不要被误导
设计和实现可扩展的图形数据库系统从来都不是一项简单的任务。有无数的企业,尤其是互联网巨头,已经探索了使图形数据处理可扩展的方法。尽管如此,大多数解决方案要么仅限于其私有和狭窄的用例,要么通过硬件加速以垂直方式提供可扩展性,这再次证明大型机架构计算机在 90 年代被 PC 架构计算机确定性取代的原因主要是与水平可扩展性相比,垂直可扩展性通常被认为是劣质的且可扩展性较差。分布式数据库通过添加廉价PC来实现可扩展性(存储和计算),并试图按需一劳永逸地存储数据,这已成为一种常态。但是,如果不大量牺牲图形系统上的查询性能,这样做就无法实现同等的可扩展性。
为什么图形(数据库)系统的可扩展性如此难以(获得)?主要原因是图系统是高维的;这与传统的 SQL 或 NoSQL 系统形成鲜明对比,传统的 SQL 或 NoSQL 系统主要以表为中心,本质上是列式和行式存储(以及更简单的 KV 存储),并且已被证明通过水平可扩展设计相对容易实现。
一个看似简单直观的图查询可能会导致大量图数据的深度遍历和渗透,否则往往会导致典型的BSP(Bulky Synchronous Processing)系统在其众多分布式实例之间进行大量交换,从而导致重大(和难以忍受的)延迟。
另一方面,大多数现有的图形系统更愿意在提供可扩展性(存储)的同时牺牲性能(计算)。这将使此类系统在处理许多现实世界的业务场景时变得不切实际和无用。描述此类系统的更准确的方法是,它们可能可以存储大量数据(跨越许多实例),但不能提供足够的图形计算能力——换句话说,这些系统在被超出范围的查询时无法返回结果元数据(节点和边)。
