标签:qq Text blog 42341984 https SQL net
Text-to-SQL
1 Single table(WikiSQL)
1.1 Encode
1.1.1 NL和DB的交互(对齐)
-
预训练的方法
-
STRUG:https://blog.csdn.net/qq_42341984/article/details/115615653
-
TaBert:学习自然语言描述和数据库的(半)结构化信息的联合表示 https://www.sohu.com/a/413894298_657157
-
GRAPPA:ICLR 2021
在文本数据和表数据的联合表示中学习组合归纳偏见。
数据扩增:通过同步上下文无关语法(SCFG)在高质量的表上构造合成的Question-SQL对。
预训练:在合成数据上对模型进行预训练,将语义分析中常见的重要结构特性注入预训练的语言模型中。
-
两个预训练目标:
-
掩模语言建模(MLM): conduct masking for both natural language sentence and table headers
-
SQL语义预测(SSP):添加一个辅助任务来训练列表示。即给定一个自然语言语句和表头,预测SQL查询中是否出现一列,以及触发什么操作。然后将所有SQL序列标签转换为每个列的操作分类标签。例如,在图1中,列位置的操作分类标签是SELECT和GROUP BY HAVING。对于出现在嵌套查询中的列,我们在每个操作之前附加相应的嵌套关键字。例如,因为列nation在INTERSECT嵌套子查询中,所以它的标签是INTERSECT SELECT和INTERSECT GROUP BY。对于每个额外的表名,我们只预测它是否被选中,以便在FROM子句中构造可能的连接。在我们的实验中,总共有254个可供操作的类。
-
-
-
-
模糊匹配的方法
代表工作:BRIDGE
https://blog.csdn.net/qq_42341984/article/details/113059271
-
Schema Linking
代表工作:RATSQL
https://zhuanlan.zhihu.com/p/143400912
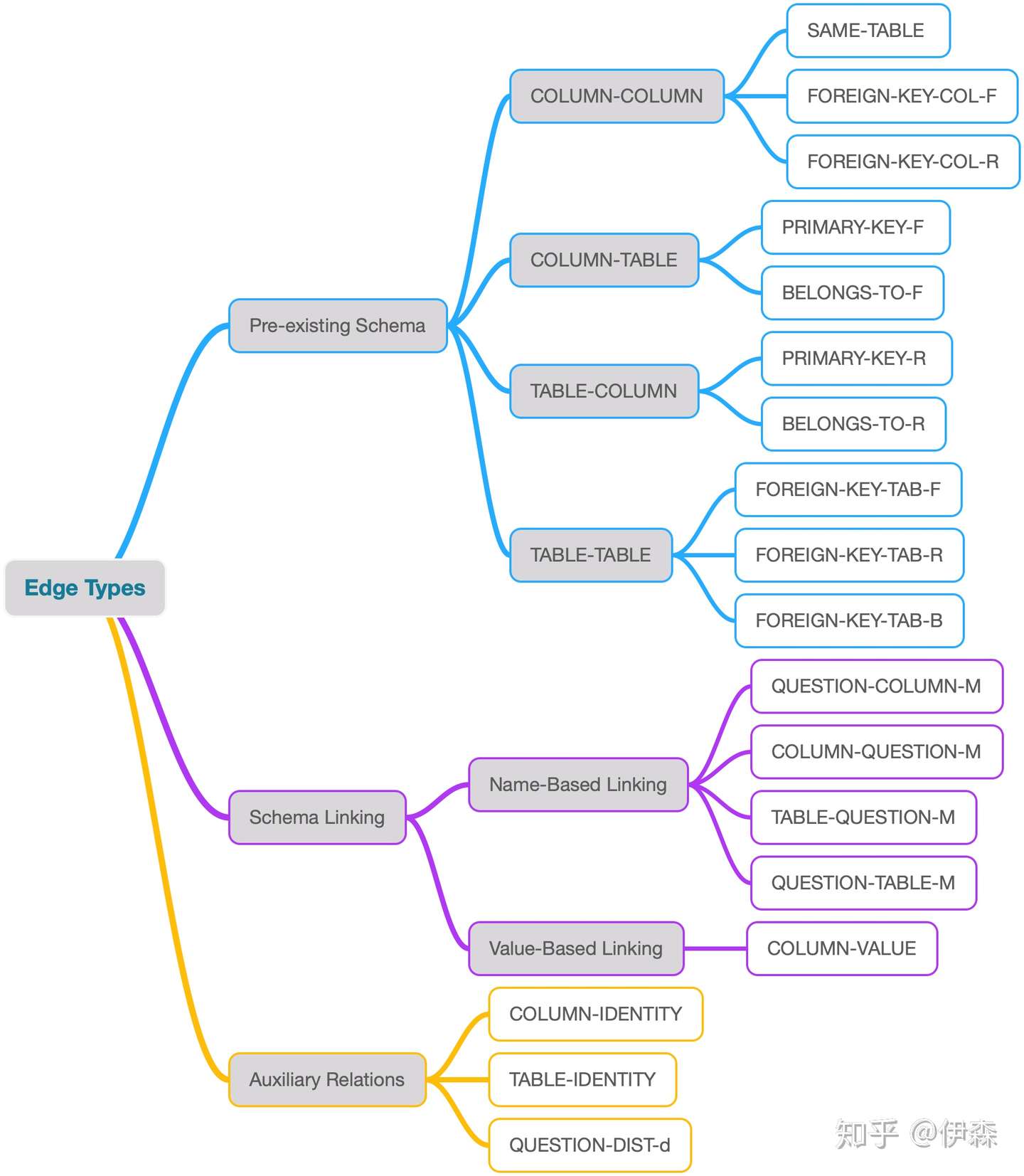
1.1.2 增强Schema表示
-
图神经网络的方法
-
利用 bert 风格的预训练模型(MT-DNN)的上下文输出来增强结构模式表示(schema representation),并结合类型信息(type information) 来学习用于下游任务的新模式表示。
1.2 Decode
1.2.1 generation-based(
标签:qq,Text,blog,42341984,https,SQL,net 来源: https://blog.csdn.net/qq_42341984/article/details/115842255
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。