绘制融合模型决策域知识讲解
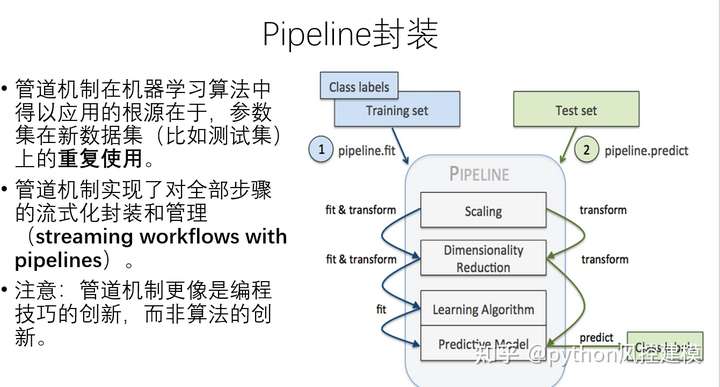
课程还讲述stacking融合模型和pipeline机器学习管道共同作业的python代码和实例讲解
标签:False,verbose,训练,stacking,模型,分类器,大杀器 来源: https://blog.51cto.com/u_15002417/2901749
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。