本文旨在揭开图形数据库的可扩展性挑战的神秘面纱,同时重点关注性能问题。简而言之,您将对任何图形数据库系统的可伸缩性和性能有更好、更通畅的理解,并在选择您未来的图形系统时更有信心。
市场上有很多关于图数据库可扩展性的声音;一些供应商声称他们具有无限的可扩展性,而其他供应商则声称他们是第一个企业级可扩展图形数据库。你应该相信或跟随谁?唯一的出路是让自己对图形数据库系统的可扩展性有足够的了解,这样你就可以自己验证它,而不必被所有那些营销炒作所误导。
诚然,图数据库可扩展性有很多术语;有些可能非常令人困惑,仅举几例:HA、RAFT 或分布式共识、HTAP、联合、结构、分片、分区等。
你真的能分辨出所有这些术语的区别吗?我们会解开它们。
3 分布式图系统架构设计流派
首先,确保您了解从独立(图形数据库)实例到完全分布式且可水平扩展的图形数据库实例集群的演进路径。
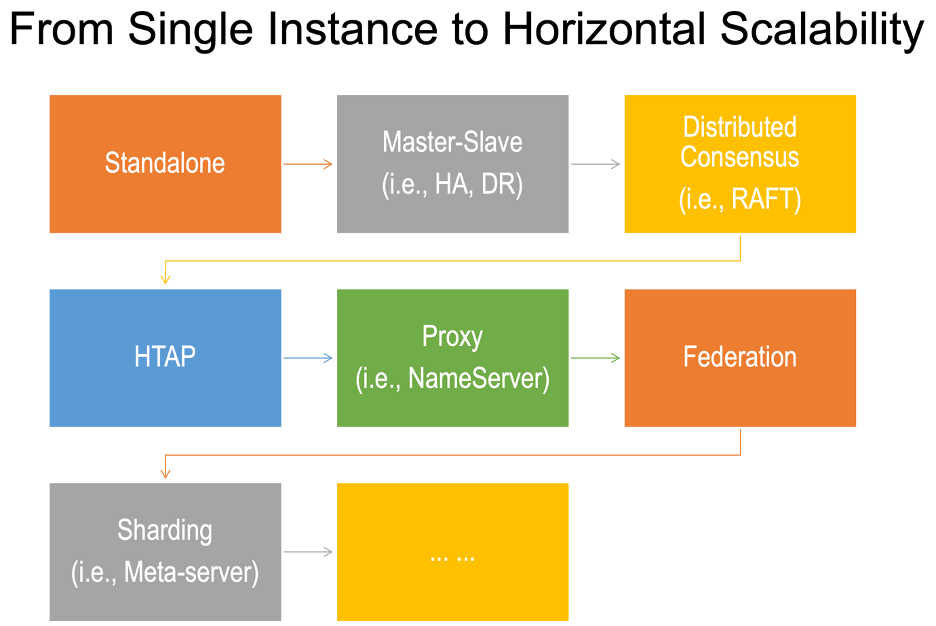
分布式系统可能有多种形式,这种丰富的多样化可能会导致混乱。一些供应商误导性地(讽刺地)声称他们的数据库系统均匀分布在单个基础硬件实例上,而其他供应商则声称他们的分片图形数据库集群可以处理数以万计的图形数据集,而实际上,集群不能甚至可以处理反复遍历整个数据集的典型多跳图查询或图算法。
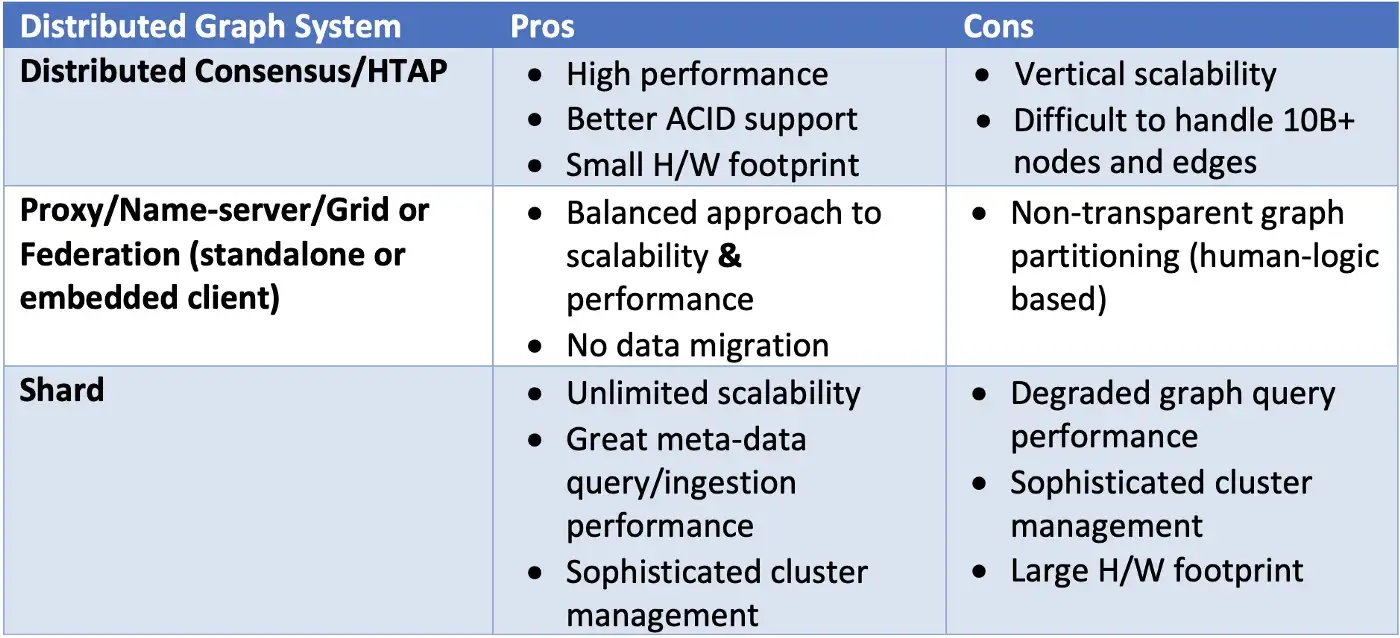
简而言之,只有三种可扩展图形数据库架构设计流派,如表所示:
多环芳烃架构
第一种学派被认为是主从模型的自然扩展,我们称之为分布式共识集群,通常三个实例组成一个图数据库集群。在同一集群中拥有三个或奇数个实例的唯一原因是更容易投票选出集群的领导者。
如您所见,这种集群设计模型可能有很多变化;例如,Neo4j 的企业版 v4.x 支持原始的 RAFT 协议,只有一个实例处理工作负载,而其他两个实例被动地从主实例同步数据——当然,这是让 RAFT 协议工作的一种天真方式. 一种更实用的处理工作负载的方法是扩充 RAFT 协议以允许所有实例以负载均衡的方式工作。例如,让领导实例处理读写操作,而其他实例至少可以处理读取类型的查询,以确保整个集群的数据一致性。
在这种分布式图形系统设计中,一种更复杂的方法是允许 HTAP(混合事务和分析处理),这意味着将在集群实例之间分配不同的角色;领导者将处理 TP 操作,而追随者将处理 AP 操作,这些操作可以进一步细分为图算法等角色。
利用分布式共识的图系统的优缺点包括:
- 硬件占用空间小(更便宜)。
- 数据一致性好(更容易实现)。
- 复杂和深度查询的最佳性能。
- 可扩展性有限(依赖垂直可扩展性)。
- 难以处理超过一百亿个节点和边的单个图。
下面展示的是来自 Ultipa 的新型 HTAP 架构,其主要功能如下:
- 高密度并行图计算。
- 多层存储加速(存储与计算非常接近)。
- 动态修剪(通过动态修剪机制加速图形遍历)。
- 超线性性能(即当CPU核数等计算资源增加一倍时,性能提升可达一倍以上)。
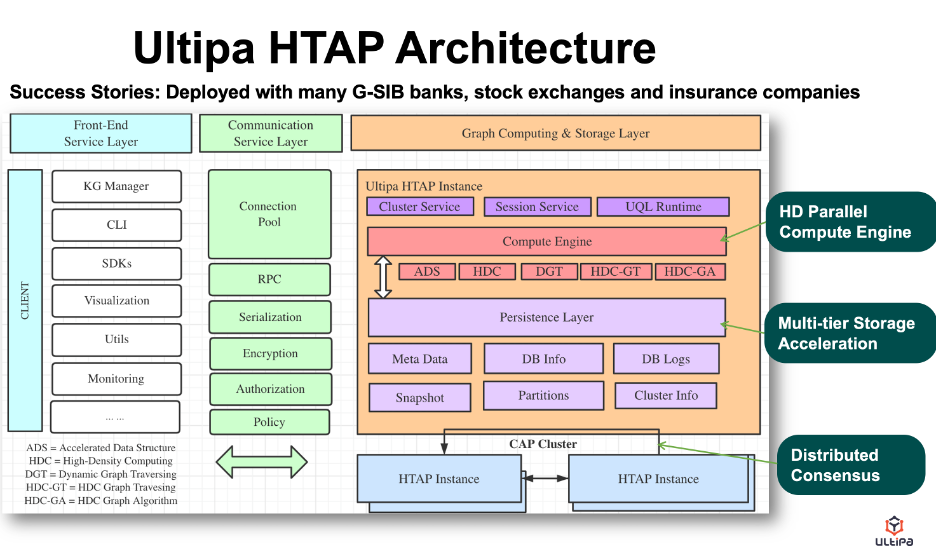
请注意,这种 HTAP 架构在小于 10B 节点 + 边的图形数据大小上运行良好。因为很多计算加速都是通过内存计算来完成的,如果每十亿个节点和边消耗大约100GB的DRAM,那么单个实例可能需要1TB的DRAM来处理一个百亿个节点和边的图。
这种设计的好处是该体系结构可以满足大多数真实场景的要求。即使对于 G-SIB(全球系统重要性银行),典型的欺诈检测、资产负债管理或流动性风险管理用例也会消耗大约 10 亿个数据;一个合理大小的虚拟机或 PC 服务器可以很好地容纳这样的数据规模,并且可以通过 HTAP 设置非常高效。
这种设计的缺点是缺乏水平(和无限)的可扩展性。而这一挑战在分布式图形系统设计的第二和第三流派中得到解决(见表 1)。
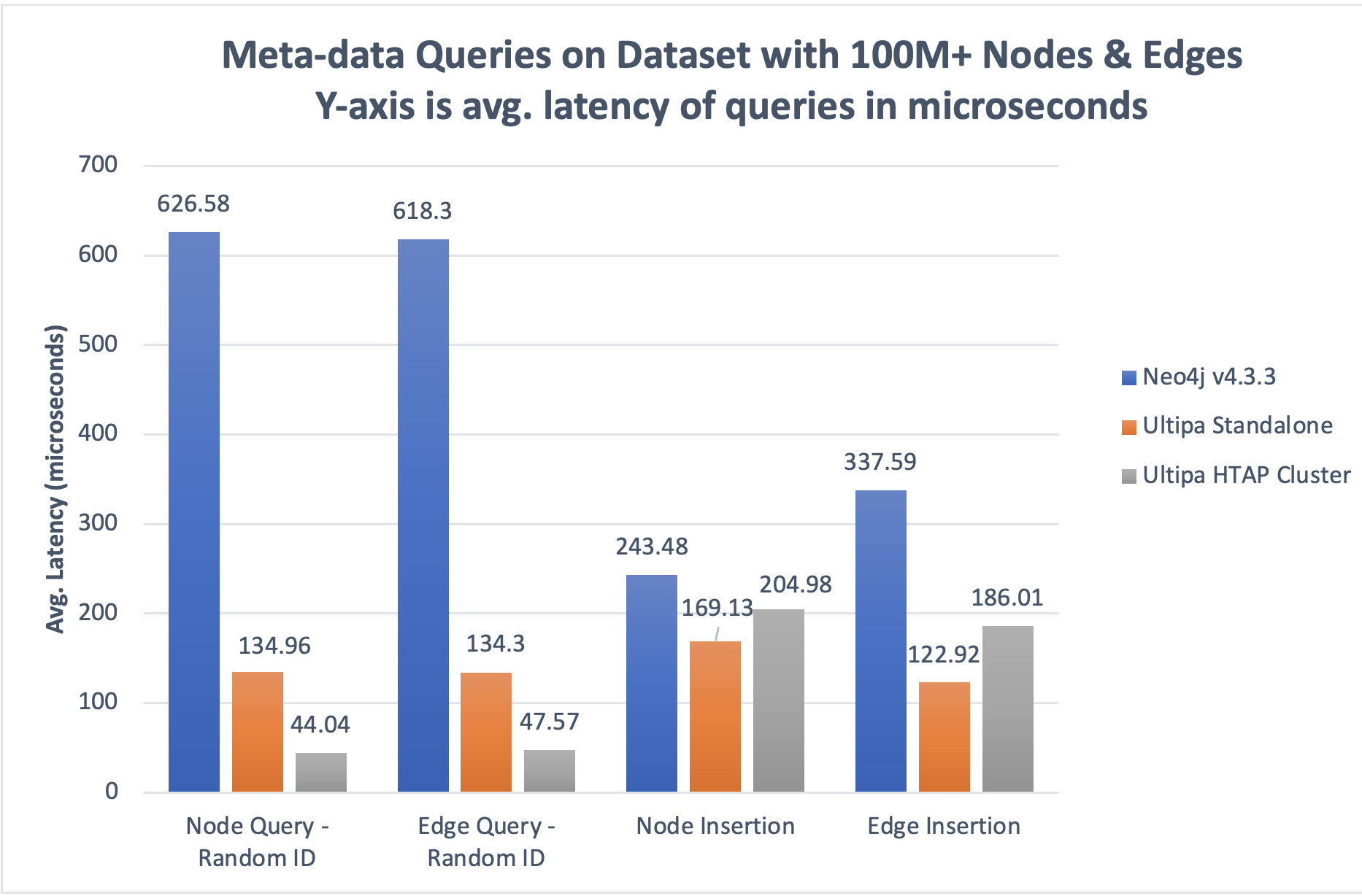
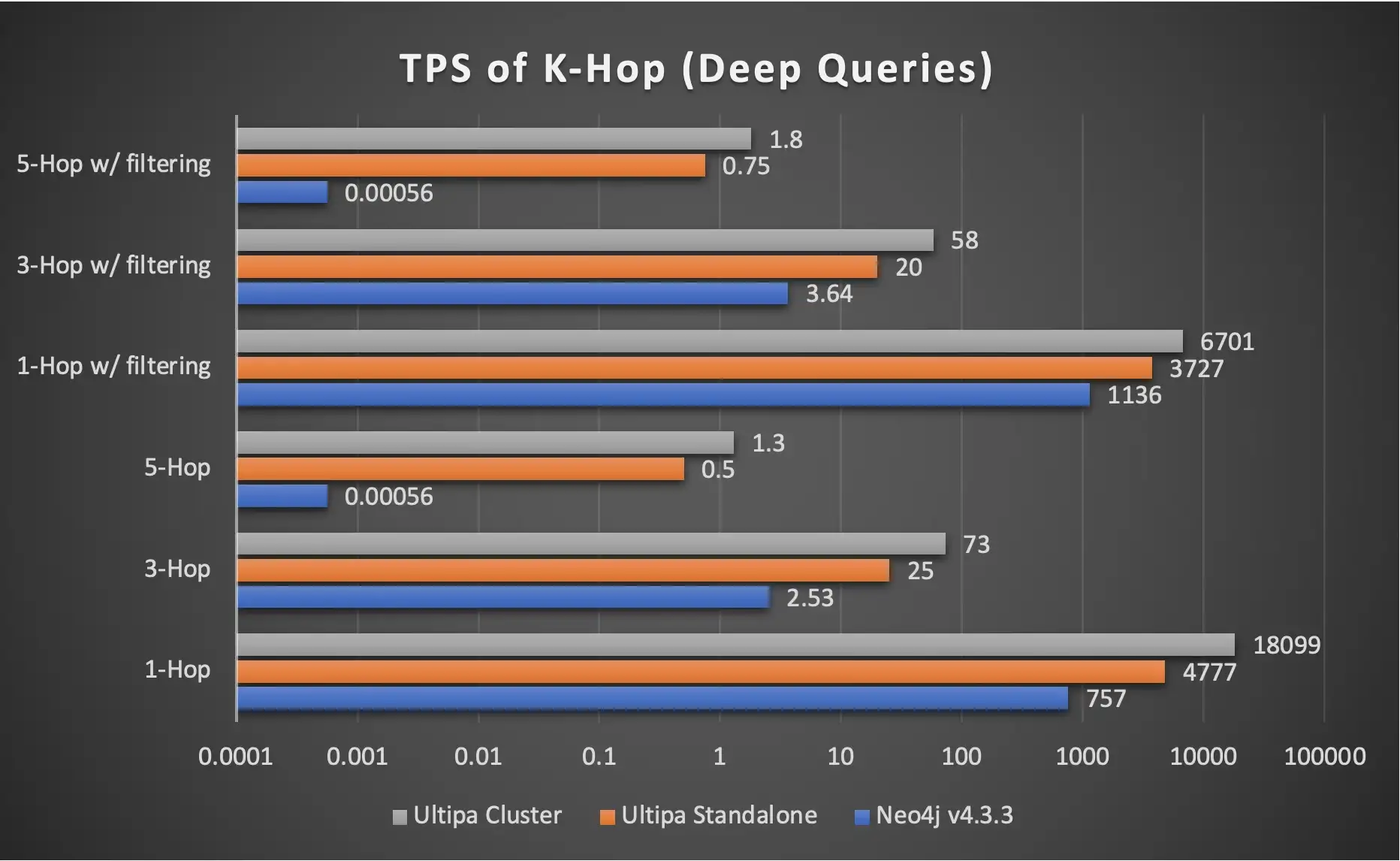
下面两张图展示了 HTAP 架构的性能优势。有两点需要注意:
- 线性性能增益:一个 3 实例 Ultipa HTAP 集群的吞吐量可以达到独立实例的 ~300%。增益主要反映在 AP 类型的操作中,例如元数据查询、路径/k-hop 查询和图形算法,但不反映在 TP 操作中,例如元数据的插入或删除,因为这些操作主要是在与辅助实例同步之前的主实例。
- 更好的性能 = 更低的延迟和更高的吞吐量(TPS 或 QPS)。
网格架构
在第二流派中,这种类型的分布式和可扩展图系统设计也有相当多的命名变体(有些是误导性的)。仅举几例:代理、名称服务器、MapReduce、网格或联合。忽略命名差异;中学和第一学校之间的主要区别在于名称服务器充当客户端和服务器端之间的代理。
作为代理服务器时,名称服务器仅用于路由查询和转发数据。最重要的是,除了运行图算法外,名称服务器还具有从基础实例聚合数据的能力。此外,在联合模式下,可以针对多个基础实例运行查询(查询联合);然而,对于图算法,联邦的性能很差(由于数据迁移,就像 map-reduce 的工作原理一样)。请注意,第二所学校与第三所学校在一个方面有所不同:数据在功能上进行了分区,但在该设计学校中并未分片。
对于图数据集,功能分区是图数据的逻辑划分,例如按时间序列(水平分区)或按业务逻辑(垂直分区)。
另一方面,分片旨在实现自动化,业务逻辑或时间序列无知。分片通常考虑基于网络存储的数据分区位置;它利用各种冗余数据和特殊的数据分布来提高性能,例如一方面对节点和边缘进行切割,另一方面复制部分切割数据以获得更好的访问性能。事实上,sharding 非常复杂且难以理解。根据定义,自动分片旨在以最小到零的人为干预和业务逻辑无知来处理不可预测的数据分布,但是当面临与特定数据分布纠缠在一起的业务挑战时,这种无知可能会带来很大问题。
让我们用具体的例子来说明这一点。假设您有 12 个月的信用卡交易数据。在人工分区模式下,您自然地将数据网络划分为 12 个图形集,一个图形集在每个包含三个实例的集群上包含一个月的事务,并且此逻辑由数据库管理员预定义。它强调通过数据库的元数据来划分数据,而忽略了不同图集之间的连接性。它对业务友好,不会减慢数据迁移速度,并且具有良好的查询性能。另一方面,在自动分片模式下,由图系统决定如何划分(切割)数据集,分片逻辑对数据库管理员是透明的。但是开发人员很难立即弄清楚数据存储在哪里,
仅仅因为自动分片涉及较少的人为干预就声称自动分片比功能分区更智能是不明智的。
你觉得这里有什么不对吗?随着人工智能的不断兴起,这正是我们正在经历的,我们允许机器代表我们做出决定,而且它并不总是智能的!(在另一篇文章中,我们将讨论从人工智能到增强智能的全球转变的主题,以及为什么图形技术在战略上定位于推动这种转变。)
在 Graph-5 中,展示了属于第二设计学院的网格架构;在 Graph-2 的 HTAP 架构之上添加的两个额外组件是名称服务器和元服务器。基本上所有的查询都是通过名称服务器代理的,名称服务器与元服务器共同工作以确保网格的弹性;服务器集群实例在很大程度上与原始 HTAP 实例相同(如图 2 所示)。

参考表1,网格架构设计的优缺点可以归纳如下:
- 保留了典型 HTAP 架构的所有优点/优点。
- 可扩展性是在性能不变的情况下实现的(与 HTAP 架构相比)。
- 可扩展性受限——服务器集群在 DBA/管理员干预下进行分区。
- 引入名称服务器/元服务器,使集群管理更加复杂。
- 名称服务器在确保业务逻辑在服务器集群上分布式执行并在返回给客户端之前在其上具有简单的合并和聚合功能方面至关重要且复杂。
- 可能需要业务逻辑配合分区和查询。
分片架构
现在,我们可以迎来具有无限可扩展性的分布式图系统设计的第三个流派——分片(shard)(见表1)。
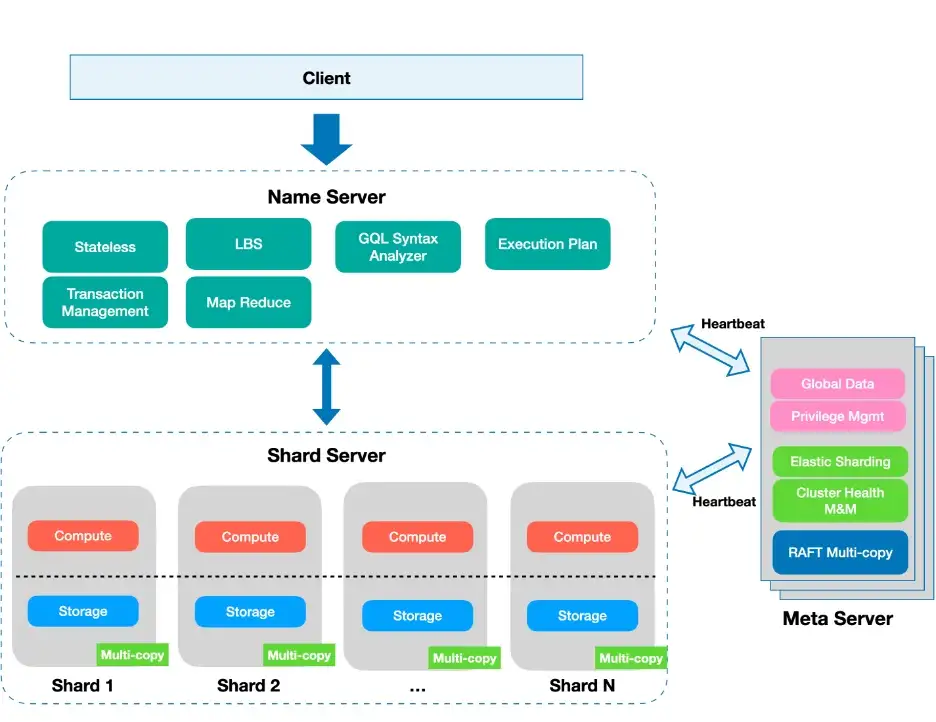
从表面上看,分片系统的水平可扩展性也像第二种设计一样利用名称服务器和元服务器,但主要区别在于:
- 分片服务器是真正共享的。
- 名称服务器不直接了解业务逻辑(如第二所学校)。间接地,它可以通过自动统计来粗略判断业务逻辑的类别。这个解耦很重要,在二流不可能优雅的实现。
分片架构有一些变化;有的叫fabric(其实更像中学的grid architecture),有的叫map-reduce,但还是要深入核心的数据处理逻辑来揭开谜底。
分片架构中只有两类数据处理逻辑:
- 类型 1:数据主要在名称服务器(或代理服务器)上处理
- 类型 2:数据在分片或分区服务器以及名称服务器上处理。
类型 1 是典型的,正如您在大多数 map-reduce 系统(例如 Hadoop)中看到的那样;数据分散在高度分布式的实例中。然而,在它们在那里被处理之前,它们需要被提升并转移到名称服务器。
类型 2 的不同之处在于,分片服务器有能力在数据被聚合并在名称服务器上进行二次处理之前在本地处理数据(这称为:在存储附近计算或与存储或以数据为中心的计算并置)。
正如您所想象的那样,类型1更容易实现,因为它是许多大数据框架的成熟设计方案;但是,类型 2 通过更复杂的集群设计和查询优化提供更好的性能。type-2 中的分片服务器提供计算能力,而 type-1 没有这种能力。
下图显示了 type-2 分片设计:
从传统 SQL 或 NoSQL 大数据框架设计的角度来看,分片并不是什么新鲜事。然而,图数据的分片可能是潘多拉魔盒,原因如下:
- 多个分片将提高 I/O 性能,尤其是数据摄取速度。
- 但是多个分片将显着增加任何跨越多个分片的图查询的周转时间,例如路径查询、k-hop 查询和大多数图算法(延迟增加可能是指数级的!)。
- 图查询计划和优化可能非常复杂,如今大多数供应商在这方面做得很浅,并且有大量的机会可以即时深化查询优化:
- 级联(启发式与成本)
- 分区修剪(实际上是碎片修剪)
- 索引选择
- 统计(智能估计)
- 下推(使计算尽可能靠近存储)等等。
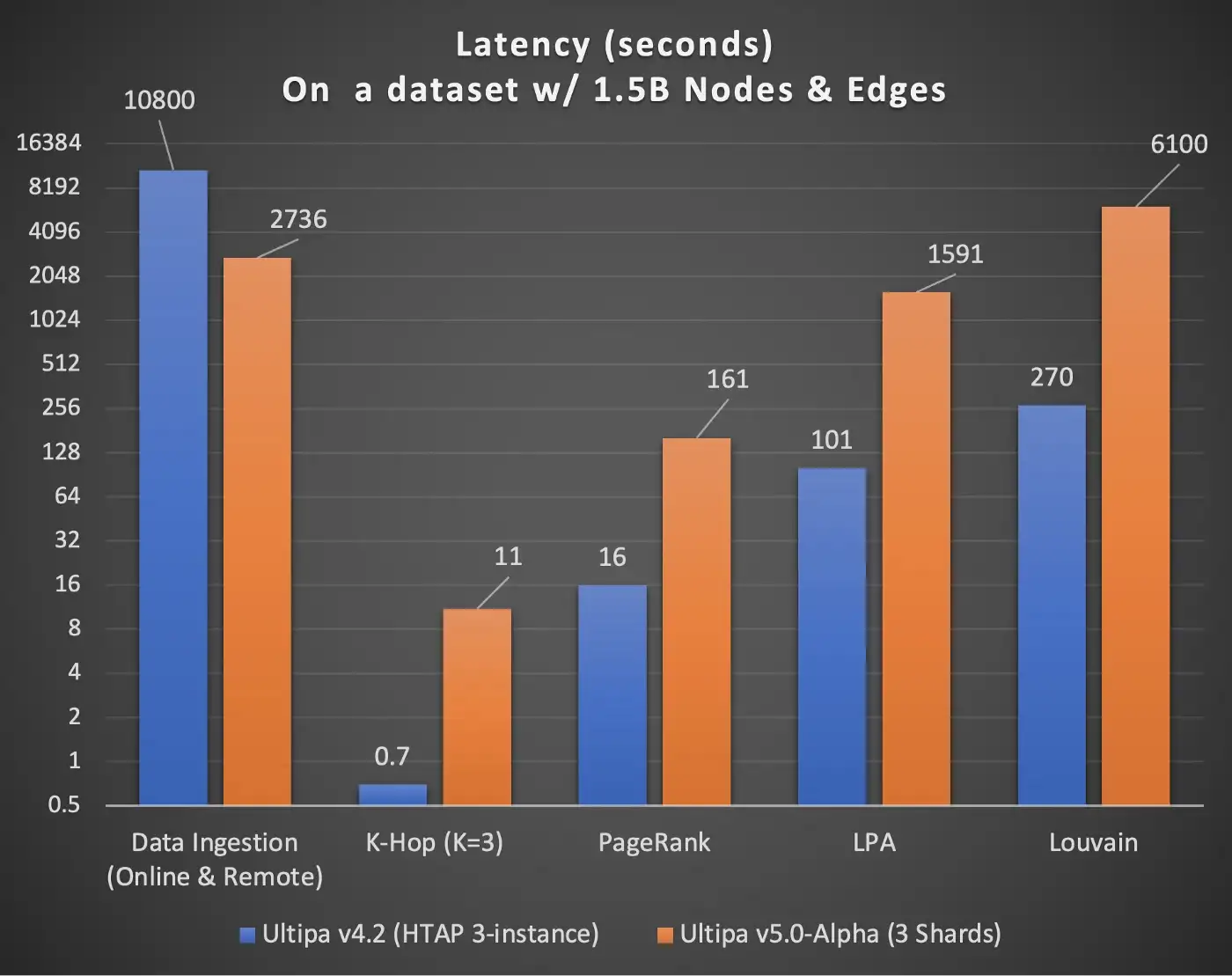
在 Graph-7 中,我们捕获了一些关于 Ultipa HTAP 集群和 Ultipa Shard 集群的初步发现;如您所见,数据摄取速度提高了四倍(超线性),但其他一切往往会慢五倍或更多(PageRank 慢 10 倍,LPA 慢 16 倍,等等)
本站声明: 1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享; 2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关; 3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关; 4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除; 5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。